






数据探索性分析是数据分析的重要步骤之一,通过对数据进行可视化和摘要统计,可以更好地理解数据的特征和关系,发现其中的模式和异常,为进一步建模和分析做准备。而pandas和pygwalker是两个强大的Python库,可以让我们更加方便地进行数据探索性分析。
什么是数据探索性分析
数据探索性分析是数据分析的重要步骤之一。其目标在于通过对数据进行可视化和摘要统计,更好地理解数据的性质和结构,探索数据中潜在的模式和关系,并为后续的数据建模和分析提供支持。在数据探索性分析的过程中,我们可以通过直方图、散点图、箱线图等可视化图表,以及均值、中位数、标准差等统计指标,对数据的特征、分布、离散情况等进行探索和解释。这些分析结果可以帮助我们更好地理解数据,为后续的数据建模和分析提供支持。
数据探索性分析的作用不仅仅局限于数据建模和分析。它还可以帮助我们发现数据中的异常值、缺失值等问题,进一步优化数据质量。此外,数据探索性分析也可以帮助我们发现数据中的规律和趋势,从而为业务决策提供支持。在数据探索性分析的基础上,我们可以更加全面、准确地理解数据,从而作出更加科学、合理的决策。
常用工具和技术
以下是数据探索性分析中常用的工具和技术:
- pandas:pandas是一个提供了丰富数据结构和数据分析工具的Python库。它可以处理各种数据格式,如CSV、Excel、SQL等,并提供了各种数据操作和处理的函数。在数据探索性分析中,我们可以使用pandas进行数据读取、处理、摘要统计和可视化等操作,以更好地理解数据的性质和结构。
- pygwalker:pygwalker是一个基于matplotlib和seaborn库的Python可视化工具库,可以让我们更加方便地进行数据可视化。在数据探索性分析中,我们可以使用pygwalker绘制各种类型的图表,如直方图、散点图、箱线图等,以更好地展示数据的特征、分布和离散情况等。
- Jupyter:Jupyter是一个开源的Web应用程序,可以让你创建和共享文档,包括实时代码、方程式、可视化和说明文本。它支持数十种编程语言,包括Python、R、Julia和Scala等。使用Jupyter,你可以在一个交互式的环境中编写和运行代码,实时查看代码的输出结果,并将代码和文档一起保存在一个Notebook中。