






提升准确率的最佳实践
一、数据模型配置“抽取”
对于excel、csv类型的数据源,建议配置为抽取。数据抽取至MPP再解析,有助于提升大模型的准确率。
具体实现过程:在数据模型列表中找到相应的数据模型>编辑>设置>抽取
参考:数据抽取
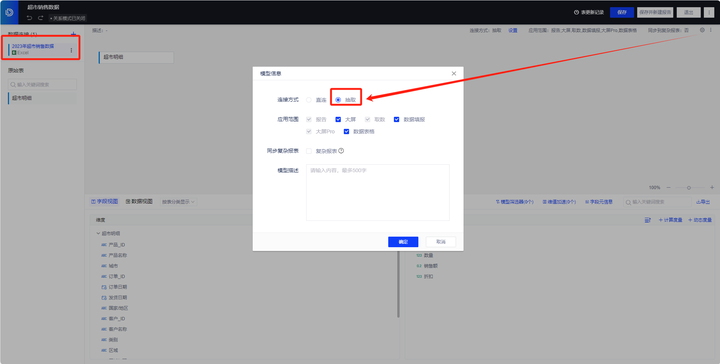
二、模型重命名
创建新的数据模型后,应将其重命名为一个直观且具有描述性的名称,以便于大模型更好地理解和应用。
避免使用诸如“未命名数据模型”或缺乏实际意义的英文词汇等模糊命名,以确保模型命名的准确性和实用性。
具体实现过程:在数据模型列表中找到相应的数据模型>右键>重命名
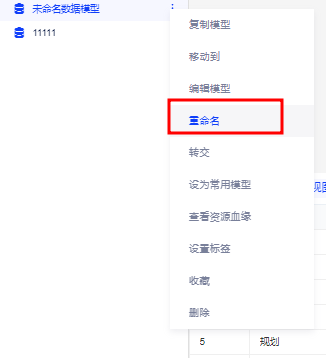
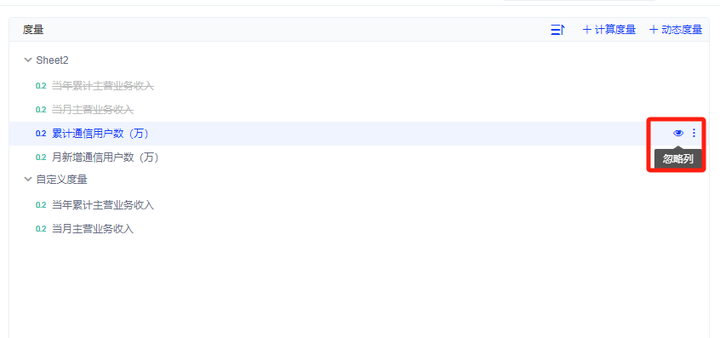
三、数据模型仅保留有效字段
对于那些在当前分析场景中不直接相关或冗余的字段,建议选择隐藏。有助于减少混淆,提高问答准确率,还能让界面更加简洁明了。
例:
①序号类自增无意义的字段
②备份字段
③不常用或不需要参与分析的配置字段
具体实现过程:通过点击忽略列(眼睛图标),选择需要隐藏的字段
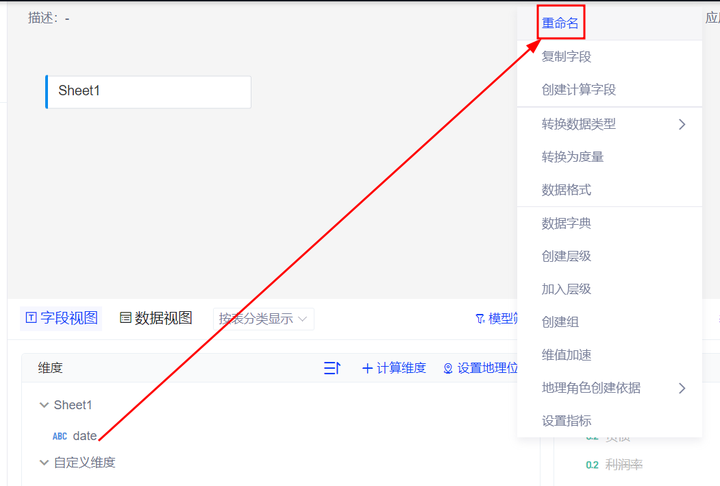
四、字段重命名为中文
提问语言和数据模型的语言一致,会让模型的表现更好,建议数据模型的字段名称设置为中文。
