






最近我读到一篇很有意思的论文,名字叫《Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures》,是 DeepSeek 团队的新作。

别急着打瞌睡,虽然这是技术论文,但他们聊的是一个特别现实的问题:我们都在谈大模型训练得越来越厉害,可是,撑起这些大模型的硬件,真的够用了么?又该怎么设计,才能不“烧钱烧机房”?
一次大模型训练背后的“硬件炼狱”
DeepSeek-V3 的训练用上了 2048 块 NVIDIA H800 GPU——这听起来像是“硬件豪宅”,但他们却用这套系统推导出一个结论:靠硬堆设备已经玩不转 LLM 了,必须软硬件一起动脑筋。
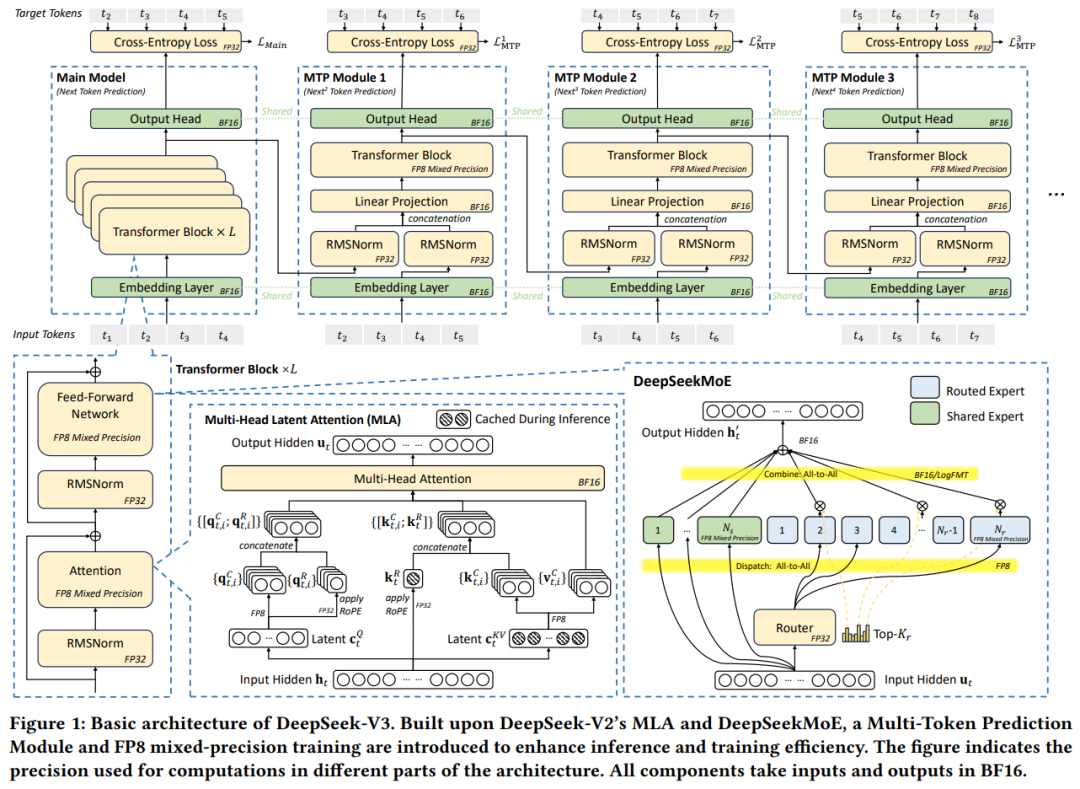
而这次,他们没再继续聊模型结构的细节,而是把重心放在了模型和硬件之间的互动。比如,怎样把计算任务安排得更顺、怎么让 GPU 别在等内存或网卡,白白浪费宝贵算力资源。
把专家拆开:MoE 架构的聪明玩法
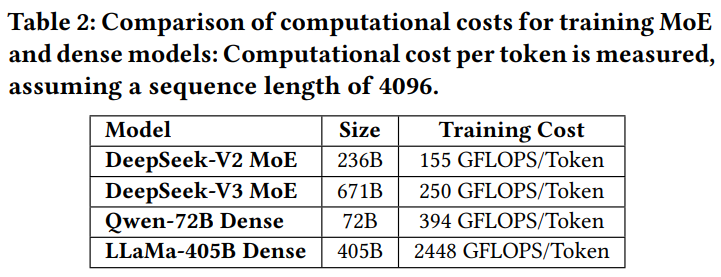
DeepSeek-V3 采用的是 MoE(混合专家)架构,模型有 671B 个参数,但每次推理只用其中 37B 个。这就像你开一家店有 1000 个员工,但每次只安排 50 个上班。这样一来,能省下不少电费(字面意义上的电费)和硬件开销。
相比那种参数全启用的“大块头”模型(比如 LLaMA 3.1),MoE 模型的计算开销少一个量级。例如每个 token 的训练消耗只有 250 GFLOPS,而密集模型动辄上千 GFLOPS。
KV 缓存别太膨胀:MLA 技术上场
