







在现有的多视角3D目标检测方法中,通常包含三个主要的模块:
- 2D主干网络,用来对输入的多视角图片进行编码,得到2D图像特征;
- 2D到3D的特征拉升,用来将上一步中获取到的2D图像特征拉升到3D空间中预定义的一些锚点上,得到拉升后的3D特征;
- 基于拉升后的3D特征做3D目标检测。
在这其中第二步是现有的端到端的多视角3D目标检测方法的核心,起到了承上启下的关键作用。现有的方法主要基于两种特征拉升方法:
- 由Lift-Splat-Shoot提出的基于Lift-Splat的特征拉升方法(如下图a),虽然具有对深度的感知能力,但是由于该方法中3D锚点和2D图像特征之间的关系是由确定的几何关系固定了的,无法进行调整,因此,该拉升方法在整个3D目标检测流程中只能进行一次,一旦有任何误差便无法纠正回来。除此之外该方法还有一个小缺点,由于在拉升过程中需要显式地根据2D特征构建3D特征,2D特征的分辨率就不能太大,否则显存占用会急速膨胀。
- 基于2D注意力机制的特征拉升方法,例如由PETR提出的基于dense attention的、由BEVFormer提出的基于deformable attention的、由DETR3D提出的基于point attention(deformable attention的一种退化形式,只有一个采样点)的等等。在这类方法中,3D锚点与2D图像特征之间的关系是由学习到的采样点确定的,是可调整的,因此该拉升方法在整个检测流程中可以多次进行,从而进行优化。但,由于这类拉升方法直接将深度方向给忽略掉了,因此存在深度模糊问题。更具体的,如下图(b,c)所示,多个3D锚点投影到某个视图的时候,会落到十分相近的位置,导致他们采样到的特征耦合的十分严重,最终引起误检。
由此可见,目前主流的这些特征拉升方法都不尽如人意。为此,我们提出了一个基础算子:3D Deformable Attention,并基于此基础算子将2D图像特征更加合理地拉升到3D空间中(如下图d所示):即有对深度的感知能力,又有进行多层优化的能力。我们借助一些简单的数学推导极大地减少了执行该基础算子所需的资源,并通过CUDA实现来对其进行了进一步的优化。为了验证其有效性,我们将DFA3D适配到了多个方法上,带来了平均1.41% mAP的提升。

(1)LSS
代码讲解:(已开源)ECCV 2020 视觉BEV经典算法:LSS详解与代码_lss模型-CSDN博客
和Lift Splat 没有Shoot LSS入门看这个就够了_lift-splat-CSDN博客 这两篇博客还是很不错的
以及https://zhuanlan.zhihu.com/p/658864347

