







读在前面:
三元量化中的 group 方法是指,通过逐渐增加全精度权重量化的比例来减小量化带来的误差。量化误差可以表达为:
∥
y
−
x
⊤
w
∥
2
2
≤
∥
y
−
x
⊤
(
r
w
+
(
1
−
r
)
Q
(
w
)
)
∥
2
2
≤
∥
y
−
x
⊤
Q
(
w
)
∥
2
2
,
\begin{gathered} \|\mathbf{y}-\mathbf{x}^{\top}\mathbf{w}\|_{2}^{2} \leq\|\mathbf{y}-\mathbf{x}^{\top}(r\mathbf{w}+(1-r)\mathbb{Q}(\mathbf{w}))\|_{2}^{2} \\ \leq\|\mathbf{y}-\mathbf{x}^{\top}\mathbb{Q}(\mathbf{w})\|_{2}^{2}, \end{gathered}
∥y−x⊤w∥22≤∥y−x⊤(rw+(1−r)Q(w))∥22≤∥y−x⊤Q(w)∥22,其中,
r
r
r 控制着量化的比例。
本博客中文献笔记总结:
| 文献索引 | 量化精度 | 缩放因子求解 | 量化损失函数定义 | 增加精度方式 | 适用算法 |
|---|---|---|---|---|---|
| 一 | 多bit( 2 2 2的幂次) | \ | E ( W l ) = L ( W l ) + λ R ( W l ) E(\mathbf{W}_l)=L(\mathbf{W}_l)+\lambda R(\mathbf{W}_l) E(Wl)=L(Wl)+λR(Wl) | 重训练 | CNN(all) |
| 二 | 2/3 bit | α l = m e a n ( W l ) + β m a x ( W l ) , β = 0.05 \alpha_{l}=mean(W_{l})+\beta max(W_{l}),\\\beta=0.05 αl=mean(Wl)+βmax(Wl),β=0.05 | L ( W l ) + a 1 L p ( W l , W l ^ ) + a 2 E ( W l , W l ^ ) L(W_l)+a_1L_p(W_l,\widehat{W_l})+a_2E(W_l,\widehat{W_l}) L(Wl)+a1Lp(Wl,Wl )+a2E(Wl,Wl ) | 重写量化损失+重训练 | DNN |
| 三 | \ | \ | \ | 重训练 | all |
| 四 | 多bit | 最小二乘法求解 | E x ∼ N ( 0 , 1 ) , x > ϵ [ ( Q ϵ ( x ) − x ) 2 ] , 利用稀疏度 ϵ E_{x\sim\mathcal{N}(0,1),x>\epsilon}[(Q_\epsilon(x)-x)^2], \text{利用稀疏度}\epsilon Ex∼N(0,1),x>ϵ[(Qϵ(x)−x)2],利用稀疏度ϵ ∑ { α i } , { w ^ i T } ∥ y i T − Q ϵ ( α i w ^ i T X ) ∥ 2 2 \sum_{\{\alpha_i\},\{\hat{w}_i^T\}}\parallel y_i^T-Q_\epsilon(\alpha_i\hat{w}_i^TX)\parallel_2^2 ∑{αi},{w^iT}∥yiT−Qϵ(αiw^iTX)∥22 | 解耦量化“权重”和“激活” | DNN |
| 五 | 3 bit | α ∗ = ( ∑ i ∈ I Δ ∣ W i ∣ ) / ∣ I Δ ∣ \alpha^{*}=(\sum_{i\in I_{\Delta}}\vert\mathbf{W}_{i}\vert)/\vert I_{\Delta}\vert α∗=(∑i∈IΔ∣Wi∣)/∣IΔ∣ | ∑ i argmin α i , W ^ ( i ) ∣ W ( i ) − α i W ^ ( i ) ∣ F 2 \sum_{i}\underset{\alpha_{i},\hat{\mathbf{W}}^{(i)}}{\operatorname*{argmin}}|\mathbf{W}^{(i)}-\alpha_{i}\hat{\mathbf{W}}^{(i)}|_{F}^{2} ∑iαi,W^(i)argmin∣W(i)−αiW^(i)∣F2 | 分组解析分析 | all |
| 六 | 3 bit | 向后传播动态得到 | \ | pixel-wise和row-wise两种分组方式 | DNN(CNN) |
| 七 | 3 bit | NP问题,贪心策略 | minimize { x i } , { d i } , { y i } ∥ W − ∑ i k d i x i y i T ∥ F 2 \underset{{\{x_i\},\{d_i\},\{y_i\}}}{\operatorname{minimize}}\parallel W-\sum_i^kd_ix_iy_i^T\parallel_F^2 {xi},{di},{yi}minimize∥W−∑ikdixiyiT∥F2 | 权重矩阵的不动点分解 | all |
下面是如下这篇综述中关于“Weight Grouping”部分引用文献的笔记:
作者综述笔记:Ternary Quantization: A Survey
原文链接:Ternary Quantization: A Survey
一、INCREMENTAL NETWORK QUANTIZATION: TOWARDS LOSSLESS CNNS WITH LOW-PRECISION WEIGHTS
Zhou A, Yao A, Guo Y, et al. Incremental network quantization: Towards lossless cnns with low-precision weights[J]. arXiv preprint arXiv:1702.03044, 2017.
ICLR 2017(此会虽无CCF等级,但是是人工智能顶会)
1. 动机和贡献
动机: 虽然 CNN 的量化已经取得了一些进步,但是依然面临着两个重要的问题:
- CNN量化过程中不可避免的精度损失;
- 与全精度权重训练模型相比,量化后模型需要增加更多轮数使得模型收敛。
贡献: 本文提出一种 incremental network quantization(INQ)CNN量化框架,在没有对CNN结构做出任何限制性假设的前提下,可以有效地将已经预训练好的全精度CNN模型(例如:32bit)转化为低精度模型(权重值限制到 2 2 2 的幂次或者是 0 0 0)。相比于其他一次性将全部权重都进行量化的技术,本文通过考虑不同网络权重的重要程度不同,对其进行分批次的量化,主要包括如下几个步骤:
- weight partition:将全精度权重分为两个互不相交的 “组group”;
- group-wise quantization:将一个组中的权重量化,另一个组保持不变;
- re-training:固定已量化后的组中的值,重新训练模型,改变另一个组中的值。
注:本文中将权重量化为 2 2 2 的幂次或者是 0 0 0的目的是:将全精度权重的浮点数乘法运算变成二进制移位运算,以达到降低计算复杂度的作用。
2. 算法表示
2.2 weight partition
对于第
l
l
l 层, weight partition 可以定义为:
A
l
(
1
)
∪
A
l
(
2
)
=
{
W
l
(
i
,
j
)
}
,
a
n
d
A
l
(
1
)
∩
A
l
(
2
)
=
∅
,
\mathbf{A}_{l}^{(1)}\cup\mathbf{A}_{l}^{(2)}=\{\mathbf{W}_{l}(i,j)\},\mathrm{and}~\mathbf{A}_{l}^{(1)}\cap\mathbf{A}_{l}^{(2)}=\emptyset,
Al(1)∪Al(2)={Wl(i,j)},and Al(1)∩Al(2)=∅,同时定义一个二元矩阵
T
l
(
i
,
j
)
\mathbf{T}_l(i,j)
Tl(i,j) 作为掩码,即:
{
T
l
(
i
,
j
)
=
0
if
W
l
(
i
,
j
)
∈
A
l
(
1
)
T
l
(
i
,
j
)
=
1
if
W
l
(
i
,
j
)
∈
A
l
(
2
)
\left\{\begin{matrix} \mathbf{T}_l(i,j)=0 & \text{if}~\mathbf{W}_l(i,j)\in\mathbf{A}_l^{(1)}\\ \mathbf{T}_l(i,j)=1 & \text{if}~\mathbf{W}_l(i,j)\in\mathbf{A}_l^{(2)} \end{matrix}\right.
