







WSL安装CentOS7及深度学习环境配置
文章目录
前言
写这篇文章之前自己安装过两次环境,可能每次都会产生碰到同样的问题,而每次上网查询答案总是需要多个贴共同协作,为了搭建适合自己的虚拟环境保证每一步的正确性,按顺序记录一下
一、安装WSL前置条件及步骤
写内容前先放两个帖子
链接:
WSL2的安装详细过程
基于Windwos11的WSL安装CentOS
里面包含以下要点:
1.1 Windows 10(要求
(已更新到版本 2004 的内部版本 19041 或更高版本,win11无此需求)最好是22H2版本以上,内部版本19045以上。如果未达到请按上述链接升级
.

1.2.检查是否满足潜在条件
2.1控制面板 -> 程序 -> 程序和功能 -> 启用或关闭Windows功能->适用于window的linux子系统
2.2 任务管理器->性能->CPU->虚拟化(虚拟化未开启需要进入BIOS打开虚拟化)
2.3 BIOS开启虚拟化的方法
二、安装WSL及CentOS7镜像
2.1启动powershell分别输入以下命令
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart
#重启电脑
#更改为wsl2
wsl --set-default-version 2
安装CentOS
这里有一个地址是github上的Centwsl提供的镜像,我安装的是CentOS7,但不是这里来的,可以自己尝试一下
https://github.com/wsldl-pg/CentWSL
下载安装CentOS7参照以下的链接
基于Windwos11的WSL安装CentOS
在安装wsl中遇到各种报错可以参考这个帖子:
关于几种报错的解决办法
2.2 如何查看存在的子系统,以及重置子系统
当遇到问题需要重置系统时也很简单
powershell打开
wsl.exe --list --all #查看存在子系统
wsl.exe --unregister CentOS7
选择默认的linux版本
wslconfig /setdefault linuxname
#切换版本
wsl --set-version linuxname
wsl --list --verbose
#关闭某一个发行版
wsl -t linuxname
然后按照上述链接中重新安装一遍CentOS7即可
可能需要安装的必要的东西
更新系统中已有的软件包 yum -y update
安装gcc、gcc+、wget等 yum -y install gcc gcc-c++ make wget
安装ssh相关 yum -y install openssh-clients openssh-server
安装vim编辑器 yum -y install vim
安装压缩解压缩工具 yum -y install tar
安装网络工具 yum -y install net-tools
字符终端处理库 yum -y install ncurses
2.3 安装环境设置普通用户
CentOS7默认是root用户,设置普通用户及密码是有必要的
#这部分还没做,暂时用root用户试试
进入后输入重置密码
[root@DESKTOP-JUJ5EQK ~]# passwd
Changing password for user root.
New password:
BAD PASSWORD: The password fails the dictionary check - it is based on a dictionary word
Retype new password:
passwd: all authentication tokens updated successfully.
接下来设置了window下VScode配置WSL(liunx环境下)
配置CentOS7的SSH
2.4 ssh 连接
yum list installed | grep openssh-server
#修改ssh_config文件
vi /etc/ssh/sshd_config
找到修改成以下样子
Port 22
#AddressFamily any
ListenAddress 0.0.0.0
ListenAddress ::
PermitRootLogin yes
SSH启动参考这个链接启动SSH
[root@localhost ~]$ ps -e | grep sshd #检查是否已开启ssh
