







原文链接:
https://aclanthology.org/2022.acl-long.63.pdf
ACL 2022
介绍
问题
基于span的方法虽然在解决嵌套实体上存在巨大潜力,但存在以下问题:
1)难以充分利用span的丰富语义;
2)重叠较多的正负样本会降低模型的性能;
3)训练集中的嵌套实体,基本上不会存在于测试集中,即模型需要有较强的泛化能力;
IDEA
因此作者通过利用基于检索的span图来改进span表征,根据n-gram特征连接训练集中的span与实体。
方法
将嵌套实体视为span的分类任务,即将多个相邻的token视为一个span,并预测相应的类别。具体的,对于有n个token的句子![]() ,
,
枚举出所有可能的span 放入集合![]() ,其中
,其中表示xi到xj的span。
整个模型的框架如下图所示:
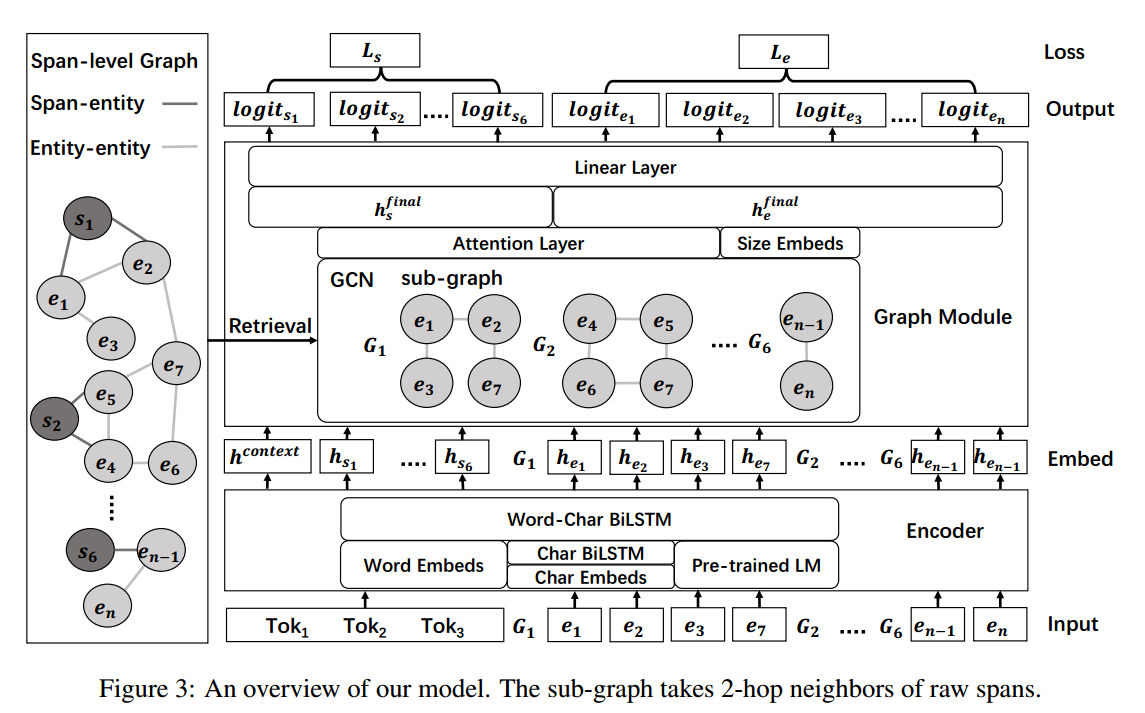
Span-level Graph
这里作者提出了两种图:实体-实体图和跨度-实体图
,如果将每个实体或者原始跨度视为多个相邻跨度,那这两个图都可以模拟跨度之间的关系。
E表示是所有实体的集合,R表示原始span,![]() ,
,![]() 表示图G中顶点v的k跳邻接顶点集合,基于BPE来计算span之间的n-gram相似度
表示图G中顶点v的k跳邻接顶点集合,基于BPE来计算span之间的n-gram相似度![]() 。
。
Entity-entity graph
实体-实体图用![]() 表示,其中,节点是实体集E中的实体,但相同token不同类别的视为不同的节点。对每个结点的不同边,它的n-gram相似度计算公式(即边的权重)如下:
表示,其中,节点是实体集E中的实体,但相同token不同类别的视为不同的节点。对每个结点的不同边,它的n-gram相似度计算公式(即边的权重)如下:
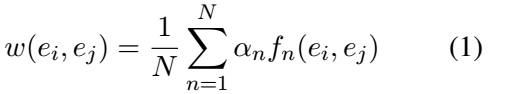
![]() 表示每个n-gram特征的重要程度,N是gram的最大长度,权重越高表示两个实体中词共同出现频率越高。
表示每个n-gram特征的重要程度,N是gram的最大长度,权重越高表示两个实体中词共同出现频率越高。
Span-entity graph
跨度-实体图,对实体和span之间进行建模。节点包括了实体和span,每条边分别连接一个span和一个实体。但span与实体之间的n-gram特征之间存在以下区别:1)越长的span与实体之间就会有更多的语法重叠;2)span比实体更加不规则,总是连接到无意义的实体,存在噪声。
