






参考博客: https://blog.csdn.net/weixin_44791964/article/details/125827160
参考知乎: https://www.zhihu.com/question/568070366/answer/3030899381
网络结构
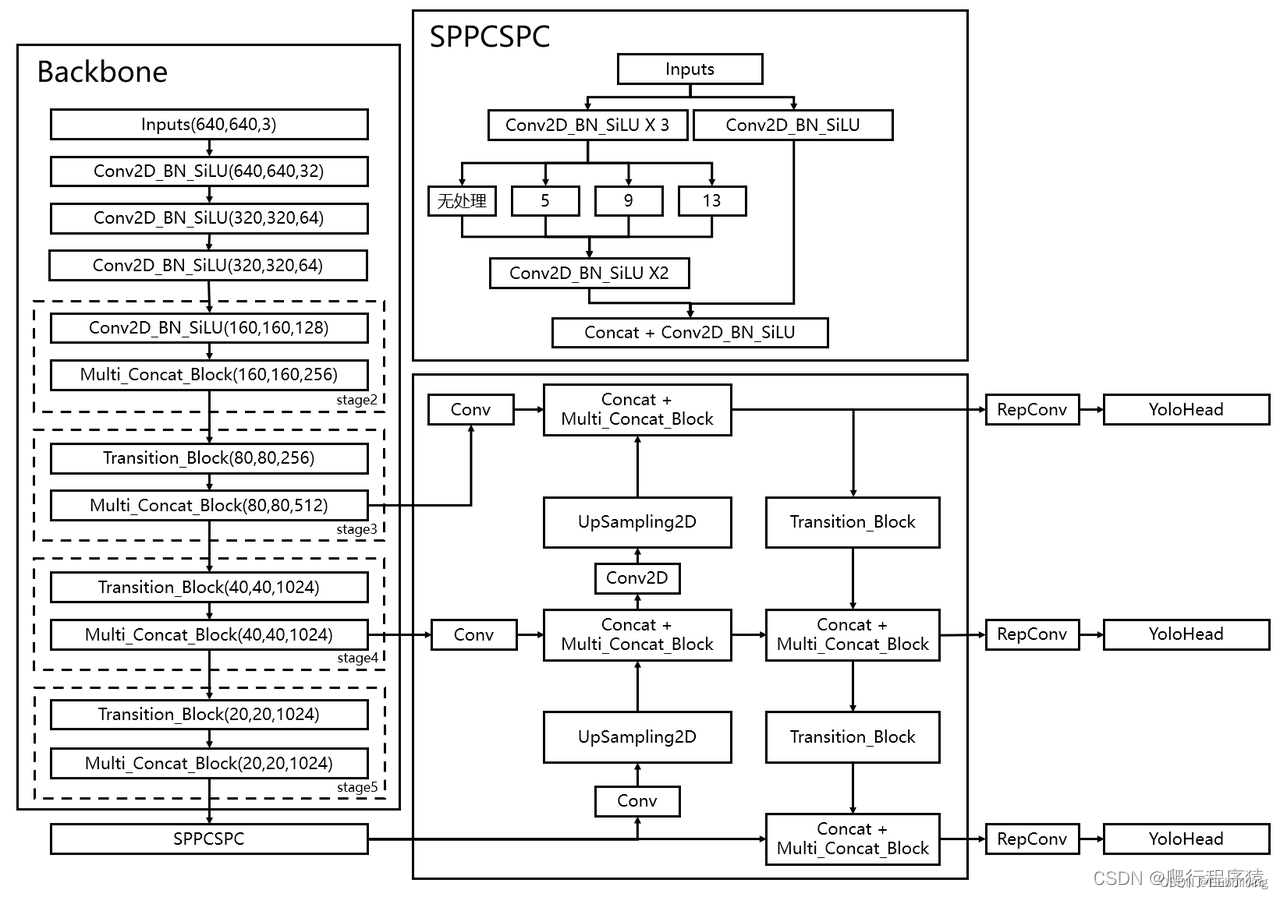
彩色图
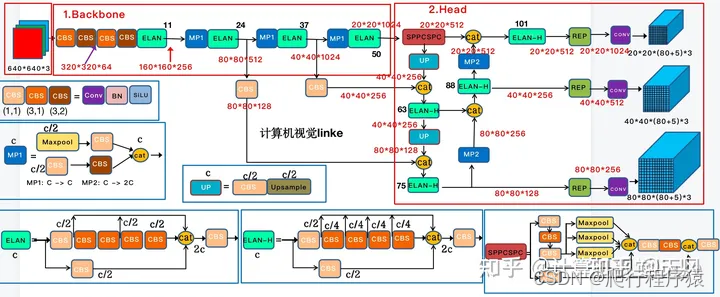
从网络结构上看和yolov3, yolov5 啥的相差不大,都是通过backbone,neck, head,最后输出三个feature map, 但里面的网络细节上有了不小的改动。最大的特点,据说是将vgg 又重新拉回舞台,能够使用较小的空间,拥有更快的速度和准确率。然后它里面使用的还是Anchor-base,没有像yolox 使用了Anchor-Free 。
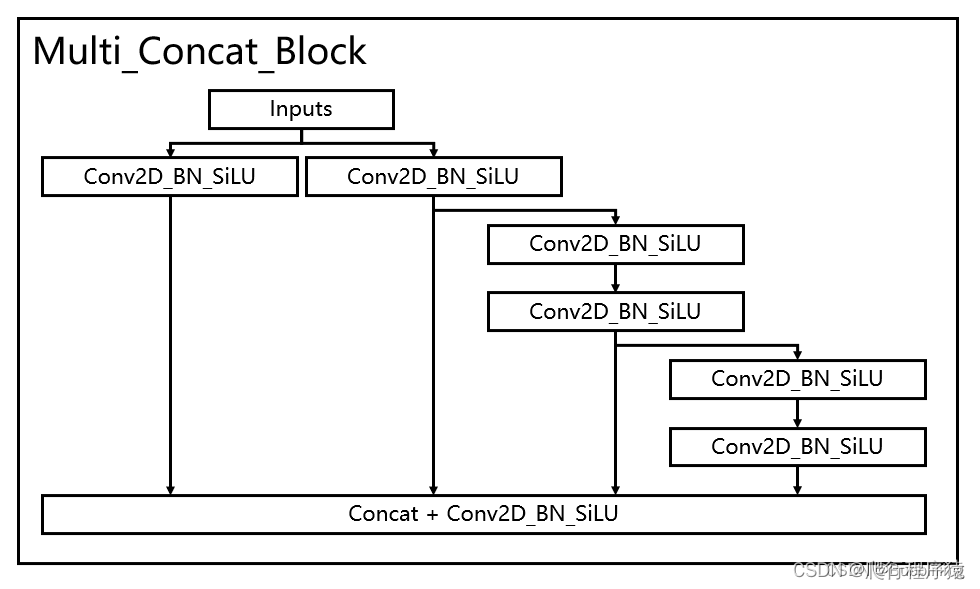
主干网络中,使用了ELAN,进行多分支融合
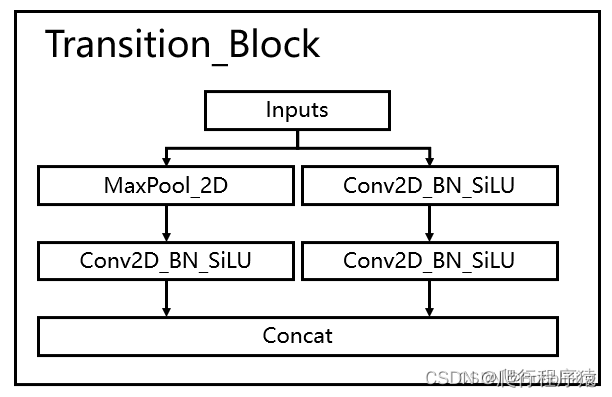
MP 中使用了池化操作和卷积下采样操作,然后将结果融合。
最后在head阶段,使用了REP

这个图的意思就是在训练阶段,使用多分支进行卷积,然后融合到一起;在预测部署的时候只采用中间的卷积输出。
