






参考文献:https://github.com/fundamentalvision/BEVFormer
https://github.com/TemryL/BEVFormer-HoP
1,环境介绍
CPU:Intel Core i5-11400
内存:32GB
主板:Z590
显卡:NVIDIA Tesla M40 24GB
硬盘:500GB机械
操作系统:Ubuntu 20.04.4 LTS
2,显卡驱动与CUDA安装
在安装好操作系统以后,需要先安装显卡驱动,这里驱动选择470.256.02的版本:
https://www.nvidia.com/en-us/drivers/details/226760/ https://www.nvidia.com/en-us/drivers/details/226760/
https://www.nvidia.com/en-us/drivers/details/226760/
下载完成后需要为该文件赋予可执行权限
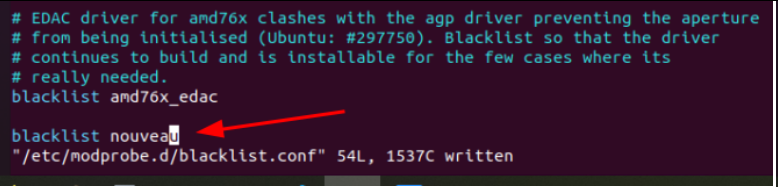
chmod +x NVIDIA-Linux-x86_64-470.256.02.run然后先禁用开源驱动,以管理员权限编辑/etc/modprobe.d/blacklist.conf文件,在末尾写入一行blacklist nouveau后,保存:
然后安装编译驱动所需的依赖:
sudo apt-get install git gcc g++ make build-essential linux-headers-$(uname -r)然后重新启动电脑,再次开机后,按组合键Ctrl+Alt+F3,进入一个后台终端,输入
sudo init 3
让系统退出图形模式,然后执行刚刚下载的驱动安装文件(如果中途被强制切换到tty1,可再次按上面的组合键回到tty3):
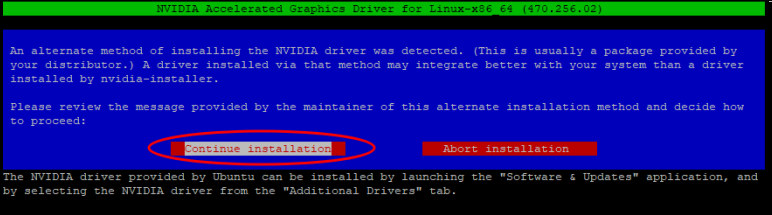
sudo ./NVIDIA-Linux-x86_64-470.256.02.run
然后在弹出的界面中选择默认的继续安装并按回车:
然后它会开始编译内核驱动(模块)

成功后会提示你是否安装32位兼容库,这里选择默认的是(按回车):

然后会弹出一个警告,不用管,直接OK

然后还会跑一个进度条:
等它跑完后,会提示安装完成:

然后重启电脑,此时打开终端,可以输入nvidia-smi查看驱动是否安装成功:

可以看到成功认到显卡的信息,并且存在任务在使用显存,就表示驱动安装成功。
然后接下来我们安装CUDA,这里要注意,驱动上标记的11.4版本,指的是这个驱动支持的最高版本,然后它是向下兼容的,我们这里需要安装11.1版本的CUDA,下载地址:
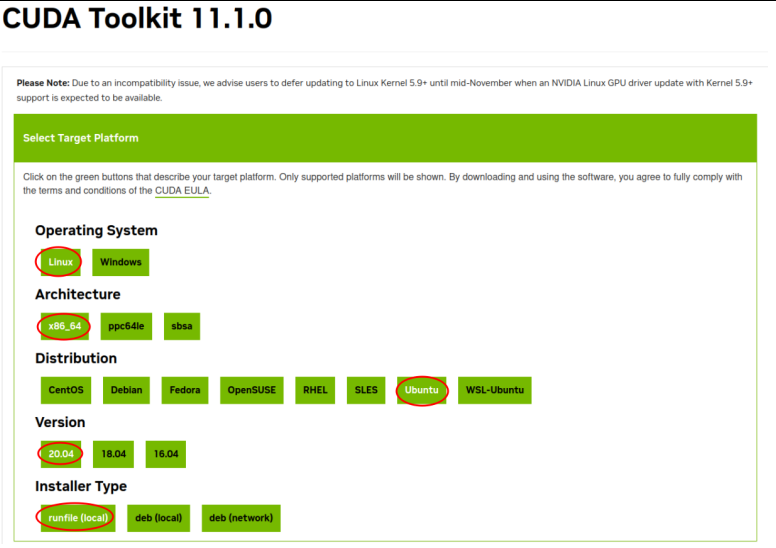
下载好以后,还是先赋予可执行权限:
chmod +x ./cuda_11.1.0_455.23.05_linux.run然后以管理员权限执行:
