







参考
- C++多线程并发基础入门教程
- 我主要是对线程池部分做了拓展
什么是C++多线程并发?
- 线程:操作系统能够进行CPU调度的最小单位,它被包含在进程之中,一个进程可包含单个或者多个线程。可以用多个线程去完成一个任务,也可以用多个进程去完成一个任务。它的本质相当于多个人去合伙完成一件事情。
- 多线程并发:把一个任务拆分成多个子任务,然后交由不同线程处理不同子任务,使得多个子任务同时执行。
- C++多线程并发:将任务的不同功能交由多个函数分别实现,创建多个线程,每个线程执行一个函数,一个任务就这样同时由不同的线程执行了。
C++多线程并发基础知识
-
创建线程:构造std::thread对象
-
头文件==#include==,管理线程的函数和类,包括std::thread
-
只要创建了线程,线程就开始执行
std::thread th1(process1);//创建一个名为th1的线程,并且th1开始执行 //实例化std::thread类对象时,至少需要传递函数名作为参数 void process2(int a, int b) { //函数体 } //实例化std::thread类对象 //参数顺序依次为函数名、函数的第一个参数、函数的第二个参数 std::thread(process2, a, b); -
当线程启动后,一定要在线程相关联的std::thread对象销毁前,对线程运用join()和detach()
join()与detach()都是std::thread类的成员函数,是两种线程阻塞方法。
-
join():等待调用线程运行结束后当前线程再继续运行
例如主函数有一条语句th1.join(),那么执行到在这里,主函数阻塞,直到线程th1运行结束,主函数再继续运行。
#include<iostream> #include<thread> using namespace std; void proc(int a) { cout << "我是子线程,传入参数为" << a << endl; cout << "子线程中显示子线程id为" << this_thread::get_id()<< endl; } int main() { cout << "我是主线程" << endl; int a = 9; thread th2(proc, a);//第一个参数为函数名,第二个参数为该函数的第一个参数,线程开始执行。 cout << "主线程中显示子线程id为" << this_thread::get_id() << endl; th2.join();//此时主线程被阻塞,等待子线程th2执行结束再继续执行主线程。 return 0; }调用join()会清理线程相关的存储部分,这代表了join()只能调用一次。使用joinable()来判断join()可否调用。
-
detach():detach()也只能调用一次,一旦detach()后就无法join()了,detach()可否调用也是使用joinable()来判断。
可能存在主线程比子线程先结束的情况,主线程结束后会释放掉自身的内存空间;在创建线程时,如果std::thread类传入的参数含有引用或指针,则子线程中的数据依赖于主线程中的内存,主线程结束后会释放掉自身的内存空间,则子线程会出现错误。
-
-
-
互斥量的使用(锁)
单位上有一台打印机(共享数据a),你要用打印机(线程1要操作数据a),同事老王也要用打印机(线程2也要操作数据a),但是打印机同一时间只能给一个人用,规定不管是谁,在用打印机之前都要向领导申请许可证(lock),用完后再向领导归还许可证(unlock),许可证总共只有一个,没有许可证的人就等着在用打印机的同事用完后才能申请许可证(阻塞,线程1lock互斥量后其他线程就无法lock,只能等线程1unlock后,其他线程才能lock)。那么,打印机就是共享数据,访问打印机的这段代码就是临界区,这个必须互斥使用的许可证就是互斥量(锁)。
互斥量是为了解决数据共享过程中可能存在访问冲突的问题。
-
死锁
多线程编程的时候要考虑多个线程同时访问共享资源所造成的问题,因此可以通过加锁来保证同一时刻只有一个线程能访问共享资源,使用锁的时候不能出现死锁。
死锁是多个线程争夺共享资源导致每个线程都不能取得自己所需的全部资源,从而程序无法向下执行。
产生死锁的必要条件:这四个条件导致死锁
- 互斥(资源同一时刻只能被一个进程使用)
- 请求并保持(进程在申请资源时,不释放自己已经占有的资源)
- 不剥离(进程已经获得的资源,在进程使用前完成,不能强制剥离)
- 循环等待(进程间形成环状的资源循环等待关系)A等B,B等C,C等A,死循环情况
死锁预防:
- 破坏死锁产生的四个条件
死锁避免:
- 对分配资源做安全性检查,确保不会产生循环等待(银行家算法)
死锁检测:
- 允许死锁发生,但提供检测方法
死锁解除:
- 已经产生了死锁,强制剥夺资源或者撤销进程
-
临界区、信号量、互斥量(锁)的区别与联系
- 临界区速度最快,但只能作用于同一进程下不同线程,不能作用于不同进程;临界区可确保某一代码段同一时刻只被一个线程执行;
- 信号量多个线程同一时刻访问共享资源,进行线程的计数,确保同时访问资源的线程数目不超过上限,当访问数超过上限后,不发出信号量;
- 互斥量(锁)比临界区慢,但支持不同进程间的同步与互斥;
-
互斥锁
互斥量mutex就是互斥锁,加锁的资源支持互斥访问
-
读写锁shared_mutex
shared_mutex读写锁把对共享资源的访问者划分成读者和写者,多个读线程能同时读取共享资源,但只有一个写线程能同时读取共享资源
