






1.什么是主题模型?
主题模型(Topic Model)是用来在一系列文档中发现抽象主题的一种统计模型。直观来讲,如果一篇文章有一个中心思想,那么一定存在一些特定词语会出现的比较频繁。
比方说,如果现在一篇文章是在讲苹果公司的,那么“乔布斯”和“iPhone”等词语出现的频率会更高一些;如果现在一篇文章是在描述微软公司的,那么“Windows”和“Microsoft”等词语出现的频率会更高一些;
但真实情况下,一篇文章中通常包含多种主题,而且每个主题所占的比例各不相同,比如一篇文章中10%和苹果公司有关,90%和微软公司有关,那么和微软有关的关键字出现的次数应该是苹果关键字出现次数的9倍。
主题模型就是一种自动分析每个文档,统计文档中的词语,根据统计的信息判断当前文档包含哪些主题以及各个主题所占比例各为多少。
主题模型是对文本中隐含主题的一种建模方法,每个主题其实是词表上单词的概率分布;主题模型是一种生成模型,一篇文章中每个词都是通过“以一定概率选择某个主题,并从这个主题中以一定概率选择某个词语”这样一个过程得到的。
2.LDA是什么?
LDA(Latent Dirichlet Allocation)由Blei, David M.、Ng, Andrew Y.、Jordan于2003年提出,是一种主题模型,它可以将每篇文档的主题以概率分布的形式给出,从而通过分析一些文档抽取出它们的主题(分布)出来后,便可以根据主题(分布)进行主题聚类或文本分类。同时,LDA主题模型不关心文档中单词的顺序,它是一种典型的词袋模型,即一篇文档是由一组词构成,词与词之间没有先后顺序的关系。(参考:NLP三种词袋模型CountVectorizer/TFIDF/HashVectorizer)此外,一篇文档可以包含多个主题,文档中每一个词都由其中的一个主题生成。
了解LDA模型,我们需要先了解LDA的生成模型,LDA认为一篇文章是怎么形成的呢?
LDA模型认为主题可以由一个词汇分布来表示,而文章可以由主题分布来表示。比如有两个主题,美食和美妆。LDA说两个主题可以由词汇分布表示,他们分别是:
{面包:0.4,火锅:0.5,眉笔:0.03,腮红:0.07}
{眉笔:0.4,腮红:0.5,面包:0.03,火锅:0.07}
同样,对于两篇文章,LDA认为文章可以由主题分布这么表示:
《美妆日记》{美妆:0.8,美食:0.1,其他:0.1}
《美食探索》{美食:0.8,美妆:0.1,其他:0.1}