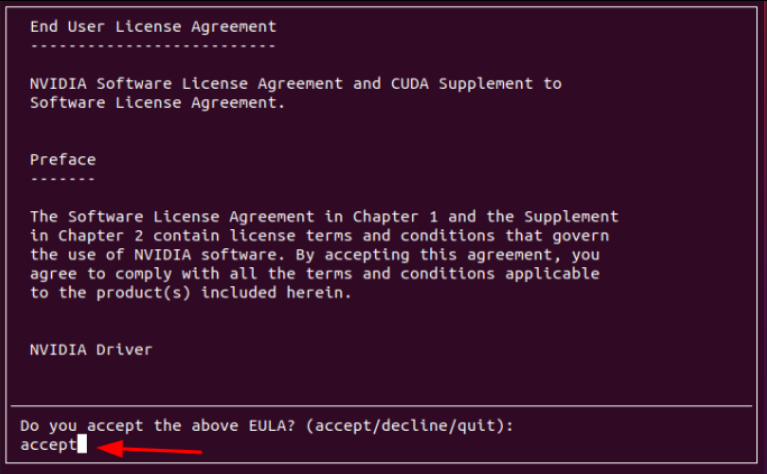
sudo ./cuda_11.1.0_455.23.05_linux.run然后会弹出一个对话框,我们需要在里面输入 accept
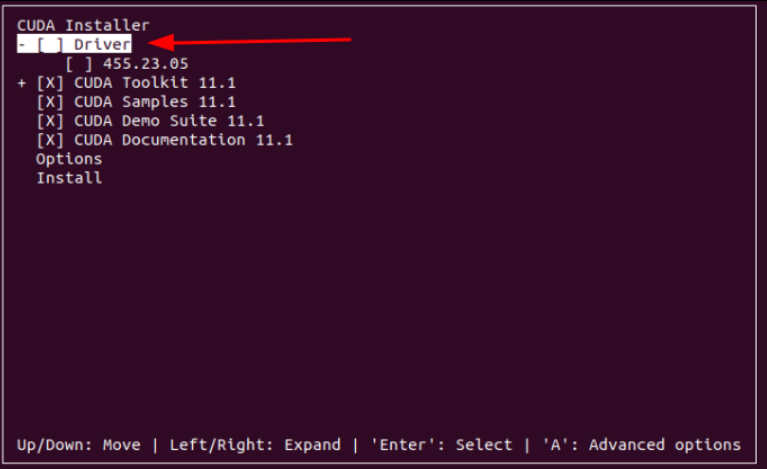
然后按空格键取消选择驱动的安装,因为我们已经安装过了,所以驱动就不用重复安装了。
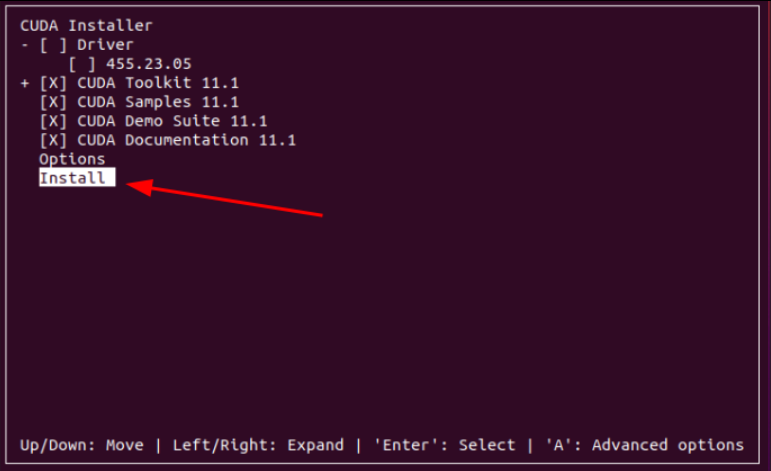
然后把光标移动到最下面的Install上,然后按回车
安装完成以后,会提示一堆概述信息,可以保存下来以后用。不过本次我们用不到。
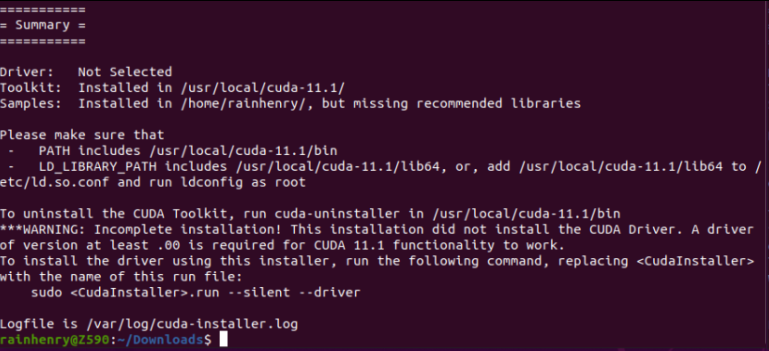
3,安装python基础环境,验证CUDA环境
首先安装python
sudo apt-get install python3 python3-pip python3-venv python3-tk
然后新建一个工作目录,并创建python虚拟环境:
mkdir test1
cd test1/
python3 -m venv env
source env/bin/activate
然后安装torch库等
pip install torch==1.9.1+cu111 torchvision==0.10.1+cu111 torchaudio==0.9.1 -f https://download.pytorch.org/whl/torch_stable.html
这里的操作对网络环境要求比较严格,需要网络环境较好的地方才可以。如果网络环境不好可以重新尝试执行该命令,或者自行更换其它源等。
然后我在网上找了一小段代码,可以用来检查你的CUDA环境是否OK,代码出处:
https://zhuanlan.zhihu.com/p/671997917
代码如下:
import torch
# 检查是否有可用的 GPU
if torch.cuda.is_available():
# 获取 GPU 设备的数量
gpu_count = torch.cuda.device_count()
print(f"Number of available GPUs: {gpu_count}")
# 获取当前 GPU 的名称
current_gpu_name = torch.cuda.get_device_name(torch.cuda.current_device())
print(f"Current GPU: {current_gpu_name}")
# 获取所有 GPU 的名称
all_gpu_names = [torch.cuda.get_device_name(i) for i in range(gpu_count)]
print(f"All GPUs: {all_gpu_names}")
else:
print("No GPU available.")然后我这里就把它命名为check_gpu.py,然后执行它:
python3 check_gpu.py 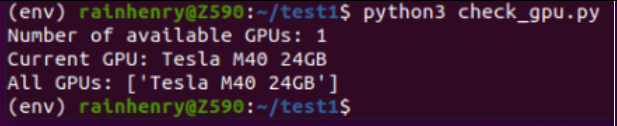
可以看到,环境搭建OK了,可以成功认到GPU。
其他依赖安装
pip install "mmcv-full==1.4.0" -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.9.1/index.html 在安装这个的时候,会有一段报错,可以不用管。而且它在编译的时间会比较长,耐心等待。
然后这里要注意,如果你的系统中已经安装了mmcv,请卸载它,一定要安装mmcv-full版本。
pip install mmsegmentation==0.14.1然后需要从源码安装mmdetection3d:
git clone https://github.com/open-mmlab/mmdetection3d.git
cd mmdetection3d
git checkout v0.17.1
然后在编译它之前,先安装一些依赖
pip install "scikit-image==0.21.0"
pip install "scikit-learn==1.3.2"
pip install "mmdet==2.14.0"
pip install "networkx==3.1"
pip install "numpy==1.23.5"安装这些包的时候,会有报错,也不用管
然后再执行安装
python3 setup.py install然后安装
pip install einops fvcore seaborn iopath timm typing-extensions pylint ipython==8.12 matplotlib==3.5.2 numba==0.48.0 pandas==1.4.4 然后需要从源码安装detectron2
cd ..
git clone https://github.com/facebookresearch/detectron2.git
cd detectron2
git checkout v0.4
同样在安装它之前也要安装一些依赖
pip install MarkupSafe然后执行安装
python3 setup.py install然后还有一些包也要安装一下
pip install pyquaternion
pip install shapely
pip install cachetools
pip install "tools==0.1.6" "pytils==0.4.1" ## 这里中间会有报错,不用管
pip install "Pillow==9.5.0"
pip install yapf==0.40.1 importlib-metadata==8.5.04, 下载源码,模型和数据集
cd ..
