







前言
LSTM作为经典模型,可以用来做语言模型,实现类似于语言模型的功能,同时还经常用于做时间序列。由于LSTM的原版论文相关版权问题,这里以colah大佬的博客为基础进行讲解。之前写过一篇Tensorflow中的LSTM详解,但是原理部分跟代码部分的联系并不紧密,实践性较强但是如果想要进行更加深入的调试就会出现原理性上面的问题,因此特此作文解决这个问题,想要用LSTM这个有趣的模型做出更加好的机器学习效果😊。
网络架构
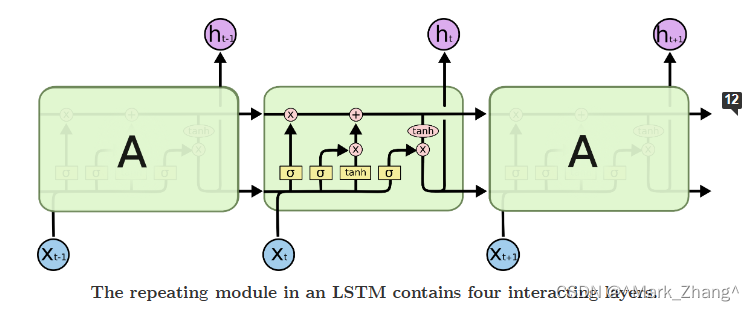
这张图展示了LSTM在整体结构,下面就开始分部分介绍中间这个东东。
总线

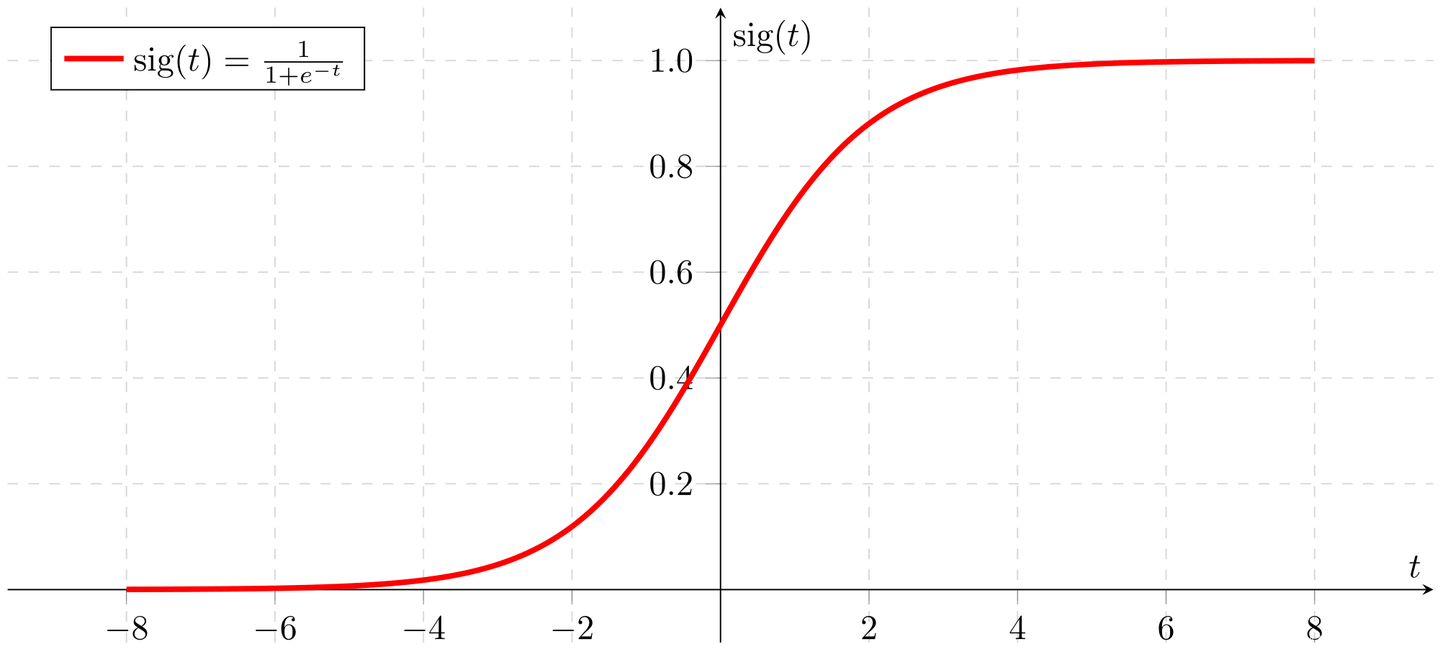
这条是总线,可以实现神经元结构的保存或者更改,如果就是像上图一样一条总线贯穿不做任何改变,那么就是不改变细胞状态。那么如果想要改变细胞状态怎么办?可以通过门来实现,这里的门跟高中生物中学的神经兴奋阈值比较像,用数学来表示就是sigmoid函数或者其他的激活函数,当门的输入达到要求,门就会打开,允许当前门后面的信息“穿过”门改变主线上面传递的信息,如果把每一个神经元看成一个时间节点,那么从上一个时间节点传到下一个时间节点过程中的门的开启与关闭就实现了时间序列数据的信息传递。
遗忘门
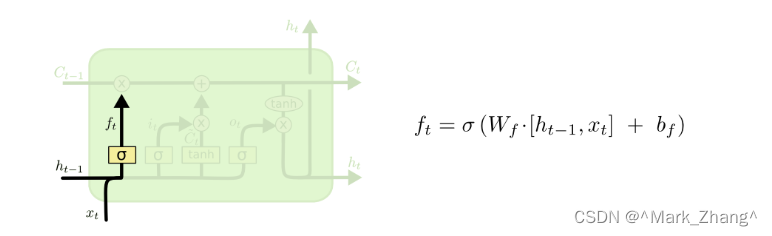
首先是遗忘门,这个门的作用是决定从上一个神经元传输到当前神经元的数据丢弃的程度,如果经过sigmoid函数以后输出0表示全部丢弃,输出1表示全部保留,这个层的输入是旧的信息和当前的新信息。
σ \sigma σ:sigmoid函数
W f W_f Wf:权重向量
b f b_f bf:偏置项,决定丢弃上一个时间节点的程度,如果是正数,表示更容易遗忘,如果是负数,表示比较容易记忆
h t − 1 h_{t-1} ht−1:上一个时刻的输入
x t x_t xt:当前层的输入
记忆门
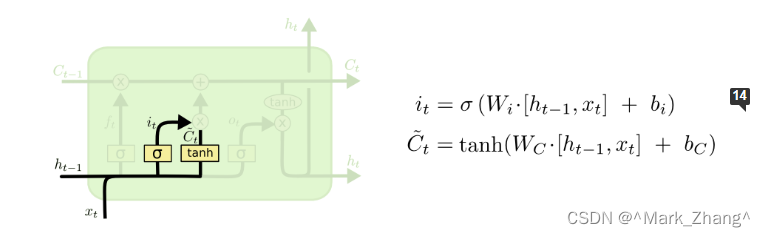
接下来是记忆门,这个门决定要记住什么信息,同时决定按照什么程度记住上一个状态的信息。
i t i_t it:在时间步t时刻的输入门激活值,计算方法跟上面的遗忘门是一样的,只是目的不一样,这里是记忆
C ~ t \tilde{C}_{t} C~t:表示上一个时刻的信息和当前时刻的信息的集合,但是是规则化到[-1,1]这个范围内了的
记忆细胞
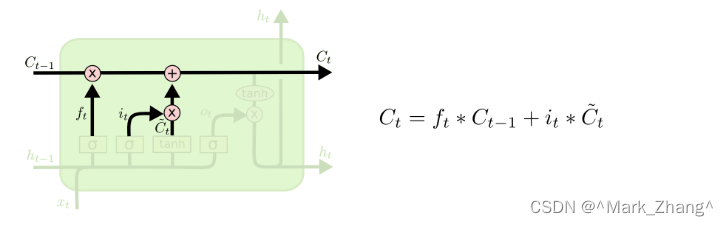
有了上面的要记忆的信息和要丢弃的信息,记忆细胞的功能就可以得到实现,用
f
t
f_t
ft这个标量决定上一个状态要遗忘什么,用
i
t
i_t
it这个标量决定上一个状态要记住什么以及当前状态的信息要记住什么。这样就形成了一个记忆闭环了。
输出门
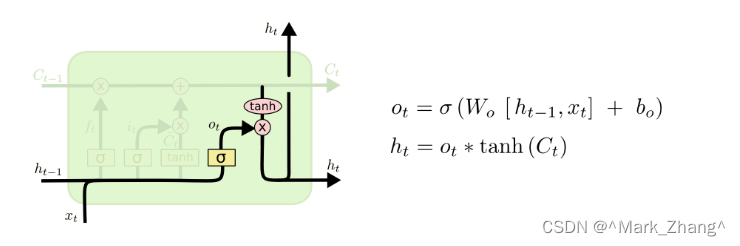
最后,在有了记忆细胞以后不仅仅不要将当前细胞状态记住,还要将当前的信息向下一层继续传输,实现公式中的状态转移。
o t o_t ot:跟前面的门公式都一样,但是功能是决定输出的程度
h t h_t ht:将输出规范到[-1,1]的区间,这里有两个输出的原因是在构建LSTM网络的时候需要有纵向向上的那个 h t h_t ht,然而在当前层的LSTM的神经元之间还是首尾相接的😍。