这个Notebook可以被共享、导出为HTML、PDF等格式,或者发布到Jupyter Notebook Viewer上。Jupyter是数据科学家、教育工作者、研究人员、工程师和开发人员等的理想工具,可以帮助他们更加高效地进行数据分析、可视化、模拟和交互式编程等工作。
以上是数据探索性分析中常用的工具和技术。通过这些工具和技术的使用,我们可以更加全面、准确地理解数据,发现其中的规律和趋势,为后续的数据建模和分析提供支持。
pandas如何进行数据探索性分析
数据读取和处理
在pandas中,我们可以使用read_csv()、read_excel、read_sql等函数读取不同格式的数据文件,并将其转换为DataFrame格式。例如,下面各函数读取不同的数据文件的代码:
import pandas as pd
#读取csv格式的数据如下
df = pd.read_csv('data.csv')
#读取excel格式的数据如下
df = pd.read_excel('/User/wangjye/Document/09-data/data.xlsx')
#读取mysql格式的数据如下
#1.建立数据库链接
conn = pymysql.connect(host='localhost',user='root',password='******',database='***_event')
#2.读取数据
sql = 'select event_id,first_time,last_time,event_status,ci_appname,ci_name,ci_instance,event_title,alert_kpi,alert_value,alert_info from event_info order by first_time'
alerts = pd.read_sql(sql,con=conn)
读取数据文件后,我们可以使用head()函数查看前几行数据:
print(alerts.head())
我们也可以使用info()函数查看数据的基本信息,如字段信息、字段数据类型、非空值的统计记录数等信息:
print(alerts.info())
