









像之前我们讨论的大量强化学习方法(DQN, Double DQN, Priorized DQN, Policy Gradient, PPO等等)都是基于model-free的,这也是RL学习的主要优势之一,因为大部分情况下agent所处的环境会非常复杂,很难获得一个model。但是如果我们想学习一个environment模型,或者说是我们已经有一个environment模型,该如何利用这个environment来加快阿agent学习进程?这篇文章就一起探讨下学习处RL的environment模型。文章主要从以下3个方面来探讨:
- 如何给环境建模?
- 用基础理论(比如q-learning)实现一个简单例子。
- 将这个理论扩展到更一般的情况。
一个agent从一个state开始,在这个状态下通过某种策略选择一个可行的action进入到下一个state,同时环境会给一个反馈reward。一般化表示为:(state, action) -> (next_state, r)这样的一个映射关系。例如:在走迷宫的地图上,如果agent撞到了墙则下一个状态并不会变,获得的reward = 0,即:(state, action) -> (state, 0)。
算法概述
下面我们来看下如何利用environment的模型来加速我们的Q-learning. 这里我们采用Dyna-Q算法,算法步骤如下:

这个算法简单明了,前四步(a,b,c,d)和普通的q-learning算法那一模一样;只有第e和f稍微不同。在e中,environment的模型是基于确定环境下的假设(对于非确定的环境或者是非常复杂的环境根据特定的情况来做assumption),f步骤可以被概括为使用已经学习到的模型来更新Q函数n次。f步骤的最后一行算法和d步骤的一模一样。此外,在Dyna-Q中同样的强化学习方法既可以用于从实际经验中学习也可以用于从模拟经验中进行规划,因此强化学习方法是学习和规划(planning)的最终共同道路。
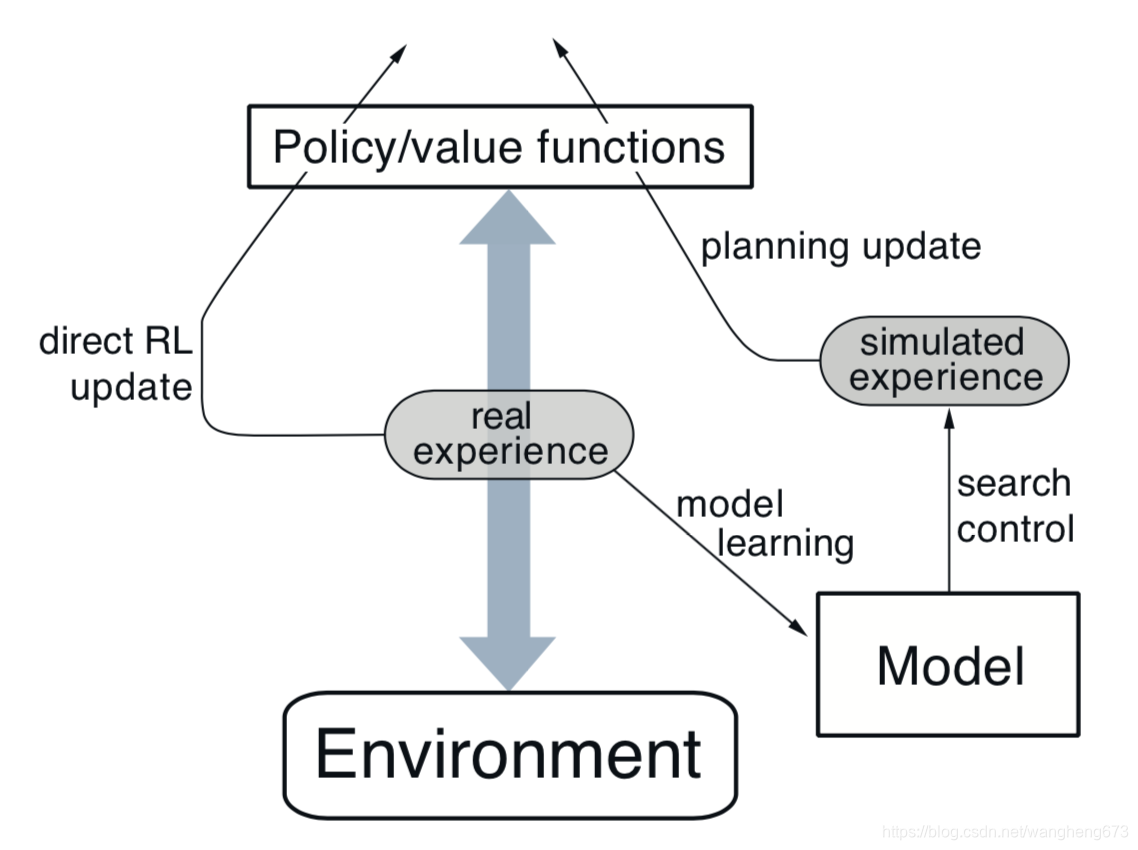
上图为Dyna-Q的结构。我们不难发现有两个向上的箭头指向 Policy/value functions,也就是我们这篇文章中说的Q function,左边的箭头是RL直接从实际的经验对Q进行更新,右边的更新Q箭头是从模拟经验进行的规划更新。由此可见,每当agent采取一个action时,学习的进程同时通过实际的选择的action和环境模型的模拟来更新,这样就能够加快我们智能体的学习速度。下面我们使用python对Dyna-Q算法进行实现。
算法实现
借助python tkinker库进行绘制maze:
具体代码实现参考我的github: https://github.com/deepBrainWH/MLAlgorithm/blob/master/reinforcement_learning/Dyna-q/maze_env.py

