






参考:飞桨PaddlePaddle-源于产业实践的开源深度学习平台
自然语言处理 Paddle NLP - 检索式文本问答-理论 - VipSoft - 博客园 (cnblogs.com)
词向量(Word Embedding)是表示自然语言里单词的一种方法,即把每个词都表示为一个N维空间内的点,即一个高维空间内的向量。通过这种方法,实现把自然语言计算转换为向量计算。

先把每个词(如queen,king等)转换成一个高维空间的向量,这些向量在一定意义上可以代表这个词的语义信息。再通过计算这些向量之间的距离,就可以计算出词语之间的关联关系,从而达到让计算机像计算数值一样去计算自然语言的目的。
如何把词转换为向量? 自然语言单词是离散信号,比如“香蕉”,“橘子”,“水果”在我们看来就是3个离散的词。 如何把每个离散的单词转换为一个向量?
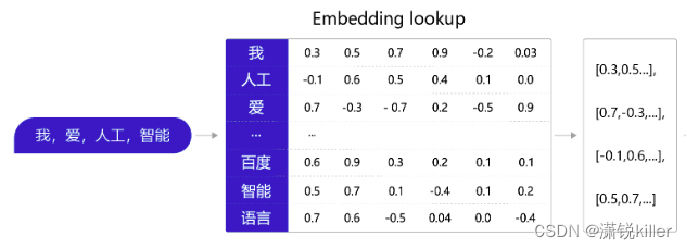
通常情况下,我们可以维护一个如 图 所示的查询表。表中每一行都存储了一个特定词语的向量值,每一列的第一个元素都代表着这个词本身,以便于我们进行词和向量的映射(如“我”对应的向量值为 [0.3,0.5,0.7,0.9,-0.2,0.03] )
先把每个词(如queen,king等)转换成一个高维空间的向量,这些向量在一定意义上可以代表这个词的语义信息。 再通过计算这些向量之间的距离,就可以计算出词语之间的关联关系,从而达到让计算机像计算数值一样去计算自然语言的目的。