所以想要生成一篇文章,可以先以一定的概率选取上述某个主题,再以一定的概率选取那个主题下的某个单词,不断重复这两步就可以生成最终文章。
我们引用三位作者在原始论文中的一个简单的例子。在LDA模型中,每个文档被看作是多个主题的混合,而每个主题则被定义为词汇表上的概率分布。例如:
- Arts:这个主题可能与艺术相关的内容,比如音乐、戏剧、电影等。在LDA模型中,与"Arts"相关的词汇可能包括"music"、"theater"、"exhibit"等。
- Budgets:这个主题可能涉及财政预算相关的内容,如政府支出、税收、经济计划等。相关的词汇可能包括"finance"、"spending"、"tax"等。
- Children:这个主题可能与儿童相关的话题,如教育、健康、儿童福利等。相关的词汇可能包括"pediatrics"、"education"、"childcare"等。
- Education:这个主题涉及教育领域,可能包括学校政策、课程发展、学生成就等。相关的词汇可能包括"school"、"curriculum"、"students"等。
在LDA模型中,每个文档都会被表示为这些主题的混合,每个主题在文档中有一定的比例。例如,一篇关于学校预算的新闻文章可能会被表示为"Budgets"主题的一个强指标,同时也轻微地涉及"Education"主题。通过这种方式,LDA模型能够识别和量化文档集合中的主题分布,帮助我们理解文档内容的高级结构。
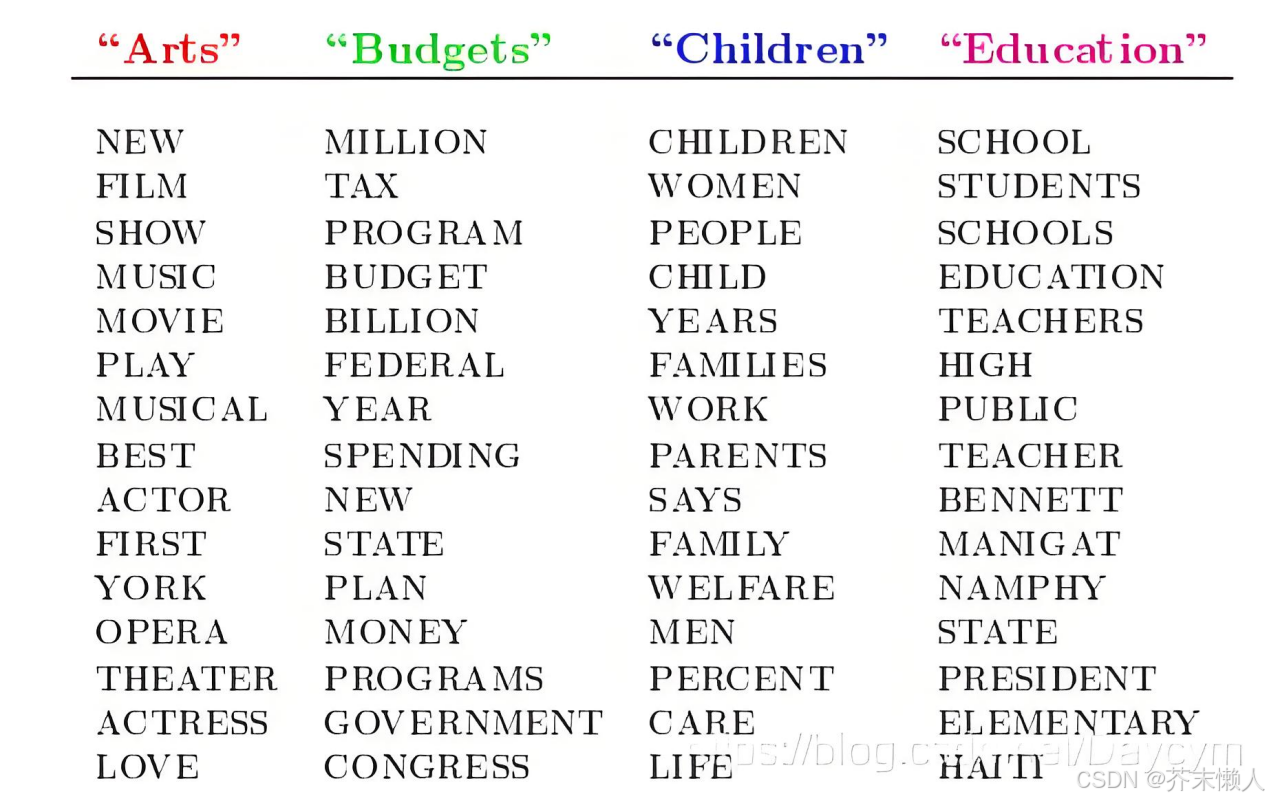
通过此插图,可以确定不同主题如何在文档文本中混合。

LDA 主题模型要干的事就是:根据给定的一篇文档,反推其主题分布。
看到文章推断其隐藏的主题分布,就是建模的目的。换言之,人类根据文档生成模型写成了各类文章,然后丢给了计算机,相当于计算机看到的是一篇篇已经写好的文章。现在计算机需要根据一篇篇文章中看到的一系列词归纳出当篇文章的主题,进而得出各个主题各自不同的出现概率:主题分布。
LDA主题模型简介及Python实现-CSDN博客Dirichlet分布:LDA主题模型简介及Python实现-CSDN博客
详细的数学推导:通俗理解LDA主题模型(2014年版)-CSDN博客
至于LDA主题模型在计算机中具体是怎么实现的,我们也可以不必细究,现在有很多可以直接用来进行LDA主题分析的包,我们直接用就行。
3.如何构建LDA主题模型?