具体实现过程:右键需要重命名的字段,将英文名称的字段重命名为中文。
数据表注释批量转换
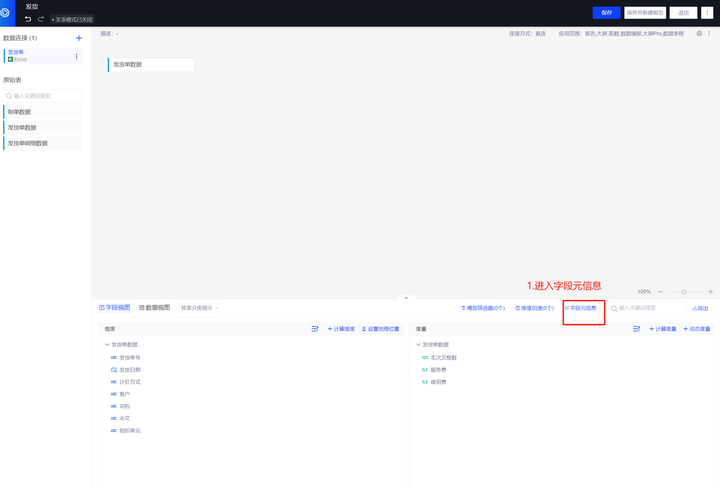
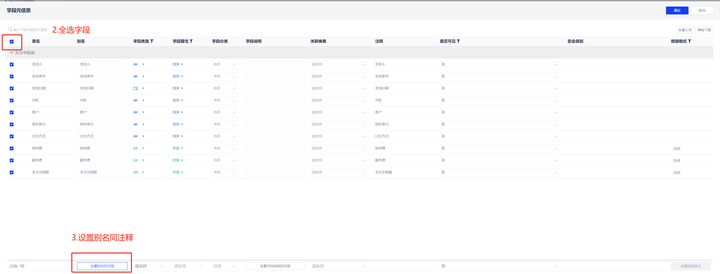
五、设置度量与维度
在构建数据模型时,对字段属于维度/度量进行正确的分类。
维度:用于对数据分组和聚合,如地区、部门、时间等
度量:可以进行数学运算和聚合的数值型数据,如销售额、利润、用户数等
具体实现过程:您可以通过右键需要修改的字段名称,点击转换为度量/维度,实现二者的转换。或者直接鼠标拖拽移动
例:序号、编号等字段,尽管为数值型,但由于其本质上不具备数学运算或聚合意义,因此应被转化为维度字段
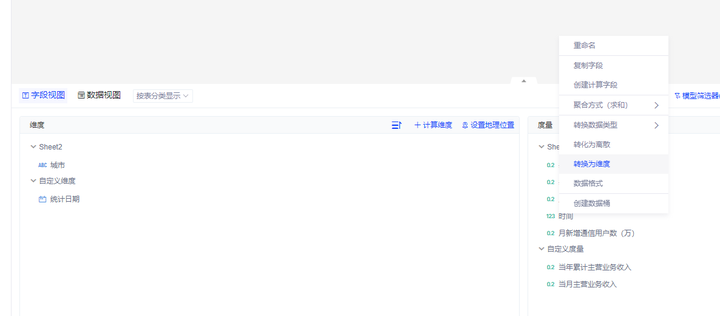
六、日期类型转换
大模型无法将语义里的时间和非日期型字段相关联,需要在数据模型中,将代表日期的非日期型字段需要修改为日期类型。
若您的日期字段为标准格式(yyyy-mm-dd 或 yyyy-dd hh:mm:ss),将格式转换为日期即可。
具体实现过程:您可以通过右键需要修改的字段名称,点击转换数据类型
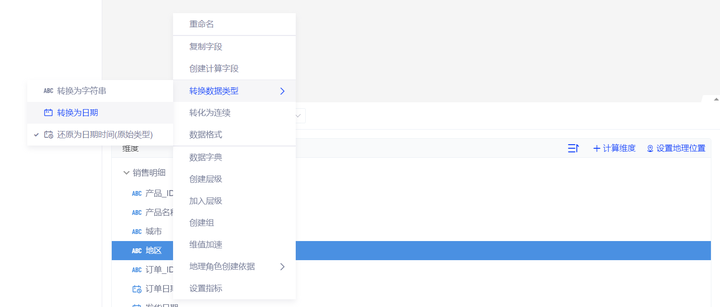
若您的日期字段非标准格式,请不要直接将其转换为日期格式,需要先进行字段的处理。
具体实现过程:可以根据您的日期相关的字段创建新的计算字段(维度),通过输入公式转化数据格式