模型定义
单个LSTM神经元的定义
# 定义单个LSTM单元
# 定义单个LSTM单元
class My_LSTM(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(My_LSTM, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
# 初始化门的权重和偏置,由于每一个神经元都有自己的偏置,所以在定义单元内部定义
self.Wf = nn.Parameter(torch.Tensor(input_size + hidden_size, hidden_size))
self.bf = nn.Parameter(torch.Tensor(hidden_size))
self.Wi = nn.Parameter(torch.Tensor(input_size + hidden_size, hidden_size))
self.bi = nn.Parameter(torch.Tensor(hidden_size))
self.Wo = nn.Parameter(torch.Tensor(input_size + hidden_size, hidden_size))
self.bo = nn.Parameter(torch.Tensor(hidden_size))
self.Wg = nn.Parameter(torch.Tensor(input_size + hidden_size, hidden_size))
self.bg = nn.Parameter(torch.Tensor(hidden_size))
# 初始化输出层的权重和偏置
self.W = nn.Parameter(torch.Tensor(hidden_size, output_size))
self.b = nn.Parameter(torch.Tensor(output_size))
# 用于计算每一种权重的函数
def cal_weight(self, input, weight, bias):
return F.linear(input, weight, bias)
# x是输入的数据,数据的格式是(batch, seq_len, input_size),包含的是batch个序列,每个序列有seq_len个时间步,每个时间步有input_size个特征
def forward(self, x):
# 初始化隐藏层和细胞状态
h = torch.zeros(1, 1, self.hidden_size).to(x.device)
c = torch.zeros(1, 1, self.hidden_size).to(x.device)
# 遍历每一个时间步
for i in range(x.size(1)):
input = x[:, i, :].view(1, 1, -1) # 取出每一个时间步的数据
# 计算每一个门的权重
f = torch.sigmoid(self.cal_weight(input, self.Wf, self.bf)) # 遗忘门
i = torch.sigmoid(self.cal_weight(input, self.Wi, self.bi)) # 输入门
o = torch.sigmoid(self.cal_weight(input, self.Wo, self.bo)) # 输出门