shared_mutex通过lock_shared,unlock_shared进行读者的锁定与解锁;通过lock,unlock进行写者的锁定与解锁。
shared_mutex s_m; std::string book; //允许多个读线程同时读取共享资源 void read() { s_m.lock_shared();//读线程锁 cout << book; s_m.unlock_shared();//读线程解锁 } //同一时刻,只允许一个写线程读取共享资源 void write() { s_m.lock();//写线程锁 book = "new context"; s_m.unlock();//写线程解锁 } -
自旋锁
如果自旋锁已经被别的执行单元保持,调用者就一直循环在那里看是否该自旋锁的保持者已经释放了锁;
自旋锁比较适用于锁使用者保持锁时间比较短的情况
-
互斥量(锁)怎么使用?
-
头文件#include
-
std::mutex
#include<iostream> #include<thread> #include<mutex> using namespace std; mutex m;//实例化m对象,不要理解为定义变量 void proc1(int a) { m.lock(); cout << "proc1函数正在改写a" << endl; cout << "原始a为" << a << endl; cout << "现在a为" << a + 2 << endl; m.unlock(); } void proc2(int a) { m.lock(); cout << "proc2函数正在改写a" << endl; cout << "原始a为" << a << endl; cout << "现在a为" << a + 1 << endl; m.unlock(); } int main() { int a = 0; thread t1(proc1, a);//创建一个名为t1的线程,并且t1开始执行 thread t2(proc2, a);//创建一个名为t2的线程,并且t2开始执行 t1.join();//此时主线程被阻塞,等待子线程th1执行结束再继续执行主线程 t2.join();//此时主线程被阻塞,等待子线程th2执行结束再继续执行主线程 return 0; }当一个线程使用特定互斥量锁住共享数据时,其他的线程想要访问锁住的数据,都必须等到之前那个线程对数据进行解锁后,才能进行访问。
不推荐直接调用成员函数lock(),因为如果忘记unlock(),将导致锁无法释放,使用lock_guard或者unique_lock则能避免忘记解锁带来的问题。
-
std::lock_guard
声明一个局部的std::lock_guard对象,在其构造函数中进行加锁,在其析构函数中进行解锁。最终的结果就是:创建即加锁,作用域结束自动解锁。从而使用std::lock_guard()就可以替代lock()与unlock()。
通过设定作用域,使得std::lock_guard在合适的地方被析构
#include<iostream> #include<thread> #include<mutex> using namespace std; mutex m;//实例化m对象,不要理解为定义变量 void proc1(int a) { lock_guard<mutex> g1(m);//用此语句替换了m.lock();lock_guard传入一个参数时,该参数为互斥量,此时调用了lock_guard的构造函数,申请锁定m cout << "proc1函数正在改写a" << endl; cout << "原始a为" << a << endl; cout << "现在a为" << a + 2 << endl; }//此时不需要写m.unlock(),g1出了作用域被释放,自动调用析构函数,于是m被解锁 void proc2(int a) { { lock_guard<mutex> g2(m); cout << "proc2函数正在改写a" << endl; cout << "原始a为" << a << endl; cout << "现在a为" << a + 1 << endl; }//通过使用{}来调整作用域范围,可使得m在合适的地方被解锁 cout << "作用域外的内容3" << endl; cout << "作用域外的内容4" << endl; cout << "作用域外的内容5" << endl; } int main() { int a = 0; thread t1(proc1, a);//创建一个名为t1的线程,并且t2开始执行 thread t2(proc2, a);//创建一个名为t2的线程,并且t2开始执行 t1.join();//此时主线程被阻塞,等待子线程th1执行结束再继续执行主线程 t2.join();//此时主线程被阻塞,等待子线程th2执行结束再继续执行主线程 return 0; } -
std::unique_lock
std::unique_lock类似于lock_guard,只是std::unique_lock用法更加丰富,同时支持std::lock_guard()的原有功能。 使用std::lock_guard后不能手动lock()与手动unlock();使用std::unique_lock后可以手动lock()与手动unlock();