{Tl(i,j)=0Tl(i,j)=1if Wl(i,j)∈Al(1)if Wl(i,j)∈Al(2)
对于分组策略,本文中提出了两种方案:
- random partition:随机的将待分权重分成不相交的两个组;
- pruning-inspired partition:给一个以层为单位的阈值,绝对值大于此阈值的权重更有可能被分到同一组进行量化。(原因是:本文认为绝对值大的权重要性更大)
2.2 group-wise quantization: 使用变长编码的权重量化
假设 CNN 模型的权重可以表示为
{
W
l
:
1
≤
l
≤
L
}
\{{\mathbf{W}}_{l}:1\leq l\leq L\}
{Wl:1≤l≤L},其中
W
l
{\mathbf{W}}_{l}
Wl 表示第
l
l
l 层权重值集合,
L
L
L 表示总层数;量化后低精度模型权重表示为
w
^
l
\widehat{\mathbf{w}}_{l}
w
l,它的每一个元素取值都从集合
P
l
\mathbf{P}_l
Pl 中选取:
P
l
=
{
±
2
n
1
,
⋯
,
±
2
n
2
,
0
}
,
\mathbf{P}_l=\{\pm2^{n_1},\cdots,\pm2^{n_2},0\},
Pl={±2n1,⋯,±2n2,0},其中,
n
1
≥
n
2
n_1\geq n_2
n1≥n2 是两个整数。
INQ 的量化规则为:
W
^
l
(
i
,
j
)
=
{
β
sgn
(
W
l
(
i
,
j
)
)
if
(
α
+
β
)
/
2
≤
abs
(
W
l
(
i
,
j
)
)
<
3
β
/
2
0
otherwise
,
\widehat{\mathbf{W}}_l(i,j)=\begin{cases}\beta\text{sgn}(\mathbf{W}_l(i,j))&\text{if}~(\alpha+\beta)/2\leq\text{abs}(\mathbf{W}_l(i,j))<3\beta/2\\0&\text{otherwise},\end{cases}
W
l(i,j)={βsgn(Wl(i,j))0if (α+β)/2≤abs(Wl(i,j))<3β/2otherwise,其中,
α
,
β
\alpha,\beta
α,β 表示集合
P
l
\mathbf{P}_l
Pl 中的相邻的两个元素。那么,如何得到集合
P
l
\mathbf{P}_l
Pl 中的元素,即得到
n
1
,
n
2
n_1,n_2
n1,n2 的值?首先,定义
n
1
n_1
n1 的取值为:
n
1
=
floor
(
log
2
(
4
s
/
3
)
)
,
n_1=\text{floor}(\log_2(4s/3)),
n1=floor(log2(4s/3)),其中,
s
=
max
(
abs
(
W
l
)
)
.
s=\max(\operatorname{abs}(\mathbf{W}_{l})).
s=max(abs(Wl)).因此,当确定量化维数
b
b
b 后,可以得到
n
2
n_2
n2 的值为:
n
2
=
n
1
+
1
−
2
(
b
−
1
)
2
,
n_2=n_1+1-\frac{2^{(b-1)}}{2},
n2=n1+1−22(b−1),下图是关于上述量化过程的一个示意图:

2.3 re-training
根据上面描述,重训练需要优化的如下目标函数:
min
W
l
E
(
W
l
)
=
L
(
W
l
)
+
λ
R
(
W
l
)
s.t.
W
l
(
i
,
j
)
∈
P
l
,
if
T
l
(
i
,
j
)
=
0
,
1
≤
l
≤
L
,
\begin{array}{rl}\min\limits_{\mathbf{W}_l}&E(\mathbf{W}_l)=L(\mathbf{W}_l)+\lambda R(\mathbf{W}_l)\\\text{s.t.}&\mathbf{W}_l(i,j)\in\mathbf{P}_l,\text{if}~\mathbf{T}_l(i,j)=0,1\le l\le L,\end{array}
Wlmins.t.E(Wl)=L(Wl)+λR(Wl)Wl(i,j)∈Pl,if Tl(i,j)=0,1≤l≤L,其中,
L
(
W
l
)
L(\mathbf{W}_l)
L(Wl) 表示网络损失函数,
R
(
W
l
)
R(\mathbf{W}_l)
R(Wl) 表示正则项。因此,可以得到如下重训练规则:
W
l
(
i
,
j
)
←
W
l
(
i
,
j
)
−
γ
∂
E
∂
(
W
l
(
i
,
j
)
)
T
l
(
i
,
j
)
,
\mathbf{W}_l(i,j)\leftarrow\mathbf{W}_l(i,j)-\gamma\frac{\partial E}{\partial(\mathbf{W}_l(i,j))}\mathbf{T}_l(i,j),
Wl(i,j)←Wl(i,j)−γ∂(Wl(i,j))∂ETl(i,j),
综上,总算法流程图为:

二、Explicit Loss-Error-Aware Quantization for Low-Bit Deep Neural Networks
Zhou, Aojun, et al. “Explicit loss-error-aware quantization for low-bit deep neural networks.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
CVPR 2018 CCF-A
1. 动机和贡献
动机: 现有关于DNN的二元/三元压缩存在测试精度低的问题,可能原因包括:
- 通过最小化 原始模型和量化后模型的差异 或者 输入与原始模型内积和输入与量化模型内积 这两种方式之一来量化模型;
- 很多策略都是一次性全部量化模型。
贡献: 本文提出一种基于最小化损失函数的量化技术(ELQ)来解决上述问题:
- 首先,同时考虑了 “近似误差” 和 “损失扰动” 的影响;
- 然后,通过增强策略,逐步量化模型参数(仿照“一”中思想)。
2. 主要算法
2.1 预备知识
向量函数的Taylor公式:
带积分余项的泰勒公式
0阶:
f
(
x
)
=
f
(
x
0
)
+
⟨
∫
0
1
∇
f
(
x
0
+
θ
(
x
−
x
0
)
)
d
θ
,
x
−
x
0
⟩
f(x)=f(x_0)+\left\langle\int_0^1\nabla f(x_0+\theta(x-x_0))\mathrm{d}\theta,x-x_0\right\rangle
f(x)=f(x0)+⟨∫01∇f(x0+θ(x−x0))dθ,x−x0⟩
1阶:
f
(
x
)
=
f
(
x
0
)
+
⟨
∇
f
(
x
0
)
,
x
−
x
0
⟩
+
⟨
∫
0
1
∇
2
f
(
x
0
+
θ
(
x
−
x
0
)
)
(
1
−
θ
)
d
θ
(
x
−
x
0
)
,
x
−
x
0
⟩
\begin{aligned} f(x)&=f(x_0)+\langle\nabla f(x_0),x-x_0\rangle \\ &+\left\langle\int_{0}^{1}\nabla^{2}f(x_{0}+\theta(x-x_{0}))(1-\theta)\mathrm{d}\theta(x-x_{0}),x-x_{0}\right\rangle \end{aligned}
f(x)=f(x0)+⟨∇f(x0),x−x0⟩+⟨∫01∇2f(x0+θ(x−x0))(1−θ)dθ(x−x0),x−x0⟩
带Lagrange余项的泰勒公式
0阶:
f
(
x
)
=
f
(
x
0
)
+
⟨
∇
f
(
ξ
)
,
x
−
x
0
⟩
f(x)=f(x_0)+\langle\nabla f(\xi),x-x_0\rangle
f(x)=f(x0)+⟨∇f(ξ),x−x0⟩
1阶:
f
(
x
)
=
f
(
x
0
)
+
⟨
∇
f
(
x
0
)
,
x
−
x
0
⟩
+
1
2
⟨
∇
2
f
(
ξ
)
(
x
−
x
0
)
,
x
−
x
0
⟩
f(x)=f(x_0)+\langle\nabla f(x_0),x-x_0\rangle+\frac{1}{2}\left\langle\nabla^2f(\xi)(x-x_0),x-x_0\right\rangle
f(x)=f(x0)+⟨∇f(x0),x−x0⟩+21⟨∇2f(ξ)(x−x0),x−x0⟩
带Peano余项的泰勒公式
0阶:
f
(
x
)
=
f
(
x
0
)
+
o
(
1
)
f(x)=f(x_0)+o(1)
f(x)=f(x0)+o(1)
1阶:
f
(
x
)
=
f
(
x
0
)
+
⟨
∇
f
(
x
0
)
,
x
−
x
0
⟩
+
o
(
∥
x
−
x
0
∥
)
f(x)=f(x_0)+\langle\nabla f(x_0),x-x_0\rangle+o(\|x-x_0\|)
f(x)=f(x0)+⟨∇f(x0),x−x0⟩+o(∥x−x0∥)
2阶:
f
(
x
)
=
f
(
x
0
)
+
⟨
∇
f
(
x
0
)
,
x
−
x
0
⟩
+
1
2
⟨
∇
2
f
(
x
0
)
(
x
−
x
0
)
,
x
−
x
0
⟩
+
o
(
∥
x
−
x
0
∥
2
)
\begin{gathered}f(x)=f(x_0)+\langle\nabla f(x_0),x-x_0\rangle+\frac{1}{2}\big\langle\nabla^2f(x_0)(x-x_0),x-x_0\big\rangle\\+o(\|x-x_0\|^2)\end{gathered}
f(x)=f(x0)+⟨∇f(x0),x−x0⟩+21⟨∇2f(x0)(x−x0),x−x0⟩+o(∥x−x0∥2)
其中,
⟨
x
,
y
⟩
\langle x,y\rangle
⟨x,y⟩表示
x
x
x 和
y
y
y 的内积(i.e. 若
x
,
y
∈
R
d
x,y\in\mathbb{R}^d
x,y∈Rd,则
⟨
x
,
y
⟩
=
x
T
y
\langle x,y\rangle=x^Ty
⟨x,y⟩=xTy);
∥
x
∥
\|x\|
∥x∥ 表示
x
x
x 的范数,
∥
x
∥
=
⟨
x
,
x
⟩
\|x\|=\sqrt{\langle x,x\rangle}
∥x∥=⟨x,x⟩。
2.2 基本 ELQ
首先,定义本文中量化函数的形式为:
Q
l
=
{
α
l
c
k
∣
1
≤
k
≤
K
}
{Q_{l}}=\{\alpha_{l}c_{k}|{1}\leq k\leq K\}
Ql={αlck∣1≤k≤K}其中,
L
L
L表示量化中心的总个数;
α
l
\alpha_l
αl 表示按层收缩因子;
c
k
c_k
ck 表示一个正整数。例如,二元量化中,
K
=
2
,
c
k
∈
{
−
1
,
+
1
}
K=2,c_k\in\{-1,+1\}
K=2,ck∈{−1,+1};三元量化中,
K
=
3
,
c
k
∈
{
−
1
,
0
,
+
1
}
K=3,c_k\in\{-1,0,+1\}
K=3,ck∈{−1,0,+1}。
然后,为了联合考虑“近似误差”和“损失扰动”的影响,ELQ算法中重新定义了优化问题,即:
min
W
l
^
L
(
W
l
)
+
a
1
L
p
(
W
l
,
W
l
^
)
+
a
2
E
(
W
l
,
W
l
^
)
s.t.
