







使用GPTQ进行4位LLM量化
权重量化的最新进展使我们能够在消费级硬件上运行大量大型语言模型,例如在RTX 3090 GPU上运行LLaMA-30B模型。这要归功于性能降低最小的4-bit量化技术,如GPTQ、GGML和NF4。
在上一篇文章中,我们介绍了naïve 8位量化技术和优秀的LLM.int8()。在本文中,我们将探讨流行的GPTQ算法,以了解它是如何工作的,并使用AutoGPTQ库实现它。
最佳脑量化
让我们从介绍我们试图解决的问题开始。对于网络中的每个层
l
l
l,我们希望找到原始权重
W
l
W_l
Wl的量化版本
W
l
^
\hat{W_l}
Wl^。这被称为 layer-wise 压缩问题。更具体地说,为了最大限度地减少性能下降,我们希望这些新权重的输出
W
l
^
X
l
\hat{W_l}X_l
Wl^Xl尽可能接近原始权重
W
l
X
l
W_lX_l
WlXl。换句话说,我们想找到:
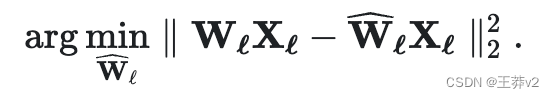
已经提出了不同的方法来解决这个问题,但我们在这里感兴趣的是最优脑量化(OBQ)框架。
这种方法的灵感来自一种修剪技术,从训练后的密集神经网络(Optimal Brain Surgeon)中仔细去除权重。它使用近似技术,并提供最佳单权重
w
q
w_q
wq 去删除和优化更新
δ
F
δ_F
δF,以调整剩余的非量化权重
F
F
F ,以弥补去除:
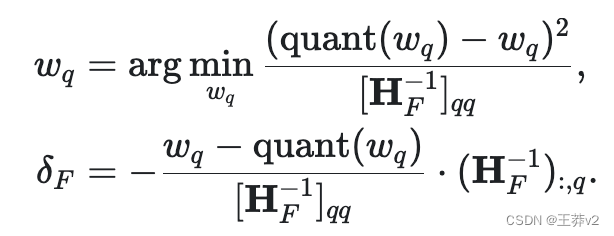
其中 quant(w) 是 quantization 给出的权重四舍五入,
H
F
H_F
HF 是Hessian。
使用OBQ,我们可以首先量化最简单的权重,然后调整所有剩余的非量化权重来补偿这种精度损失。然后我们选择下一个权重来量化,以此类推。
这种方法的一个潜在问题是,当存在离群值权重时,可能导致高量化误差。通常,这些离群值最后会被量化,此时剩下的非量化权重很少,可以调整以补偿较大的误差。当一些权重被中间更新推到网格之外时,这种效果可能会恶化。一个简单的启发式应用来防止这种情况:异常值一出现就被量化。
这个过程可能需要大量的计算,特别是对于LLMs。为了解决这个问题,OBQ方法使用了一种技巧,避免在每次简化权重时重新进行整个计算。量化权重后,它通过删除与该权重相关的行和列(使用高斯消去)来调整计算中使用的矩阵(Hessian矩阵)。
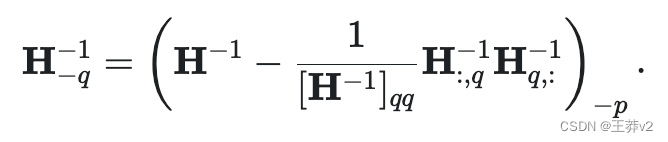
该方法还采用向量化的方法,一次处理多行权矩阵。尽管OBQ的效率很高,但随着权值矩阵的增大,OBQ的计算时间也会显著增加。这种三次增长使得在具有数十亿个参数的非常大的模型上使用OBQ变得困难。
GPTQ算法
由Frantar等人(2023)引入的GPTQ算法从OBQ方法中获得灵感,但进行了重大改进,可以将其扩展到(非常)大的语言模型。
步骤1:任意顺序洞察
OBQ方法按照一定的顺序选择权重(模型中的参数)进行量化,这取决于哪个顺序添加的额外误差最小。然而,GPTQ观察到,对于大型模型,以任何固定顺序量化权重都可以达到同样的效果。这是因为即使一些权重可能单独引入更多的误差,但在稍后的过程中,当剩下的其他可能增加误差的权重很少时,它们也会被量化。所以顺序并不像我们想象的那么重要。
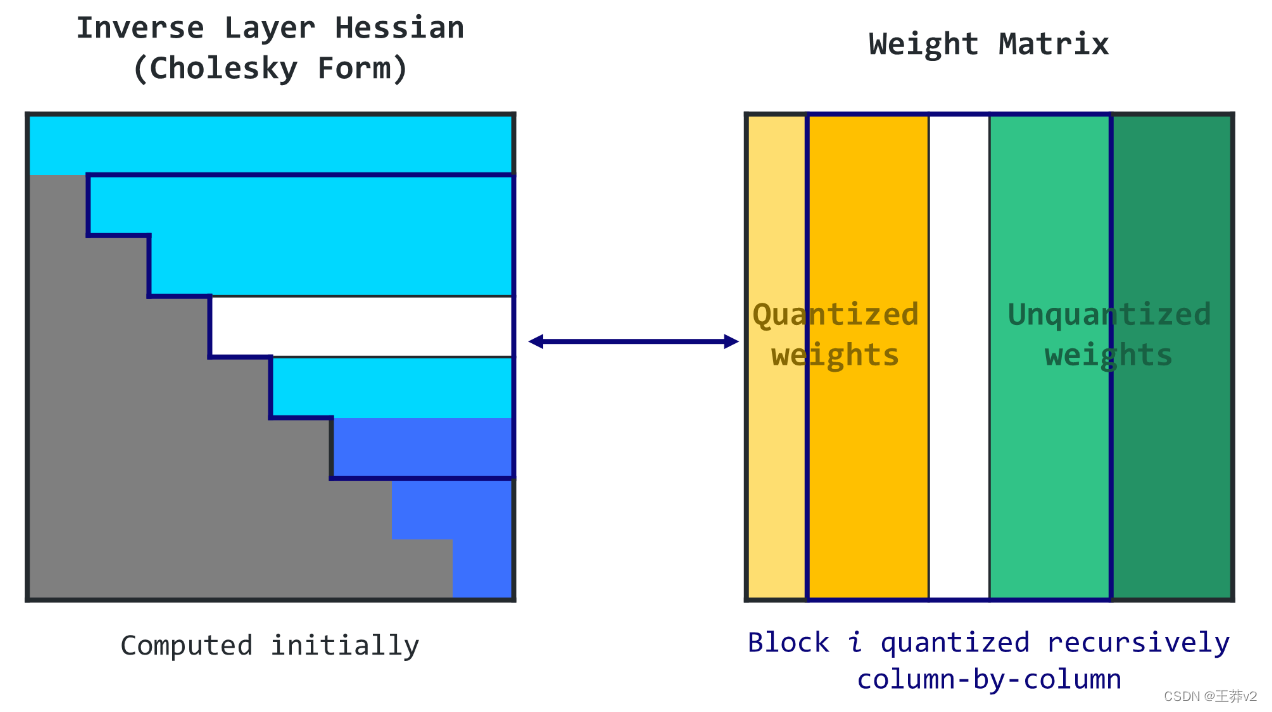
基于这种见解,GPTQ旨在以相同的顺序对矩阵的所有行量化所有权重。这使得计算过程更快,因为某些计算只需要对每一列执行一次,而不是对每个权重执行一次。
步骤2:延迟批量更新
这个方案不会很快,因为它需要更新一个巨大的矩阵,每个条目的计算量很少。这种类型的操作不能充分利用gpu的计算能力,并且会因内存限制(内存吞吐量瓶颈)而减慢速度。
为了解决这个问题,GPTQ引入了延迟批处理更新。结果表明,给定列的最终舍入决策仅受对该列执行的更新的影响,而不受对后面列执行的更新的影响。因此,GPTQ可以一次将算法应用于一批列(如128列),仅更新这些列和矩阵的相应块。在一个块被完全处理后,算法对整个矩阵执行全局更新。