具体处理方式
①用户日期格式非标准情况:如原字段存在分隔符、日期顺序为自定义等情况
使用DATEPARSE函数:
用途:将字符串转成指定格式的日期
语法:DATEPARSE(格式串,字符串)
-
格式串:数据库中日期的类型:
例如订单表中[订单日期]格式为[2017-02-14],则格式串类型为[yyyy-mm-dd](y为年,m为月,d为日),若[发货日期]格式为[03/12 2019],则格式串类型为[mm/dd yyyy]
-
字符串:想要转换的日期或日期型表达式(必须为字符串形式),若非字符串形式,使用str函数实现格式转化
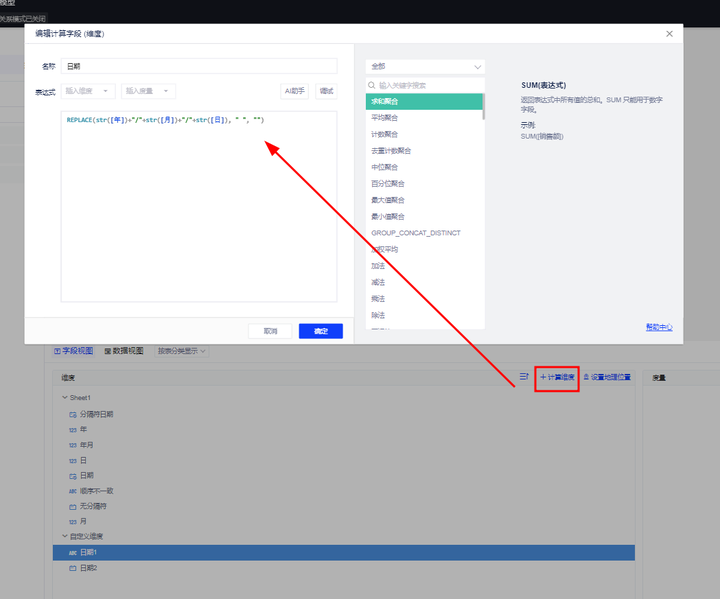
例:将"yyyymm"格式的年月字段转换为日期格式
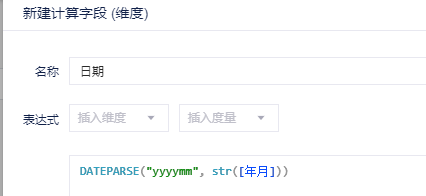
②用户的日期维度分为多个字段:如分为年、月、日三个字段
添加图片注释,不超过 140 字(可选)
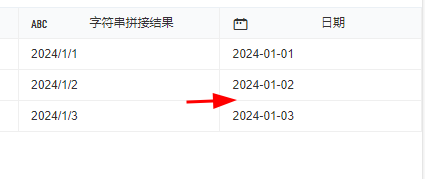
可以先进行字符串拼接:利用 “/” 将您的字段(年、月、日)进行拼接起来
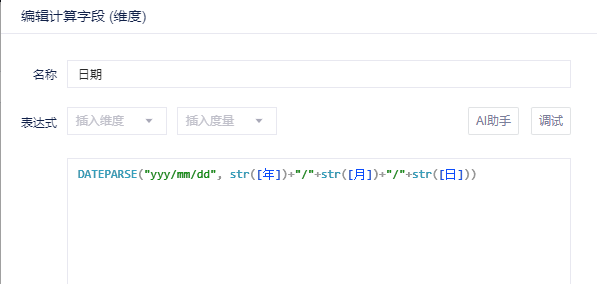
str([年])+"/"+str([月])+"/"+str([日])

再利用DATEPARSE函数转为标准格式日期