import torch
import torch.nn as nn
import cfg
class Lss():
def __init__(self):
self.frustum = self.create_frustum().to('cuda')
# (B, N, D, H, W, 3) = torch.Size([2, 6, 118, 32, 88, 3])
self.geom = self.get_geometry(cfg.camera2lidar_rots,
cfg.camera2lidar_trans,
cfg.intrins,
cfg.post_rots,
cfg.post_trans)
print(self.geom)
def create_frustum(self):
# 原图大小
iH, iW = 128, 352
# 特征图大小
fH, fW = 8, 22
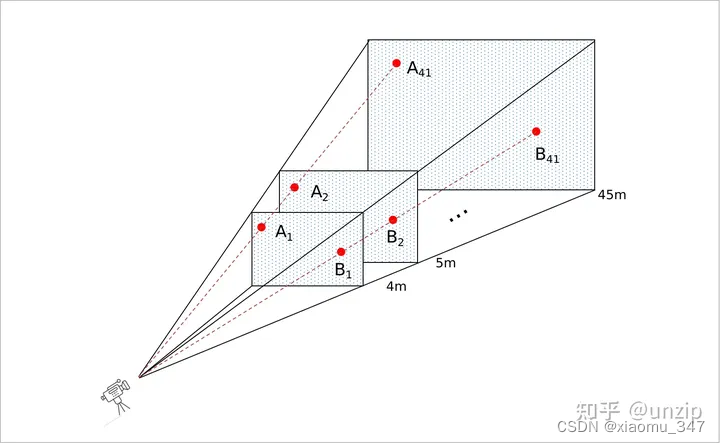
# 原图的深度范围:4-45,每隔 1 米有个深度值
dbound = [4, 45, 1]
ds = (
torch.arange(*dbound, dtype=torch.float)
.view(-1, 1, 1)
.expand(-1, fH, fW)
)
D, _, _ = ds.shape
xs = (
torch.linspace(0, iW - 1, fW, dtype=torch.float)
.view(1, 1, fW)
.expand(D, fH, fW)
)
ys = (
torch.linspace(0, iH - 1, fH, dtype=torch.float)
.view(1, fH, 1)
.expand(D, fH, fW)
)
# 特征图的深度点到原图的映射。
# (d, h, w, 3)=torch.Size([41, 8, 22, 3])
frustum = torch.stack((xs, ys, ds), -1)
return nn.Parameter(frustum, requires_grad=False)
def get_geometry(
self,
camera2lidar_rots,
camera2lidar_trans,
intrins,
post_rots,
post_trans,
):
B, N, _ = camera2lidar_trans.shape
# 去掉图像增强
# B x N x D x H x W x 3
points = self.frustum - post_trans.view(B, N, 1, 1, 1, 3)
points = (
torch.inverse(post_rots)
.view(B, N, 1, 1, 1, 3, 3)
.matmul(points.unsqueeze(-1))
)
# 将点转换到lidar坐标系
points = torch.cat(
(
points[:, :, :, :, :, :2] * points[:, :, :, :, :, 2:3],
points[:, :, :, :, :, 2:3],
),
5,
)
combine = camera2lidar_rots.matmul(torch.inverse(intrins))
points = combine.view(B, N, 1, 1, 1, 3, 3).matmul(points).squeeze(-1)
points += camera2lidar_trans.view(B, N, 1, 1, 1, 3)
# (B, N, D, H, W, 3) = torch.Size([1, 6, 118, 32, 88, 3])
return points
def main():
lss = Lss()
if __name__ == '__main__':
main()(2)BEVDET
基于LSS的成功,鉴智机器人提出了BEVDet,目前来到了2.0版本,在nuscences排行榜中以mAP=0.586暂列第一名。本文将对BEVDet的原理进行简要说明,然后结合代码对BEVDet进深度解析。
BEVDet的主要包含一下四个步骤,如下图所示:
- Image-view Encoder: 提取环视图片的特征
- View Transformer:提取BEV特征
- BEV Encoder:BEV特征编码
- Head:检测头

通过View Transformer,可以获得显示的BEV特征,类似点云特征,因此可以对BEV特征进行增强,同时使用cuda对Voxel Pooling过程进行加速,并且在Head中使用改进的NMS,具体详细细节可以参考[BEV] 学习笔记之BEVDet(原理+代码解析)-CSDN博客,总之bevdet中间采用了FPN+LSS+BEV数据增广+scale nms一系列技术,有助于算法的快速迭代部署。
(3)DETR/DETR3D
LSS方法进行透视视角到bev视角转换是非常直接的,但会带来较高的计算复杂度。而且仅从目标检测这个任务来说,稠密的特征表达其实是非必要的,因为最终目标是得到少量的target bbox。又因为我们有transformer这个大杀器,让自顶向下的稀疏bev表示成为可能。DETR3D便是在bev空间中使用transformer进行自顶向下特征提取的新范式。
通过DETR和DETR3D的网络结构对比,我们就可以简要领略这种改进是如何完成的:

DETR
如上图所示,DETR的主要框架是首先经过CNN提取特征,再通过transformer encoder进行全局特征编码,得到K和V再通过预设的object queries,与上一步获取的K和V做cross-attention,更新object queries,再经过FFN(feed forward network)得到目标分类和bbox回归结果。这里的object queries代表每一个潜在的目标检测框,个数即为最大支持的检测数目,省去了预设大量anchors的步骤。同时通过匈牙利匹配算法替换原来的nms操作,实现了真正的端到端检测,显著提高了效率。后面针对DETR计算量大、收敛较慢、难以作用于高分辨率图像等问题,基于可变卷积思想提出了一种可变注意力机制(deformable attention )网络Deformable DETR。
可变注意力机制避免了原生注意力机制中每个query和所有图像特征之间的交互计算,而是引入了参考点(reference points)和采样点(sampling points),每个object query对应一个参考点,代表目标的初始位置,它只和K个采样点做交互计算,大大节省了计算量,其中参考点和采样点的位置同样是可学习的,推理的结果不是bbox的绝对坐标,而是与参考点坐标的offset,使推理结果与decoder attention直接相关,有利于模型加速收敛。另外,deformable DETR还使用cross attention进行多尺度特征之间的信息交互,不需要FPN,并用scale-level embedding来区分不同尺度,对于小目标的检测效果提升显著。deformable DETR后续也成为一种重要的范式。
而DETR3D即是建立在DETR和deformable DETR的基础上,将2D检测推广到bev 3D检测的经典模型。

