







! pip install "openai>=1" "langchain>=0.0.331rc2" matplotlib pillow
加载图像
我们将图像编码为 base64 字符串,如 OpenAI GPT-4V 文档中所述。
import base64
import io
import os
import numpy as np
from IPython.display import HTML, display
from PIL import Image
def encode_image(image_path):
"""获取图像的 base64 字符串"""
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
def plt_img_base64(img_base64):
"""显示 base64 图像"""
# 使用 base64 字符串创建 HTML img 标签
image_html = f'<img src="data:image/jpeg;base64,{img_base64}" />'
# 通过渲染 HTML 显示图像
display(HTML(image_html))
# 问答用图像
path = "/Users/rlm/Desktop/Multimodal_Eval/qa/llm_strategies.jpeg"
img_base64 = encode_image(path)
plt_img_base64(img_base64)
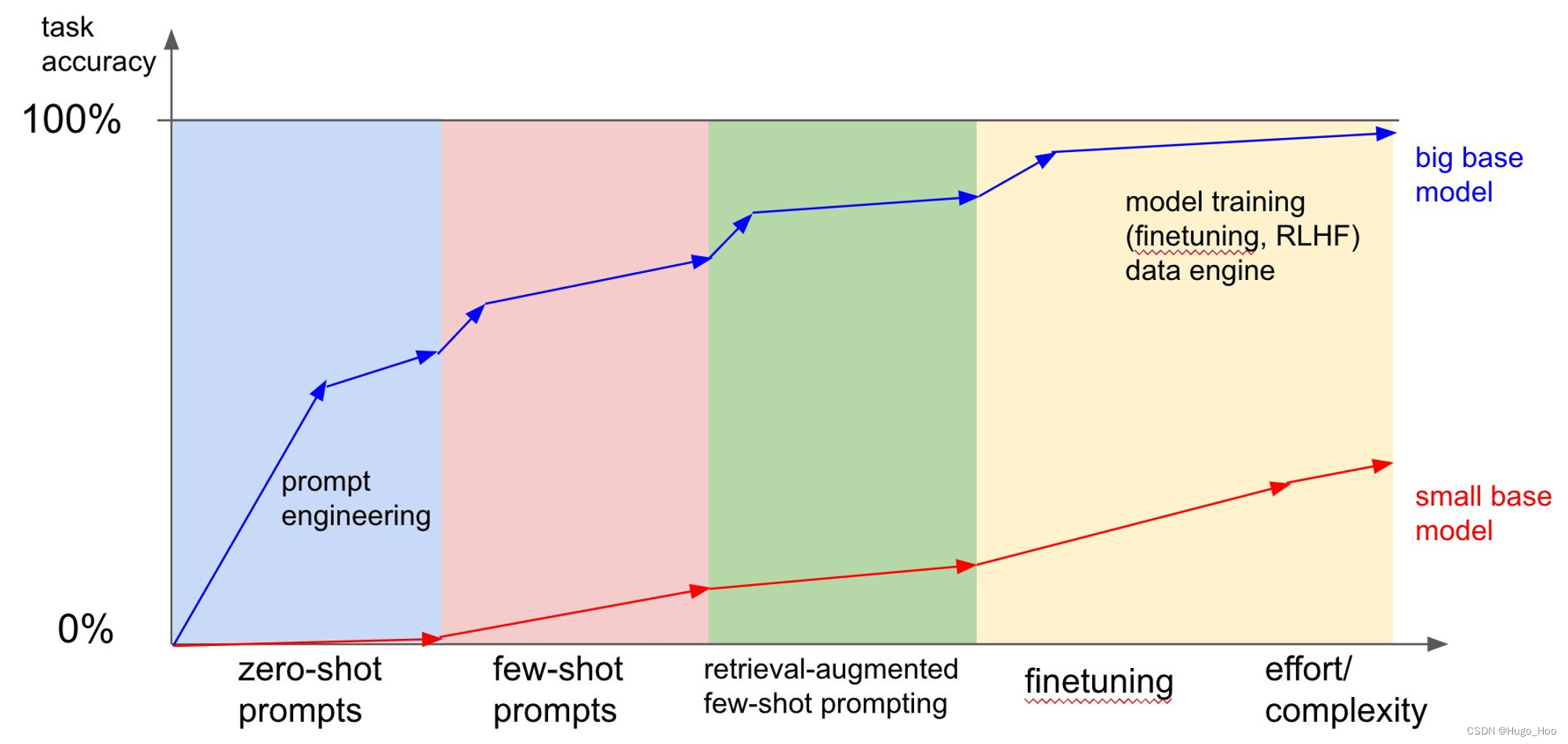
QA with GPT-4Vision 使用 GPT-4Vision 进行 QA
我们可以使用 GPT-4V 对图像进行 QA。有关详细信息,请参阅此处:
https://github.com/openai/openai-python/releases/tag/v1.0.0
https://platform.openai.com/docs/guides/vision
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
chat = ChatOpenAI(model="gpt-4-vision-preview", max_tokens=1024)
msg = chat.invoke(
[
HumanMessage(
content=[
{
"type": "text",
"text": "Based on the image, what is the difference in training strategy between a small and a large base model?",
},
{
"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{img_base64}"},
},
]
)
]
)
结果 msg.content 如下所示:
该图像似乎是一张图表,描述了两种不同基本模型大小(大和小)的任务准确性,作为不同训练策略以及与之相关的工作量/复杂性的函数。下面是小基础模型和大基础模型之间训练策略差异的描述,如图所示:
- 零样本提示:两种模型都以一定的基线精度开始,无需额外训练,这表明零样本学习能力。但是,与小型基础模型相比,大基础模型开箱即用的精度更高。
- 提示工程:随着复杂性随着提示工程的增加,大基础模型在任务准确性方面表现出显着提高,表明它比小基础模型更有效地理解和利用精心设计的提示。
- 小样本提示:随着小样本提示的引入,模型提供了一些示例供学习,与小基础模型相比,大基础模型继续显示出更高的任务准确性,小基础模型也有所改进,但程度不同。
- 检索增强小样本提示:在这个阶段,模型通过检索机制得到增强,以协助小样本学习过程。大基础模型在任务准确性方面保持领先地位,表明它可以更好地集成检索增强策略。