综上,计算公式为:
DATEPARSE("yyy/mm/dd", str([年])+"/"+str([月])+"/"+str([日]))
③若您创建了新的日期字段,记得将已经不需要的日期相关字段隐藏
七、业务知识:行业名称解释
在实际使用的过程中,用户提问的时候会带入一些业务场景规则和自己的提问习惯,而这些非通用的内容可能存在无法被大模型识别的问题。因此在取数过程中,如果感觉大模型对于特定业务及概念的理解不足,可通过提示词帮助大模型理解问题。
当前提示词配置支持以下方式:
-
选择触发条件(什么情况下该提示词生效):目前支持「问题包含关键词」和「所有问题」两类触发条件
-
设置规则(提示词生效时,您希望大模型大模型做什么):目前支持「自定义规则」和「选择字段」
需要注意的是,一条记录是对一个名词的解释,因此不要在一条记录中解释多个名词
具体实现过程:点击数据源--数据模型--编辑--ChatBI设置--提示词配置
提示词配置场景
场景一:配置数据和业务问法的映射规则
若您希望当问题包含某些关键词时,您希望让大模型按照设置好的规则去查询,具体操作如下:
-
设置提示词触发条件为“问题包含关键字”
-
在「自定义规则」选项中,选择您希望设置的规则
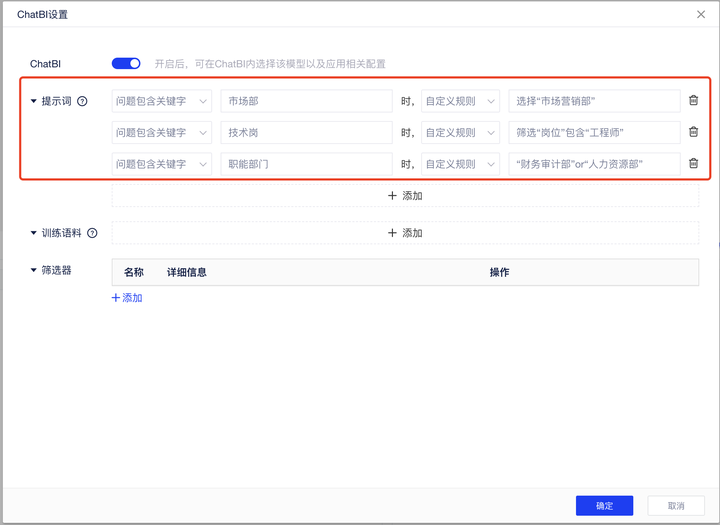
例:现在您要对员工信息进行分析,对「员工信息表」做如下配置,让大模型也能习得这些知识。
