







概述
全文可以分为四个部分,1)什么样的数据能被表达成图;2)图表和其他数据之间的不同,以及在使用图表数据时需要进行哪些必要操作;3)提出了一个图神经网络模型GNN;4)提供了一个GNN的playground;
介绍
什么是图
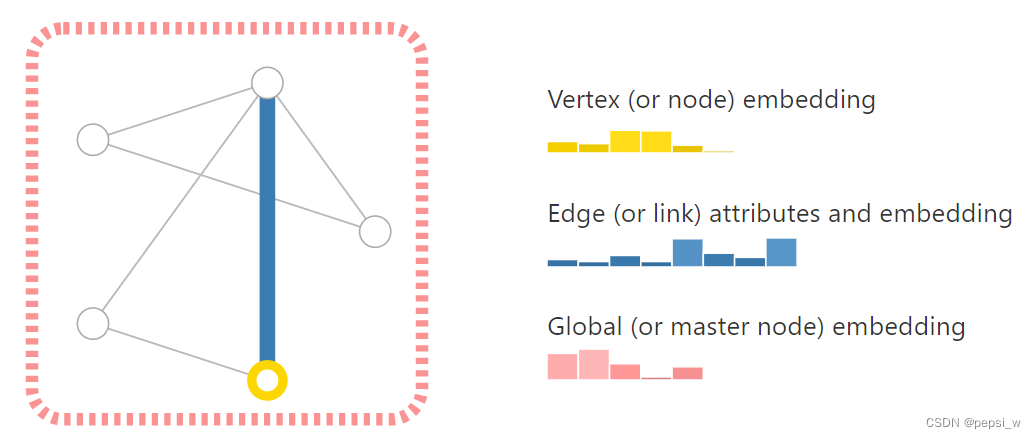
用来表示实体(node)之间的关系(edges),分为有向图和无向图,有向图表示的是某个实体之间的依赖关系,无向图只是表示实体之间的连接关系。图里面一共有顶点向量、边向量、全局向量这三个向量。这里的全局向量可以看作是个虚拟的点(称为master node、context vector),该点与整个图中的所有点和边都相连。

其他数据如何表示为图
图片表示为图
一般将图片表示成tensor形式(如224*224*3),其中的每个像素都表示为图中的一个顶点,且与其邻近像素相连接。如下图,中间部分就是改图的一个邻接矩阵(通常是一个稀疏矩阵),右边部分是该图片的图结构。
文本表示为图
文本是一个序列数据,将每个词表示为一个顶点,上一个词到下一个词之间是一个有向边,如下图所示:

其他数据表示为图
化学分子图表示为图的具体结构如下图所示,

社交网络结构表示为图的具体结构如下:

另外一些文章之间的引用关系也可以表示为图。
图结构的任务类型
一共有三大类的任务,顶点级、边级以及全局的一个预测。在图层面,就类似于CV里的图像分类问题,文本任务中的情感分类问题。对输入的图根据石否有环进行分类问题。

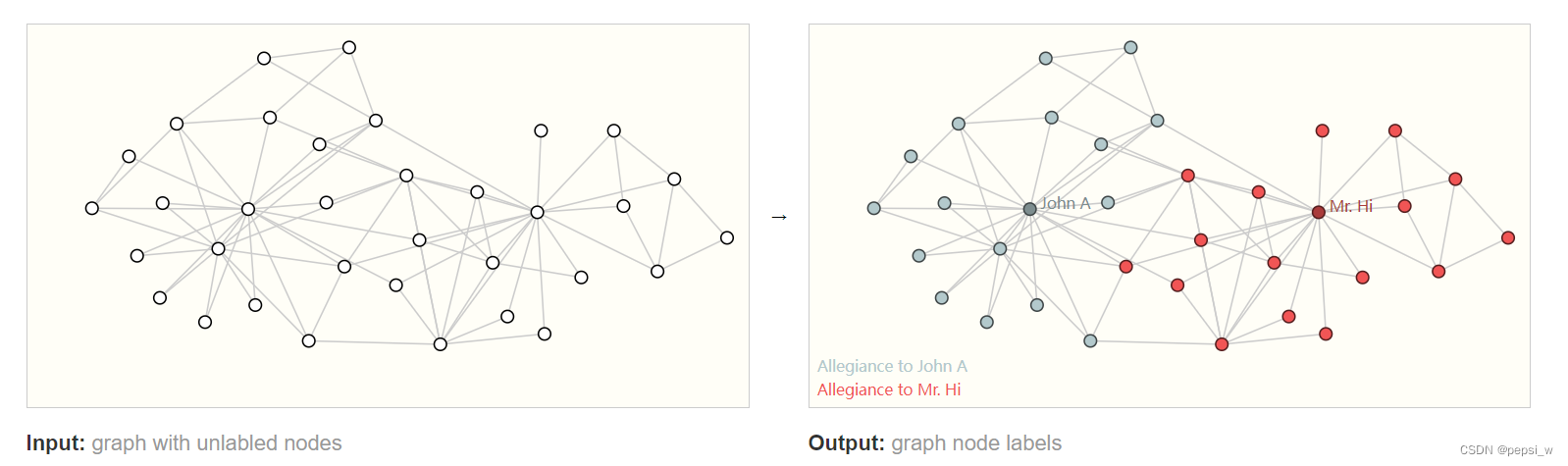
顶点层面,输入node不带类别的graph,输出每个node的类别。类似于图像中的语义分割,文本中的词性分类问题。这里以社交关系(空手道学生与老师)为例,判断顶点的阵营。
边层面,用来预测实体之间的关系。如下图所示,先通过语义分割来将不同部分分割出来,然后判断不同部分的关系。