红色的是我们的agent,黄色的是目标点,黑色的是墙。现在我们要训练agent使其能够学习到从起点绕开黑色的墙到达我们的重点区域。
RL算法:https://github.com/deepBrainWH/MLAlgorithm/blob/master/reinforcement_learning/Dyna-q/dyna_q_brain.py
def learn(self):
self.steps_per_episode = []
for ep in range(self.episodes):
while not self.maze.end:
action_index = self.choose_action()
self.state_actions.append((self.state, action_index))
nxtState, reward = self.maze.step(action_index)
# update Q-value
self.Q_values[self.state][action_index] += self.lr * (reward + np.max(list(self.Q_values[nxtState].values())) - self.Q_values[self.state][action])
# update model
if self.state not in self.model.keys():
self.model[self.state] = {}
self.model[self.state][action_index] = (reward, nxtState)
self.state = nxtState
# loop n times to randomly update Q-value
for _ in range(self.steps):
# randomly choose an state
rand_idx = np.random.choice(range(len(self.model.keys())))
_state = list(self.model)[rand_idx]
# randomly choose an action
rand_idx = np.random.choice(range(len(self.model[_state].keys())))
_action = list(self.model[_state])[rand_idx]
_reward, _nxtState = self.model[_state][_action]
self.Q_values[_state][_action] += self.lr * (_reward + np.max(list(self.Q_values[_nxtState].values())) - self.Q_values[_state][_action])
# end of game
if ep % 10 == 0:
print("episode", ep)
self.steps_per_episode.append(len(self.state_actions))
self.reset()算法的主体代码参考上面,非常简单,详细琢磨两遍即可理解,这里就不在过多赘述。
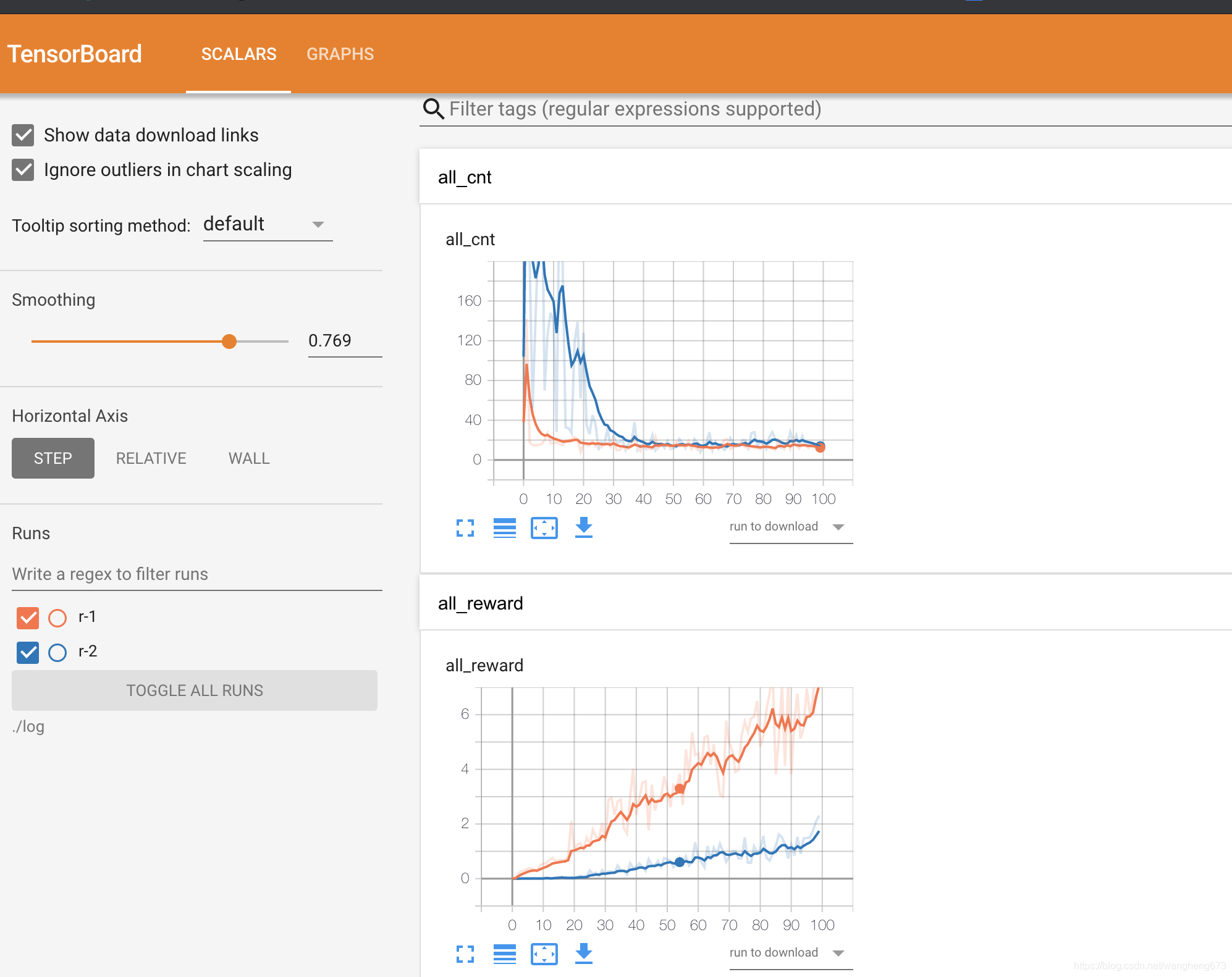
上图是我在maze_env下面做的实验结果, 蓝色的是普通的Q-Learning, 黄色的是Dyna-Q, all_cnt图是完成一轮探索要走多少步, all_reward是进行一轮训练, 平均reward.

















 16
16

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