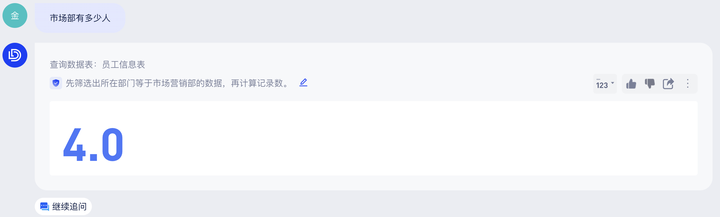
问答结果:
场景二:全局固定展示字段
若您希望无论查询何种问题,只要基于该数据表,都能在问答结果中包含某字段,具体操作如下:
-
设置提示词触发条件为“所有问题”
-
在「选择字段」选项中,选择您希望在所有相关问答中自动包含的字段
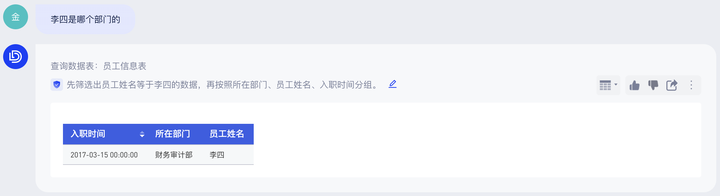
例:「人员信息表」中为人员的基础信息明细数据,如果您希望用户基于该表的问答均能带上「员工姓名」,那就可以设置提示词在“所有问题”均「选择字段」,然后在字段列表下拉选择“员工姓名”这个字段。
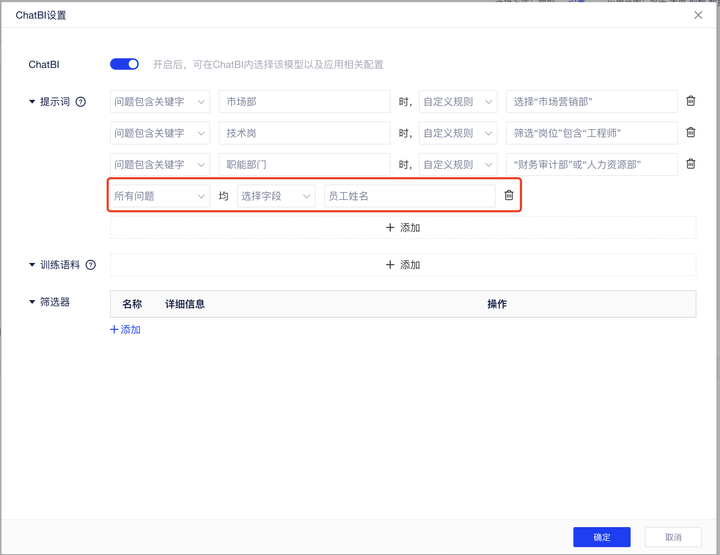
问答结果
配置前:
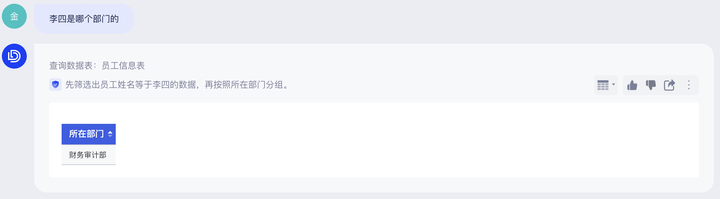
配置后:
场景三:字段联想
若您希望当查询的模型结果包含某字段的时候,为了方便对照,问答反馈同时展示相关的字段,具体操作如下:
-
设置提示词触发条件为“问题包含字段”
-
在「添加」选项中,选择您希望在问答反馈中一同展示的字段
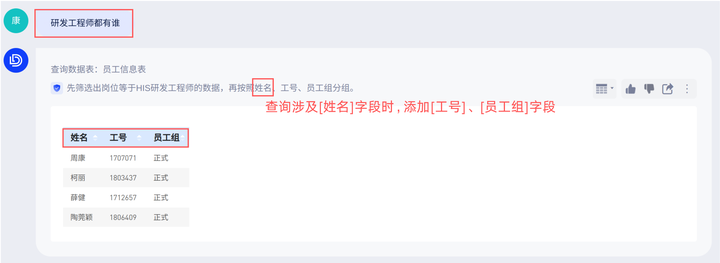
例:「人员信息表」包含人员的基础信息明细数据,当您查询“研发工程师都有谁”时,如果你希望当问题包含[员工姓名]时,同时展示[工号] 、[员工组]等信息以方便用户做对照。那就可以设置提示词在“问题包含字段”「工号」,“时,添加”「选择字段」然后在字段列表下拉选择“工号、员工组”字段。