预处理数据:这是大多数自然语言处理任务的第一步,包括文本清洗、标准化、分词、去除停用词等。预处理的目标是将原始文本转换为可以输入到模型的格式。
构建文档-词项矩阵:在预处理后,我们需要将文档转化为一种数值表示。在主题模型中,通常情况下我们会构建个文档-词项矩阵,其中每一行表示一个文档,每一列表示一个词项(通常是一个词或短语),并且每个单元格的值表示词顶在该文档中的频率或权重。
LDA模型训练:在构建了文档-词项矩阵之后,我们就可以使用LDA模型来进行训练。在训练过程中,我们需要设定主题数(即我们希望模型发现的主题数量)。型将尝试寻找每个主题下最重要的词项,以及每个文档中各个主题的分布。
分析结果:模型训练结束后,我们可以分析其结果。LDA模型的输出包括每个主题的词项分布以及每个文档的主题分布。我们可以通过查看每个主题的最重要的词项来理解主题的内容,也可以查看每个文档的主题分布来理解文档的主题结构。
4.python实现
1.导入算法包
在用python进行LDA主题模型分析之前,先对文档进行了分词和停用词处理。
分词是文本信息处理的基础环节,是将一个单词序列切分成单个单词的过程。中文分词的任务就是把中文的序列切分成有意义的词,即添加合适的词串使得所形成的词串反映句子的本意。
停用词也就是电脑检索中的虚字、非检索用字。
import jieba
import pandas as pd
# import warnings
# warnings.simplefilter('ignore', PendingDeprecationWarning)
# from sklearn.feature_extraction.text import TfidfVectorizer
from gensim import corpora, models
import pyLDAvis
import pyLDAvis.gensim_models
import matplotlib.pyplot as plt
from sklearn.feature_extraction.text import TfidfVectorizer
# 1. 读取政策文本数据
with open('D:/pythonProjects/lda_1112/test_input.txt', 'r', encoding='utf-8') as file:
content = file.read()
# print(content)
texts = content.split()
# print(texts)
# 2. 分词和去停用词
def preprocess(text):
stopwords = set(line.strip() for line in open('D:/pythonProjects/lda_1112/stopwords.txt', encoding='utf-8'))
words = jieba.lcut(text)
return ' '.join([word for word in words if word not in stopwords])
processed_texts = [preprocess(text) for text in texts]
# 3. 生成 TF-IDF 矩阵
tfidf_vectorizer = TfidfVectorizer()
tfidf_matrix = tfidf_vectorizer.fit_transform(processed_texts)
# Print the processed texts
for i, text in enumerate(processed_texts):
print(f"Processed text {i + 1}: {text}")
# Print the feature names
feature_names = tfidf_vectorizer.get_feature_names_out()
