








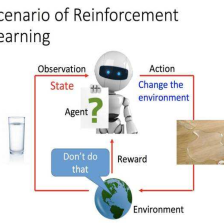

李宏毅机器学习系列-强化学习之Q-Learning小改进
Double DQN
我们在实验中发现Q的值是被高估的,比如下图,红色的曲线是DQN的估计值,直线是Q的DQN的真实值,很明显估计值比真实值高很多,然后我们又用了DDQN,是蓝色的,可以看到估计值和真实值差的不多,而且都要比DQN小,没有高估很多:

那为什么会被高估呢,我们来看看。我们是会找一个使得Q最大的a,如果a被高估了,那Q也会被高估,所以是跟a有关系:

那我们怎么来解决呢,可以用两个网络来合作计算Q值,一个是要训练你的
Q
Q
Q,一个是目标
Q
′
Q'
Q′,如果
Q
Q
Q选择了高估的a,那只要
Q
′
Q'
Q′不给他高估的值就可以,如果
Q
′
Q'
Q′高估了,那就让
Q
Q
Q不去选择高估的那个a,等于相互制约着:

Dueling DQN
这个带来的的好处就是我们可以比较有效率的去使用我们的数据,具体马上会讲他是怎么做的,其实他只是从结构上改变了原来的DQN,把原来的Q,变成了一个V+A,V就是某个s状态下的估计值,A是某个s下所有的行为a的估计值:

我们来举个例子,下图Q可以看成是一个表格,横轴是状态,纵轴是行为,每一个状态的每一个行为都有Q值,V是每个状态下的值,A是每个状态下采取某个a的值,把V加到A的每一行去,就是Q:

假设我们现在训练,要改动两个值,但是我们是改不了直接的Q,我们是根据V和A来改的:

其实我们只需要改动V,就可能会改变3个值,因为Q=A+V,也就是说我们只要固定A在某个s下的值加起来为0,这样对Q造成影响的只能是V了:

所以我们可以想办法,让A的列的和为0,这样V就是Q的列的平均值了,只要V变了,就会影响整一列的值跟着变,这样更新的效率就提高了:

那具体我们怎么来操作呢,可以在A的地方加一层标准化,均值是0就可以:

Prioritized Reply
这个的思路就是说,我们要去多采样那些TD误差比较大的样本,因为这些是我们之前训练不好的样本,应该多拿他们来训练,具体的做法可以看相关的论文,其实还没那么简单,改的还比较多的:

Multi-step
这个就是结合了MC和TD的方法,本来我们只采集一个步骤的数据,现在可以采集多个步骤,这样会估计的比较准,然后奖励的方差也没那么大,可以调节N来调整:

Noisy Net
上次的说的探索是在选择行为的时候有个随机选择,而现在可以在整个网络的参数上面加随机,在每一个轮次的开始给每个参数加随机的噪音:

如果仅仅是随机选择动作,那其实是随机乱试,这样就是可能导致同样的状态,可能会有不一样的动作,好像和真实世界有偏差啊,看到同样的情况一会儿是好的,一会儿是很奇怪的行为。但是如果是给网络加随机噪音,这样他可能看到相同的状态会有做出类似的行为,也就是说对状态是有依赖的探索,也就是有系统地试,不会乱试:

Distributional Q-function
这个的思路就是说我们的Q本来是评估期望的,也就是说是均值,但是不同的分布可能有相同的均值,但是所含的意义是不同的:

,他的思路就是在同一个s状态下,把不同动作所对应的Q的分布给找出来,然后选均值最大的那个,当然也可以选其他的,比如分布的形状,均值一样,如果方差太大,可能风险比较高,所以可以选方差小的。具体有个动画可以看视频,帮助理解:

Rainbow
刚才的方法综合起来:


然后是拿掉某个方法的结果,看看哪个方法有用,哪个没啥用:

Q-Learning解决连续的行为的方案
如果动作是个连续的,那我们要解决这个问题就比较麻烦,比如自动驾驶,方向盘的旋转角度是连续的:

方案1
采样,但是你可能没办法采样全部的行为:

方案2
用梯度上升法去解这个问题,但是可能找到的是局部最大值,运算量也大

方案3
设计一个Q函数的网络,输入s输出三个东西,Q跟这3个东西相关的,如果要Q最大,只要a是
μ
(
s
)
\mu(s)
μ(s)即可:

方案4
别用Q-Learning,前面讲到了基于策略和基于价值的,后面会讲两个结合的:

总结
本篇主要介绍强化学习的Q-learning的一些小改进,其实作用还是很大的,如果把我们合起来效果可以很厉害,也讲了怎么处理连续的动作。
好了,今天就到这里了,希望对学习理解有帮助,大神看见勿喷,仅为自己的学习理解,能力有限,请多包涵,图片来自李宏毅课件,侵删。















 92
92

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