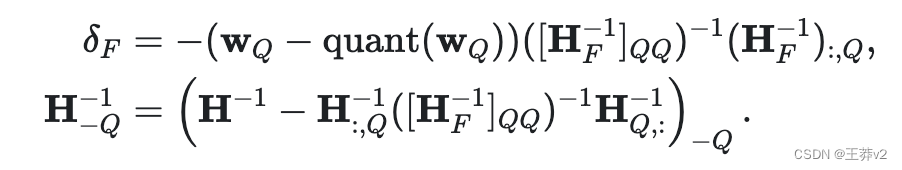
第三步:乔尔斯基重塑
然而,还有一个问题需要解决。当算法扩展到非常大的模型时,数值不精确可能成为一个问题。具体地说,某一操作的重复应用会累积数值误差。
为了解决这个问题,GPTQ使用了Cholesky分解,这是一种用于解决某些数学问题的数值稳定方法。它涉及使用Cholesky方法从矩阵中预先计算一些所需的信息。这种方法与轻微的阻尼(向矩阵的对角线元素添加一个小常数)相结合,有助于算法避免数值问题。
整个算法可以总结为几个步骤:
- GPTQ算法从Hessian逆(一个帮助决定如何调整权重的矩阵)的Cholesky分解开始,
- 然后循环运行,一次处理一批列。
- 对于批处理中的每一列,它量化权重,计算误差,并相应地更新块中的权重。
- 处理完批处理后,它根据块的错误更新所有剩余的权重。
GPTQ算法在各种语言生成任务上进行了测试。比较了其他量化方法,如将所有权重四舍五入到最接近的量化值(RTN)。GPTQ与BLOOM (176B参数)和OPT (175B参数)模型族一起使用,模型使用单个NVIDIA A100 GPU进行量化。
用AutoGPTQ量化LLM
GPTQ在创建4-bit精度的模型时非常流行,可以有效地在gpu上运行。你可以在Hugging Face Hub找到很多例子,尤其是TheBloke。如果您正在寻找一种对cpu更友好的方法,那么GGML目前是您的最佳选择。最后,带bitsandbytes的transformer库允许您在加载模型时使用loadin 4bit=true参数量化模型,这需要下载完整的模型并将其存储在RAM中。
让我们使用AutoGPTQ库实现GPTQ算法,并量化GPT-2模型。这需要一个GPU,但谷歌Colab上的免费T4就可以了。我们首先加载库并定义我们想要量化的模型(在本例中是GPT-2)。
!BUILD_CUDA_EXT=0 pip install -q auto-gptq transformers
import random
from auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig
from datasets import load_dataset
import torch
from transformers import AutoTokenizer
# Define base model and output directory
model_id = "gpt2"
out_dir = model_id + "-GPTQ"
现在我们想要加载模型和标记器。该标记器是使用transformer库中的经典AutoTokenizer类加载的。另一方面,我们需要传递一个特定的配置(BaseQuantizeConfig)来加载模型。
在这个配置中,我们可以指定要量化的位数(这里,bits=4)和组大小(惰性批处理的大小)。注意,这个组的大小是可选的:我们也可以为整个权重矩阵使用一组参数。在实践中,这些组通常以非常低的成本提高量化的质量(特别是当组大小=1024时)。阻尼百分比值在这里是为了帮助Cholesky重新配方,不应该改变。
最后,desc act(也称为act order)是一个棘手的参数。它允许您根据激活的减少来处理行,这意味着首先处理最重要或最有影响的行(由采样的输入和输出决定)。该方法旨在将大部分量化误差(在量化过程中不可避免地引入)放在不太重要的权重上。这种方法通过确保以更高的精度处理最重要的权重,提高了量化过程的总体准确性。然而,当与组大小一起使用时,desc act可能导致性能变慢
# Load quantize config, model and tokenizer
quantize_config = BaseQuantizeConfig(
bits=4,