C_ = torch.tanh(self.cal_weight(input, self.Wg, self.bg)) # 候选值
# 更新细胞状态
c = f * c + i * C_
# 更新隐藏层
h = o * torch.tanh(c) # 将输出标准化到-1到1之间
output = self.cal_weight(h, self.W, self.b) # 计算输出
return output
LSTM层内结构的定义
class My_LSTMNetwork(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(My_LSTMNetwork, self).__init__()
self.hidden_size = hidden_size
self.lstm = My_LSTM(input_size, hidden_size) # 使用自定义的LSTM单元
self.fc = nn.Linear(hidden_size, output_size) # 定义全连接层
def forward(self, x):
h0 = torch.zeros(1, x.size(0), self.hidden_size).to(x.device)
c0 = torch.zeros(1, x.size(0), self.hidden_size).to(x.device)
out, _ = self.lstm(x, (h0, c0)) # LSTM层的前向传播
out = self.fc(out[:, -1, :]) # 全连接层的前向传播
return out
模型训练
history = model.fit(trainX, trainY, batch_size=64, epochs=50,
validation_split=0.1, verbose=2)
print('compilation time:', time.time()-start)
模型评估
为了更加直观展示,这里用画图的方法进行结果展示。
fig3 = plt.figure(figsize=(20, 15))
plt.plot(np.arange(train_size+1, len(dataset)+1, 1), scaler.inverse_transform(dataset)[train_size:], label='dataset')
plt.plot(testPredictPlot, 'g', label='test')
plt.ylabel('price')
plt.xlabel('date')
plt.legend()
plt.show()
代码细节
LSTM层单元的首尾的处理
-
首部:由于第一个节点不用接受来自上一个节点的输入,不需要有输入,当然也有一些是添加标识。
-
尾部:由于已经进行到当前层的最后一个节点,因此输出只需要向下一层进行传递而不用向下一个节点传递,添加标识也是可以的。
配置Tensorflow的GPU版本
这一篇写的比较好,我自己的硬件环境如下图所示,需要的可以借鉴一下,当然也可以在我提供的代码链接直接用我给的environment.yml一键构建环境😃。


















 1323
1323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