W
l
^
∈
{
α
l
c
k
∣
1
≤
k
≤
K
}
,
1
≤
l
≤
L
\begin{array}{ll}\min_{\widehat{W_l}}&L(W_l)+a_1L_p(W_l,\widehat{W_l})+a_2E(W_l,\widehat{W_l})\\\\\text{s.t.}&\widehat{W_l}\in\{\alpha_lc_k|1\le k\le K\},1\le l\le L\end{array}
minWl
s.t.L(Wl)+a1Lp(Wl,Wl
)+a2E(Wl,Wl
)Wl
∈{αlck∣1≤k≤K},1≤l≤L其中,
L
L
L 表示全精度模型的损失函数;
L
p
L_p
Lp 表示全精度模型和量化模型损失的差异;
E
E
E 表示全精度模型和量化模型的近似差异;
a
1
,
a
2
∈
R
+
a_1,a_2\in\mathbb{R}^+
a1,a2∈R+ 表示两个正则化系数。特别的,定义函数
L
p
,
E
L_p,E
Lp,E 如下:
L
p
(
W
l
,
W
l
^
)
=
∣
L
(
W
l
)
−
L
(
W
l
^
)
∣
=
(
a
)
∣
∂
L
∂
(
W
l
)
∣
δ
,
E
(
W
l
,
W
l
^
)
=
∣
∣
W
l
−
W
l
^
∣
∣
2
.
\begin{aligned} L_p(W_l,\widehat{W_l})&=|L(W_l)-L(\widehat{W_l})|\overset{(a)}{=}|\frac{\partial L}{\partial(W_{l})}|\delta,\\ E(W_l,\widehat{W_l})&=||W_{l}-\widehat{W_{l}}||^{2}. \end{aligned}
Lp(Wl,Wl
)E(Wl,Wl
)=∣L(Wl)−L(Wl
)∣=(a)∣∂(Wl)∂L∣δ,=∣∣Wl−Wl
∣∣2.其中,等式
=
(
a
)
\overset{(a)}{=}
=(a) 成立是由于:对函数
L
p
L_p
Lp 在
W
l
W_l
Wl 处进行1阶Taylor展开,得到:
L
p
(
W
l
,
W
^
l
)
=
∣
L
(
W
l
)
−
L
(
W
l
)
−
∂
L
∂
(
W
l
)
(
W
l
^
−
W
l
)
∣
=
∣
∂
L
∂
(
W
l
)
(
W
l
−
W
l
^
)
∣
=
∣
∂
L
∂
(
W
l
)
∣
δ
,
\begin{aligned} L_{p}(W_{l},\widehat{W}_{l})& =|L(W_{l})-L(W_{l})-\frac{\partial L}{\partial(W_{l})}(\widehat{W_{l}}-W_{l})| \\ &=|\frac{\partial L}{\partial(W_{l})}(W_{l}-\widehat{W_{l}})| \\ &=|\frac{\partial L}{\partial(W_{l})}|\delta, \end{aligned}
Lp(Wl,W
l)=∣L(Wl)−L(Wl)−∂(Wl)∂L(Wl
−Wl)∣=∣∂(Wl)∂L(Wl−Wl
)∣=∣∂(Wl)∂L∣δ,其中,
δ
=
∣
W
l
−
W
l
^
∣
\delta=|W_{l}-\widehat{W_{l}}|
δ=∣Wl−Wl
∣。
为了简单起见,本文中假设一个线性关系
∂
L
∂
(
W
l
)
∝
δ
\frac{\partial L}{\partial(W_{l})}\propto\delta
∂(Wl)∂L∝δ。因此,得到全精度模型的更新规则是:
W
l
t
=
W
l
t
−
1
−
γ
∂
L
∂
(
W
l
t
−
1
)
−
λ
s
i
g
n
(
W
l
t
−
1
−
W
l
^
t
−
1
)
,
\begin{aligned}W_l^t=W_l^{t-1}-\gamma\frac{\partial L}{\partial(W_l^{t-1})}-\lambda sign(W_l^{t-1}-\widehat{W_l}^{t-1}),\end{aligned}
Wlt=Wlt−1−γ∂(Wlt−1)∂L−λsign(Wlt−1−Wl
t−1),
最后,定义量化函数
Q
l
Q_l
Ql 中的收缩因子
α
l
\alpha_l
αl 为:
α
l
=
m
e
a
n
(
W
l
)
+
β
m
a
x
(
W
l
)
,
\alpha_{l}=mean(W_{l})+\beta max(W_{l}),
αl=mean(Wl)+βmax(Wl),其中,
β
=
0.05
\beta=0.05
β=0.05表示超参,根据实验所得。那么可以定义二元/三元量化函数为:
W
l
^
=
{
α
l
if
W
l
≥
0
−
α
l
otherwise
,
W
l
^
=
{
α
l
if
W
l
>
0.5
α
l
−
α
l
if
W
l
<
−
0.5
α
l
0
otherwise
.
\begin{matrix} \widehat{W_l}=\begin{cases}\alpha_l&\text{if}~W_l\geq0\\-\alpha_l&\text{otherwise},\end{cases} & \widehat{W_l}=\begin{cases}\alpha_l&\text{if}~W_l>0.5\alpha_l\\-\alpha_l&\text{if}~W_l<-0.5\alpha_l\\0&\text{otherwise}.\end{cases} \end{matrix}
Wl
={αl−αlif Wl≥0otherwise,Wl
=⎩
⎨
⎧αl−αl0if Wl>0.5αlif Wl<−0.5αlotherwise.
注:本文没有介绍阈值
Δ
\Delta
Δ的介绍,只是定义
Δ
=
0
\Delta=0
Δ=0或者
Δ
=
±
0.5
α
l
\Delta=\pm0.5\alpha_l
Δ=±0.5αl。
2.3 ELQ和增量策略的结合
仿照 “一” 中的思想,本文采取逐步量化的策略,即分为 “模型分类、模型量化、重训练” 三个步骤。那么全精度模型的更新规则修改为:
W
l
t
=
W
l
t
−
1
−
γ
∂
L
∂
(
W
l
t
−
1
)
⊙
T
l
−
λ
s
i
g
n
(
W
l
t
−
1
−
W
l
^
t
−
1
)
⊙
T
l
W_l^t=W_l^{t-1}-\gamma\frac{\partial L}{\partial(W_l^{t-1})}\odot T_l-\lambda sign(W_l^{t-1}-\widehat{W_l}^{t-1})\odot T_l
Wlt=Wlt−1−γ∂(Wlt−1)∂L⊙Tl−λsign(Wlt−1−Wl
t−1)⊙Tl其中,矩阵
T
l
T_l
Tl定义为:
T
l
=
{
0
if
W
l
⊙
T
l
∈
W
a
,
1
if
W
l
⊙
T
l
∈
W
b
,
W
a
∪
W
b
=
W
l
a
n
d
W
a
∩
W
b
=
∅
.
\begin{matrix} T_l=\begin{cases}0&\text{if }W_l\odot T_l\in W_a,\\1&\text{if }W_l\odot T_l\in W_b,\end{cases} & W_a\cup W_b=W_l~\mathrm{and}~W_a\cap W_b=\emptyset. \end{matrix}
Tl={01if Wl⊙Tl∈Wa,if Wl⊙Tl∈Wb,Wa∪Wb=Wl and Wa∩Wb=∅.