git clone https://github.com/fundamentalvision/BEVFormer.git
cd BEVFormer
mkdir ckpts
cd ckpts
wget -c https://github.com/zhiqi-li/storage/releases/download/v1.0/r101_dcn_fcos3d_pretrain.pth下载好后的文件信息:

然后去下载can_bus.zip
先打开网站:https://www.nuscenes.org/download
然后自己注册一个账号,随便一个能收到邮件的邮箱都行,我这里用的是qq邮箱
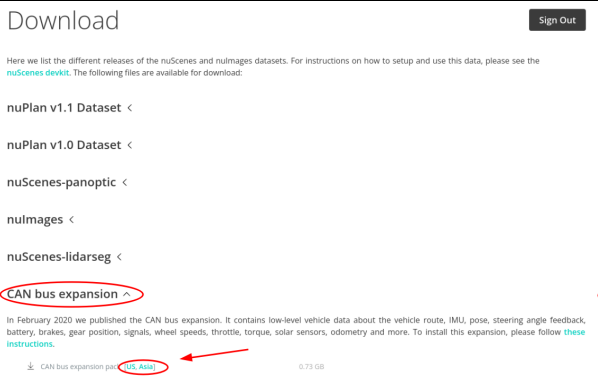
然后登陆,然后把前面几项都折叠起来,找到CAN bus这项,然后根据你所在地区进行下载:
下载好后是一个压缩包:

然后在源码目录中新建一个data文件夹,把它解压进去:
cd BEVFormer
mkdir data
cd data
unzip ./../../can_bus.zip然后再下载数据集:
先找到这里

然后下面的三个都是,文件非常庞大
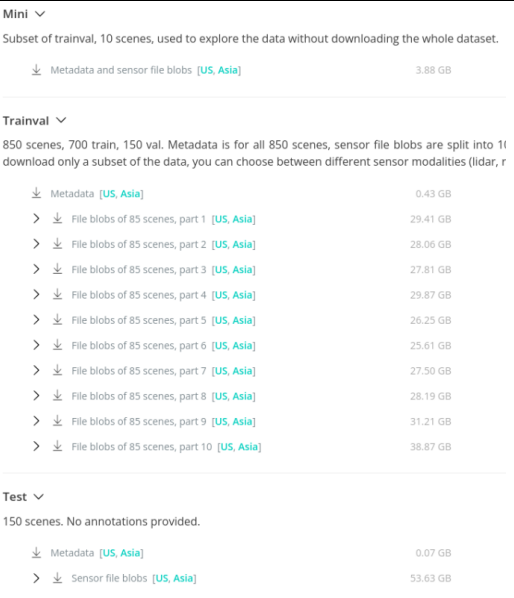
如果这里你想偷懒的话,可以只下载Mini的,然后把它重命名复制成其他的就可以了(但是会影响到后面Hop的部分)