1、通过查询字典,先把句子中的单词转换成一个ID(通常是一个大于等于0的整数),我=>1, 人工=>2,爱=>3,…)
2、得到ID后,再把每个ID转换成一个固定长度的向量。 假设字典的词表中有5000个词,那么,对于单词“我”,就可以用一个5000维的向量来表示。 由于“我”的ID是1,因此这个向量的第一个元素是1,其他元素都是0([1,0,0,…,0]); 由于每个单词的向量表示都只有一个元素为1,而其他元素为0,因此我们称上述过程为One-Hot Encoding。
张量本质上是一种**多维数组**,它可以用来表示具有特定维度结构和数值的数据。 张量的概念扩展了标量(0维张量,即单个数字)、向量(1维张量,一列有序数字)和矩阵(2维张量,由行和列构成的矩形数字阵列)的概念,以涵盖更高维度的数据结构。 张量的维度被称为秩(rank),它对应于张量中独立索引的数量。 阶数与维度: 张量的阶数(rank)指定了它涉及向量空间的数量。一阶张量即为向量,二阶张量可以理解为矩阵,三阶及更高阶张量则对应更复杂的多维数组结构。 张量的维度是指其在某个坐标系下的分量总数,通常用一个列表或元组来表示其各模式(mode)的大小。比如,一个三维张量可能有形状 (m, n, p),表示它有 m 行、n 列和 p 层。 独热编码会创建一组新的二进制特征(通常是虚拟或指示符变量),其中每一个新特征代表原特征中的一个特定类别。
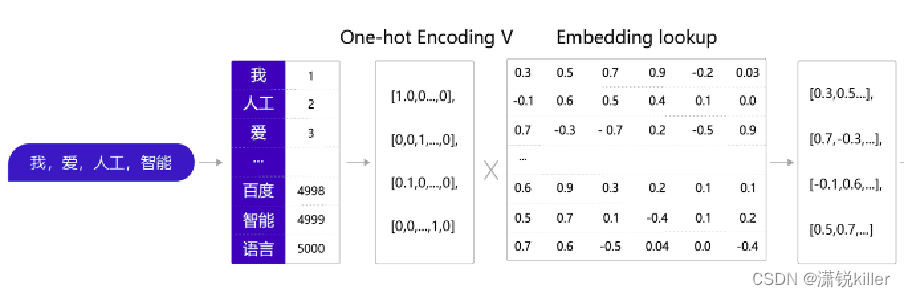
3、经过One-Hot Encoding后,句子“我,爱,人工,智能”就被转换成为了一个形状为 4×5000的张量 在这个张量里共有4行、5000列,从上到下,每一行分别代表了“我”、“爱”、“人工”、“智能” 四个单词的One-Hot Encoding
4、把这个张量V和另外一个稠密张量W相乘,其中W张量的形状为5000 × 128(5000表示词表大小,128表示 每个词的向量大小)。经过张量乘法,我们就得到了一个4×128的张量,从而完成了把单词表示成向量。
稠密张量的初始值通常是由特定的词向量学习算法自动生成的。这些算法旨在将每个词汇映射到一个低维、稠密的向量空间中,使得语义相关的词在该空间中的向量距离较近,而不相关的词则距离较远。 预训练模型:直接使用已经训练好的词向量模型(如Word2Vec、GloVe、FastText、BERT、ELMo等)提供的词向量作为初始值。这些模型基于大规模文本语料库学习得到,其词向量蕴含丰富的语言学和语义信息,能够为后续任务提供良好的起点。 5000×128 的张量 行数(5000) 表示词表大小,即词汇表中不同词语的数量。这意味着您的词汇表包含5000个不同的词语或词项。 列数(128) 表示每个词的向量大小,即每个词语在词向量空间中所对应的向量维度。这意味着每个词语都被表示为一个长度为128的浮点数向量。
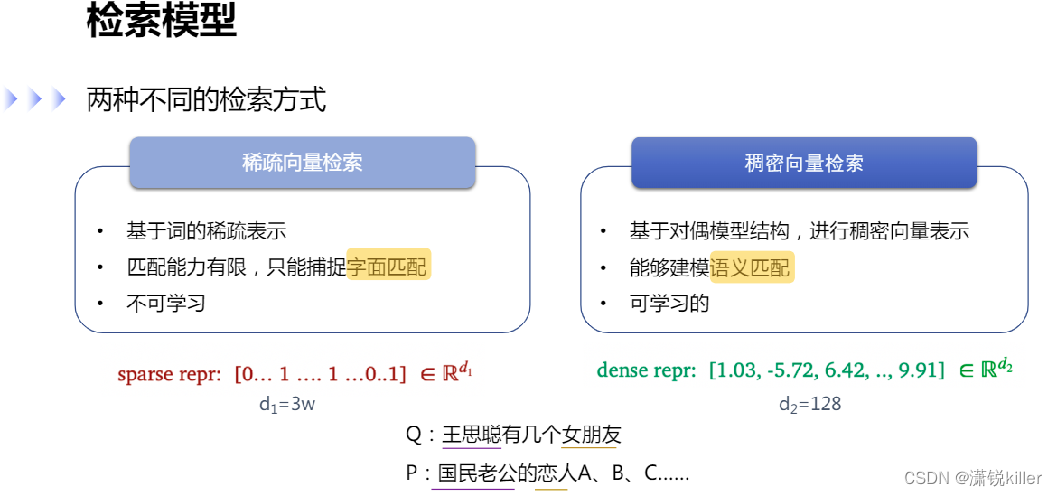
稀疏向量检索:双塔 基于词的稀疏表示 匹配能力有限,只能捕捉字面匹配 不可学习 把文本表示成 one hot (拼写可能有错)的形式,常见的有 TFDF、BM? 文章编码成向量,向量的长度和词典的大小一致,比如词典的大小是3W,稀疏向量表示3W, 每个位置表示这个词有没有在问题中出现过,出现过就是1 倒排索引,一般采用稀疏向量方式,只能做字面匹配 稀疏向量,几百、上千万的文档都支持