因此,作者提出以下方法来解决该问题:
1)对连接span边的权重,引入长度![]() 来进行惩罚:
来进行惩罚:
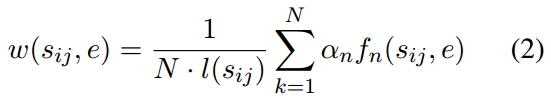
2)通过设置阈值来排除这些span到实体的噪声边,并删除权重低于该阈值的边。
Span-level (sub-)graph
span-level ![]() ,是GEE和GSE的并集,为了提高同构图的训练效率,作者排除了span,即
,是GEE和GSE的并集,为了提高同构图的训练效率,作者排除了span,即![]() ,而为了进行小批量训练,作者从
,而为了进行小批量训练,作者从和
中动态提取span-level子图,由于推理的目标是对原始跨度进行分类,因此我们在训练过程中只提取原始跨度的 K 跳子图。
提取过程如下:
1)对于每个span节点Vs,从中提取它的一阶邻居
![]() ;
;
2)基于一阶邻居,从中提取i跳邻居的集合与其合并,
![]()
3)排除原始span节点Vs,并保留其余节点之间的边,就得到了Vs的子图:![]()
Encoder
将每个token的char embedding(BiLSTM)、word embedding(Word Glove)和context embedding(预训练模型)一起concate后送入BiLSTM来得最终表征hi。对于span级别的表示,作者对span内的单词进行最大池化后得到。
Graph Module
为了对span级图进行建模,作者采用图卷积网络 (GCN) 。A表示G的归一化对称邻接矩阵,GCN的层数也就是子图的跳数K,H0是encoder的输出,则特征矩阵Hk+1 的第(K+1)层为:
![]()
使用注意力机制,在子图表征中融合邻接节点的表征,![]() 表示span在GCN的第k层的隐藏状态,
表示span在GCN的第k层的隐藏状态,![]() 是span的第i个实体邻居在k层的隐藏状态,则原始跨度的子图嵌入
是span的第i个实体邻居在k层的隐藏状态,则原始跨度的子图嵌入![]() :
:
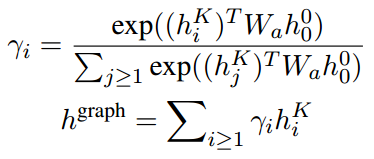
将encoder的输出h0、span的子图embedding、上下文embedding(预训练模型的[CLS]token的向量)、size embedding进行concat得到span的embedding:
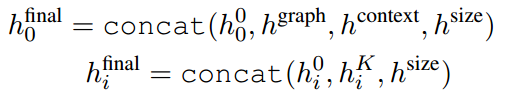
最后,将span h0和实体hi送入线性层得到对数分数:

Multitask Learning
损失函数包括包括span和实体的交叉熵损失两部分:
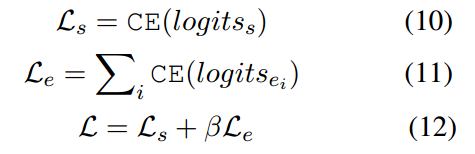
在推理阶段,只涉及到span。
实验
对比实验
在ACE2004、ACE2005、GENIA数据集上进行实验,结果如下图示:

消融实验
对主要模块进行消融实验,结果如下所示:

(这差别,我只能说微乎其微)
与SpERT(我也不知道为啥要跟这个模型做对比,论文链接:SpERT)在嵌套实体上的召回率进行比较,实验结果如下所示:

与SpERT模型在ACE2005数据集中不同长度的实体进行比较,结果如下所示:
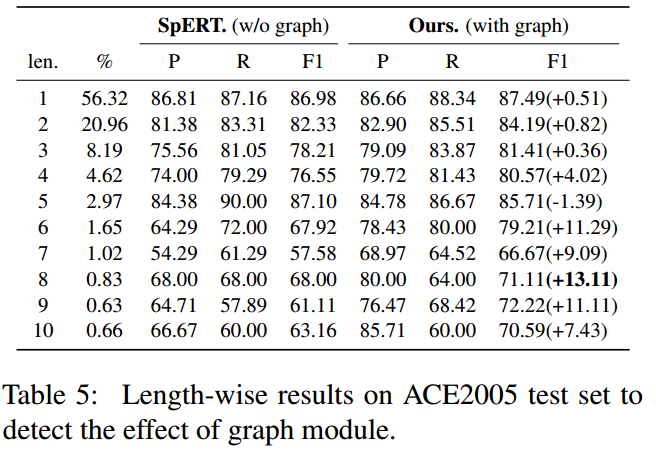
可以看见作者的模型在长实体上有了较大的提升。
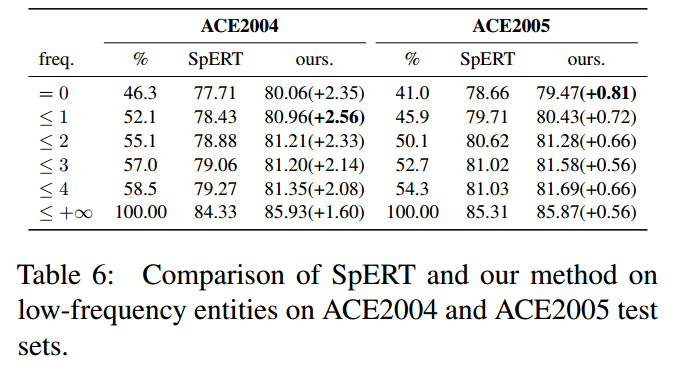
在ACE2004和ACE2005测试集和训练集中频率<4的实体召回率进行比较,结果如下图所示:
Case study
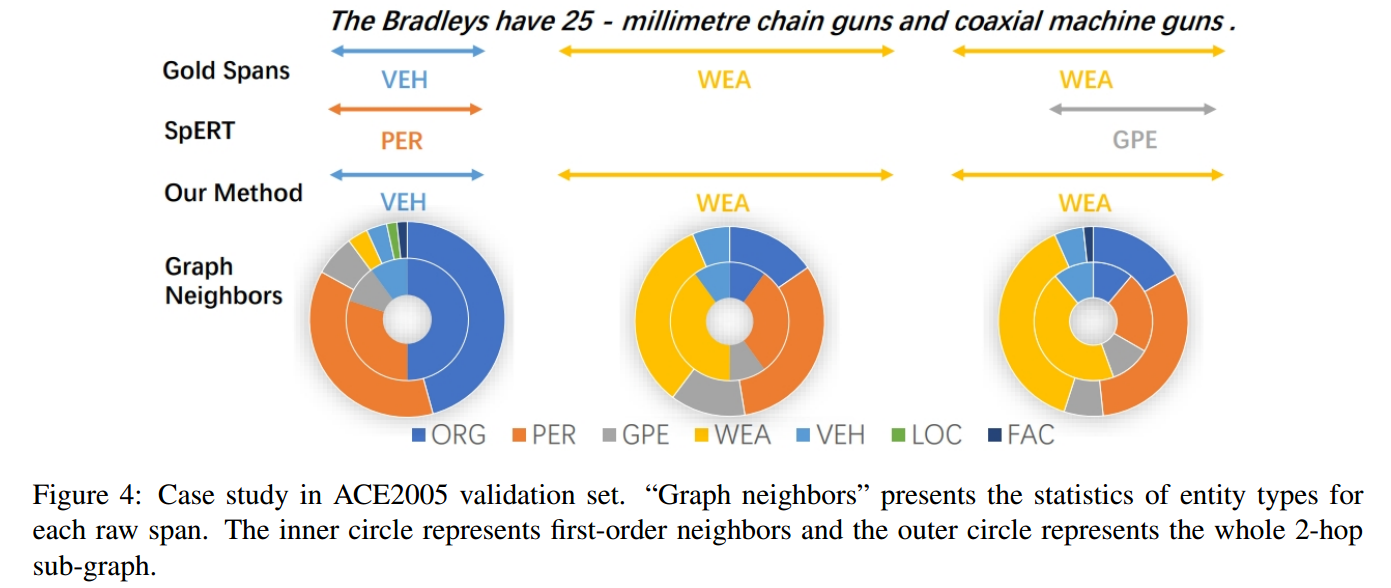
总结
讲得很复杂,模型也很复杂,但是效果不怎么样。消融实验最多只有0.5个点的差距,不好评价。而且作者为什么要跟SpERT这个模型做对比?














 2753
2753











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