print("Feature names:")
print(feature_names)
# Print the TF-IDF matrix
print("TF-IDF matrix:")
print(tfidf_matrix.toarray())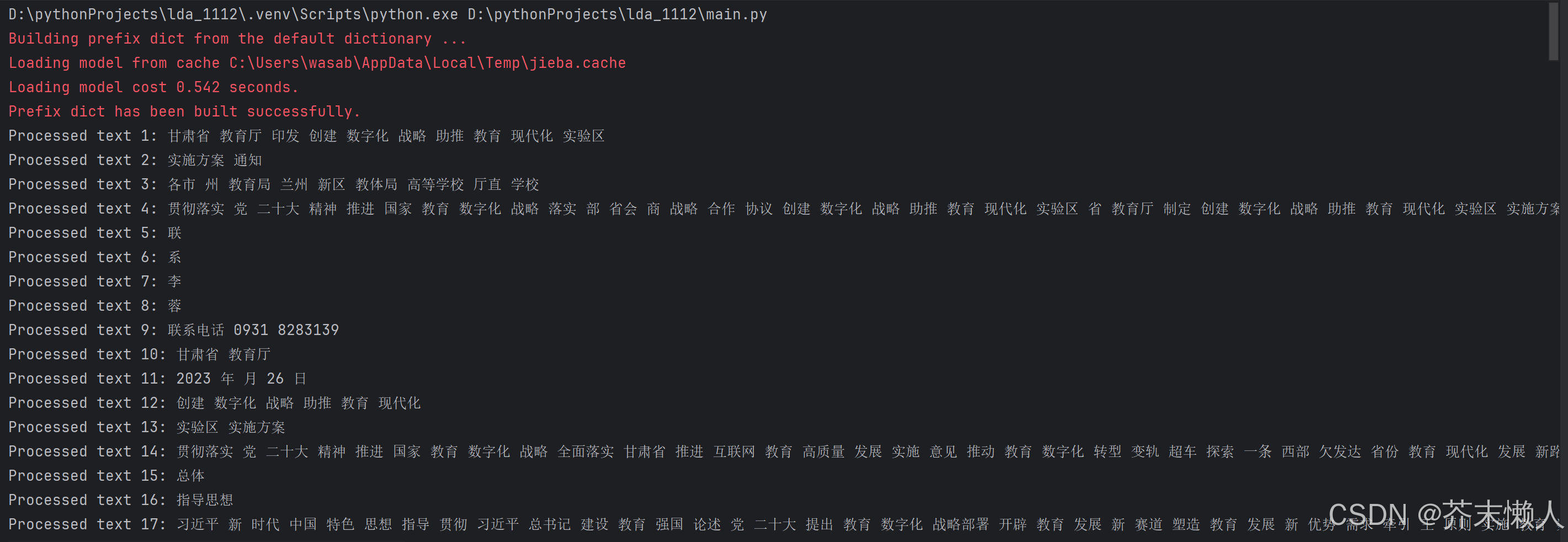

2.加载数据
建构词典、语料向量化表示:创建了Gensim库所需的字典和语料库。字典包含了所有文档的词汇,而语料库则是将文档转换为词袋模型。
# 4. 创建字典和语料库
dictionary = corpora.Dictionary([text.split() for text in processed_texts])
corpus = [dictionary.doc2bow(text.split()) for text in processed_texts]3.确定最佳主题数量
(1)通过Jaccard相似度确定最佳主题数量:用于衡量两个主题之间的相似性,帮助我们确定主题是否太过相似,从而避免选择过多重复的主题。
from itertools import combinations
import numpy as np
# 3. 定义获取主题关键词的函数
def get_topic_keywords(lda_model, top_n=10):
# 获取每个主题的关键词,按重要性排序
topic_keywords = []
for i in range(lda_model.num_topics):
words = [word for word, prob in lda_model.show_topic(i, top_n)]
topic_keywords.append(set(words))
return topic_keywords
# 4. 训练多个 LDA 模型并计算 Jaccard 相似度
def calculate_jaccard_sim_for_topics(topic_keywords):
jaccard_sims = []
for (topic1, topic2) in combinations(topic_keywords, 2):
# 计算两个主题关键词集合的 Jaccard 相似度
intersection = len(topic1.intersection(topic2))
union = len(topic1.union(topic2))
jaccard_sim = intersection / union
jaccard_sims.append(jaccard_sim)
return np.mean(jaccard_sims) # 返回平均 Jaccard 相似度
# 5. 通过 Jaccard 相似度确定最佳主题数量
num_topics_range = range(2, 10) # 假设我们尝试 2 到 10 个主题
best_num_topics = None
best_jaccard = 1.0 # 初始设置为 1.0,即完全相似
for num_topics in num_topics_range:
lda_model = models.LdaModel(corpus, num_topics=num_topics, id2word=dictionary, passes=10)
topic_keywords = get_topic_keywords(lda_model, top_n=10)
jaccard_mean = calculate_jaccard_sim_for_topics(topic_keywords)
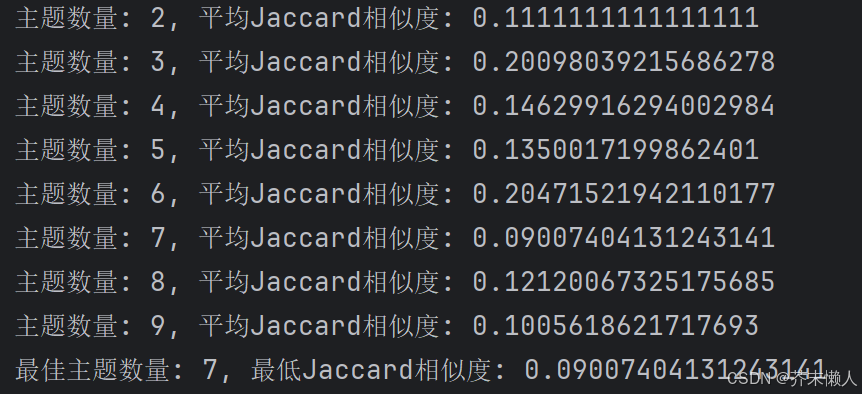
print(f'主题数量: {num_topics}, 平均Jaccard相似度: {jaccard_mean}')