损失函数 还是分为坐标损失,置信度损失,分类损失,其中目标置信度损失和分类损失采用BCEWithLogitsLoss(带log的二值交叉熵损失),坐标损失采用CIoU损失。
使用了SimOTA对预测的锚框与真实框进行匹配,从而选择最优的预测锚框进行训练与损失计算
步骤如下:
首先粗略匹配
-
根据训练集中【真实框】 通过k-mean算法,先验获得9个从小到大的排列的 anchor(与yolov5类似)
-
将每个【真实框】与得到的9个anchor 匹配: 分别计算【真实框】与这9个anchor 的宽高比(比较大的除以比较小的,比值大于1),得到两个比较值,取最大值,如果最大值小于阈值,就将这个anchor 框设置为正样本(正样本的意思就是说这个框里面有要检测的物体,负样本是说,有个框,但框里没有要检测的物体)。
精细匹配
-
找到【真实框】的中心位置,将最近的2个邻域网格也作为预测网格,也即一个【真实框】可以由3个网格来预测
-
取与当前【真实框】有top10最大iou的prediction结果。将这top10 (5-15之间均可,并不敏感)iou进行sum,就为当前gt的k。k最小取1。
-
根据损失函数计算每个【真实框】和候选anchor损失(前期会加大分类损失权重,后面减低分类损失权重,如1:5->1:3),并保留损失最小的前K个
-
去掉同一个anchor被分配到多个GT的情况。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