#include<iostream> #include<thread> #include<mutex> using namespace std; mutex m; void proc1(int a) { unique_lock<mutex> g1(m, defer_lock);//始化了一个没有加锁的mutex cout << "xxxxxxxx" << endl; g1.lock();//手动加锁,注意,不是m.lock();注意,不是m.lock(),m已经被g1接管了; cout << "proc1函数正在改写a" << endl; cout << "原始a为" << a << endl; cout << "现在a为" << a + 2 << endl; g1.unlock();//临时解锁 cout << "xxxxx" << endl; g1.lock(); cout << "xxxxxx" << endl; }//自动解锁 void proc2(int a) { unique_lock<mutex> g2(m, try_to_lock);//尝试加锁一次,但如果没有锁定成功,会立即返回,不会阻塞在那里,且不会再次尝试锁操作。 if (g2.owns_lock()) {//锁成功 cout << "proc2函数正在改写a" << endl; cout << "原始a为" << a << endl; cout << "现在a为" << a + 1 << endl; } else {//锁失败则执行这段语句 cout << "" << endl; } }//自动解锁 int main() { int a = 0; thread t1(proc1, a); t1.join(); //thread t2(proc2, a); //t2.join(); return 0; }使用try_to_lock要小心,因为try_to_lock尝试锁失败后不会阻塞线程,而是继续往下执行程序,因此,需要使用if-else语句来判断是否锁成功,只有锁成功后才能去执行互斥代码段。而且需要注意的是,因为try_to_lock尝试锁失败后代码继续往下执行了,因此该语句不会再次去尝试锁。
-
对比 lock_guard unique_lock 手动lock与手动unlock 不支持 支持 参数 adopt_lock:构造函数中不进行互斥量锁定,需要提前手动锁定 adopt_lock:构造函数中不进行互斥量锁定,需要提前手动锁定。 try_to_lock: 尝试去锁定,得保证锁处于。unlock的状态,然后尝试现在能不能获得锁。 defer_lock: 始化了一个没有加锁的mutex
-
-
condition_variable:
#include<condition_variable>
它的作用是用来同步线程,它的用法相当于编程中常见的flag标志(A、B两个人约定flag=true为行动号角,默认flag为false,A不断的检查flag的值,只要B将flag修改为true,A就开始行动)。
A、B两个人约定notify_one为行动号角,A就等着(调用wait(),阻塞),只要B一调用notify_one,A就开始行动(不再阻塞)。
- wait(locker) :wait函数需要传入一个std::mutex(一般会传入std::unique_lock对象),即上述的locker。wait函数会自动调用 locker.unlock() 释放锁(因为需要释放锁,所以要传入mutex)并阻塞当前线程,本线程释放锁使得其他的线程得以继续竞争锁。一旦当前线程获得notify(通常是另外某个线程调用 notify_* 唤醒了当前线程),wait() 函数此时再自动调用 locker.lock()上锁。
- cond.notify_one(): 随机唤醒一个等待的线程
- cond.notify_all(): 唤醒所有等待的线程
-
-
生产者消费者问题
生产者消费者模型是典型的多线程并发协作模型
-
生产者:用于生成数据,生产一个就往共享数据区存一个,如果共享数据区已满的话,生产者就暂停生产,等待消费者的通知后再启动
-
消费者:用于消费数据,一个一个的从共享数据区取,如果共享数据区为空的话,消费者就暂停取数据,等待生产者的通知后再启动
-
生产者和消费者不能直接交互,他们之间所共享的数据使用队列结构来实现
-
以下代码编译方法:
g++ test.cc -o a.out -std=c++11 -pthread#include<iostream> #include<thread> #include<mutex> #include<queue> #include<condition_variable> using namespace std; //缓冲区存储的数据类型 struct CacheData { int id;//商品id string data;//商品属性 }; queue<CacheData> Q;//定义缓冲区 const int MAX_CACHEDATA_LENGTH = 10;//缓冲区最大空间 mutex m;//互斥量(锁),生产者之间,消费者之间,生产者和消费者之间,同时都只能一个线程访问缓冲区 condition_variable condConsumer; condition_variable condProducer; int ID = 1;//全局商品id //消费者动作 void ConsumerActor() { unique_lock<mutex> lockerConsumer(m);//加锁 cout << "[" << this_thread::get_id() << "] 获取了锁" << endl; while (Q.empty()) { cout << "因为队列为空,所以消费者Sleep" << endl; cout << "[" << this_thread::get_id() << "] 不再持有锁" << endl; //队列空,消费者停止,等待生产者唤醒,线程阻塞 