与 “一” 中的不同点在于 “模型量化” 上。其核心思想是:当权重的训练越靠近量化权重中心时(例如对于三元量化,有3个量化权重中心,
−
α
,
0
,
+
α
-\alpha,0,+\alpha
−α,0,+α),将更加有利于重训练过程;因此,本文将远离量化权重中心的值量化为中心点,然后进行重训练。这会带来一个问题:如何判断哪些值时远离量化权重中心的呢?本文定义了interval bound factor
{
σ
n
∈
[
0
,
1
]
∣
1
≤
n
≤
N
}
\{\sigma_{n}\in[0,1]|1\leq n\leq N\}
{σn∈[0,1]∣1≤n≤N}来进行确定。另外,本文根据经验对三元量化选择
{
σ
1
=
0.5
,
σ
2
=
0.4
,
σ
3
=
0.3
,
σ
4
=
0.2
,
σ
5
=
0.15
,
σ
6
=
0.1
,
σ
7
=
0.05
,
σ
8
=
0
}
\{\sigma_{1}=0.5,\sigma_{2}=0.4,\sigma_{3}=0.3,\sigma_{4}=0.2,\sigma_5=0.15,\sigma_6=0.1,\sigma_7=0.05,\sigma_8=0\}
{σ1=0.5,σ2=0.4,σ3=0.3,σ4=0.2,σ5=0.15,σ6=0.1,σ7=0.05,σ8=0},文中给出一个示例:
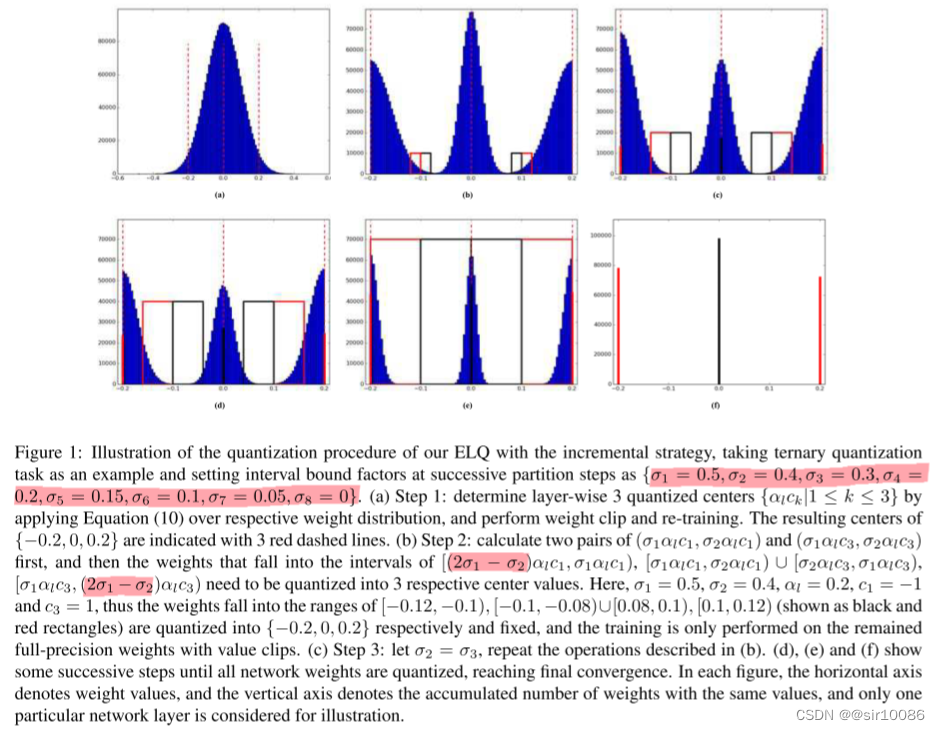
综上,得出ELQ算法流程为:

3. 讨论
本文主要创新点如下:
- 通过综合考虑之前成果中的 近似误差和损失扰动,来重写损失函数,以增加量化后模型的测试精度
- 模仿 “一” 中的增量量化策略,但修改了分组策略:将远离权重中心点的值最为量化的一组,其余的作为固定的一组,然后精心重训练
缺点如下:
- 没有详细解释量化函数中的阈值 Δ \Delta Δ,而是直接定义 Δ = 0 \Delta=0 Δ=0或者 Δ = ± 0.5 α l \Delta=\pm0.5\alpha_l Δ=±0.5αl
- 对新提出的分组策略没有详尽地介绍,即如何得到interval bound factor σ \sigma σ 的取值
三、RPR: Random partition relaxation for training; Binary and ternary weight neural networks
Cavigelli L, Benini L. RPR: Random partition relaxation for training; Binary and ternary weight neural networks[J]. arXiv preprint arXiv:2001.01091, 2020.
arXiv 2020
本文中心思想为:将待量化的权重
W
q
\mathbb{W}_q
Wq 按照 冻结因子
F
F
=
W
q
c
o
n
s
t
r
W
q
∈
[
0
,
1
]
FF=\frac{\mathbb{W}_q^{constr}}{\mathbb{W}_q}\in[0,1]
FF=WqWqconstr∈[0,1] 随机分为
W
q
c
o
n
s
t
r
\mathbb{W}_q^{constr}
Wqconstr 和
W
q
r
e
l
a
x
e
d
\mathbb{W}_q^{relaxed}
Wqrelaxed。首先,选择一个
F
F
FF
FF 的值,将
W
q
c
o
n
s
t
r
\mathbb{W}_q^{constr}
Wqconstr 中的权重量化,然后重训练修改
W
q
r
e
l
a
x
e
d
\mathbb{W}_q^{relaxed}
Wqrelaxed,最后重新将为量化之前的
W
q
c
o
n
s
t
r
\mathbb{W}_q^{constr}
Wqconstr 值代入。重复上述过程,直到
F
F
=
1
FF=1
FF=1 时模型依旧可以收敛,量化后的结果就是最终结果。一个简单的示例如下:
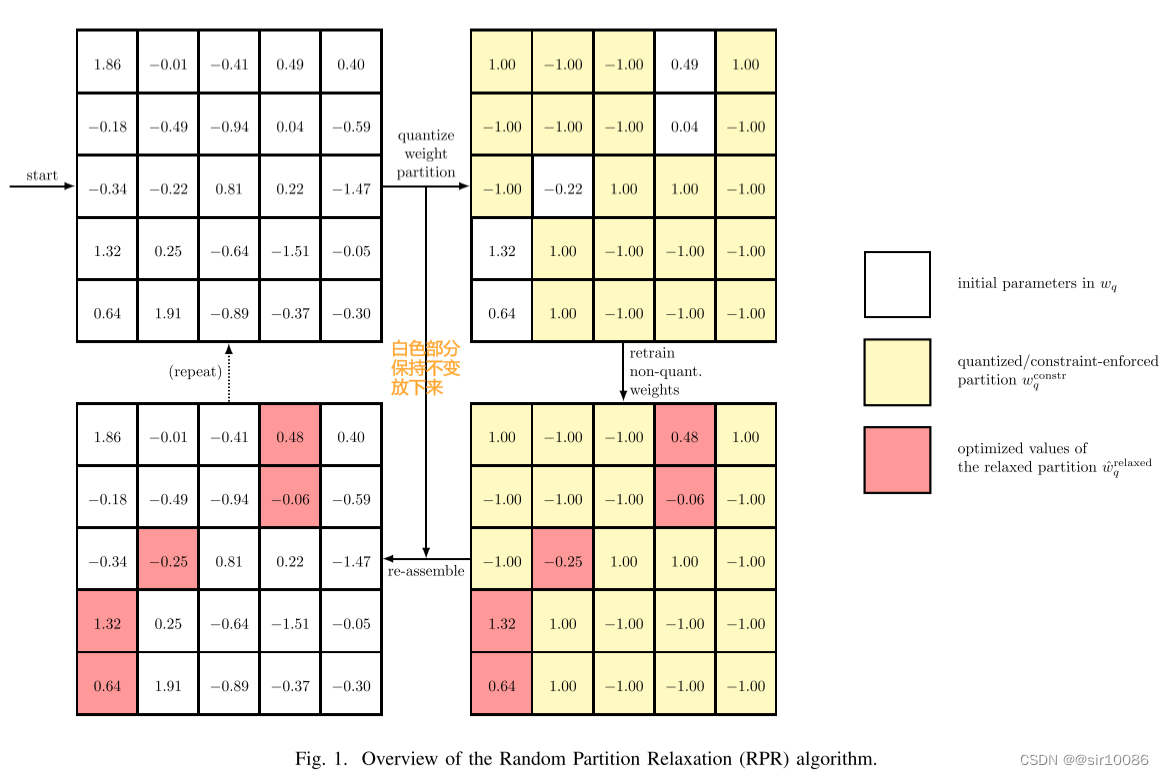
四、Two-Step Quantization for Low-bit Neural Networks
Wang P, Hu Q, Zhang Y, et al. Two-step quantization for low-bit neural networks[C]//Proceedings of the IEEE Conference on computer vision and pattern recognition. 2018: 4376-4384.