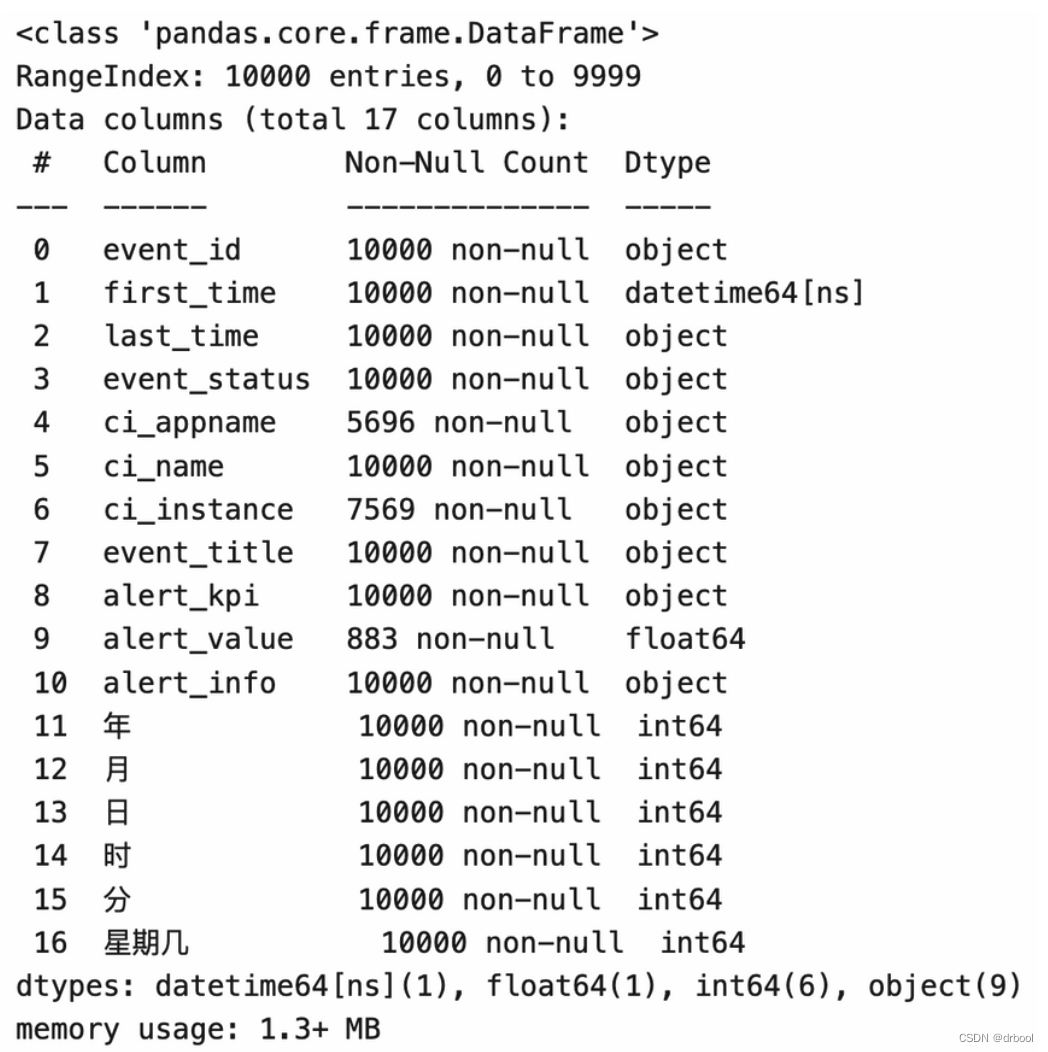
针对一些重要的字段,如果发现这些字段为空的情况比较多,可以定位并查看是什么原因导致的。例如,本例中上图所示 ci_appname 字段为空的情况比较多。对于运营告警来说,该字段非常重要,因为它用于判断当前告警对象所服务的业务系统是哪个。因此,可以有针对性地对该数据进行治理。
如果数据中有缺失值,我们可以使用fillna()函数将其填充为特定的值,如下所示:
df.fillna(0, inplace=True)
在进行数据处理时,我们还需要考虑数据质量和数据标准化等问题。
数据质量是指数据的准确性、完整性、一致性、可信度等方面的问题。在数据探索性分析中,如果数据存在缺失值、重复值、异常值等问题,都会影响我们对数据的理解和分析。因此,在进行数据处理之前,我们需要对数据进行质量检查和清洗,以保证数据的质量。我们可以使用pandas中的函数,如isnull()、duplicated()、dropna()、replace()等函数,对数据进行质量检查和清洗。
数据标准化是指将原始数据转换为统一格式或单位,以便于后续的数据分析和建模。在数据探索性分析中,如果数据存在不同的格式或单位,会影响我们对数据的比较和分析。因此,在进行数据处理之前,我们需要对数据进行标准化。例如,我们可以将不同时间格式的数据转换为统一格式,或将不同货币单位的数据转换为统一货币单位。在pandas中,我们可以使用apply()函数对数据进行标准化。
通过对数据质量和数据标准化进行处理,我们可以更好地理解和分析数据,为后续的数据建模和分析提供支持。
数据摘要统计
数据摘要统计是数据探索性分析中非常重要的一环,通过对数据进行摘要统计,我们可以更好地理解数据的性质和结构,挖掘数据中的规律和趋势。数据摘要统计通常包括以下几个方面的内容:
- 描述性统计:包括均值、中位数、众数、标准差、方差、最小值、最大值等统计指标,用于描述数据的分布情况和集中趋势。
- 频数统计:用于描述数据中各个取值的出现频率和分布情况。
- 分类统计:对数据进行分组,统计各组数据的数量和频率等信息。