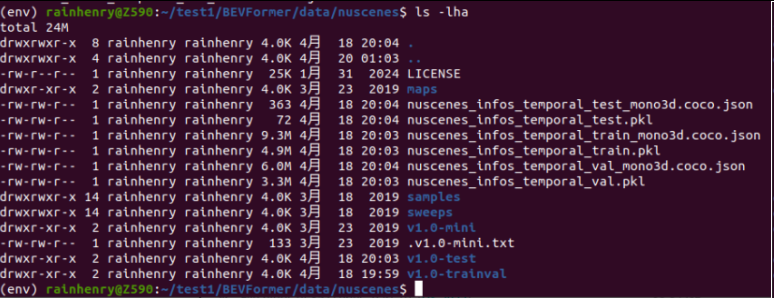
然后数据集的话要在data目录里面再新建一个nuscenes文件夹,然后把数据集解压放到里面:
然后我们需要在源码根目录的tools目录下创建一个__init__.py的空文件
cd tools
touch __init__.py 
然后切换到源码根目录后,先执行配置环境:
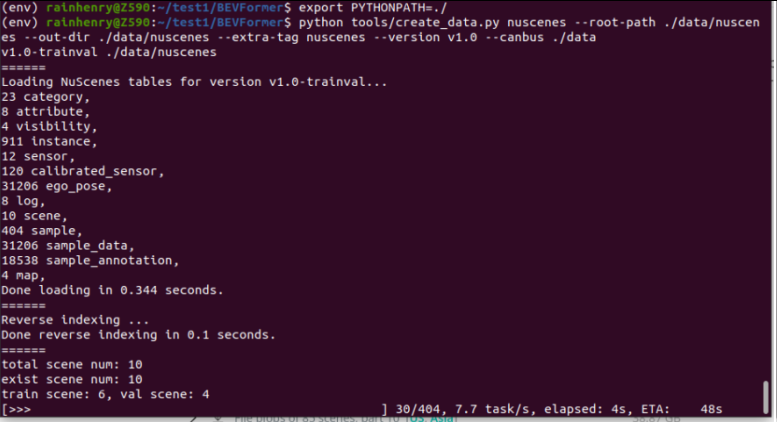
export PYTHONPATH=./然后执行下面命令对数据进行处理
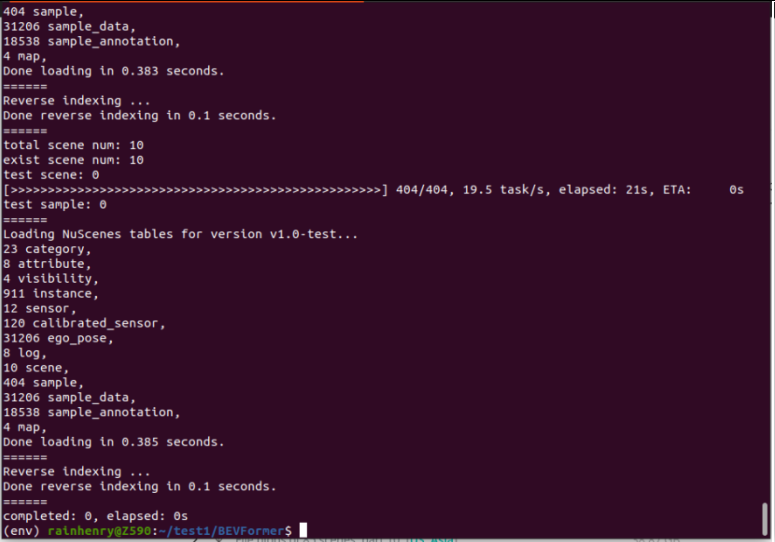
python3 tools/create_data.py nuscenes --root-path ./data/nuscenes --out-dir ./data/nuscenes --extra-tag nuscenes --version v1.0 --canbus ./data然后就开始了漫长的数据处理了:
处理完后如图:
5, 训练和测试
首先是训练,这个是可选的,因为我们下载的模型已经是预训练的模型了,然后由于我们的硬件限制,这里使用tiny的模型
./tools/dist_train.sh ./projects/configs/bevformer/bevformer_tiny.py 1后面的1表示使用1个GPU,因为我只有1个GPU