condConsumer.wait(lockerConsumer); cout << "[" << this_thread::get_id() << "] Weak, 重新获取了锁" << endl; } cout << "[" << this_thread::get_id() << "] "; CacheData temp = Q.front(); cout << "- ID:" << temp.id << " Data:" << temp.data << endl; Q.pop(); condProducer.notify_one(); cout << "[" << this_thread::get_id() << "] 释放了锁" << endl; }//lockerConsumer出了作用域,自动解锁 //生产者动作 void ProducerActor() { unique_lock<mutex> lockerProducer(m);//加锁 cout << "[" << this_thread::get_id() << "] 获取了锁" << endl; while (Q.size() >= MAX_CACHEDATA_LENGTH) { cout << "因为队列为满,所以生产者Sleep" << endl; cout << "[" << this_thread::get_id() << "] 不再持有锁" << endl; //对列已满,生产者停止,等待消费者唤醒,线程阻塞 condProducer.wait(lockerProducer); cout << "[" << this_thread::get_id() << "] Weak, 重新获取了锁" << endl; } cout << "[" << this_thread::get_id() << "] "; CacheData temp; temp.id = ID++; temp.data = "*****"; cout << "+ ID:" << temp.id << " Data:" << temp.data << endl; Q.push(temp); condConsumer.notify_one(); cout << "[" << this_thread::get_id() << "] 释放了锁" << endl; }//lockerProducer出了作用域,自动解锁 //消费者 void ConsumerTask() { while(1) { ConsumerActor(); } } //生产者 void ProducerTask() { while(1) { ProducerActor(); } } //管理线程的函数 void Dispatch(int ConsumerNum, int ProducerNum) { vector<thread> thsC; for (int i = 0; i < ConsumerNum; ++i) { thsC.push_back(thread(ConsumerTask)); } vector<thread> thsP; for (int j = 0; j < ProducerNum; ++j) { thsP.push_back(thread(ProducerTask)); } for (int i = 0; i < ConsumerNum; ++i) { if (thsC[i].joinable()) { thsC[i].join(); } } for (int j = 0; j < ProducerNum; ++j) { if (thsP[j].joinable()) { thsP[j].join(); } } } int main() { //1个消费者线程,5个生产者线程,则生产者经常要等待消费者 Dispatch(1,5); return 0; }
线程池
采用线程池时:创建线程 -> 由该线程执行任务 -> 任务执行完毕后销毁线程。即使需要使用到大量线程,每个线程都要按照这个流程来创建、执行与销毁。
虽然创建与销毁线程消耗的时间远小于线程执行的时间,但是对于需要频繁创建大量线程的任务,创建与销毁线程 所占用的时间与CPU资源也会有很大占比。
-
为了减少创建与销毁线程所带来的时间消耗与资源消耗,因此采用线程池的策略:
程序启动后,预先创建一定数量的线程放入空闲队列中,这些线程都是处于阻塞状态,基本不消耗CPU,只占用较小的内存空间。接收到任务后,任务被挂在任务队列,线程池选择一个空闲线程来执行此任务。任务执行完毕后,不销毁线程,线程继续保持在池中等待下一次的任务。
-
线程池所解决的问题:
需要频繁创建与销毁大量线程的情况下,由于线程预先就创建好了,接到任务就能马上从线程池中调用线程来处理任务,减少了创建与销毁线程带来的时间开销和CPU资源占用。
需要并发的任务很多时候,无法为每个任务指定一个线程(线程不够分),使用线程池可以将提交的任务挂在任务队列上,等到池中有空闲线程时就可以为该任务指定线程。
-
线程池代码