在pandas中,我们可以使用describe()函数进行描述性统计,使用value_counts()函数进行频数统计,使用groupby()函数进行分类统计。例如,为了便于更好地理解,下面是对某个简单的DataFrame对象进行描述性统计、频数统计和分类统计的代码:
import pandas as pd
df = pd.DataFrame({'name': ['Alice', 'Bob', 'Charlie', 'David', 'Emily'],
'age': [25, 30, 35, 40, 45],
'gender': ['F', 'M', 'M', 'M', 'F']})
# 描述性统计
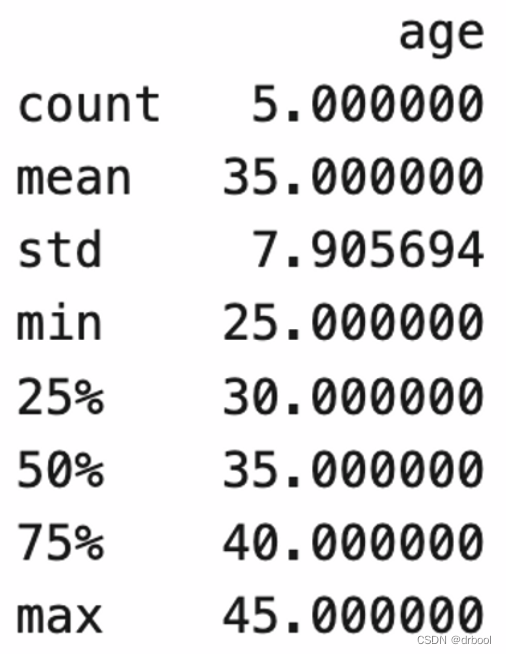
print(df.describe())
# 统计每个姓别的人数
print(df['gender'].value_counts())
![]()
# 按不同的姓别统计平均年龄
print(df.groupby('gender').mean())

以上是数据摘要统计的基本方法,通过这些方法我们可以更好地理解数据的性质和结构,为后续的数据建模和分析提供支持。
数据可视化
数据可视化是数据探索性分析中非常重要的一环,通过可视化图表展示数据,我们可以更好地理解数据的特征、分布和离散情况等,为后续的数据建模和分析提供支持。
pygwalker如何进行数据可视化
pygwalker可以简化Jupyter的数据可视化、数据探索性分析的工作流程,可以直接将pandas中的dataframe数据转换为Tableau风格的用户界面进行可视化数据探索及分析。
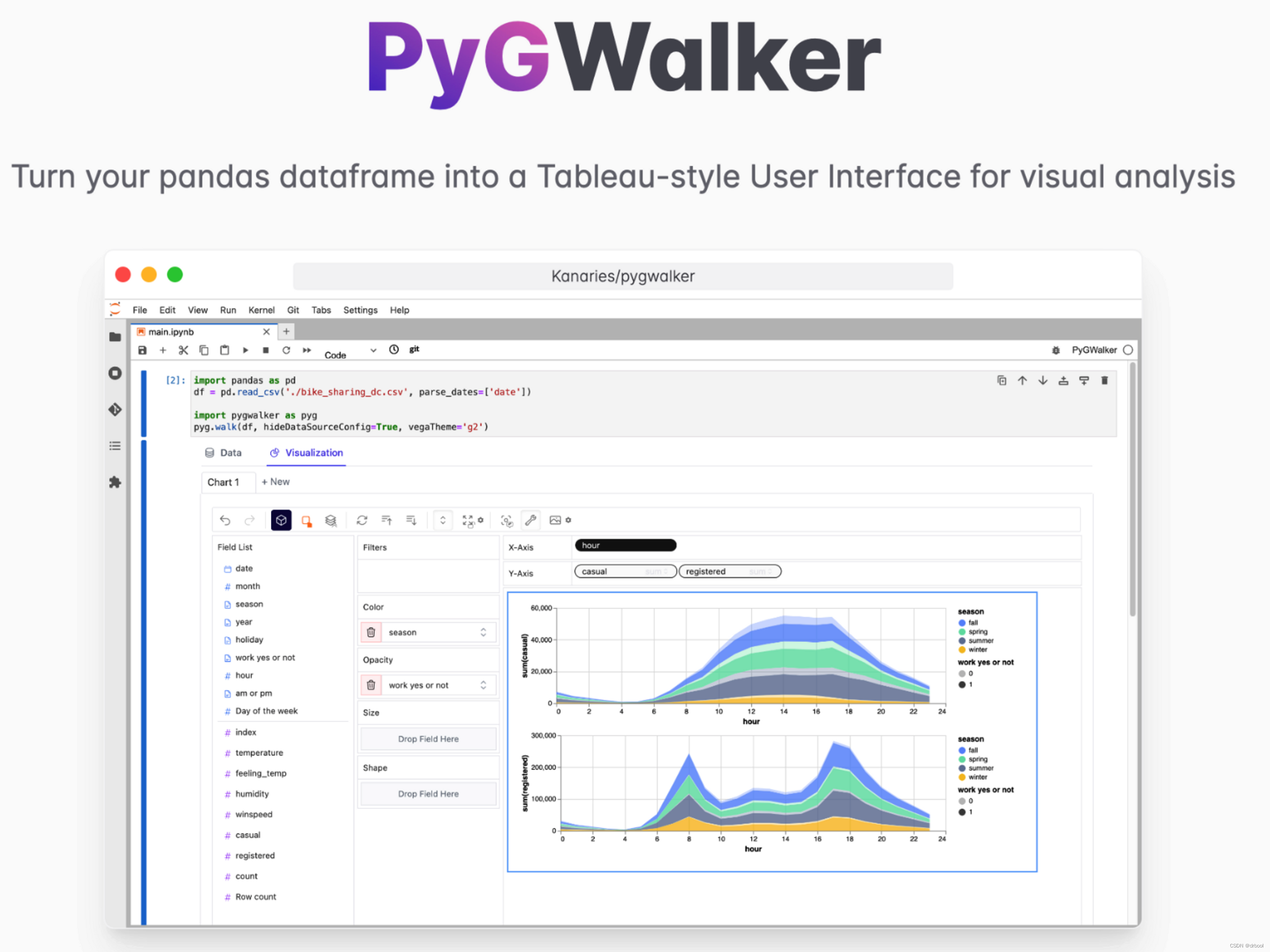
常用图表类型和用法
pygwalker支持多种图表类型,包括直方图、散点图、箱线图、折线图、饼图等。下面是常用的几种图表类型和用法:
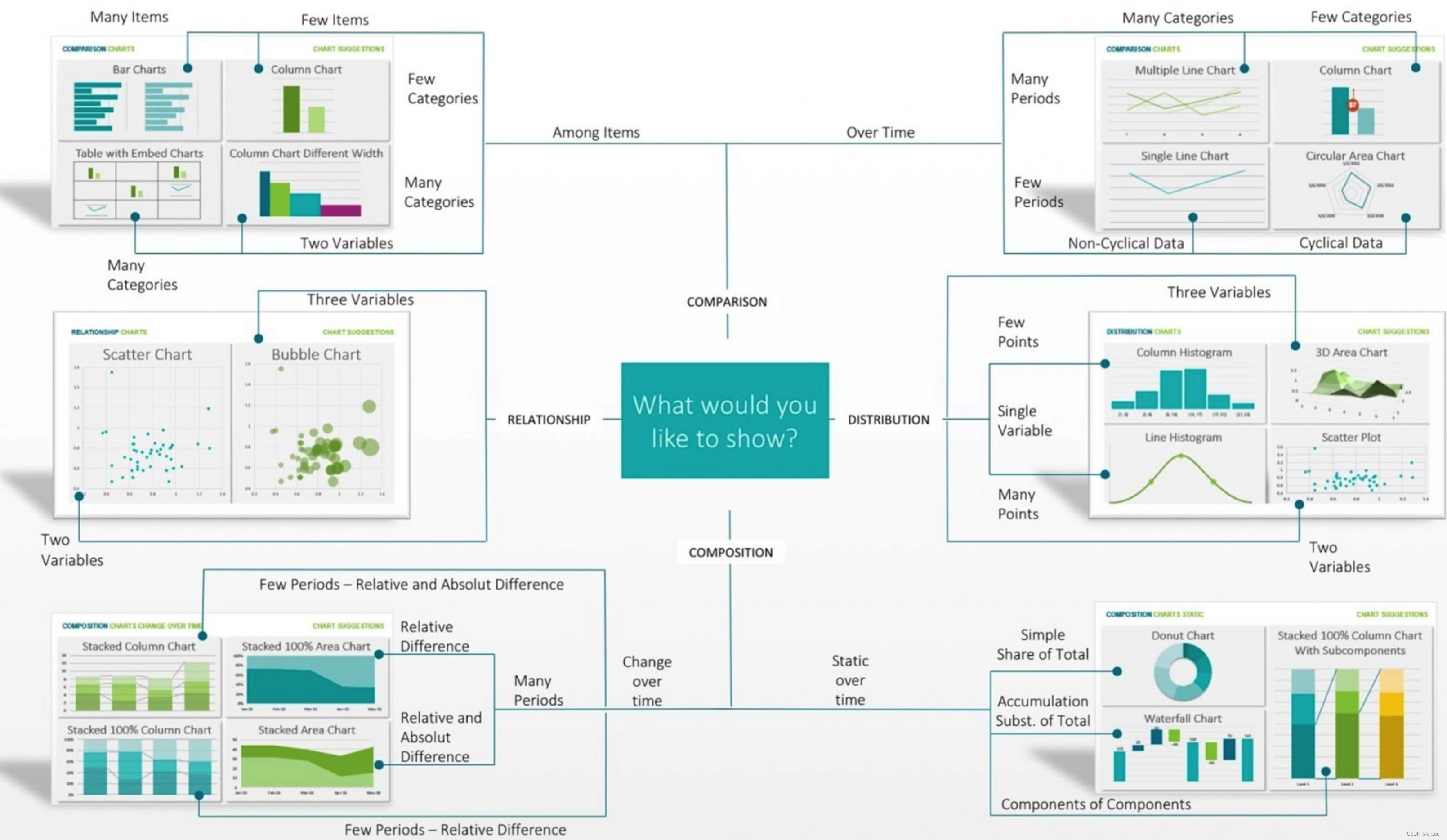
comparison(比较)、relationship(关系)、distribution(分布)和composition(组成)是进行数据可视化和探索性分析的四个分支。
- 比较分析:是指对数据中的不同变量或不同时间点的数据进行比较,以发现它们之间的差异和相似之处。常用的比较分析方法包括折线图、柱状图、堆积柱状图等。