CVPR 2018 CCF-A会
1. 动机和贡献
动机: DNN的量化过程中,需要量化两种参数:“权重”和“激活”,但是当这两种参数同时使用较低精度量化时,模型测试精度下降会十分严重,甚至导致模型不能收敛。
注:和之前不同的是,本文提到了量化“激活”。具体概念在 2.1 中解释。
贡献: 为了解决同时量化 “权重”和“激活” 导致的模型性能下降的问题,本文提出了一种 两步走量化策略TSQ,来解耦权重量化过程和激活量化过程,主要包括如下两个部分:
- code learning(量化激活):利用网络中的 “激活稀疏性activation sparsity” 进行量化;
注:大多文献关注权重的稀疏性,而没有解决激活的稀疏性 - transformation function learning(量化权重):当激活量化之后,认为它已经是最忧,然后利用 “最小二乘法” 优化权重。
2. 算法
2.1 量化权重与量化激活
传统DNN的优化问题可以转化为量化后DNN的优化问题,具体表示为:
minimize
L
(
Z
L
,
y
)
subject to
Z
l
=
W
l
A
l
−
1
A
l
=
ψ
(
Z
l
)
,
for
l
=
1
,
2
,
⋯
L
⇒
t
a
n
s
l
a
t
e
i
n
t
o
minimize
{
W
l
}
L
(
Z
L
,
y
)
subject to
W
^
l
=
Q
w
(
W
l
)
Z
l
=
W
^
l
A
^
l
−
1
A
l
=
ψ
(
Z
l
)
A
^
l
=
Q
a
(
A
l
)
,
f
o
r
l
=
1
,
2
,
⋯
L
\begin{array}{ll}\text{minimize}&\mathcal{L}(Z_L,y)\\\text{subject to}&Z_l=W_lA_{l-1}\\&A_l=\psi(Z_l),\text{for}l=1,2,\cdots L\end{array} \overset{tanslate~into}{\Rightarrow}\quad \begin{aligned} &\operatorname*{minimize}_{\{W_{l}\}} \mathcal{L}(Z_{L},y) \\ &\text{subject to}~ \hat{W}_{l}=Q_{\boldsymbol{w}}(W_{l}) \\ &\qquad\qquad~~ Z_{l}=\hat{W}_{l}\hat{A}_{l-1} \\ &\qquad\qquad~~ A_{l}=\psi(Z_{l}) \\ &\qquad\qquad~~ \hat{A}_{l}={Q}_{\boldsymbol{a}}(A_{l}),\mathrm{for}l=1,2,\cdots L \end{aligned}
minimizesubject toL(ZL,y)Zl=WlAl−1Al=ψ(Zl),forl=1,2,⋯L⇒tanslate into{Wl}minimizeL(ZL,y)subject to W^l=Qw(Wl) Zl=W^lA^l−1 Al=ψ(Zl) A^l=Qa(Al),forl=1,2,⋯L其中,
W
l
W_l
Wl 表示第
l
l
l 层权重,
Q
w
ψ
(
⋅
)
Q_{\boldsymbol{w}}\psi(\cdot)
Qwψ(⋅) 表示权重量化函数;
A
l
A_l
Al 表示第
l
l
l 层激活(
A
0
A_0
A0就是输入数据),
Q
a
{Q}_{\boldsymbol{a}}
Qa 表示激活量化函数;
ψ
(
⋅
)
\psi(\cdot)
ψ(⋅) 表示DNN中的激活函数。
2.2 Code Learning(量化激活)
在这个阶段,所有的权重都是全精度的,只有激活会被量化,其核心思想是:绝对值大的激活对网络的左右大于小的,因此,引入稀疏度将所有低于某个阈值的激活设置为
0
0
0,用数学语言定义为:给定一个稀疏阈值(sparse threshold)
ϵ
\epsilon
ϵ,那么量化函数为:
Q
ϵ
(
x
)
=
{
q
i
′
x
∈
(
t
i
′
,
t
i
+
1
′
]
,
0
x
≤
ϵ
,
\left.Q_\epsilon(x)=\left\{\begin{array}{cl}q_i'&x\in(t_i',t_{i+1}'],\\0&x\leq\epsilon,\end{array}\right.\right.
Qϵ(x)={qi′0x∈(ti′,ti+1′],x≤ϵ,那么,量化函数可以由解决以下优化问题得到:
Q
ϵ
∗
(
x
)
=
a
r
g
m
i
n
Q
ϵ
E
x
∼
N
(
0
,
1
)
,
x
>
ϵ
[
(
Q
ϵ
(
x
)
−
x
)
2
]
,
Q_\epsilon^*(x)=\underset{Q_\epsilon}{\mathrm{argmin}}E_{x\sim\mathcal{N}(0,1),x>\epsilon}[(Q_\epsilon(x)-x)^2],
Qϵ∗(x)=QϵargminEx∼N(0,1),x>ϵ[(Qϵ(x)−x)2],最后,稀疏阈值
ϵ
\epsilon
ϵ定义为:经过 批归一化batch normalization,每层的输出近似为一个标准正太分布
x
∼
N
(
0
,
1
)
x\sim\mathcal{N}(0,1)
x∼N(0,1),因此,给定一个稀疏度
θ
\theta
θ,稀疏阈值通过解决如下等式得到:
Φ
(
ϵ
)
=
P
(
x
<
=
ϵ
)
=
θ
.
\Phi(\epsilon)=P(x<=\epsilon)=\theta.
Φ(ϵ)=P(x<=ϵ)=θ.
注:上述过程说明,只要获得了稀疏度 θ \theta θ 就可以得到量化函数。那么,如何获得稀疏度 θ \theta θ 呢?本文没有详细说明,我认为是通过预处理过程吗?
2.3 Transformation Function Learning(量化权重)
经过 Code Learning,认为激活的量化已经是最优,表示为
A
^
l
\hat{A}_l
A^l。这个阶段,主要是考虑如何学习
A
^
l
−
1
→
A
^
l
\hat{A}_{l-1}\rightarrow\hat{A}_{l}
A^l−1→A^l 的转换函数。假设
A
^
l
−
1
,
A
^
l
\hat{A}_{l-1},\hat{A}_l
A^l−1,A^l 表示为
X
,
Y
X,Y
X,Y,那么,转换函数学习问题的解决如同解决如下最小二乘问题:
minimize
∥
Y
−
Q
ϵ
(
Λ
W
^
X
)
∥
F
2
=
minimize
∑
{
α
i
}
,
{
w
^
i
T
}
∥
y
i
T
−
Q
ϵ
(
α
i
w
^
i
T
X
)
∥
2
2
\begin{aligned}&\text{minimize}\quad\parallel Y-Q_\epsilon(\Lambda\hat{W}X)\parallel_F^2\\=&\text{minimize}\quad\sum_{\{\alpha_i\},\{\hat{w}_i^T\}}\parallel y_i^T-Q_\epsilon(\alpha_i\hat{w}_i^TX)\parallel_2^2\end{aligned}
=minimize∥Y−Qϵ(ΛW^X)∥F2minimize{αi},{w^iT}∑∥yiT−Qϵ(αiw^iTX)∥22其中,
α
i
\alpha_i
αi 表示量化后权重
w
^
i
\hat{w}_i
w^i 的全精度缩放因子。
注:本文中
α
i
\alpha_i
αi 表示为量化后卷积核
w
^
i
\hat{w}_i
w^i 的全精度缩放因子。
由于量化函数
Q
ϵ
(
⋅
)
Q_{\epsilon}(\cdot)
Qϵ(⋅) 没办法求导,因此本文中,通过引入一个辅助变量
z
z
z 来解决,即:
minimize
α
.