然后就开始了漫长的训练过程:
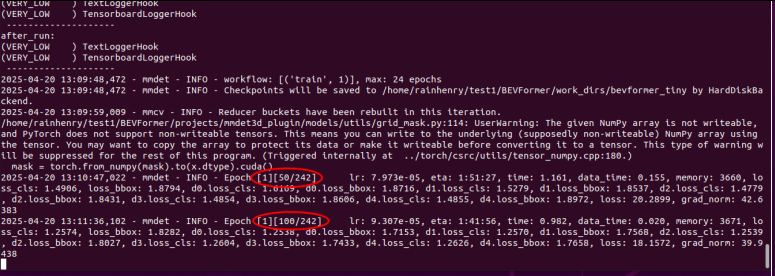
画圈的位置是进度
然后我这边在第一轮得到的结果是:
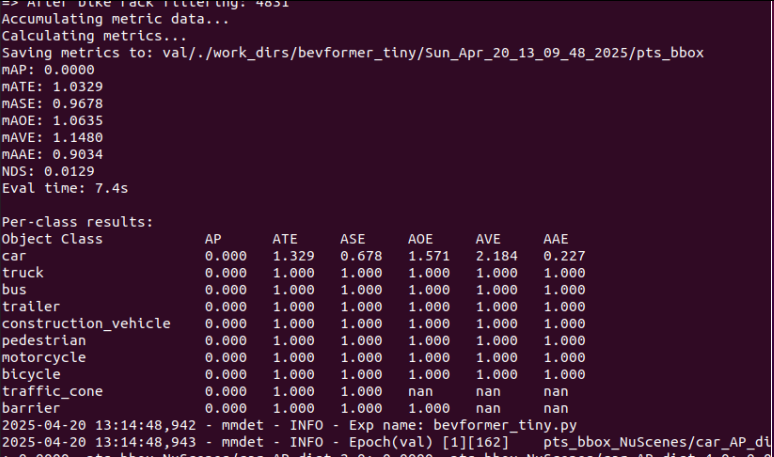
然后别急,这个一共要跑24轮呢。。。很漫长的
然后顺便再看下显卡那边的负载情况:
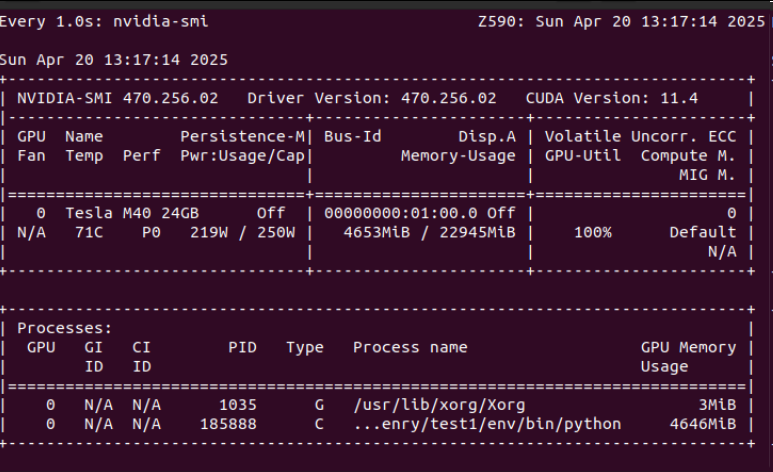
而且已经明显能感受到机器吹出来的热风了。。。
顺便这里再多说一句,我这个机器的电源是两个拼在一起的,主板和CPU使用一个500W的,然后显卡单独用了一个2000W的,如果只用1个500W电源的话,在满载的时候会直接断电的。
经过几个小时漫长的等待,终于跑完了最后一轮,结果如下:
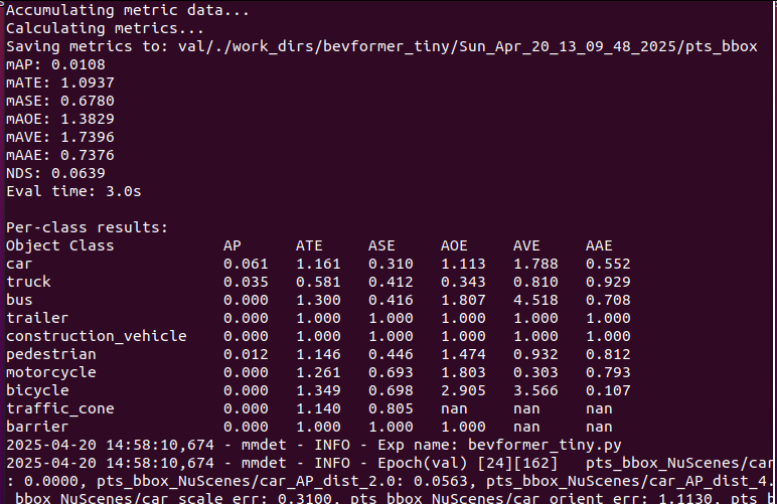
然后就是跑下测试集
./tools/dist_test.sh ./projects/configs/bevformer/bevformer_tiny.py ./ckpts/r101_dcn_fcos3d_pretrain.pth 1结果如下:
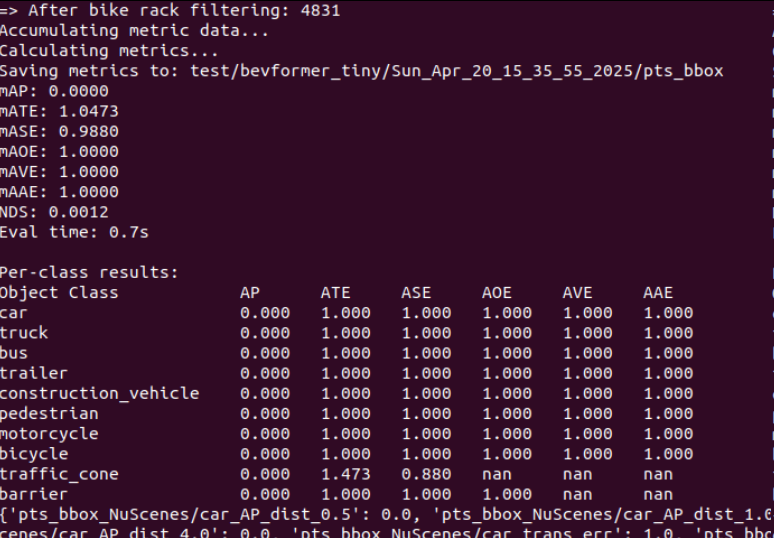
那么,我们如何看到一些更加直观的效果呢?