group_size=128,
damp_percent=0.01,
desc_act=False,
)
model = AutoGPTQForCausalLM.from_pretrained(model_id, quantize_config)
tokenizer = AutoTokenizer.from_pretrained(model_id)
量化过程在很大程度上依赖于样本来评估和提高量化质量。它们提供了一种比较原始模型和新量化模型产生的输出的方法。提供的样本数量越多,就越有可能进行更准确和有效的比较,从而提高量化质量。
在本文中,我们使用C4 (Colossal Clean crawl Corpus)数据集来生成我们的样本。C4数据集是一个大规模的、多语言的网络文本集合,收集自Common Crawl项目。这个扩展的数据集已经经过清理,并专门为训练大规模语言模型而准备,使其成为此类任务的重要资源。WikiText数据集是另一个流行的选择。
在下面的代码块中,我们从C4数据集加载1024个样本,对它们进行标记并格式化。
# Load data and tokenize examples
n_samples = 1024
data = load_dataset("allenai/c4", data_files="en/c4-train.00001-of-01024.json.gz", split=f"train[:{n_samples*5}]")
tokenized_data = tokenizer("\n\n".join(data['text']), return_tensors='pt')
# Format tokenized examples
examples_ids = []
for _ in range(n_samples):
i = random.randint(0, tokenized_data.input_ids.shape[1] - tokenizer.model_max_length - 1)
j = i + tokenizer.model_max_length
input_ids = tokenized_data.input_ids[:, i:j]
attention_mask = torch.ones_like(input_ids)
examples_ids.append({'input_ids': input_ids, 'attention_mask': attention_mask})
WARNING:datasets.builder:Found cached dataset json (/root/.cache/huggingface/datasets/allenai___json/allenai--c4-6e494e9c0ee1404e/0.0.0/8bb11242116d547c741b2e8a1f18598ffdd40a1d4f2a2872c7a28b697434bc96)
Token indices sequence length is longer than the specified maximum sequence length for this model (2441065 > 1024). Running this sequence through the model will result in indexing errors
%%time
# Quantize with GPTQ
model.quantize(
examples_ids,
batch_size=1,
use_triton=True,
)
# Save model and tokenizer
model.save_quantized(out_dir, use_safetensors=True)
tokenizer.save_pretrained(out_dir)
CPU times: user 4min 35s, sys: 3.49 s, total: 4min 39s