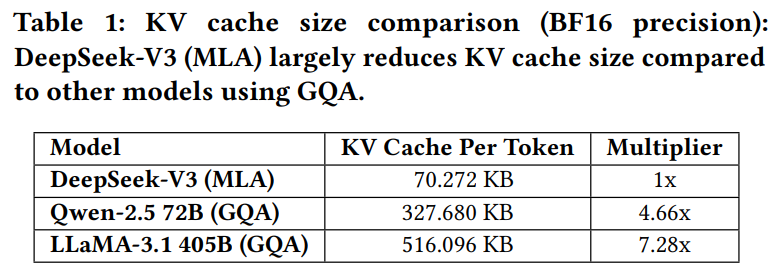
推理阶段的最大内存杀手,就是键值(KV)缓存。DeepSeek 搞了个新方案叫 MLA(多头潜在注意力),它可以把每个 token 的缓存压到只有 70 KB。参考下 LLaMA3.1 的 516 KB,这简直是存储界的极限压缩大师。
MLA 的原理很巧妙:它不是记录每个注意力头的键值,而是算出一个“潜在空间”,只记录这个空间的值,大幅节省内存。配合共享 KV(GQA/MQA)、窗口 KV 和量化方法,能让模型在推理时既快又省。
推理速度怎么卷?他们用“双核流水线”解决了
你以为模型推理就是顺着跑一遍?别天真了。为了让 GPU 不闲着,DeepSeek 把推理分成两个“微批次”交替运行,一个算 MoE,一个通信调度。相当于做饭时一边炒菜一边煮饭,时间就能用满了。
而且在生产环境里,他们还玩起了“推测解码”+“解耦预填充”这一套,确保海量请求和低延迟用户可以互不干扰。
低精度≠低质量:FP8 成功登上训练舞台
过去大家用 FP16、BF16 进行训练,DeepSeek 搞出一套 FP8 训练系统。这种极低精度的计算格式以前只敢用在推理环节,现在他们用来训练大模型了。
他们不仅优化了计算流程,还引入了一种叫 LogFMT 的量化格式,让 token 的传输压缩率翻倍,通信开销大减。
多节点训练,网络真的跟得上吗?
模型拆开跑就完事了?当然没那么简单。模型一拆,节点就得疯狂互相通信。NVLink(节点内)和 IB(节点间)的带宽差别让人抓狂。
DeepSeek 提出的解法之一是“节点受限式路由”策略,简单来说,就是尽量把任务分配给同一节点内部的专家,减少走 IB 的次数。这样可以把通信时间从 8t 降到 Mt(M<8),大大减轻了网络压力。
