







 GROVER是为解决分子图的监督训练数据不足和泛化能力差的问题而提出的。通过设计自监督任务,它能从大量未标记的分子数据中学习丰富的结构和语义信息。模型采用图神经网络与Transformer结合的架构,增强了分子的表示能力。动态消息传递网络(dyMPN)允许在训练过程中随机选择消息传递步数,提高模型的泛化性能。预训练任务包括上下文属性预测和图级基序预测,以增强模型的学习。实验表明,自我监督预训练、GTransformer和dyMPN都是提升GROVER性能的关键因素。
GROVER是为解决分子图的监督训练数据不足和泛化能力差的问题而提出的。通过设计自监督任务,它能从大量未标记的分子数据中学习丰富的结构和语义信息。模型采用图神经网络与Transformer结合的架构,增强了分子的表示能力。动态消息传递网络(dyMPN)允许在训练过程中随机选择消息传递步数,提高模型的泛化性能。预训练任务包括上下文属性预测和图级基序预测,以增强模型的学习。实验表明,自我监督预训练、GTransformer和dyMPN都是提升GROVER性能的关键因素。
GROVER 2020
Motivations
1、insufficient labeled molecules for supervised training
2、poor generalization capability to new-synthesized molecules
3、Graph Representation frOm self superVised mEssage passing tRansformer
(1)carefully designed self-supervised tasks in node-, edge- and graph-level, GROVER can learn rich structural and semantic information of molecules from enormous unlabelled molecular data
(2)GROVER integrates Message Passing Networks into the Transformer-style architecture to deliver a class of more expressive encoders of molecules
Related Work
1、SMILES:molecule can be transformed into sequential representation
fail to explicitly encode the structural information of molecules as using the SMILES representation is not topology-aware(转换成序列表示的方法无法提取结构信息,不是拓扑感知的)
2、pre-trained model directly on the graph representations of molecules
(1)在masking任务中,把原子类型作为标签,数量远低于NLP中的词,会造成表示歧义,对高频原子学不到有意义的信息
(2)图层次的预训练任务是有监督的,如果下游任务与图级监督任务不一致,可能会有相反的作用
3、Self-supervised Learning on Graphs
(1)利用n-gram模型提取顶点上下文信息
(2)各种策略预训练GNNs 三种自监督任务
缺点:很难维护局部结构和顶点性质的域知识;图层次的任务是建立在监督性质标签上的
Methods
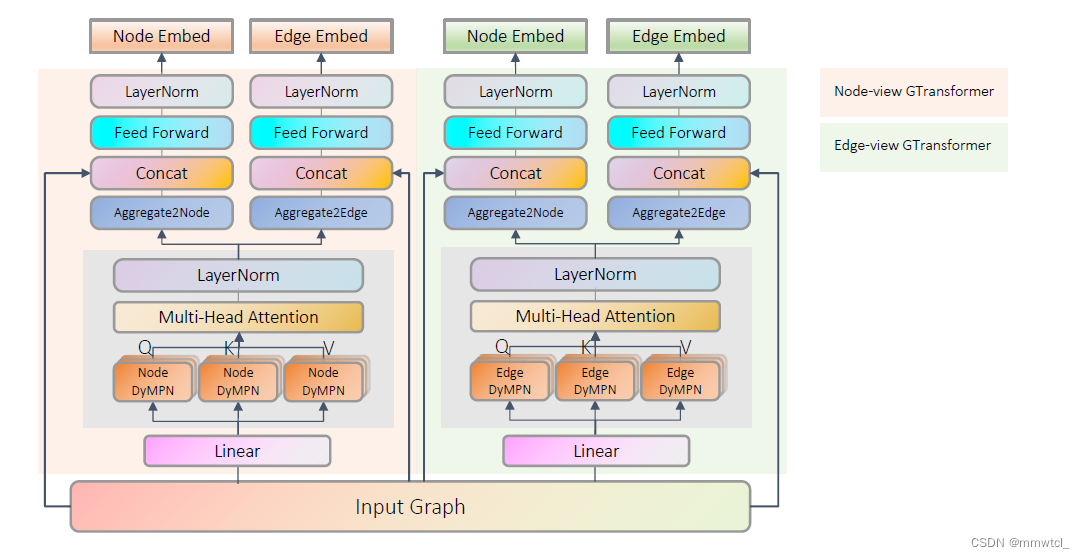
the model outputs four sets of embeddings from two information flows. The GROVER node information flow (node GTransformer) maintains node hidden states and finally transform them into another node embeddings and edge embeddings, while the edge information flow (edge GTransformer) maintains edge hidden states and also transforms them into node and edge embeddings.
Details of Model Architecture
GNN Transformer
1、we design a tailored GNNs (dyMPN, see the following sections for details) to extract vectors as queries, keys and values from nodes of the graph, then feed them into the attention block(使用dyMPN的GNN提取完图的局部信息之后,将输出的节点表示作为KQV送入attention模块)
2、the Transformer encoder can be viewed as a variant of the GAT on a fully connected graph(可看作在一个全连接图上做某种GAT)
3、GTransformer applies a single long-range residual connection from the input feature to convey the initial node/edge feature information directly to the last layers of GTransformer(用一个长的残差连接代替Transformer中多个短的残差连接)
Dynamic Message Passing Network (dyMPN)
Instead of pre-specifie K, we develop a randomized strategy for choosing the number of message passing hops during training process:
1、uniform distribution(均匀分布)
2、truncated normal distribution(被截断的正态分布)
Self-supervised Task Construction for Pre-training
1、Contextual Property Prediction
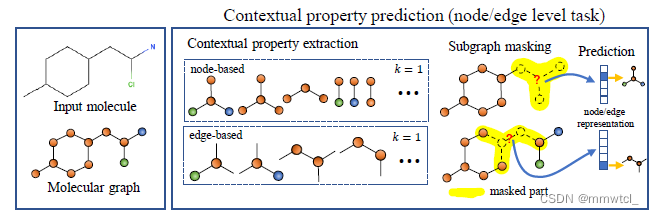
(1)给定一个分子图送入GROVER编码器,得到结点和边的表示
(2)随机选取一个结点(原子),将该结点表示送进一个非常简单的模型,然后将输出用于预测该结点上下文的性质
2、Graph-level Motif Prediction
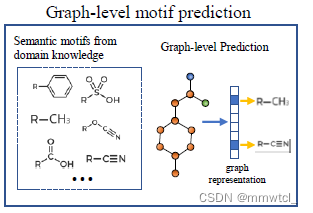
(1)对于一个分子,使用专业软件检测每个基序是否出现在该分子中
(2)预测分子中是否出现各种基序
Conclusions
1、Self-supervised Pre-training
the performance of GROVER becomes worse without pre-training:the self-supervised pre-training strategy can learn the implicit domain knowledge and enhance the prediction performance of downstream tasks
2、GTransformer
GROVER with GTransformer backbone outperforms GIN and MPNN in both training and validation
3、dyMPN and GTransformer
(1)GROVER w/o GTrans is the worst one in both training and validation:It implies that trivially combining the GNN and Transformer can not enhance the expressive power of GNN
(2)dyMPN brings a better generalization ability to GROVER by randomizing the receptive field for every message passing step
Future Work
1、More self-supervised tasks: such as distance-preserving tasks and tasks that getting 3D input information involved
2、More downstream tasks: such as node prediction and link prediction tasks on different kinds of graphs
3、Wider and deeper models

















 269
269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