稠密向量检索:单塔 基于对偶模型结构,进行稠密向量表示 能够建模语义匹配 可学习的 把文本表示成稠密向量,也就是 Embedding,需要通过模型,对文本的语义信息进行建模,然后把信息记录在向量里,这边的向量长度,一般是128、256、768,相较于稀疏向量检索小很多,每个位置的数字是浮点数 一般通过对偶模型的结构进行训练,来获得建模的语义向量, 例: Q:王思聪有几个女朋友 P:国民老公的恋人A、B、C...... 如果通过 稀疏向量检索,可能完全匹配不到 稠密向量检索,可以学习到,国民老公=>王思聪,恋人=> 女朋友
文本匹配中的两种模型结构
对偶式模型结构:问题、段落分别编码,得到各自的 Embedding,然后通过内积或者 cosin 来计算向量之间的相似度,这个相似度代表了问题和段落之间的匹配程度 问题和段落之间难以交互,因为他们是分别编码的。底层没有交互,所以逻辑会弱些 可以快速索引,可以提前把段落向量这边计算好
交互式模型结构:输入把问题和段落拼一起,在中间交互层问题的文本和段落的文本会有个完全的交互。最后输出一个来表示问题和段落的匹配程度 对偶模型的参数可以共享,共享参数对字面匹配效果好些,不共享效果也差不了太多 实际应用中,把所有的文档都计算完,把向量存储下来。在线计算时,直接去检索
单塔模型 常用于处理稠密向量(如通过深度学习模型生成的低维、连续且大部分元素非零的特征向量,如词嵌入、深度特征提取等)的检索任务。单塔模型只有一个共享的神经网络结构: 共享塔(Shared Tower):对于用户和物品,都通过相同的神经网络结构进行编码,生成各自的向量表示。输入可以是用户和物品的联合特征,也可以是各自独立的特征,然后通过共享的权重进行学习。 在训练阶段,单塔模型通过联合学习用户和物品的向量表示,使得正样本对的向量相似度高于负样本对。与双塔模型类似,也常常采用对比学习或最大内积采样等策略。 在推理阶段,给定一个用户,通过共享塔生成用户向量,然后与所有物品向量(同样通过共享塔预先计算并存储)计算相似度,以找到最相关的物品。虽然单塔模型没有像双塔模型那样明确分离用户和物品的处理,但由于其共享权重的特性,能够在一定程度上捕获用户和物品之间的共性,有时能带来更好的表示学习效果。
总结来说,双塔模型利用两个独立的神经网络分别对用户和物品进行编码,适用于处理稀疏向量的检索任务,具有较高的检索效率和良好的可扩展性。而单塔模型采用一个共享的神经网络结构对用户和物品进行联合编码,适用于处理稠密向量的检索任务,可能在表示学习方面具有更强的灵活性和捕获交叉信息的能力。选择哪种模型结构取决于具体的应用场景、数据特性以及对检索效率、模型复杂度等方面的需求。
ErnieTokenizer.from_pretrained('ernie-3.0-tiny-medium-v2-zh') 初始化了一个分词器(Tokenizer),该分词器基于预训练模型 ernie-3.0-tiny-medium-v2-zh 的词汇表和编码规则。分词器负责将原始文本字符串转换为模型可接受的输入格式,如整数索引列表(token IDs)或子词单元(subwords)。
ErnieModel.from_pretrained('ernie-3.0-tiny-medium-v2-zh') 初始化了一个模型实例,该模型加载了预训练模型 ernie-3.0-tiny-medium-v2-zh 的权重。预训练模型是在大规模无标注文本数据上预先训练好的,旨在学习语言的通用表示。ERNIE(Enhanced Representation through kNowledge IntEgration)是百度研发的一种预训练语言模型,具备优秀的中文语言理解能力。

















 2026
2026











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