网络设计也有门道:多平面胖树 MPFT
这次训练用的网络拓扑是多平面双层胖树(MPFT),能支持上万块 GPU,还保留了低延迟的优势。对比了一下英伟达推的 MRFT,DeepSeek 的 MPFT 性能几乎持平,但部署成本更低。
不过这套网络方案没完美实现,因为当前使用的 IB 网卡(ConnectX-7)不支持某些多端口特性,需要升级到未来的 ConnectX-8 才能完美落地。
未来还想做什么?他们给出了几大方向
除了论文里的工程细节,DeepSeek 还分享了他们对下一代硬件架构的思考:
-
- 想办法解决“隐性错误”,比如内存翻转引起的模型损坏。
-
- 提高 CPU 与 GPU 的协同效率,比如取消 PCIe 中间桥接,直接打通通路。
-
- 在网络中“边传边算”,让网络不只是运输工,还能变成计算工。
-
- 用光互联和智能路由技术,解决 all-to-all 这种神烦的通信瓶颈。
最后说点个人的感受
读完这篇论文,我感觉 DeepSeek 真的是“硬件亲儿子”选手。他们没有选择暴力堆算力,而是用软硬件协同,把每一块 GPU、每一条带宽都压榨到极致。特别是像 MLA 和 MoE 的协同机制,不仅提升了性能,也让训练更省钱、更可持续。
对 AI 从业者来说,这篇论文的意义在于它不是告诉你“我们模型多厉害”,而是在说“要想模型跑得快,你得先搞懂背后硬件怎么回事”。这不仅是工程问题,更是一种系统性思维的体现。
大模型岗位需求
大模型时代,企业对人才的需求变了,AIGC相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