- 关系分析:是指对数据中不同变量之间的相关性进行分析,以发现它们之间的关系和影响。常用的关系分析方法包括散点图、气泡图、雷达图等。
- 分布分析:是指对数据的分布情况进行分析,以发现数据的分布规律和异常情况。常用的分布分析方法包括直方图、密度图、箱线图等。
- 组成分析:是指对数据的组成部分进行分析,以发现它们之间的比例和关系。常用的组成分析方法包括饼图、堆积柱状图、簇状柱状图等。
通过对数据的可视化和探索性分析,我们可以更好地理解数据的特征和关系,发现其中的模式和异常,为进一步建模和分析做准备。
在Python中,我们可以使用pygwalker库进行数据可视化。
实例分析:如何运用pandas和pygwalker进行告警数据探索性分析
数据准备

首先,我们需要准备一份数据文件,例如名为alerts.xlsx的数据文件。该数据文件包含以下字段:
- 首次发生时间:告警的首次发生时间
- 持续时间:从告警首次发生到目前为止或告警关闭的持续时间
- 发次次数:告警发生的次数
- 告警对象:告警的对象主体是谁,如,某一个主机的IP、业务系统或服务
- 告警标题:告警发生了什么事情的简要描述,如,某主机发生FULLGC_COUNT的告警
- 告警来源:该告警是由哪个监控源系统报出来的,如prometheus、zabbix等
- 告警内容:用于描述告警发生的主要内容,如某某业务系统下的某主机IP发生FULLGC_COUNT异常…
数据载入
我们可以使用pandas的read_excel()函数读取数据文件,并将其转换为DataFrame格式,例如:
#载入pandas数据处理库
import pandas as pd
#载入pygwalker数据探索性分析库
import pygwalker as pyg
#pandas读取nb_alerts.xlsx告警数据文件
file = 'Users/wangjye/Documents/00-擎创/混沌工程-根因定位/alert_data/nb_alerts.xlsx
alerts = pd.read_excel(file)
#展示alerts中的文件内容,只展示开头的5条样本数据
alerts.head()

对数据进行摘要统计