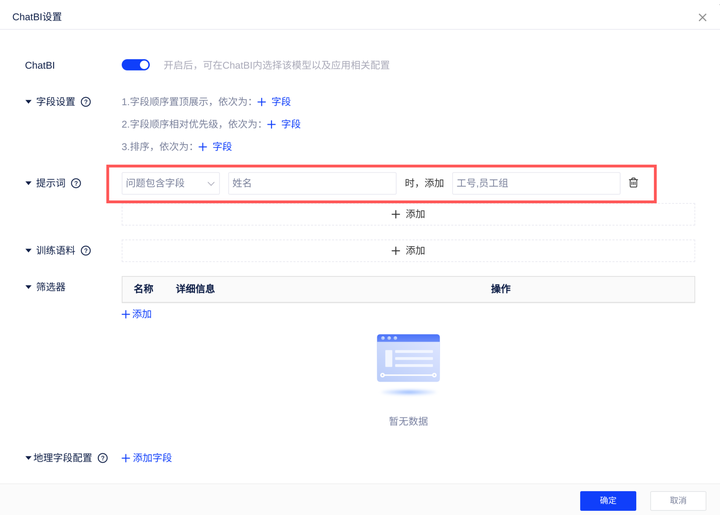
问答结果:
配置前:
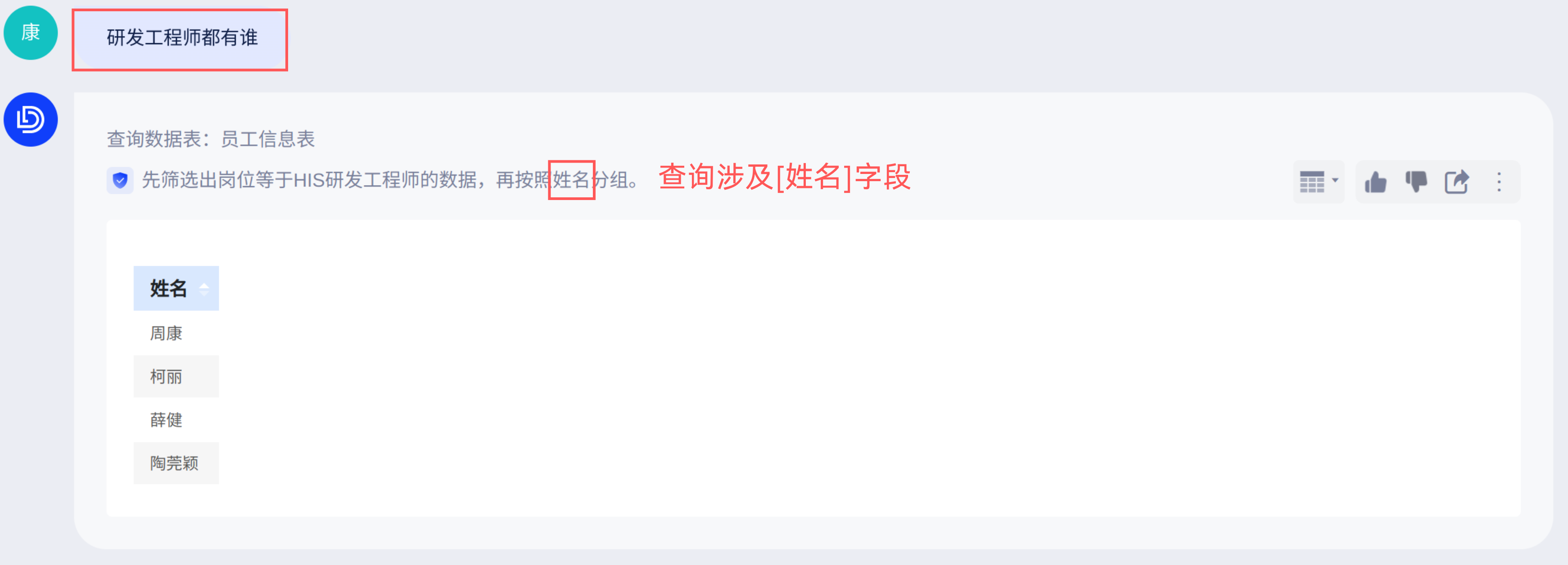
配置后:
八、业务知识:别名
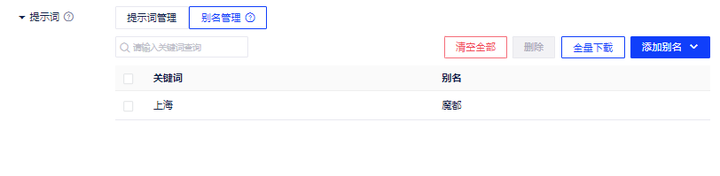
当您倾向于采用一种或多种特定俗称(俗称“行业黑话”)来指代某一概念时,可以在别名管理中为关键词配置别名,确保即使使用不同的表述方式,系统也能准确识别并返回相关结果。
需要注意的是,一个原始名称可以配置多个别名,别名可以表达字段名称,也可以表达某一字段的成员项
例:提问“魔都的人均GDP”,模型能够理解为“上海的人均GDP”
九、复杂问题的处理
1. 提示词字段配置
对于需要进行运算的字段,为了便于模型理解,可以在提示词配置中增加相应的规则。
具体实现过程:在提示词中进行配置,添加关键词和自定义规则。
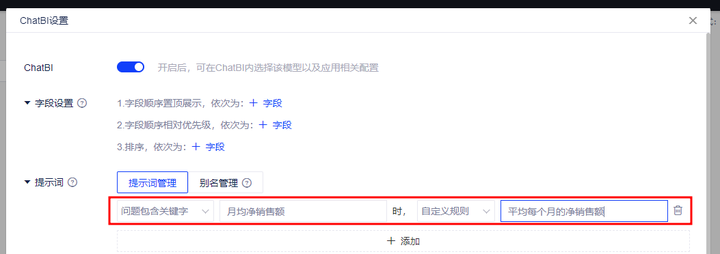
例:当您的数据表中含有【下单时间】和【净销售额】字段,想要获得月均销售额
可以设置关键字为“月均净销售额”,自定义规则为“平均每个月的净销售额”
2. 添加计算字段帮助模型准确理解需求
当计算字段逻辑较为复杂时,难以在自定义规则中用一句话解释,涉及到多种运算组合或者复杂函数,建议在数据模型中添加计算字段,便于模型反馈准确结果。