DETR3D
不同于LSS、BEVDepth的bottom-up式,先进行深度估计,设计2D转3D的模块。DETR3D是一种3D转2D的top-down思路。先预设一系列预测框的查询向量object querys,利用它们生成3D reference point,将这些3D reference point 利用相机参数转换矩阵,投影回2D图像坐标,并根据他们在图像的位置去找到对应的图像特征,用图像特征和object querys做cross-attention,不断refine object querys。最后利用两个MLP分支分别输出分类预测结果与回归预测结果。正负样本则采用和DETR相同的二分图匹配,即根据最小cost在900个object querys中找到与GT数量最匹配的N个预测框。由于正负样本匹配以及object querys这种查询目标的方式与DETR类似,因此可以看成是DETR在3D的扩展。
比较三者的代码还会发现,DETR的transformer阶段是标准的attention计算方式,包含Q,K,V的计算,而deformable DETR和DETR3D的K和V是合二为一的,与Q进行交互。这里可能也是为了节省计算量,或者因为已经进行了特征筛选,不需要再做多维度的特征提取。
(4)PETR
PETR开发了用于多视图3D对象检测的位置嵌入变换(PETR)。PETR将3D坐标的位置信息编码为图像特征,产生3D位置感知特征,对象查询可以感知3D位置感知特征并执行端到端对象检测。PETR在标准nuScenes数据集上实现了最先进的性能(50.4%的NDS和44.1%的mAP),并在基准测试中排名第一。它可以作为未来研究的简单而有力的基线。整体结构如下所示:

PETR中多视图图像被输入到主干网络(ResNet)以提取多视图2D图像特征。在3D坐标生成器中,所有视图共享的相机截头体空间被离散化为3D网格。网格坐标由不同的摄像机参数变换,从而生成三维世界空间中的坐标。然后将2D图像特征和3D坐标注入所提出的3D位置编码器以生成3D位置感知特征。从查询生成器生成的对象查询通过与transformer解码器中的3D位置感知特征交互来更新,更新的查询还用于预测3D边界框和对象类。
(5)BEVFormer
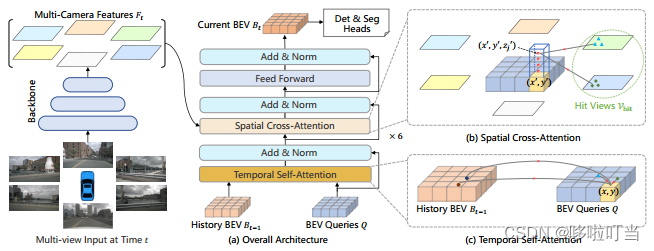
BEVFormer是一种基于Transformer的BEV编码器,从多视角摄像头和历史BEV特征中聚合时空特征,即时空编码,注意力机制用来融合时空信息。文中提到了三个关键点
- 网格状BEV查询,通过灵活的注意机制融合空间和时间特征
- 空间交叉注意模块,用于聚合来自多摄像头图像的空间特征
- 时间自注意模块,来自RNN的思想,用于从历史BEV特征中提取时序信息,(移动物体的速度估计和遮挡物体的检测)递归操作实现的准确速度预测
输入数据是六个摄像头在相同时间段内的数据,每个时刻对应了六张图表示周围的空间。
具体工作流程:先对前一个时刻的BEV特征做查询结合上当前的时刻特征,这样就是能够学习到时序关系,输出的BEV query再空间交叉注意力查询多摄像头的特征信息,生成当前时间戳的BEV特征bev_embedding,然后基于匈牙利算法做框匹配,利用已知的框位和模型框选计算L1 loss,结合分类损失平均最小。
具体总结如下,BEVFormer提出了一个新的框架,它使用时空transformer学习统一的BEV表示,以支持多个自主驾驶感知任务。BEVFormer通过预定义的网格形状的BEV查询与空间和时间空间交互,利用空间和时间信息。为了聚合空间信息,论文设计了空间cross-attention,每个BEV查询从摄像机视图的感兴趣区域提取空间特征。对于时间信息,提出了时间self-attention来递归地融合历史BEV信息。
具体的详细操作和代码解读可以参考https://zhuanlan.zhihu.com/p/543335939
(6)surroundocc
bevdet4d->bevformer
参考链接:
1、https://zhuanlan.zhihu.com/p/645990510
2、升级到3D多个SOTA!TP3M:图像关键点配准新方法(ICRA'24)-CSDN博客
3、https://zhuanlan.zhihu.com/p/685860085
4、超全 | 基于纯视觉Multi-Camera的3D感知方法汇总!_multi-camera vision-CSDN博客















 5023
5023

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