[wangl@DESKTOP-JUJ5EQK:]$netstat -ta |grep ssh #检查是否已开启ssh ubuntu系统下
[root@localhost ~]$systemctl enable sshd.service #设置ssh service自启动
[root@localhost ~]ifconfig #查看linux系统的ip地址
VScode与wsl互联配置参照这个
vscode(windows) 如何连接虚拟机中的linux
Host Swei
HostName 192.168.86.10 #linux的ip地址
User swei #linux的用户名
Port 22 #端口
IdentityFile "C:\Users\SweiJ\.ssh\id_rsa" #id_rsa的路径
连接之后的情况
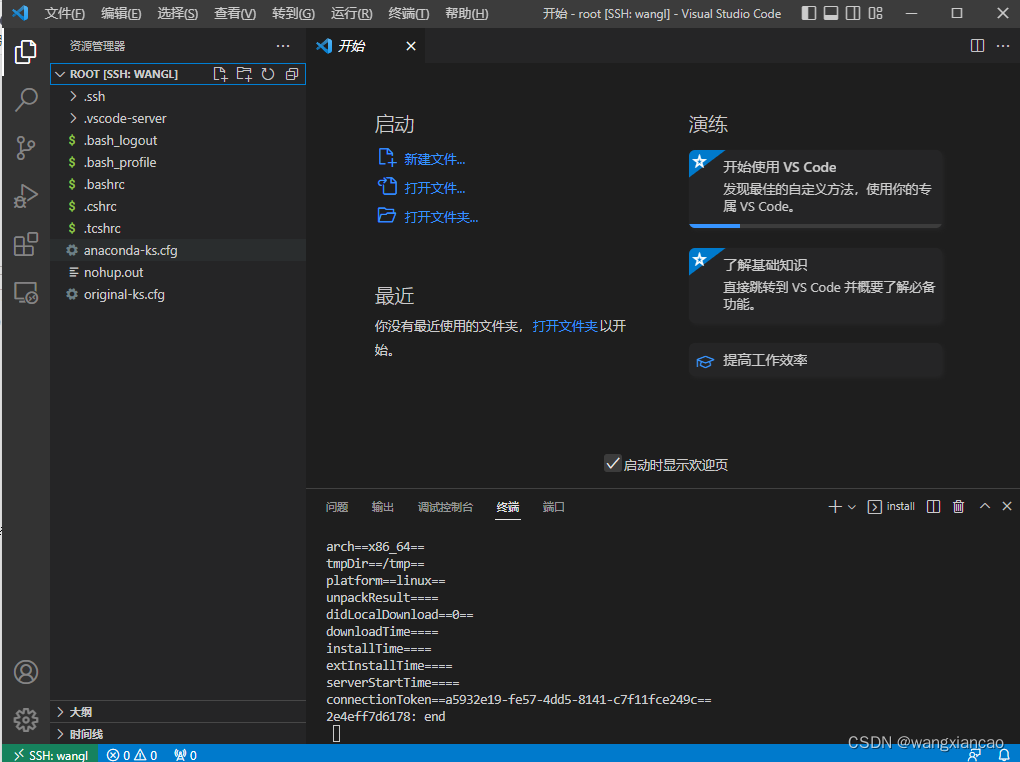
三、Conda配置与pytorch cuda环境安装
3.1 CentOS7 miniconda安装
wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-4.7.12.1-Linux-x86_64.sh
chmod 777 Miniconda3-4.7.12.1-Linux-x86_64.sh #给执行权限
bash Miniconda3-latest-Linux-x86_64.sh
安装屏幕上的提示安装,完成!!!
(base) [root@DESKTOP-JUJ5EQK ~]#
3.2配置环境
创建新环境,添加新镜像
conda create -n mllab python=3.10.6
vi ~/.pip/pip.conf #如果没有就创造路径创造文件
#填写内容
[global]
timeout=6000
index-url = http://pypi.douban.com/simple/
trusted-host=pypi.douban.com/simple
vi ~/.condarc
#如果没有就创造文件
#填写内容
channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/pro
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
- defaults
show_channel_urls: true
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
3.3 CUDA、cudnn安装
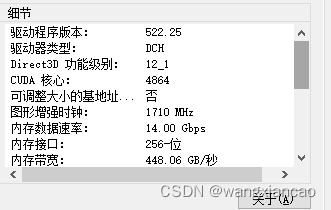
首先你要有一块英伟达显卡,其次使用 NVIDIA GeForce Experience安装最新的驱动,如果你本身已经是最新则不需要重新安装
右键->Nvidia 控制面板->系统信息->驱动程序版本
这个链接查看CUDA匹配的cuda toolkit
安装CUDA toolkit
网站提示的安装指令安装
第一次安装的电脑可能会显示 rpm not found
输入命令 sudo apt-get install rpm(此时需要这台电脑能够上网),等待自行下载
wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda-repo-rhel7-11-8-local-11.8.0_520.61.05-1.x86_64.rpm
sudo rpm -i cuda-repo-rhel7-11-8-local-11.8.0_520.61.05-1.x86_64.rpm
sudo yum clean all
sudo yum -y install nvidia-driver-latest-dkms
sudo yum -y install cuda
#安装遇到了报错,
https://www.nvidia.com/Download/index.aspx?lang=en-us
发现wsl中可能需要其他的nvdia的支持,此链接安装nvdia的驱动
#根据doc提供的信息,wsl暂时只有wsl-Ubuntu版本,CentOS暂时搁置,下面使用Ubuntu20.04进行部署
有了前面的铺垫后面就变得轻车熟路,也没有遇到什么报错
ubuntu下的ssh配置参考2.4节
安装完成CUDA和cudnn也配置完成
接下来激动人心的时刻!!