读取数据文件后,我们可以使用pandas和pygwalker进行数据摘要统计。例如,我们可以使用info()函数查看数据的基本信息,使用describe()函数进行描述性统计,使用value_counts()函数进行频数统计,使用groupby()函数进行分类统计。例如:
我们也可以使用info()函数查看数据的基本信息,如字段信息、字段数据类型、非空值的统计记录数等信息:
alerts.info()
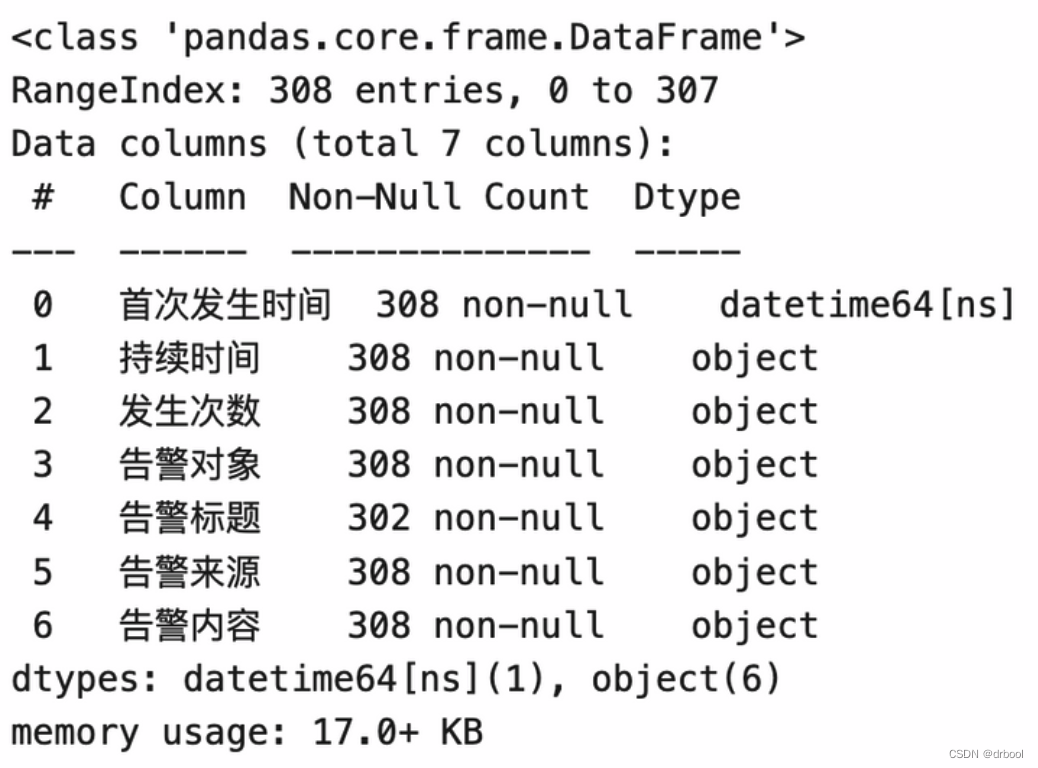
通过查看,我们可以看到告警标题存在空值的情况,而其它的字段都不存在空值,针对空值我们可以回头再关注一下告警的数据质量并确认:
- 是哪些告警来源的告警标题会为空
- 为什么为空
- 能否补充这些内容
可以通过value_counts()函数实现对告警数据中某个告警对象的发生次数的统计。
#对告警数据中,每个告警对象发生的告警次数进行统计,以查看哪些告警对象更容易出问题
print(alerts['告警对象'].value_counts()
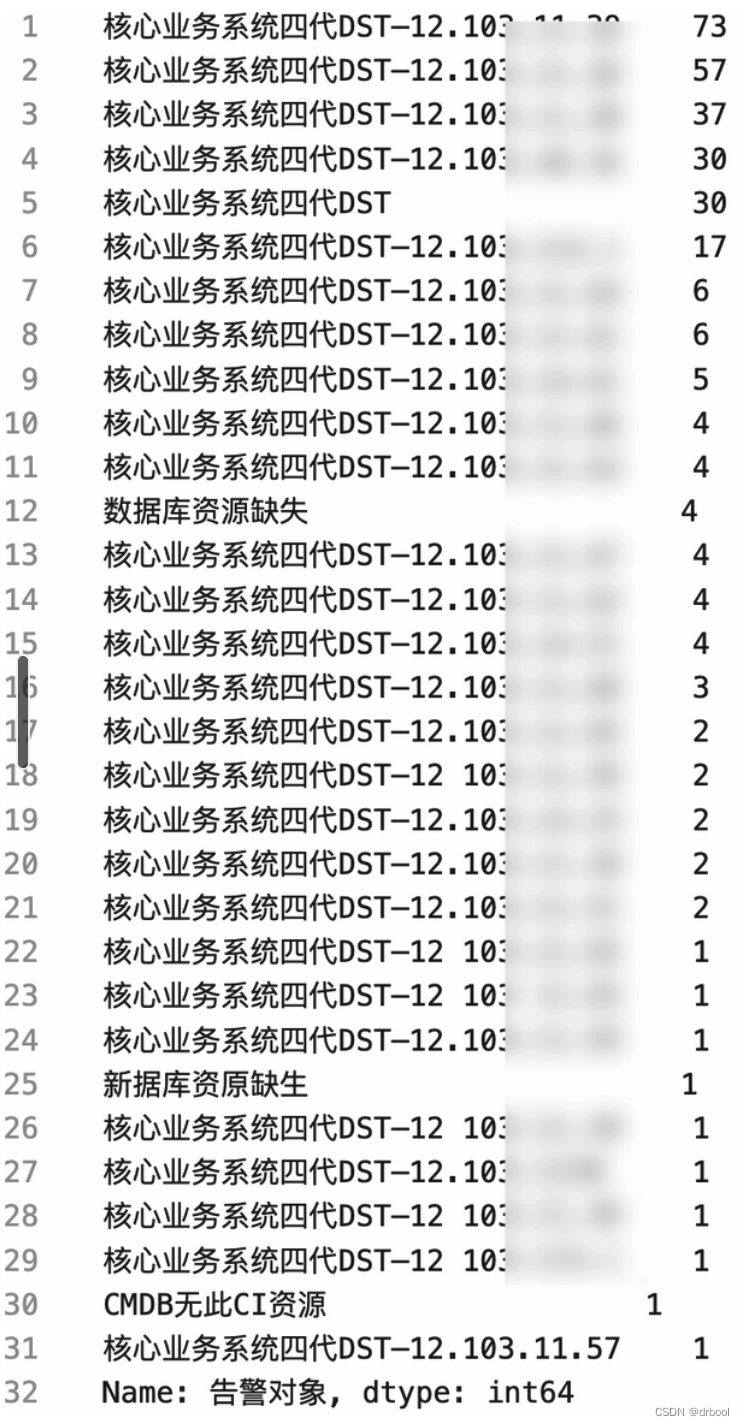
数据标准化处理
通过对数据的了解我们看到四个问题:
- 告警对象:格式是业务系统+主机的,我们需要拆分为业务系统、主机两个字段,以便我们更好地识别问题、定位问题。
- 告警标题:有缺失值,需要进行线下治理。
- 告警标题:有同一个指标所产生的问题,但是描述内容不一致的情况,需要进行统一。
- 首次发生时间:需要统计告警发生的时序特征进行根因探索性分析、周期性分析,因此需要进行时间维度的特征化处理。
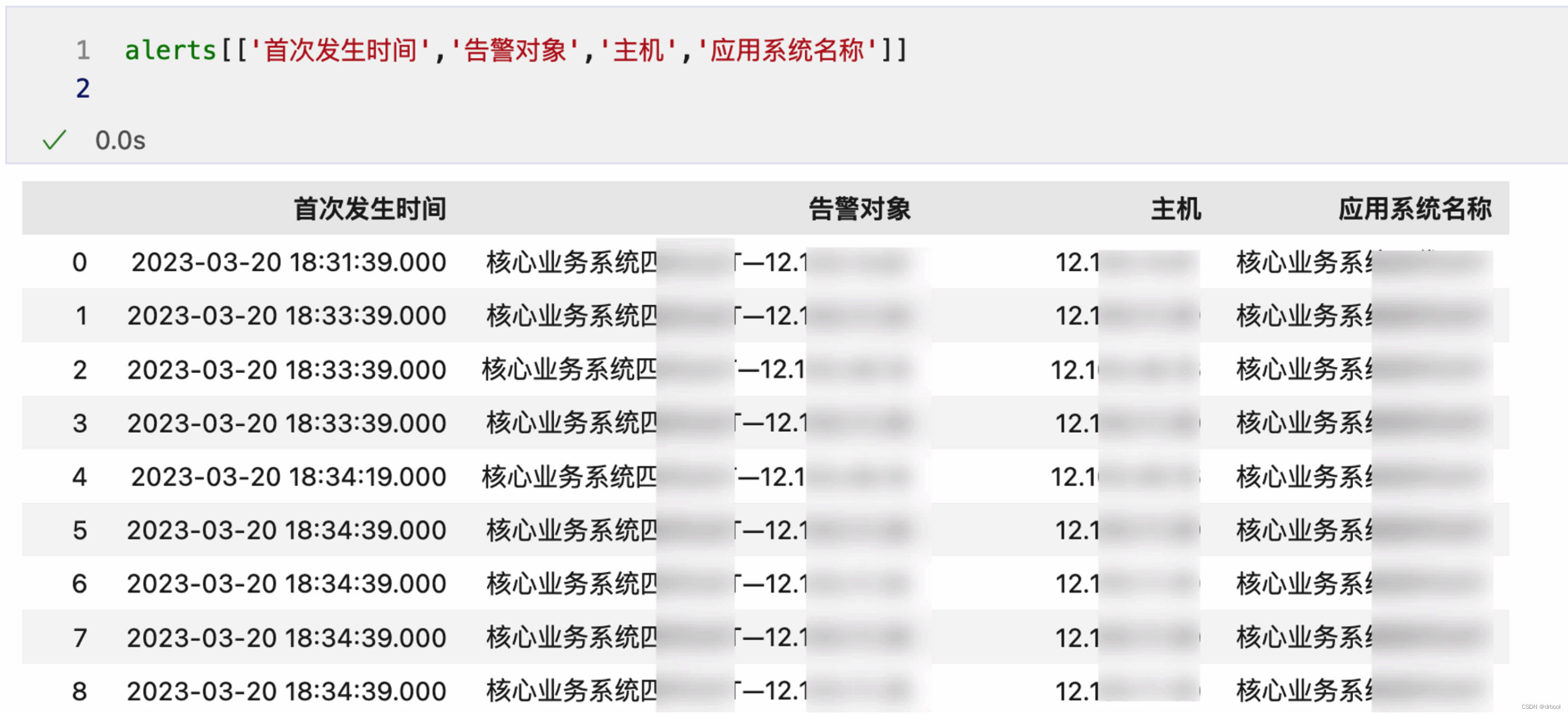
告警对象按业务系统和主机进行拆分:
#告警特征生成处理
#1.将告警对象中应用系统和主机IP进行拆分,生成**主机**及**应用系统**名称两个字段
alerts['主机'] = alerts['告警对象'].str.split('—',expand=True)[1]
alerts['业务系统名称'] = alerts['告警对象'].str.split('—',expand=True)[0]
#查看主机和应用系统名称是否正确拆分