机器学习运用在图上的挑战
使用神经网络来对图进行处理,首先考虑的是如何表示和神经网络相兼容的图。graph最多有4种想要预测的信息:node、edge、global-context和connectivity。前3个可以用矩阵来表示,对于connectivity的表示要复杂的多,最直接的方式是构建邻接矩阵,但是空间利用率很低,会产生非常稀疏的邻接矩阵。
另一个问题是,一种连接方式可以用多个邻接矩阵来进行表示,如下图所示,一个图的连接情况可以由28个矩阵进行表示:

为了解决这两个问题,使得既能实现高效存储,又能让整个排序不影响邻接矩阵。设下图有8个顶点,7条边。每个顶点、边及全局的属性都用一个标量来表示(可根据需要替换成向量)。引入一个邻接列表,长度与边数相同,第i项表示第i条边连接了哪两个顶点。这样就实现了高效存储,并且对于顺序是无关的,即边的顺序可以任意打乱,打乱后只需要对应得对邻接列表中的顺序进行更新即可,同理顶点顺序也可任意打乱。
图神经网络GNN
简单的GNN
GNN是一个对图上所有的属性进行的一个可以优化的变换,这个变换可保持图的对称信息,所谓的对称信息是指若将图上的顶点进行另外一个排序后,整个结果不会改变。
作者使用的是一个信息传递(message passing)的一个神经网络。GNN的输入输出都是一个图,它会对图的顶点、边、全局等属性(向量)进行变换,但不会改变图的连接性。如下图所示,一共有3个MLP(独自对某一属性来作用,不考虑图的连接性)来分别对点、边、全局的属性进行更新,但最后输出的仍旧是具体相同结构的一个图。

如下图所示,当对某个顶点进行分类的时候,更新后的每个顶点进入到同一个全连接层和一个softmax得到输出,n分类将全连接层输出维度设置为n即可。

当对没有向量的顶点来进行预测的时候, 可以把该点连接的边的向量和全局的向量做一个pooling,作为顶点的向量。

最后也通过一个全连接层来对顶点进行分类,如下图所示。

同样地,在没有边向量的图里面,可以把该边连接的两个顶点的向量和全局向量做pooling操作,作为边的向量进入到输出层,如下图所示。

若没有全局向量,可以用全部的顶点向量来做pooling,如下图所示。

将以上内容结合起来,得到一个简单的GNN,如下图所示。这里的GNN blocks是单独的考虑顶点、边以及全局,没有考虑到整个图的结构(顶点与边之间的连接信息),导致得到的结果没有充分的利用图的信息。classification layer是根据对某一属性进行预测,添加合适的pooling层和全连接层。

改进GNN
由于简单模型中,没有对图的一个整体结构进行处理,这里考虑使用pooling层来对顶点、边、全局进行更新。先将顶点及与它连接的顶点进行一个pooling,得到的新的向量再进入MLP进行更新。这与标准的图片卷积比较相似,但严格意义上来说,卷积是做了加权和,但是这里的pooling是直接相加,并无权值。
如下图所示,顶点信息传递给边,再将边信息传到顶点。

当然也可也反过来边-顶点-边,这里更新顺序不同,会产生完全不同的结果。目前没有一致的结论谁更优,作者提出可以交替更新。同时进行顶点-边、边-顶点,汇聚过后先不进行更新,再反过来汇聚一次,最后再更新。

由于全局向量U与所有的顶点、边相连,所以在做pooling时,会把U也汇聚进来,最后更新U的信息时,也会将所有的顶点与边的信息都传回来再做更新。


这样更新后的图,通过对顶点、边、全局的pooling,最后每个顶点、边包括的就是一个全局的信息。
实验
作者将GNN嵌入JavaScriot中,搭建了一个GNN playground,可以调节超参数,将训练结果可视化。

作者也对不同的超参数对精度影响进行了实验,首先是参数数量对精度的一个影响。可以看出随着参数量增长,整个模型AUC的上限在提高。

向量的长度对结果精度的一个影响,如下图所示。该图称为箱线图,白色的点表示中位线,这里希望中值越高越好,并且希望bar不要太长。可以看出其实向量的长度对精确度的影响不是很大。

不同层数对结果的影响,如下图所示。可以看出层数为3的结果是比较好的,只有一层的结构得到的结果是比较差的。

对不同pooling函数的结果进行对比,如下图所示,可以看出这里其实三种函数的表现是差不多的。

在不同对象中传递消息对结果的一个影响,如下图所示。可以看出不传递任何消息的模型,结果是最差的,在顶点与全局之间,或者顶点、边以及全局之间进行消息传递的模型,效果是比较好的。

总体来看,GNN对超参数还是比较敏感的。
总结
图是一个很强大的工具,基本所有数据都可以表示成一个图,这也使得在图上做优化很难,因为它是一个稀疏架构,每一个结构是动态结构,如何在CPU、GPU和加速器上进行计算是一件很难的事。另外,GNN对超参数很敏感,整个网络架构什么样、如何采样和优化这些温特都使得GNN的门槛很高,目前应用很少。
















 535
535











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









