







SSD借鉴了yolov1的one-stage思想,直接用一个神经网络对bbox进行目标分类和回归定位,同时也引入了Faster RCNN中的anchor机制来提升精度。
那么,针对yolov1精度低、定位不准、小目标检测差的问题,SSD做了哪些改进?
一 Model
创新点
1.多尺度特转图预测
因为不同size的feature map的感受野不同,可以检测不同大小的目标。较大的map,感受野小,适合检测相对较小的目标;较小的map,感受野大,适合检测相对较大的目标。(anchor的设计正是依据感受野)
在SSD中,比如一个8x8的map(如图)可以划分为更多的单元格,每个grid的anchor尺度较小,更适合检测小目标。(此处也表明了为什么map较大的,感受野较小)

而在4x4的map中,划分的单元格较少,每个grid的anchor尺度较大,更适合检测大目标。其中,anchor的设计要求,在初始标注ground truth时,需将gt的尺寸规格赋予map中一系列固定输出的bboxes中。
多尺度预测使得SSD相比于yolov1对小目标的检测更稳定,但是SSD本身对小目标的检测还是存在天然缺陷。为什么?
- 主要原因有以下2点:
(1)SSD对底层特征利用不充分;
SSD是一种全卷积的检测器,用不同层检测不同大小的目标,但是这中间存在一个矛盾点——底层map较大,分辨率更高,但语义信息不够丰富;深层的语义信息够了,但经过多次的pooling之后,map又太小了。 而检测小目标,既需要一张足够大的map来提供精细的特征和更加密集的采样,同时也需要足够的语义信息来与背景区分开。而在SSD中,负责检测小目标的底层特征语义信息不够丰富,之后又变得较小,其位置信息有较大的损失,导致之后对小目标的检测和回归无法满足要求。
(2)对anchor的设置不是很合理。
原因1所说的矛盾,如果卷积足够深,影响其实也没那么大。但在SSD中,作者设置检测小目标的anchor为0.2,对于一张720p的image,其最小检测尺寸就有144个像素,还是太大了。对于这一点,可以在相应特征层中生成不同尺度的anchor,基本能覆盖足够小的目标就可以,但此时anchor的数量就会增加,速度会降低。
2.采用卷积方式预测
yolov1最后采用FC层预测,SSD则是将6个不同尺度的map分别输入到两个3x3的卷积中进行结果预测,这样可以适用于各种size的image。
基础网络采用VGG作为backbone:

该架构中需要注意的几点:
- 将原来的FC6、FC7分别转换为3x3、1x1的卷积,并使用FC6、FC7的参数初始化卷积层。
- 将VGG中stride=2的2x2 pool5变换成stride=1的3x3 pool。
- 转换后的conv6的卷积采用的是dilation_rate=6的空洞卷积,用于弥补感受野。
最终的检测,SSD是将6个feature map分别输入到两个3x3的卷积操作中,classifier的卷积输出维度为:anchor_num x 21.
regressor的卷积输出维度为:anchor_num x 4.
3.Anchor的设计
以feature map上每个点的中心点来生成一系列同心的default boxes(然后,中心点的坐标会乘以step,相当于从map位置映射回原图位置)。使用6个不同大小的map来做预测,最低层的map的scale位置为Smin=0.2,最高层的为Smax=0.95,其它层通过以下公式进行设计:
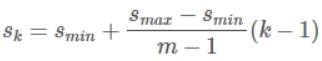
使用不同的ratio值,ar包括[1, 2, 3, 1/2, 1/3],通过下面的公式计算 default box 的宽度w和高度h:
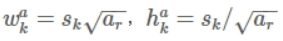
另外,每个格子还预测两个正方形default box为:
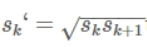
所以预测的6个框为:

二 Training
1.Default boxes匹配策略
在training时,需要将每个anchor与gt匹配,与gt匹配的anchor所对应的box负责预测目标。
在yolov1中,gt的中心落在哪个grid,该grid中与gt IoU最大的box负责预测,但在SSD中,SSD的anchor与gt的匹配策略原则主要有以下2点:
(1)对于每个gt,找到与其IoU最大的default box与其匹配,相匹配的anchor为正样本,反之为负样本。但是gt很少,anchor却很多,仅仅按照这一原则匹配,很多anchor会被划分为负样本,导致正负样本不平衡,所以还需要第二个原则;
(2)对于剩余的anchor,若与某个gt的IoU>0.5,那么该anchor也与这个gt匹配。这意味着gt可能与多个anchor匹配,这是可以的。但反过来则不行,一个anchor只能匹配一个gt。如果多个gt与某个anchor的IoU都大于0.5,那么anchor只与IoU最大的那个gt匹配。
2.难负例挖掘&数据增强
尽管一个gt可与多个anchor匹配,但是gt相对于anchor还是太少,所以负样本相比于正样本会很多。为保证正负样本平衡,SSD采用hard negative mining,对负样本抽样,按照置信度误差进行降序排列,选取置信度误差较大(预测背景的confidence越小,误差越大)的top-k作为训练的负样本。
SSD中,数据增强主要采用的技术有水平翻转、随机crop+颜色扭曲、随机采集块域等。
3.损失函数
SSD训练的目标函数源于Multi Box的目标函数,SSD对其进行了扩展,使其可以处理多个目标类别。
loss分为两部分:置信度误差(confidence loss)+位置误差(localization loss)。
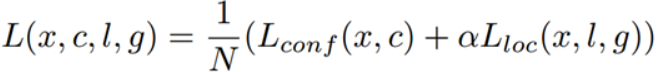
其中置信度误差采用的是softmax loss:
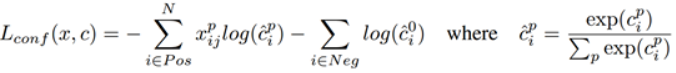
位置误差采用的是smooth L1 loss:
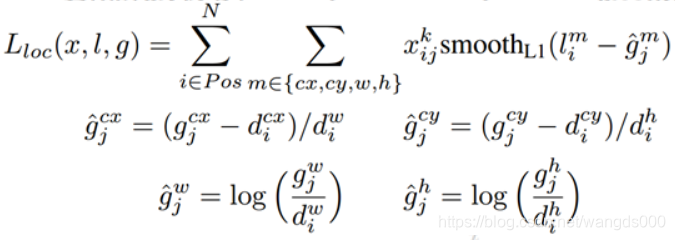















 439
439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