w
^
∥
y
−
Q
ϵ
(
α
X
T
w
^
)
∥
2
2
⇒
minimize
α
,
w
^
,
z
∥
y
−
Q
ϵ
(
z
)
∥
2
2
+
λ
∥
z
−
α
X
T
w
^
∥
2
2
\underset{\alpha.\hat{w}}{\operatorname*{minimize}}\parallel y-Q_{\epsilon}(\alpha X^{T}\hat{w})\parallel_{2}^{2} \quad\Rightarrow\quad \underset{\alpha,\hat{w},z}{\operatorname*{minimize}}\quad\parallel y-Q_{\epsilon}(z)\parallel_{2}^{2}+\lambda\parallel z-\alpha X^{T}\hat{w}\parallel_{2}^{2}
α.w^minimize∥y−Qϵ(αXTw^)∥22⇒α,w^,zminimize∥y−Qϵ(z)∥22+λ∥z−αXTw^∥22其中,
λ
\lambda
λ 表示惩罚系数。
为了解决上述问题,本文采取交替策略,即:
- 固定
z
z
z,优化
α
,
w
^
\alpha,\hat{w}
α,w^:优化问题转化为
m i n i m i z e α , w ^ J ( α , w ^ ) = ∥ z − α X T w ^ ∥ 2 2 \underset{\alpha,\hat{w}}{\operatorname*{\mathrm{minimize}}}\quad J(\alpha,\hat{w})=\parallel z-\alpha X^{T}\hat{w}\parallel_{2}^{2} α,w^minimizeJ(α,w^)=∥z−αXTw^∥22通过设置 ∂ J / ∂ α = 0 \partial J/\partial\alpha=0 ∂J/∂α=0,得到
α ∗ = z T X T w ^ w ^ T X X T w ^ ⇒ 代入原式 w ^ ∗ = a r g m a x w ^ ( z T X T w ^ ) 2 w ^ T X X T w ^ \alpha^*=\frac{z^TX^T\hat{w}}{\hat{w}^TXX^T\hat{w}} \quad\overset{代入原式}{\Rightarrow}\quad \hat{w}^*=\underset{\hat{w}}{\mathrm{argmax}}\frac{(z^TX^T\hat{w})^2}{\hat{w}^TXX^T\hat{w}} α∗=w^TXXTw^zTXTw^⇒代入原式w^∗=w^argmaxw^TXXTw^(zTXTw^)2这样,就可以通过 ”暴力搜索“ 的方式,得到最佳的 α , w ^ \alpha,\hat{w} α,w^。 - 固定
α
,
w
^
\alpha,\hat{w}
α,w^,优化
z
z
z:优化问题转化为
min z i minimize ( y i − Q ϵ ( z i ) ) 2 + λ ( z i − v i ) 2 , \min_{z_i}\text{minimize}\quad(y_i-Q_\epsilon(z_i))^2+\lambda(z_i-v_i)^2, ziminminimize(yi−Qϵ(zi))2+λ(zi−vi)2,其中, v = α X T w ^ v=\alpha X^T\hat{w} v=αXTw^是一个已知向量。为了进一步简化问题,将量化函数 Q ϵ Q_{\epsilon} Qϵ 放缩为 Q ~ ϵ \tilde{Q}_{\epsilon} Q~ϵ:
Q ~ ϵ ( x ) = { M x > M , x 0 < x ≤ M , 0 x ≤ 0. \left.\tilde{Q}_{\epsilon}(x)=\left\{\begin{array}{cl}M&x>M,\\x&0<x\leq M,\\0&x\leq0.\end{array}\right.\right. Q~ϵ(x)=⎩ ⎨ ⎧Mx0x>M,0<x≤M,x≤0.那么,上述优化问题可以通过分类讨论得到解:
{ z i ≤ 0 ⇒ z i ( 0 ) = m i n ( 0 , v i ) 0 < z i ≤ M ⇒ z i ( 1 ) = m i n ( M , m a x ( 0 , λ v i + y i 1 + λ ) M < z i ⇒ z i ( 2 ) = m a x ( M , v i ) \begin{cases} z_i\leq 0 &\Rightarrow\quad z_{i}^{(0)}=min(0,v_{i})\\ 0<z_i\leq M &\Rightarrow\quad z_i^{(1)}=min(M,max(0,\frac{\lambda v_i+y_i}{1+\lambda}) \\ M<z_i &\Rightarrow\quad z_{i}^{(2)}=max(M,v_{i}) \end{cases} ⎩ ⎨ ⎧zi≤00<zi≤MM<zi⇒zi(0)=min(0,vi)⇒zi(1)=min(M,max(0,1+λλvi+yi)⇒zi(2)=max(M,vi)
关于初始化
α
,
w
^
\alpha,\hat{w}
α,w^ 的方式:本文通过解决如下优化问题,获得初始化值:
minimize
∥
w
−
α
w
^
∥
2
2
subject to
α
>
0
w
^
∈
{
−
1
,
0
,
+
1
}
m
,
\begin{array}{ll}\text{minimize}&\parallel w-\alpha\hat{w}\parallel_2^2\\\text{subject to}&\alpha>0\\&\hat{w}\in\{-1,0,+1\}^m\end{array},
minimizesubject to∥w−αw^∥22α>0w^∈{−1,0,+1}m,那么,
α
∗
=
w
T
w
^
w
^
T
w
^
w
^
∗
=
a
r
g
m
a
x
w
^
(
w
T
w
^
)
2
w
^
T
w
^
.
\begin{aligned}\alpha^*&=\frac{w^T\hat{w}}{\hat{w}^T\hat{w}}\\\hat{w}^*&=\underset{\hat{w}}{\mathrm{argmax}}\frac{(w^T\hat{w})^2}{\hat{w}^T\hat{w}}\end{aligned}.
α∗w^∗=w^Tw^wTw^=w^argmaxw^Tw^(wTw^)2.
3. 讨论
本文主要贡献是
- 通过 ”两步走“ 的策略,当 权重量化和激活量化解耦
- 本文量化第
l
l
l 层时,前
l
−
1
l-1
l−1 层已经量化完毕,表示为
minimize Λ , W ^ ∥ Y − Q ϵ ( Λ W ^ X ~ ) ∥ F 2 \underset{\Lambda,\hat{W}}{\operatorname*{minimize}}\quad\parallel Y-Q_{\epsilon}(\Lambda\hat{W}\tilde{X})\parallel_{F}^{2} Λ,W^minimize∥Y−Qϵ(ΛW^X~)∥F2这就解决了不同层独立量化中出现的 误差积累 的问题
借鉴点:
- 对不同层之间的量化方式可以不是独立,这样可以缓解误差的积累问题
- 之前都是考虑量化权重,是否可以考虑量化激活
五、Ternary Neural Networks with Fine-Grained Quantization
Mellempudi N, Kundu A, Mudigere D, et al. Ternary neural networks with fine-grained quantization[J]. arXiv preprint arXiv:1705.01462, 2017.
arXiv 2017
1. 动机和贡献
动机: 低精度模型可以减少计算量和内存消耗,对边缘设备是十分友好的,但是却面临着测试精度下降的问题。
贡献: 本文提出一种细粒度的量化策略FGQ,在没有重训练的情况下,使用三元表示梯度,取得了较好的测试精度。
2. 算法
2.1 问题引出
TWN 中三元量化可以表示为:
α
∗
,
Δ
∗
=
argmin
α
≥
0
,
Δ
>
0
E
(
α
,
Δ
)
=
d
e
f
∥
W
−
α
W
^
∥
F
2
,
s
.
t
.
α
≥
0
,
W
^
i
∈
{
−
1
,
0
,
+
1
}
,
i
=
1
,
2
,
⋯
,
n
\alpha^{*},\Delta^{*}=\underset{\alpha\geq0,\Delta>0}{\operatorname*{argmin}}E(\alpha,\Delta)\overset{def}{=}\|\mathbf{W}-\alpha\hat{\mathbf{W}}\|_F^2,\\\mathrm{s.t.}~\alpha\geq0,\hat{\mathbf{W}}_{i}\in\{-1,0,+1\},i=1,2,\cdots,n
α∗,Δ∗=α≥0,Δ>0argminE(α,Δ)=def∥W−αW^∥F2,s.t. α≥0,W^i∈{−1,0,+1},i=1,2,⋯,n其中,
W
∈
R
n
W\in\mathbb{R}^n
W∈Rn;同时,为了更好地表示正负权重的不同分布,通常也会对其使用不同的阈值参数
Δ
p
and
Δ
n
>
0
\Delta_{p}\text{ and }\Delta_{n}>0
Δp and Δn>0。但是使用单一或者少数的阈值
Δ
\Delta
Δ 和 缩放因子
α
\alpha
α 会导致量化后权重不能很好表示原始权重之间不同的分布,从而导致量化误差的增大。
基于此,本文提出了一种新的更细粒度的算法。
2.2 算法描述
假设
I
I
I 表示权重
W
∈
R
n
W\in\mathbb{R}^n
W∈Rn 的
n
n
n 个索引组成的集合。将
I
I
I 正交的分为
k
k
k 个子集,表示为
c
1
,
c
2
⋯
c
k
c_1,c_2\cdots c_k
c1,c2⋯ck,则有
c
i
∩
c
j
=
∅
,
∪
i
c
i
=
I
,
∑
i
n
i
=
n
c_{i}\cap c_{j}=\emptyset,\cup_{i}c_{i}=I,\sum_{i}n_{i}=n
ci∩cj=∅,∪ici=I,∑ini=n。同理,权重
W
W
W 也分为
k
k
k 个正交向量
W
(
i
)
∈
R
n
,
i
=
1
,
2
,
⋯
,
k
W^{(i)}\in\mathbb{R}^n,i=1,2,\cdots,k
W(i)∈Rn,i=1,2,⋯,k,且
W
j
(
i
)
=
W
j
if
j
∈
c
i
,
otherwise
0
\mathbf{W}_{j}^{(i)}=\mathbf{W}_{j}\text{ if }j\in c_{i},\text{ otherwise }0
Wj(i)=Wj if j∈ci, otherwise 0,因此有
∑
i
W
(
i
)
=
W
\sum_{i}\mathbf{W}^{(i)}=\mathbf{W}
∑iW(i)=W。根据其正交性,可以有:
(
W
(
i
)
−
α
i
W
^
(
i
)
)
⊥
(
W
(
j
)
−
α
j
W
^
(
j
)
)
,
f
o
r
i
≠
j
⇒
∥
W
−
∑
i
α
i
W
^
(
i
)
∥
F
2
=
∑
i
∥
W
(
i
)
−
α
i
W
^
(
i
)
∥
F
2
(\mathbf{W}^{(i)}-\alpha_{i}\hat{\mathbf{W}}^{(i)})\perp (\mathbf{W}^{(j)}-\alpha_{j}\hat{\mathbf{W}}^{(j)}),\mathrm{for~}i\neq j \quad\Rightarrow\quad \|\mathbf{W}-\sum_{i}\alpha_{i}\hat{\mathbf{W}}^{(i)}\|_{F}^{2}=\sum_{i}\|\mathbf{W}^{(i)}-\alpha_{i}\hat{\mathbf{W}}^{(i)}\|_{F}^{2}
(W(i)−αiW^(i))⊥(W(j)−αjW^(j)),for i=j⇒∥W−i∑αiW^(i)∥F2=i∑∥W(i)−αiW^(i)∥F2那么上述优化问题转换为:
α
1
∗
,
.
.