Wall time: 5min 8s
('gpt2-GPTQ/tokenizer_config.json',
'gpt2-GPTQ/special_tokens_map.json',
'gpt2-GPTQ/vocab.json',
'gpt2-GPTQ/merges.txt',
'gpt2-GPTQ/added_tokens.json',
'gpt2-GPTQ/tokenizer.json')
像往常一样,可以使用AutoGPTQForCausalLM和AutoTokenizer类从输出目录加载模型和tokenizer。
device = "cuda:0" if torch.cuda.is_available() else "cpu"
# Reload model and tokenizer
model = AutoGPTQForCausalLM.from_quantized(
out_dir,
device=device,
use_triton=True,
use_safetensors=True,
)
tokenizer = AutoTokenizer.from_pretrained(out_dir)
让我们检查一下模型是否正常工作。AutoGPTQ模型(大多数情况下)作为普通的变压器模型工作,这使得它与推理管道兼容,如下面的示例所示
from transformers import pipeline
generator = pipeline('text-generation', model=model, tokenizer=tokenizer)
result = generator("I have a dream", do_sample=True, max_length=50)[0]['generated_text']
print(result)
The model 'GPT2GPTQForCausalLM' is not supported for text-generation. Supported models are ['BartForCausalLM', 'BertLMHeadModel', 'BertGenerationDecoder', 'BigBirdForCausalLM', 'BigBirdPegasusForCausalLM', 'BioGptForCausalLM', 'BlenderbotForCausalLM', 'BlenderbotSmallForCausalLM', 'BloomForCausalLM', 'CamembertForCausalLM', 'CodeGenForCausalLM', 'CpmAntForCausalLM', 'CTRLLMHeadModel', 'Data2VecTextForCausalLM', 'ElectraForCausalLM', 'ErnieForCausalLM', 'FalconForCausalLM', 'GitForCausalLM', 'GPT2LMHeadModel', 'GPT2LMHeadModel', 'GPTBigCodeForCausalLM', 'GPTNeoForCausalLM', 'GPTNeoXForCausalLM', 'GPTNeoXJapaneseForCausalLM', 'GPTJForCausalLM', 'LlamaForCausalLM', 'MarianForCausalLM', 'MBartForCausalLM', 'MegaForCausalLM', 'MegatronBertForCausalLM', 'MusicgenForCausalLM', 'MvpForCausalLM', 'OpenLlamaForCausalLM', 'OpenAIGPTLMHeadModel', 'OPTForCausalLM', 'PegasusForCausalLM', 'PLBartForCausalLM', 'ProphetNetForCausalLM', 