3.4 pytorch 安装
根据环境选择安装pytorch的版本
pytorch 1.13.0 conda CUDA 11.6 linux python
conda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia
安装依赖库
python -m pip install requirments.txt
3.5 pytorch 测试
cuda版本比非cuda版本大约加速10倍左右,具体内容后续附上
import torch
from torch import nn # 常用网络
from torch import optim # 优化工具包
import torchvision # 视觉数据集
from matplotlib import pyplot as plt
import time
timestart=time.time()
if torch.cuda.is_available():
device='cuda'
else:
device='cpu'
## 加载数据
batch_size=512
train_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('mnist_data',train=True,download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.1307,), (0.3081,)) # 做一个标准化
])),
batch_size=batch_size,shuffle=True)
test_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('mnist_data/',train=False,download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size,shuffle=True)
x,y=next(iter(train_loader))
x=x.to(device)
y=y.to(device)
print(x.shape,y.shape,x.min(),x.max())
relu = nn.ReLU() # 如果使用torch.sigmoid作为激活函数的话正确率只有60%
# 创建网络
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
# xw+b 这里的256,64使我们人根据自己的感觉指定的
self.fc1 = nn.Linear(28*28,256)
self.fc2 = nn.Linear(256,64)
self.fc3 = nn.Linear(64,10)
def forward(self,x):
# 因为找不到relu函数,就换成了激活函数
# x:[b,1,28,28]
# h1 = relu(xw1+b1)
x = relu(self.fc1(x))
# h2 = relu(h1w2+b2)
x = relu(self.fc2(x))
# h3 = h2*w3+b3
x = self.fc3(x)
return x
# 因为找不到自带的one_hot函数,就手写了一个
def one_hot(label, depth=10):
out = torch.zeros(label.size(0), depth)
idx = torch.LongTensor(label).view(-1, 1)
out.scatter_(dim=1, index=idx, value=1)
return out
## 训练模型
net = Net().to(device)
# 返回[w1,b1,w2,b2,w3,b3] 对象,lr是学习过程
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
train_loss = []
mes_loss = nn.MSELoss().to(device)
for epoch in range(10):
for batch_idx, (x, y) in enumerate(train_loader):
# x:[b,1,28,28],y:[512]
# [b,1,28,28] => [b,784]
x = x.view(x.size(0), 28 * 28)
x=x.to(device)
# =>[b,10]
out = net(x)
# [b,10]
y_onehot = one_hot(y)
y_onehot=y_onehot.to(device)
# loss = mse(out,y_onehot)
loss = mes_loss(out, y_onehot)
# 清零梯度
optimizer.zero_grad()
# 计算梯度
loss.backward()
# w' = w -lr*grad
# 更新梯度,得到新的[w1,b1,w2,b2,w3,b3]
optimizer.step()
train_loss.append(loss.item())
# if batch_idx % 10 == 0:
# print(epoch, batch_idx, loss.item())
# plot_curve(train_loss)
# 到现在得到了[w1,b1,w2,b2,w3,b3]
## 准确度测试
total_correct = 0
for x,y in test_loader:
x = x.view(x.size(0),28*28)
x=x.to(device)
y=y.to(device)
out = net(x)
# out : [b,10] => pred: [b]
pred = out.argmax(dim = 1)
correct = pred.eq(y).sum().float().item() # .float之后还是tensor类型,要拿到数据需要使用item()
total_correct += correct
total_num = len(test_loader.dataset)
acc = total_correct/total_num
print('准确率acc:',acc)
timeend=time.time()
usedtime=timeend-timestart
print('打印任务耗时%.2f s'%usedtime)
torch.Size([512, 1, 28, 28]) torch.Size([512]) tensor(-0.4242, device='cuda:0') tensor(2.8215, device='cuda:0')
准确率acc: 0.9316
#有GPU情况下的耗时
打印任务耗时68.10 s
3.6 pytorch-geometric 安装及测试
abstract
PyG (PyTorch Geometric) is a library built upon PyTorch to easily write and train Graph Neural Networks (GNNs) for a wide range of applications related to structured data
安装方法
1.安装依赖库
wheel依赖库
安装依赖库需要选择不同的版本,torch版本+cudann版本以及python版本
torch_cluster, torch_scatter, torch_sparse, torch_spline_conv
$ conda list torch
pytorch 1.13.0 py3.10_cuda11.7_cudnn8.5.0_0 pytorch
pytorch-cuda 11.7 h67b0de4_0 pytorch
$ python
Python 3.10.6 (main, Oct 24 2022, 16:07:47) [GCC 11.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
安装完成依赖库后直接使用 pip install pytorch-geometric !!
安装完成一个小测试:
import torch
from torch_geometric.data import Data
edge_index = torch.tensor([[0, 1, 1, 2],
[1, 0, 2, 1]], dtype=torch.long)
x = torch.tensor([[-1], [0], [1]], dtype=torch.float)
data = Data(x=x, edge_index=edge_index)
print(data)
>>>Data(x=[3, 1], edge_index=[2, 4])
四、遇到的问题与解决方法
4.1 长时间开启wsl导致window内存占用过高
查看发现window进程中vmmen的内存占用过高,以下链接提供了三个解决办法:解决办法
方法1:wsl --shutdown
关闭wsl后重启
方法2:在window中写.wslconfig文本
方法3:定时释放内存的任务
4.2 每次wsl2开启虚拟机IP地址变动
windows中使用openSSH调用并不是很友善,不要使用visual studio code,建议使用git或者其他ssh进行ssh链接
总结
以上就是wsl安装及配置conda深度学习环境的内容,



















 6964
6964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