零基础入门AI大模型
今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
内容包括:项目实战、面试招聘、源码解析、学习路线。
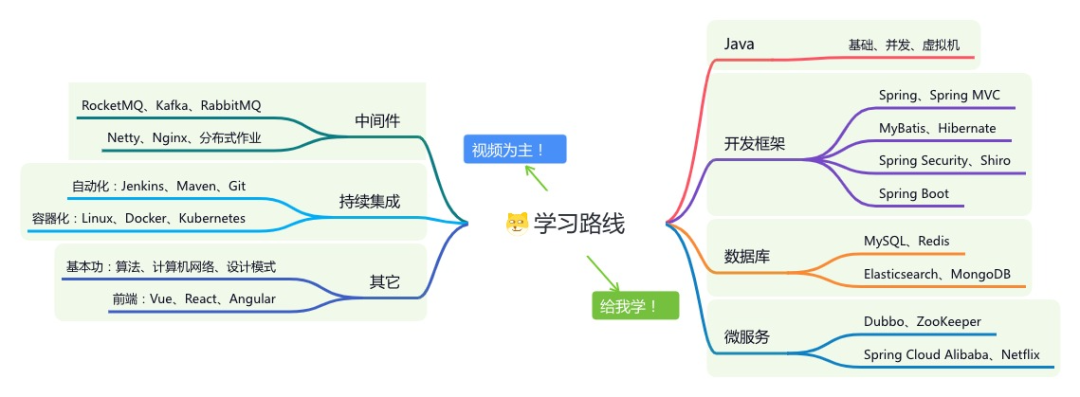
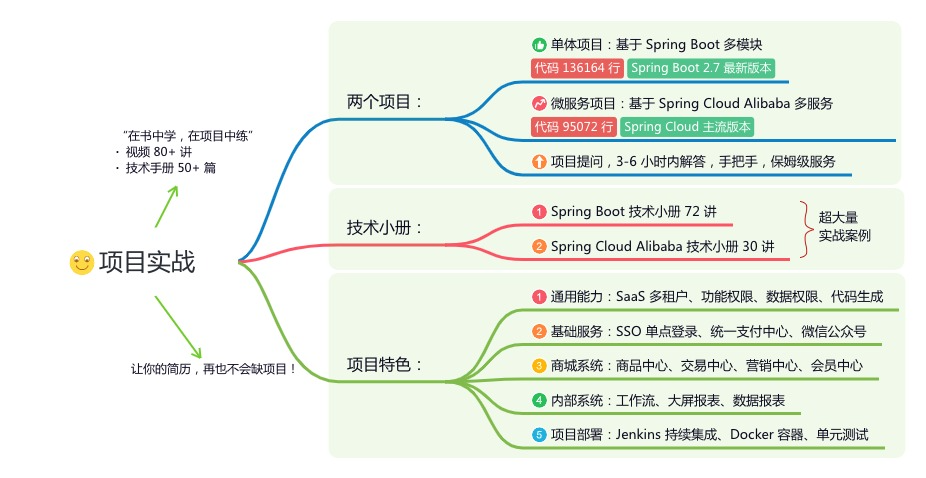
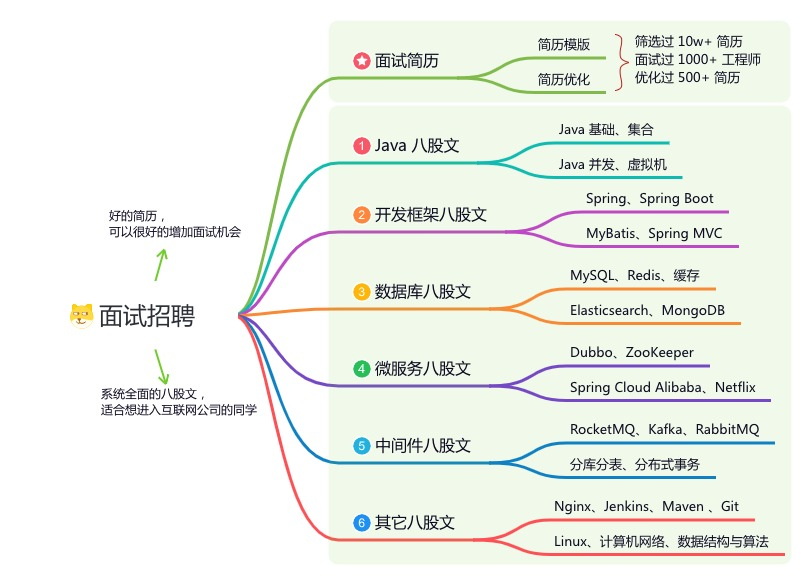
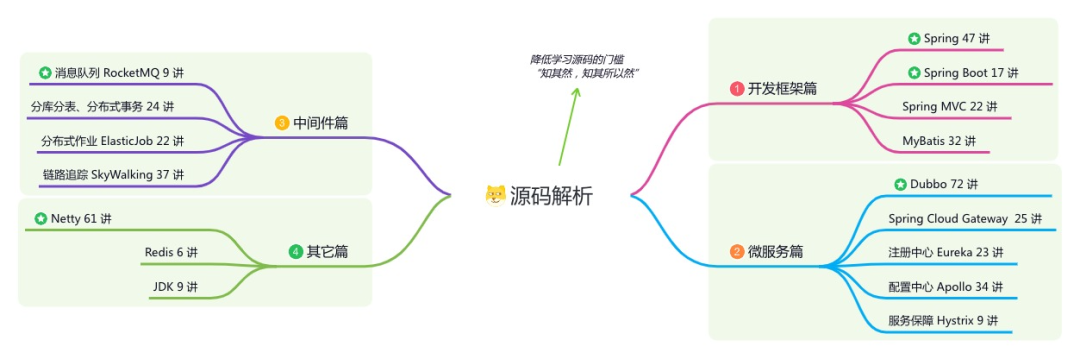
如果大家想领取完整的学习路线及大模型学习资料包,可以扫下方二维码获取

👉2.大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。(篇幅有限,仅展示部分)

大模型教程
👉3.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(篇幅有限,仅展示部分,公众号内领取)

电子书
👉4.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(篇幅有限,仅展示部分,公众号内领取)

大模型面试
**因篇幅有限,仅展示部分资料,**有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
**或扫描下方二维码领取 **

















 712
712

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