#include <condition_variable> #include <functional> #include <future> #include <memory> #include <mutex> #include <queue> #include <stdexcept> #include <thread> #include <utility> #include <vector> #include <iostream> class ThreadPool { public: explicit ThreadPool(size_t thread_size); template <class F, class... Args> auto enqueue(F&& f, Args&&... args) -> std::future<typename std::result_of<F(Args...)>::type>; ~ThreadPool(); private: // need to keep track of threads so we can join them std::vector<std::thread> workers_; // the task queue std::queue<std::function<void()> > tasks_; // 同步 std::mutex queue_mutex_; std::condition_variable condition_; bool stop_; }; // 构造函数,启动一些线程 inline ThreadPool::ThreadPool(size_t thread_size) : stop_(false) { auto thread_handler = [this] { for (;;) { std::function<void()> task; { std::unique_lock<std::mutex> lock(queue_mutex_); condition_.wait(lock, [this] { return stop_ || !tasks_.empty(); }); if (stop_ && tasks_.empty()) return; task = std::move(tasks_.front()); tasks_.pop(); } task(); } }; for (size_t i = 0; i < thread_size; ++i) { workers_.emplace_back(thread_handler); } } // 将新的任务添加到线程池中 template <class F, class... Args> auto ThreadPool::enqueue(F&& f, Args&&... args) -> std::future<typename std::result_of<F(Args...)>::type> { using return_type = typename std::result_of<F(Args...)>::type; auto task = std::make_shared<std::packaged_task<return_type()> >( std::bind(std::forward<F>(f), std::forward<Args>(args)...)); std::future<return_type> res = task->get_future(); { std::unique_lock<std::mutex> lock(queue_mutex_); // don't allow enqueueing after stopping the pool if (stop_) throw std::runtime_error("enqueue on stopped ThreadPool"); tasks_.emplace([task]() { (*task)(); }); } condition_.notify_one(); return res; } // 析构函数,join所有线程 inline ThreadPool::~ThreadPool() { { std::unique_lock<std::mutex> lock(queue_mutex_); stop_ = true; } condition_.notify_all(); for (std::thread& worker : workers_) { worker.join(); } } void fun1(int a) { std::cout << "a: " << std::this_thread::get_id() << " " << a << std::endl; } int main() { ThreadPool thread_pool_(2);//构造一个含有两个线程的线程池 int a = 1; while (1) { //利用线程池处理fun1 thread_pool_.enqueue(fun1, a); } return 0; }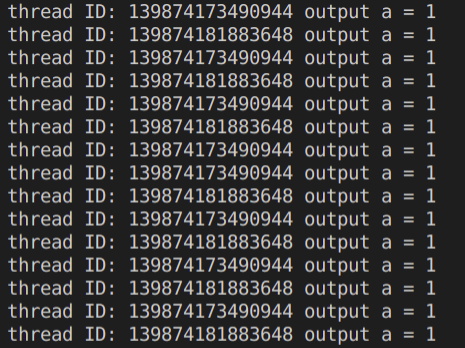
获取线程ID,可以看到线程ID为44和48的两个线程交替输出a=1,两个子线程。
-
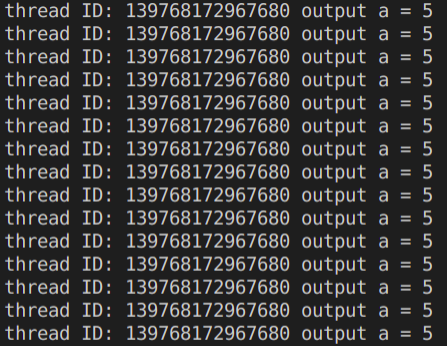
单线程代码
#include <thread> #include <iostream> void fun1(int a) { std::cout << "thread ID: " << std::this_thread::get_id() << " output a = " << a << std::endl; } int main() { int a = 5; while (1) { std::thread th(fun1, 5); th.join(); } return 0; }单线程输出情况,只有一个ID
如果大家觉得总结的还不错,那就点个赞吧哈哈哈















 2561
2561











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