alerts[['首次发生时间','告警对象','主机','应用系统名称']]
在进行分析过程中,我们发现某业务指标的“响应率”写为“响应军”导致在统计数据时不致的情况,进行数据治理操作如下:
#2.将告警中错误的指标名称进行统一标准化
alerts.loc[alerts['告警标题'] == '接口响应军','告警标题'] = '接口响应率'
对告警时序数据进行特征的生成:
#2-将时间拆分类,年、月、日、时、分,
alerts['年'] = alerts['首次发生时间'].dt.year.astype(str)
alerts['月'] = alerts['首次发生时间'].dt.month.astype(str)
alerts['日'] = alerts['首次发生时间'].dt.day.astype(str)
alerts['时'] = alerts['首次发生时间'].dt.hour.astype(str)
alerts['分'] = alerts['首次发生时间'].dt.minute.astype(str)
alerts['星期几'] = alerts['首次发生时间'].dt.dayofweek+1
#3-增加"时分"的组合
#print(str(alerts['首次发生时间'].dt.hour) + ':' + str(alerts['首次发生时间'].dt.minute)
alerts['时分'] = alerts['时'] +':' + alerts['分']
alerts['时分'] = alerts['时'] +':' + alerts['分']
#增加日、时分的组合,便于混沌工程中按特定的时段进行根因的时序分析
alerts['日时分'] = alerts['日'] + ' ' + alerts['时分']
#查看生成的告警结果
alerts

使用pygwalker进行探索性数据分析
pygwalker是一个Python的数据探索性分析库,它可以帮助用户快速探索数据,并通过可视化的方式发现数据的特征和关系。pygwalker可以直接将pandas中的dataframe做为参数进行可视化展示,因此在实际使用的过程中,pandas可以做一些数据的特征化处理、数据的载入、数据治理操作,而pygwalker进行可视化及探索性分析操作。