,
α
k
∗
,
W
^
(
1
)
∗
,
.
.
,
W
^
(
k
)
∗
=
argmin
α
i
,
W
^
(
i
)
∥
W
−
∑
i
α
i
W
^
(
i
)
∥
F
2
=
∑
i
argmin
α
i
,
W
^
(
i
)
∥
W
(
i
)
−
α
i
W
^
(
i
)
∥
F
2
\alpha_{1}^{*},..,\alpha_{k}^{*},\hat{\mathbf{W}}^{(1)*},..,\hat{\mathbf{W}}^{(k)*}=\underset{\alpha_{i},\hat{\mathbf{W}}^{(i)}}{\operatorname*{argmin}}\|\mathbf{W}-\sum_{i}\alpha_{i}\hat{\mathbf{W}}^{(i)}\|_{F}^{2}=\sum_{i}\underset{\alpha_{i},\hat{\mathbf{W}}^{(i)}}{\operatorname*{argmin}}\|\mathbf{W}^{(i)}-\alpha_{i}\hat{\mathbf{W}}^{(i)}\|_{F}^{2}
α1∗,..,αk∗,W^(1)∗,..,W^(k)∗=αi,W^(i)argmin∥W−i∑αiW^(i)∥F2=i∑αi,W^(i)argmin∥W(i)−αiW^(i)∥F2这样,就可以单独解决
k
k
k 个子问题。
另外,如果对正负权重使用不同的阈值,则优化问题是:
α
∗
,
Δ
p
∗
,
Δ
n
∗
=
argmin
α
≥
0.
Δ
n
>
0.
Δ
n
>
0
∥
W
−
α
W
^
∥
F
2
,
s
.
t
.
W
^
i
∈
{
−
1
,
0
,
+
1
}
,
i
=
1
,
⋯
,
n
.
\alpha^{*},\Delta_{p}^{*},\Delta_{n}^{*}=\underset{\alpha\geq0.\Delta_{n}>0.\Delta_{n}>0}{\operatorname*{argmin}}\|\mathbf{W}-\alpha\hat{\mathbf{W}}\|_{F}^{2},\quad\mathrm{s.t.}\quad\hat{\mathbf{W}}_{i}\in\{-1,0,+1\},i=1,\cdots,n.
α∗,Δp∗,Δn∗=α≥0.Δn>0.Δn>0argmin∥W−αW^∥F2,s.t.W^i∈{−1,0,+1},i=1,⋯,n.
根据 TWN 中给出的解析解,有:
α
∗
=
(
∑
i
∈
I
Δ
∣
W
i
∣
)
/
∣
I
Δ
∣
,
Δ
∗
=
a
r
g
m
a
x
Δ
>
0
(
∑
i
∈
I
Δ
∣
W
i
∣
)
2
/
∣
I
Δ
∣
\alpha^{*}=(\sum_{i\in I_{\Delta}}|\mathbf{W}_{i}|)/|I_{\Delta}|,\quad\Delta^{*}=\mathop{\mathrm{argmax}}_{\Delta>0}(\sum_{i\in I_{\Delta}}|\mathbf{W}_{i}|)^{2}/|I_{\Delta}|
α∗=(i∈IΔ∑∣Wi∣)/∣IΔ∣,Δ∗=argmaxΔ>0(i∈IΔ∑∣Wi∣)2/∣IΔ∣或者
Δ
p
∗
,
Δ
n
∗
=
a
r
g
m
a
x
Δ
p
>
0
,
Δ
n
>
0
(
∑
i
∈
I
Δ
+
∣
W
i
∣
+
∑
i
∈
I
Δ
−
∣
W
i
∣
)
2
∣
I
Δ
+
∣
+
∣
I
Δ
−
∣
,
α
∗
=
∑
i
∈
I
Δ
+
∣
W
i
∣
+
∑
i
∈
I
Δ
−
∣
W
i
∣
∣
I
Δ
+
∣
+
∣
I
Δ
−
∣
\Delta_{p}^{*},\Delta_{n}^{*}=\mathop{\mathrm{argmax}}_{\Delta_{p}>0,\Delta_{n}>0}\frac{(\sum_{i\in I_{\Delta}^{+}}|\mathbf{W}_{i}|+\sum_{i\in I_{\Delta}^{-}}|\mathbf{W}_{i}|)^{2}}{|I_{\Delta}^{+}|+|I_{\Delta}^{-}|},\quad\alpha^{*}=\frac{\sum_{i\in I_{\Delta}^{+}}|\mathbf{W}_{i}|+\sum_{i\in I_{\Delta}^{-}}|\mathbf{W}_{i}|}{|I_{\Delta}^{+}|+|I_{\Delta}^{-}|}
Δp∗,Δn∗=argmaxΔp>0,Δn>0∣IΔ+∣+∣IΔ−∣(∑i∈IΔ+∣Wi∣+∑i∈IΔ−∣Wi∣)2,α∗=∣IΔ+∣+∣IΔ−∣∑i∈IΔ+∣Wi∣+∑i∈IΔ−∣Wi∣
那么,如何进行分组?
原文中没有详细给出分组策略,只是给出分组需要遵守的原则是:尽可能使组中权重有着相同的数据分布。
原文中也提到了使用K-means聚类方法,只不过对算力有一定要求。
六、SYQ: Learning Symmetric Quantization For Efficient Deep Neural Networks
Faraone, Julian, et al. “Syq: Learning symmetric quantization for efficient deep neural networks.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
CVPR 2018 CCF-A会
1. 动机和贡献
动机: 由于量化导致DNN前馈和后馈过程中大量梯度的错配,因此导致推理过程中模型精度的大幅度下降。
贡献: 本文提出一种 “对称性三元量化”策略SYQ。首先通过权重的位置对其进行分组,然后对不同组权重给出不同的缩放因子。
注:本文中主要关心DNN中的 “卷积层CONV”。
2. 算法
2.1 权重量化
根据 TWN 中的描述,三元量化函数定义为:
Q
l
=
s
i
g
n
(
W
l
)
⊙
M
l
,
Q_l=sign(W_l)\odot M_l,
Ql=sign(Wl)⊙Ml,其中,权重
W
l
∈
R
K
×
K
×
I
×
N
W_l\in\mathbb{R}^{K\times K\times I\times N}
Wl∈RK×K×I×N,
K
K
K表示卷积核大小,
I
I
I表示输出特征数,
N
N
N表示输出特征数;掩码矩阵定义为:
M
l
i
,
j
=
{
1
if
∣
W
l
i
,
j
∣
≥
η
l
0
if
−
η
l
<
W
l
i
,
j
<
η
l
M_{l_{i,j}}=\begin{cases}\quad1&\quad\text{if}\quad|W_{l_{i,j}}|\geq\eta_l\\\quad0&\quad\text{if}\quad-\eta_l<W_{l_{i,j}}<\eta_l\end{cases}
Mli,j={10if∣Wli,j∣≥ηlif−ηl<Wli,j<ηl根据 TTQ 中定义,阈值
η
=
0.05
×
max
(
∥
W
l
∥
)
\eta=0.05\times\max{(\|W_l\|)}
η=0.05×max(∥Wl∥)。类似于TTQ中解决梯度消失的方式,本文中也采用STE的方式,即:
∂
E
^
∂
W
l
i
,
j
=
∂
E
^
∂
Q
l
i
,
j
,
\frac{\partial\hat{E}}{\partial W_{l_{i,j}}}=\frac{\partial\hat{E}}{\partial Q_{l_{i,j}}},
∂Wli,j∂E^=∂Qli,j∂E^,其中,
E
^
\hat{E}
E^ 表示没有缩放因子的误差函数
2.2 收缩因子定义和分组
收缩因子
c
i
c_i
ci 采用和TWN中相同的对称收缩因子的定义方式,本文采用的数学语言描述为:
∀
c
i
∈
C
p
,
∃
∣
c
j
∣
∈
C
n
where
c
i
=
∣
c
j
∣
,
\forall c_i\in C^p,\quad\exists|c_j|\in C^n\quad\text{where}\quad c_i=|c_j|,
∀ci∈Cp,∃∣cj∣∈Cnwhereci=∣cj∣,其中,
C
p
=
{
c
i
∣
c
i
>
0
}
,
C
n
=
{
c
j
∣
c
j
<
0
}
C^{p}=\{c_{i}|c_{i}>0\},C^n=\begin{Bmatrix}c_j|c_j<0\end{Bmatrix}
Cp={ci∣ci>0},Cn={cj∣cj<0}。因此,使用STE方法有:
∂
E
∂
W
l
i
,
j
=
∂
E
∂
Q
l
i
,
j
=
α
l
i
∂
E
^
∂
Q
l
i
,
j
.
\frac{\partial E}{\partial W_{l_{i,j}}}=\frac{\partial E}{\partial Q_{l_{i,j}}}=\alpha_{l}^{i}\frac{\partial\hat{E}}{\partial Q_{l_{i,j}}}.
∂Wli,j∂E=∂Qli,j∂E=αli∂Qli,j∂E^.