在源码中有一个tools/analysis_tools/visual.py的代码,我们需要修改第474行的内容为我们刚刚测试的结果,比如我这里是:

修改完以后,执行它
python3 tools/analysis_tools/visual.py然后就会有可视化的结果出现了,由于数据太多了,这里就贴几张图:


在此省略n张图,然后都渲染完以后,它也会提示一些日志:
同时,也会在你的源码根目录生成很多图片:
我们随便打开一张图,bev结尾的,就会看到:
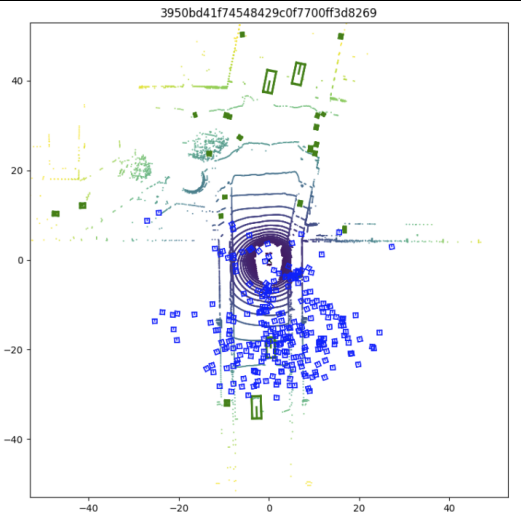
也就是从车顶上方俯视看到的场景了,这也就是这个模型的意义。而上面的这个数据,是由6个摄像头在一个车上的不同角度排到的情况,并且是连续的场景视频,才能做到这种效果。
6, 尝试使用自己的图片
虽然我们跑通了官方给的demo,但是在实际应用中是需要从摄像机获取图片数据然后得到从上方看的俯视效果图的。这里我们再下载一个源码,完成一个最简单的单个图片的推理过程。
下载源码:
git clone https://github.com/TemryL/BEVFormer-HoP.git
然后这个HoP所用的模型参数和上面原版的是有些区别的,所以这里还要单独下载一下:
所有的文件都在这个链接里:https://drive.switch.ch/index.php/s/dvADSm42HRxoi0f
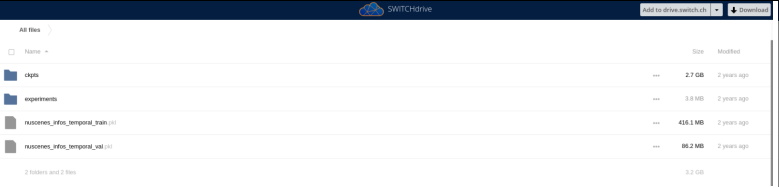
和刚刚的原版的一样,先把ckpts下载后(上图中的第一个),放到新下载的源码的ckpts目录里(自己新建一个)。
然后再新建一个data文件夹,然后里面的can_bus还是用之前的就可以,然后nuscenes文件夹里面的数据集也还是之前的,然后pkl文件使用这个新的链接的(上图中的最后2个)。
我这里为了节省磁盘空间,重复的部分使用的是软连接:
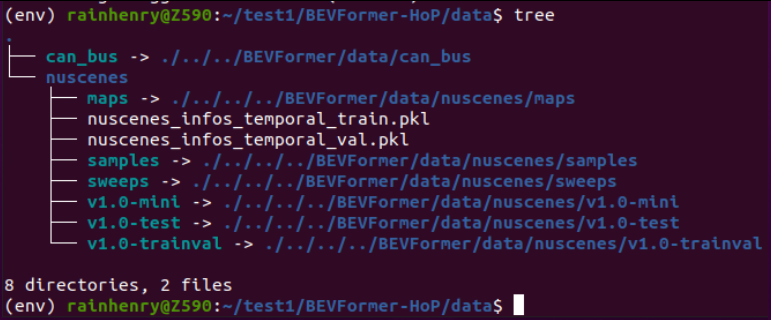
注意:上面的tree命令需要使用sudo apt-get install tree来进行安装。
然后建立软连接的方法: ln -s 原始存在的文件 软连接本体的名字
然后在源码根目录使用下面两个命令更新配置:
python3 update_nuscenes_infos.py data/nuscenes/nuscenes_infos_temporal_train.pkl ./data
python3 update_nuscenes_infos.py data/nuscenes/nuscenes_infos_temporal_val.pkl ./data
然后,我们可以随便找一张图片,就比如下面这个我在路边随便拍的一张:

然后这里需要注意一下,由于我的显卡的显存有限,不能处理太大尺寸的图,所以我通过PS将这个原图改为512x290像素大小的图了。
然后在源码根目录新建一个photo的文件
mkdir photo然后把我们刚刚修改好的图片放进去。