pygwalker载入pandas的告警数据
#载入pyg库
import pygwalker as pyg
#载入我们之前通过pandas处理好的告警数据
pyg.walk(alerts)
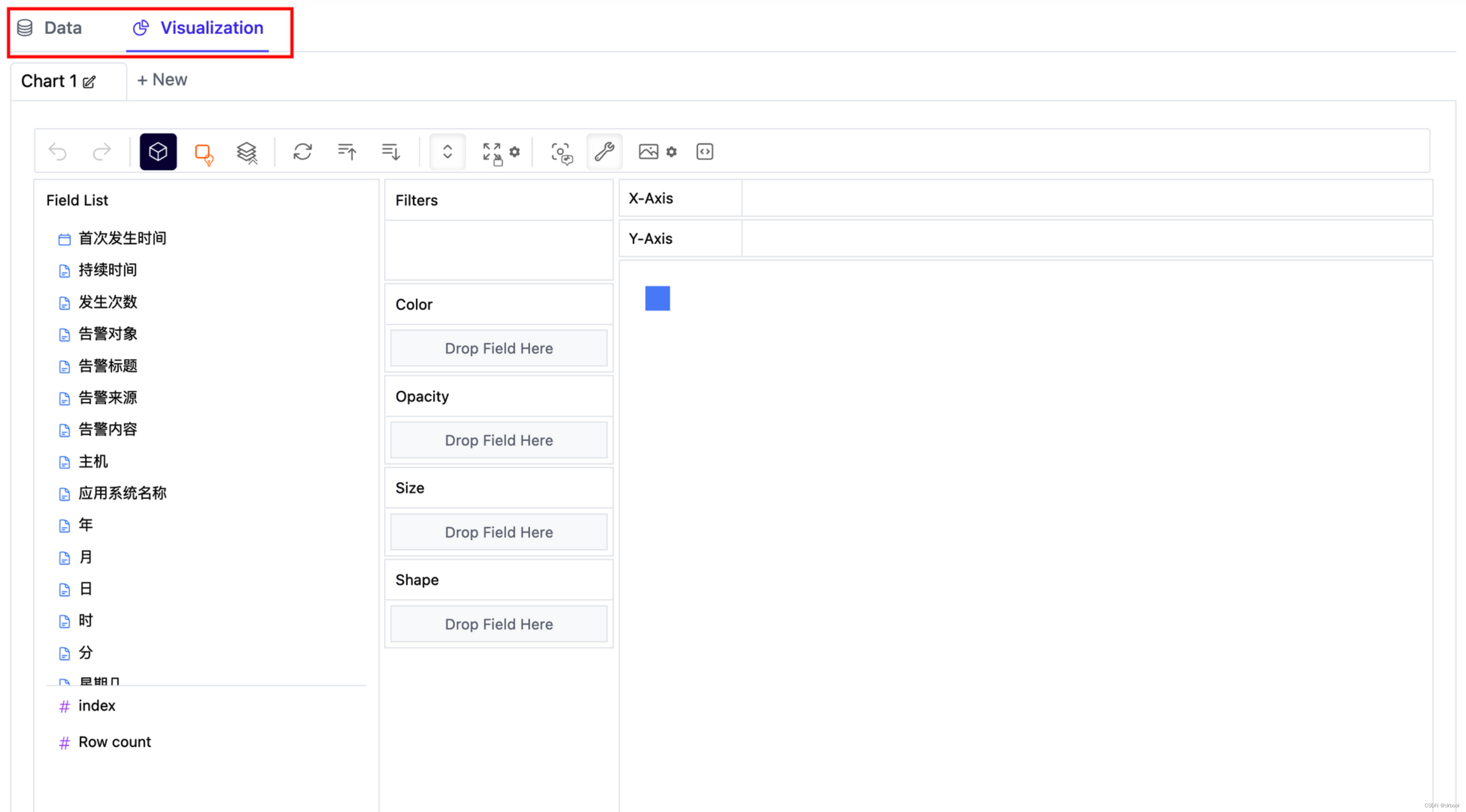
执行后,看到如下图所示的探索性分析界面:
- data:可以对所有的数据进行列表方式的查看
- Visualization:可以对数据进行可视化的分析及探索
点击data查看告警的列表数据,也可以在这里直接对数据的字段进行调整,不同的数据类型在进行探索性分析时效果不同,关注的读者可自行研究。
注意如下数据,可以左右拖动,以展示更多的数据列
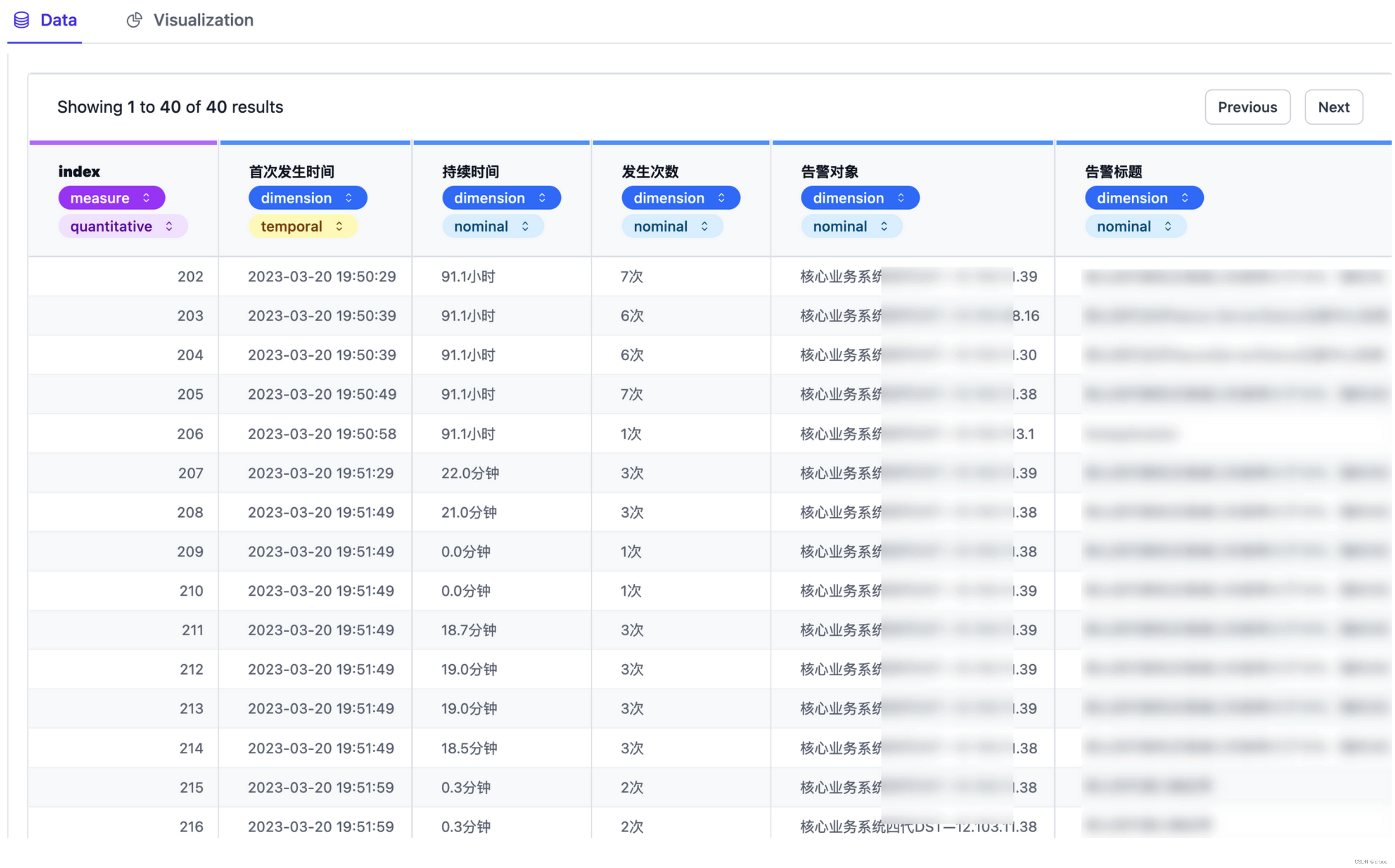
点击visualization我们可以进行数据的探索性分析:
1.主机告警量:查看所有记录中主机告警的次数统计柱状图,可以直接将左侧field list中的字段托动到X轴和Y轴即可。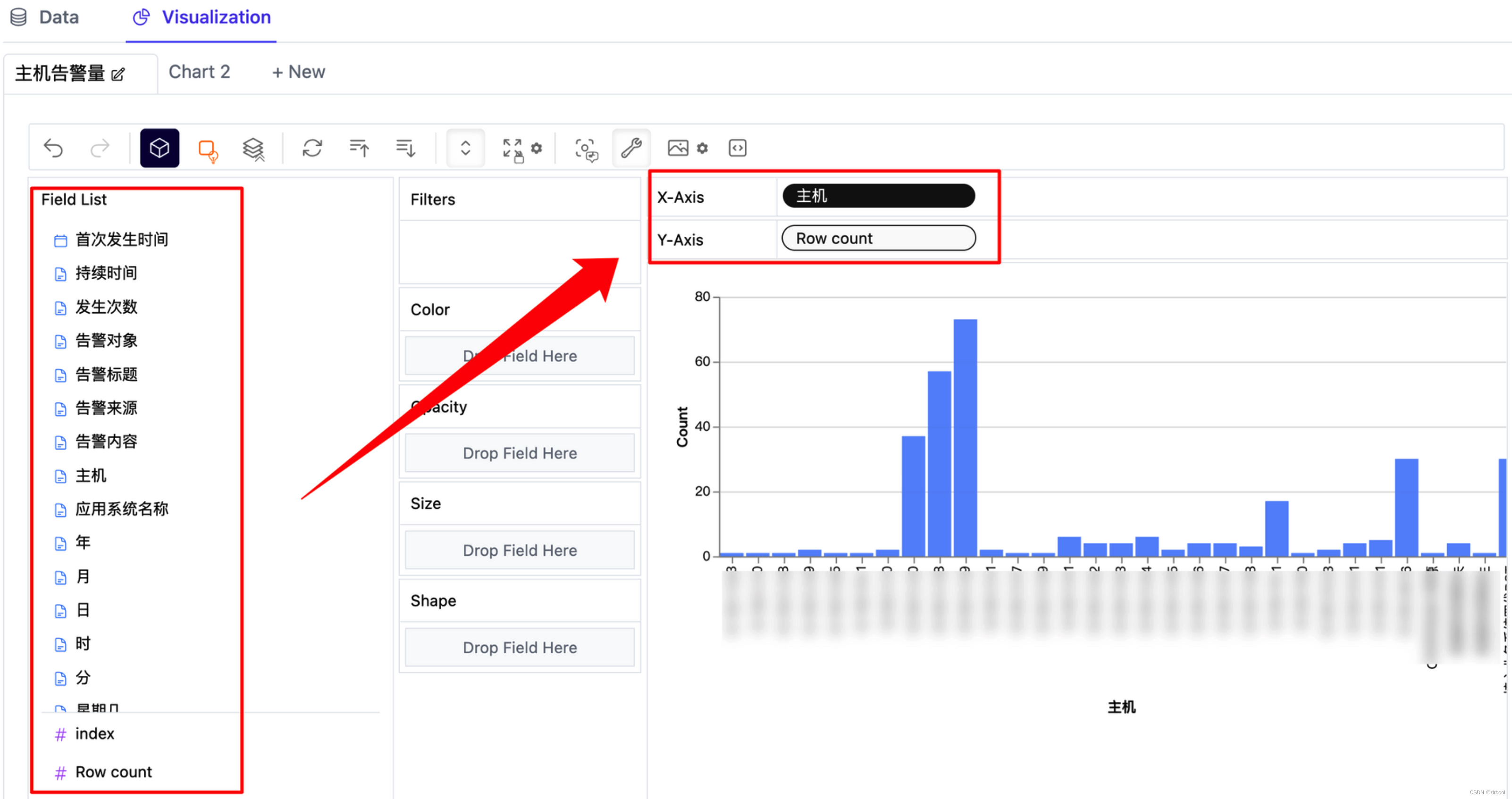
2.不同时段告警量:查看所有记录中不同时段的告警量分析结果,比较有利用判断一天中哪些时段比较容易发生告警

3.主机在不同时段的告警量统计:只需要在左侧的color中将主机字段进行添加即可生成如下图所结果
4.其它:其它更高级的您可以自行到pygwalker官方的使用手册中进行查询。
总结
本文介绍了如何使用pandas和pygwalker进行数据探索性分析,包括数据的载入、摘要统计、标准化处理和可视化分析等内容。通过本文的介绍,读者可以了解如何使用Python对数据进行分析和可视化,并从中发现数据的特征和关系。
关于作者
DRBOOL,资深的运维领域产品专家,对AIOps有深入的理解,曾参与多家银行AIOps实践,对国际主流AIOps厂商产品有深入理解,您也可以关注公众号。
















 2319
2319











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