因此,本文可以采用和TWN、TTQ相同的思路,采用向后传播的方式逐步更新缩放因子,其初始值定义为相对应权重绝对值的均值,即:
α
l
0
i
=
∑
j
∈
S
l
i
∣
W
~
l
i
,
j
∣
I
×
N
.
\alpha_{l_{0}}^{i}=\frac{\sum_{j\in S_{l}^{i}}\left|\tilde{W}_{l_{i,j}}\right|}{I\times N}.
αl0i=I×N∑j∈Sli
W~li,j
.
分组方式: 本文中的分组方式是一个比较新颖的点,包括两种方式,c。但是对于这两种方式的具体优势,本文没有给出。下图是这种分组方式的示意图:
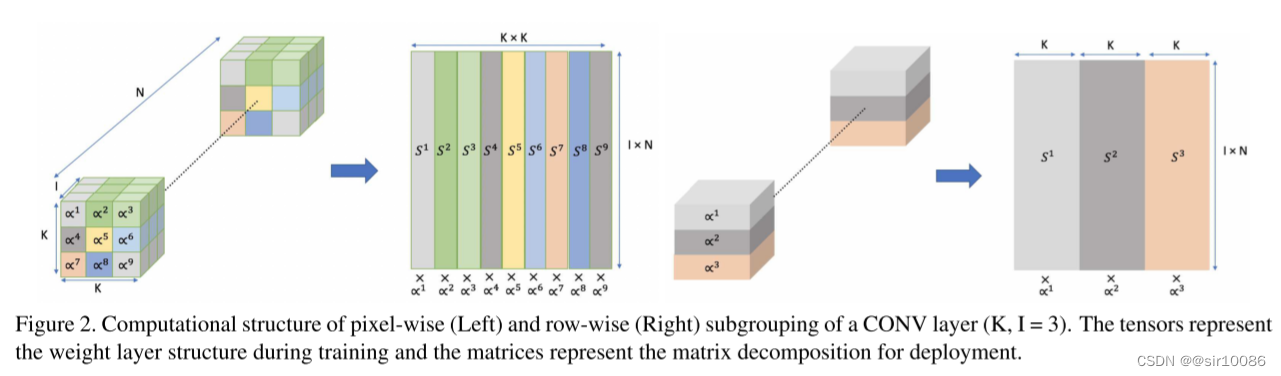
3. 讨论
本文基本采用TWN、TTQ这两篇文章的中心思想,有所不同的是给出两种权重分组策略,所以我认为创新性不太充足。
缺点:
- 本文中对误差函数的定义没有详细说明,可能采用与TWN、TTQ中相同的定义方式,即 J ( α , W ^ = ∥ W − α W ^ ∥ 2 2 ) J(\alpha,\hat{W}=\|W-\alpha\hat{W}\|_2^2) J(α,W^=∥W−αW^∥22);
- 对收缩因子的定义不清,似乎本文收缩因子绝对值采用 “绝对值权重和的平均” 来定义;
- 对于文中所提到的pixel-wise和row-wise的两种分组方式,都是适用于卷积层CONV,对于其他类型的学习算法,并不适用。
七、Fixed-point factorized networks
Wang P, Cheng J. Fixed-point factorized networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 4012-4020.
CVPR 2017 CCF-A会
1. 动机和贡献
动机: 为了压缩DNN模型,并加快其训练过程,同时尽可能地减少推理精度损失。
贡献: 本文提出了一种基于矩阵不动点分解网络模型 FFN,将原始全精度权重使用 ( − 1 , 0 , + 1 ) (-1,0,+1) (−1,0,+1) 三元组表示,具体分为如下三个部分:
- direct fixed-point factorization:基于矩阵不动点分解,FFN分解原始全精度权重,这种分解方式十分灵活且准确;
- full precision weight recovery:进行梯度累加时,如果直接使用量化值进行相加,会损失重要信息,因此,本文将量化值重新恢复为(伪)全精度值进行梯度累加;
- weight balancing:由于分解形式不是唯一的,使用分解技术通常会产生权重不平衡问题,因此,本文提出了一种有效的权重平衡策略。
2. 算法
2.1 Fixed-point Factorization of Weight Matrices
假设全精度权重矩阵为
W
∈
R
m
×
n
W\in R^{m\times n}
W∈Rm×n,那么其半离散分解SDD可以表示为:
minimize
X
,
D
,
Y
∥
W
−
X
D
Y
T
∥
F
2
=
minimize
{
x
i
}
,
{
d
i
}
,
{
y
i
}
∥
W
−
∑
i
k
d
i
x
i
y
i
T
∥
F
2
\begin{equation*} \begin{split} &\qquad\underset{{X,D,Y}}{\operatorname{minimize}}\parallel W-XDY^T\parallel_F^2\\\\&=\underset{{\{x_i\},\{d_i\},\{y_i\}}}{\operatorname{minimize}}\parallel W-\sum_i^kd_ix_iy_i^T\parallel_F^2 \end{split} \end{equation*}
X,D,Yminimize∥W−XDYT∥F2={xi},{di},{yi}minimize∥W−i∑kdixiyiT∥F2其中,
X
∈
{
−
1
,
0
,
+
1
}
m
×
k
,
Y
∈
{
−
1
,
0
,
+
1
}
n
×
k
X\in\{-1,0,+1\}^{m\times k},Y\in\{-1,0,+1\}^{n\times k}
X∈{−1,0,+1}m×k,Y∈{−1,0,+1}n×k,
D
∈
R
+
k
×
k
D\in R^{k\times k}_+
D∈R+k×k 是一个对角矩阵,
k
k
k 代表了SDD分解的维数(选择不同的
k
k
k可以尽可能准确的模拟原始全精度权重,注意到
k
k
k可以比
m
,
n
m,n
m,n都要大)。
由于上述优化问题的三元值限制,这是一个NP问题,本文借用[19]中的内容,使用贪心策略得到其近似解,具体过程见如下算法:

2.2 Full-precision Weight Recovery
假设
X
,
Y
X,Y
X,Y 的全精度表示为
X
^
,
Y
^
\hat{X},\hat{Y}
X^,Y^,注意到
X
^
,
Y
^
\hat{X},\hat{Y}
X^,Y^ 必须量化到
X
,
Y
X,Y
X,Y。本文中,将全精度权重恢复技术视为量化过程的逆过程,描述为:
m
i
n
i
m
i
z
e
∥
W
−
X
^
D
Y
^
T
∥
F
2
s
u
b
j
e
c
t
t
o
∣
X
^
i
j
−
X
i
j
∣
<
0.5
,
∀
i
,
j
∣
Y
^
i
j
−
Y
i
j
∣
<
0.5
,
∀
i
,
j
\begin{array}{rl}{\mathrm{minimize}}&{\parallel W-\hat{X}D\hat{Y}^{T}\parallel_{F}^{2}}\\{\mathrm{subject~to}}&{\mid\hat{X}_{ij}-X_{ij}\mid<0.5,\forall i,j}\\&{\mid\hat{Y}_{ij}-Y_{ij}\mid<0.5,\forall i,j}\end{array}
minimizesubject to∥W−X^DY^T∥F2∣X^ij−Xij∣<0.5,∀i,j∣Y^ij−Yij∣<0.5,∀i,j这里的两个限制条件是为了
X
^
,
Y
^
\hat{X},\hat{Y}
X^,Y^ 可以量化到
X
,
Y
X,Y
X,Y。注意到
X
^
,
Y
^
∈
[
−
1.5
,
1.5
]
\hat{X},\hat{Y}\in[-1.5,1.5]
X^,Y^∈[−1.5,1.5],同时一开始原始权重也限制到
[
−
1.5
,
1.5
]
[-1.5,1.5]
[−1.5,1.5] 之内。因此,
X
^
,
Y
^
\hat{X},\hat{Y}
X^,Y^ 的量化可以是:
q
(
A
i
j
)
=
{
+
1
0.5
<
A
i
j
<
1.5
0
−
0.5
≤
A
i
j
≤
0.5
−
1
−
1.5
<
A
i
j
<
−
0.5
\left.q(A_{ij})=\left\{\begin{array}{cc}+1&\quad0.5<A_{ij}<1.5\\0&-0.5\leq A_{ij}\leq0.5\\-1&-1.5<A_{ij}<-0.5\end{array}\right.\right.
q(Aij)=⎩
⎨
⎧+10−10.5<Aij<1.5−0.5≤Aij≤0.5−1.5<Aij<−0.5
2.3 Weight Balancing
这是由于 “矩阵的不动点分解不存在唯一的分解形式” 所导致的问题。由于不是本阶段关注重点,所以此部分略过。
3. 讨论
和传统量化方式不同,本文利用 矩阵的不动点分解进行量化,使得量化过程更加灵活、准确。
可参考的点儿:
- 在梯度累加时使用(伪)全重精度权重,可以降低损失;
- 由于(伪)全精度权重恢复的需要,原始权重可以归一到区间 [ − 1.5 , 1.5 ] [-1.5,1.5] [−1.5,1.5],而不是传统意义上的 [ − 1.1 ] [-1.1] [−1.1];














 477
477











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