具体实现过程:在数据模型的编辑界面,点击[+计算维度]/[+计算度量]按钮,创建新的计算字段,输入字段名称和表达式即可。
例:
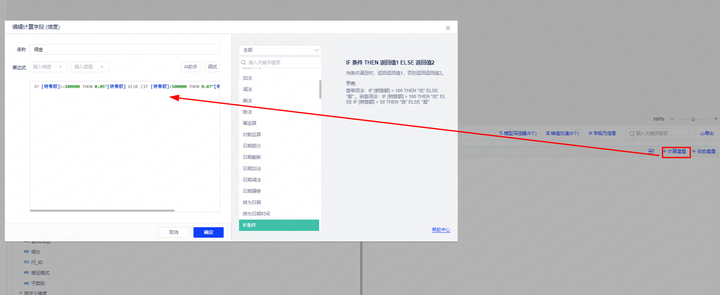
用户问题:销售人员的佣金是多少?
佣金=佣金比率*销售额
佣金比率计算规则为:销售额在10万以下,佣金比率是5%;10万到50万之间是7%;超过50万是10%
在该问题中,由于抽佣规则比较复杂,涉及到条件判断和乘法运算,提示词配置比较繁琐,因此可以通过创建新的计算字段帮助模型理解问题。
该问题的计算表达式如下:
IF [销售额]<=100000 THEN 0.05*[销售额] ELSE (IF [销售额]<500000 THEN 0.07*[销售额] ELSE 0.1*[销售额])
十、数据模型批量治理
若用户需要批量配置字段,可以通过字段元信息进行配置。
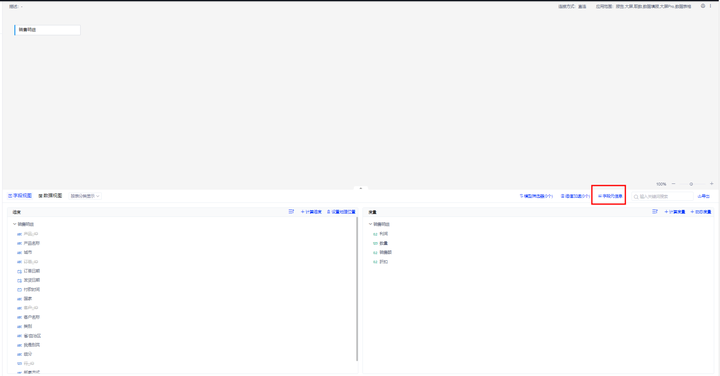
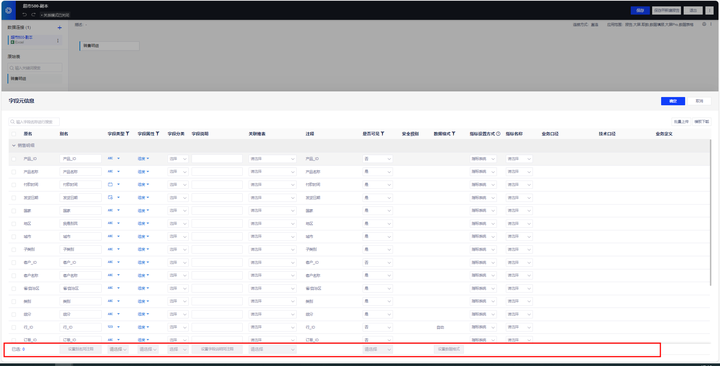
在字段元信息中,可以对字段类型、属性、是否可见、数据格式等批量配置。


















 4127
4127

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