然后由于我使用的是带有hop的mini的配置,所以需要也修改一下配置文件中的输出分辨率:
在源码根目录的 projects/configs/bevformer_hop/bevformer_tiny_hop_bi_loss_0_mini.py 文件中,把第51,52行的数值,改为我们输入图片的高度和宽度:
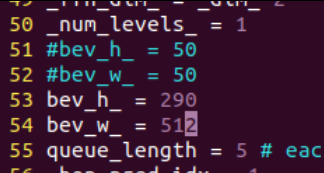
然后还需要修改一下输入输出文件的配置,在 projects/inferences/img_configs.py 文件中,将文件中的第3和4行分别改为你的输入图片 和 输出的图片:
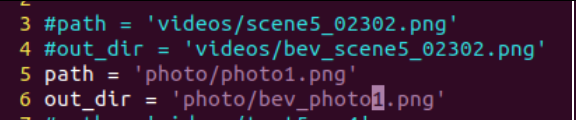
然后回到源码根目录,执行:
python3 -m projects.inferences.inference ./projects/configs/bevformer_hop/bevformer_tiny_hop_bi_loss_0_mini.py ./ckpts/bevformer_tiny_hop_bi_loss_0_mini_epoch_2.pth ./projects/inferences/img_configs.py 0.15执行成功后,会看到在我们刚刚新建的photo文件中会生产一个新的文件:

然后我们分别打开一下两个图片文件观察一下:
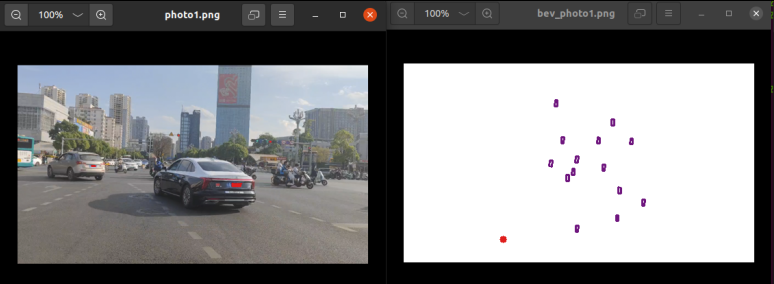
可以看到,它成功完成了推理!!
至此,我们就完成了BEVFormer的入门。
7,总结
本文详细的阐述了BEVFormer的搭建步骤和一个简单单图片应用的演示DEMO。这篇文章更多是面向初学者的,让刚入门的小伙伴可以尽量少走弯路的开始,完成最基本的环境搭建和DEMO重现等。在实际的使用中,1个相机1个图片肯定是远远不够的。就像本文中的测试集和训练集一样,需要连续的视频,并且在同一辆车上需要在6个不同方向的6组视频才可以足够精确的还原融合后的顶视图。从实际产品应用的角度来说,BEVFormer能够很好解决自动驾驶问题中如何感知周围环境的问题。相比于传统采用激光雷达和景深相机的方式,它能够区分出车辆和障碍物等。在这次环境搭建的实践中,由于我的硬件环境和资源等有限,无法更进一步为大家展示6相机的实车融合结果,如果未来有机会,我有足够的资源和实验条件后,我将会为大家更新。这也就是为什么我只在demo环节用了1张图片进行测试,实际上后面的Hop的代码,是支持连续视频文件的,但是我的硬件实在是跑不起来,显存不足呀。另外,只要是AI,基本上都会产生幻觉,完全依赖于AI的控制还是不够安全的。而在真正做产品的时候,BEVFormer还是要和激光雷达和景深相机等进行配合,才有可能做到ASIL-D的等级,否则用在汽车上将会是非常危险的。

















 379
379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