- 微调:当我们移动到表示微调的图形右侧时,与前面的步骤相比,小基础模型的精度提高了,这表明微调对较小的模型有重大影响。大基础模型虽然也受益于微调,但并没有显示出那么显着的增长,这可能是因为它的尺寸和容量更大,它已经在更高的水平上运行。
- 模型训练(微调,RLHF)和数据引擎:图的最后一部分表明,通过广泛的模型训练技术,如微调和人类反馈强化学习(RLHF),结合强大的数据引擎,大基础模型可以实现近乎完美的任务准确性。小基础模型也有所改进,但未达到相同的水平,这表明较大模型的容量使其能够更好地利用高级训练方法和数据资源。
总之,大基础模型更多地受益于高级训练策略,并通过增加工作量和复杂性表现出更高的任务准确性,而小基础模型需要更显着的微调才能实现性能的实质性改进。
QA with OSS Multi-modal LLMs 使用 OSS 多模式LLMs的 QA
我们还测试了各种开源多模态LLMs。
有关为多模式构建llama.cpp的说明LLMs,请参阅此处:
克隆llama.cpp
下载砝码:
- LLaVA-7b
- LLaVA-13b
- Bakllava
在您的 llama.cpp 目录中构建:
mkdir build && cd build && cmake ..
cmake --build .
对多模式LLMs的支持将很快添加到llama.cpp中。
同时,您可以使用 CLI 测试它们:
%%bash
# Define the path to the image
IMG_PATH="/Users/rlm/Desktop/Multimodal_Eval/qa/llm_strategies.jpeg"
# Define the model name
#MODEL_NAME="llava-7b"
#MODEL_NAME="bakllava-1"
MODEL_NAME="llava-13b"
# Execute the command and save the output to the defined output file
/Users/rlm/Desktop/Code/llama.cpp/build/bin/llava -m /Users/rlm/Desktop/Code/llama.cpp/models/${MODEL_NAME}/ggml-model-q5_k.gguf --mmproj /Users/rlm/Desktop/Code/llama.cpp/models/${MODEL_NAME}/mmproj-model-f16.gguf --temp 0.1 -p "Based on the image, what is the difference in training strategy between a small and a large base model?" --image "$IMG_PATH"
总结
本指南介绍了如何使用 OpenAI 的 GPT-4 和 LangChain 库实现多模态问答系统。文中包含了加载图像、编码图像为 base64 字符串、使用 HTML 标签显示图像,以及结合文本和图像信息进行问答的具体步骤。
扩展知识
OpenAI GPT-4V
OpenAI 的 GPT-4V 是一种能够处理和生成图像数据的增强型语言模型,适用于需要结合图像和文本信息的复杂应用场景。
LangChain
LangChain 是一个用于构建基于语言模型的应用程序的库,提供了从数据加载、预处理到模型训练和评估的全流程开发支持。
Base64 编码
Base64 编码是一种将二进制数据转换为文本格式的常用方法,便于在网络中传输图像、音频等文件。
















 901
901

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