'QDQBertLMHeadModel', 'ReformerModelWithLMHead', 'RemBertForCausalLM', 'RobertaForCausalLM', 'RobertaPreLayerNormForCausalLM', 'RoCBertForCausalLM', 'RoFormerForCausalLM', 'RwkvForCausalLM', 'Speech2Text2ForCausalLM', 'TransfoXLLMHeadModel', 'TrOCRForCausalLM', 'XGLMForCausalLM', 'XLMWithLMHeadModel', 'XLMProphetNetForCausalLM', 'XLMRobertaForCausalLM', 'XLMRobertaXLForCausalLM', 'XLNetLMHeadModel', 'XmodForCausalLM'].
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
I have a dream," she told CNN last week. "I have this dream of helping my mother f
更深入的评估将需要测量量化模型与原始模型的 perplexity。但是,我们将其排除在本文的范围之内。
结论
在本文中,我们介绍了GPTQ算法,这是一种在消费级硬件上运行llm的最先进的量化技术。我们展示了它是如何解决分层压缩问题的,它基于一种改进的OBS技术,具有任意顺序洞察力、延迟批处理更新和Cholesky重构。这种新颖的方法显著降低了内存和计算需求,使LLM能够被更广泛的受众所接受。
此外,我们在一个空闲的T4 GPU上量化了我们自己的LLM模型,并运行它来生成文本。你可以在huggingFace Hub上推送你自己版本的GPTQ 4-bit 量化模型。正如在介绍中提到的,GPTQ不是唯一的4-bit量化算法:GGML和NF4是很好的替代算法,但作用域略有不同。
References
- B. Hassibi, D. G. Stork and G. J. Wolff, “Optimal Brain Surgeon and general network pruning,” IEEE International Conference on Neural Networks, San Francisco, CA, USA, 1993, pp. 293-299 vol.1, doi: 10.1109/ICNN.1993.298572.
- Elias Frantar, Sidak Pal Singh, & Dan Alistarh. (2023). Optimal Brain Compression: A Framework for Accurate Post-Training Quantization and Pruning.
- Elias Frantar, Saleh Ashkboos, Torsten Hoefler, & Dan Alistarh. (2023). GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers.
- Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, & Peter J. Liu. (2020). Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.
- https://mlabonne.github.io/blog/posts/4_bit_Quantization_with_GPTQ.html#conclusion

















 448
448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