# 找到最小的 Jaccard 相似度,表示主题差异最大
if jaccard_mean < best_jaccard:
best_jaccard = jaccard_mean
best_num_topics = num_topics
print(f'最佳主题数量: {best_num_topics}, 最低Jaccard相似度: {best_jaccard}')
(2)通过困惑度确定最佳主题数量:衡量LDA模型对数据的预测能力,帮助我们选择模型预测能力最强的主题数量。困惑度是衡量语言模型好坏的一个重要指标,值越低表示模型越好。
from sklearn.model_selection import train_test_split
# 3. 划分训练集和测试集(计算困惑度时常用)
train_corpus, test_corpus = train_test_split(corpus, test_size=0.2, random_state=42)
# 4. 计算不同主题数下的困惑度
def compute_perplexity(corpus, dictionary, num_topics_range):
perplexities = []
for num_topics in num_topics_range:
lda_model = models.LdaModel(corpus, num_topics=num_topics, id2word=dictionary, passes=10)
perplexity = lda_model.log_perplexity(test_corpus) # 使用测试集计算困惑度
perplexities.append(perplexity)
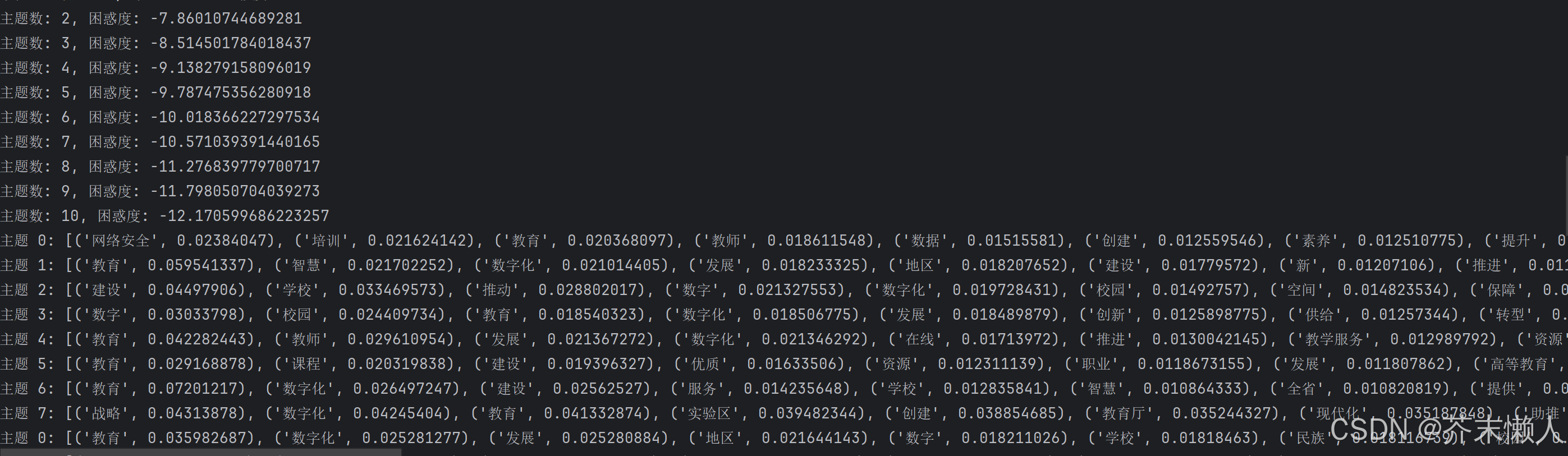
print(f'主题数: {num_topics}, 困惑度: {perplexity}')
return perplexities
# 选择主题数范围,比如从 2 到 10
num_topics_range = range(2, 11)
perplexities = compute_perplexity(train_corpus, dictionary, num_topics_range)
# 5. 绘制主题数与困惑度的关系图,找出困惑度最低点
plt.plot(num_topics_range, perplexities, marker='o')
plt.xlabel('topic')
plt.ylabel('perplexity')
plt.title('Perplexity and Number of Topics')
plt.show()
4. 训练LDA模型并显示每个主题下的关键词
训练了一个LDA模型,并显示了每个主题下的前15个关键词,有助于理解每个主题的含义。
# 5. 训练 LDA 模型
def create_lda_model(num_topics):
lda_model = models.LdaModel(corpus, num_topics=num_topics, id2word=dictionary, passes=10)
return lda_model
optimal_num_topics = 8 # 可以在这里调整不同的主题数进行实验
lda_model = create_lda_model(optimal_num_topics)
# 8. 显示每个主题下的 15 个特征词,特征词是 LDA 模型识别的每个主题中最具代表性的词汇。
num_words_per_topic = 15
for i in range(optimal_num_topics):
print(f'主题 {i}: {lda_model.show_topic(i, num_words_per_topic)}')
5.结果输出与可视化
将每篇文档的主题分布转换为一个矩阵,便于查看每个文档属于各个主题的概率。
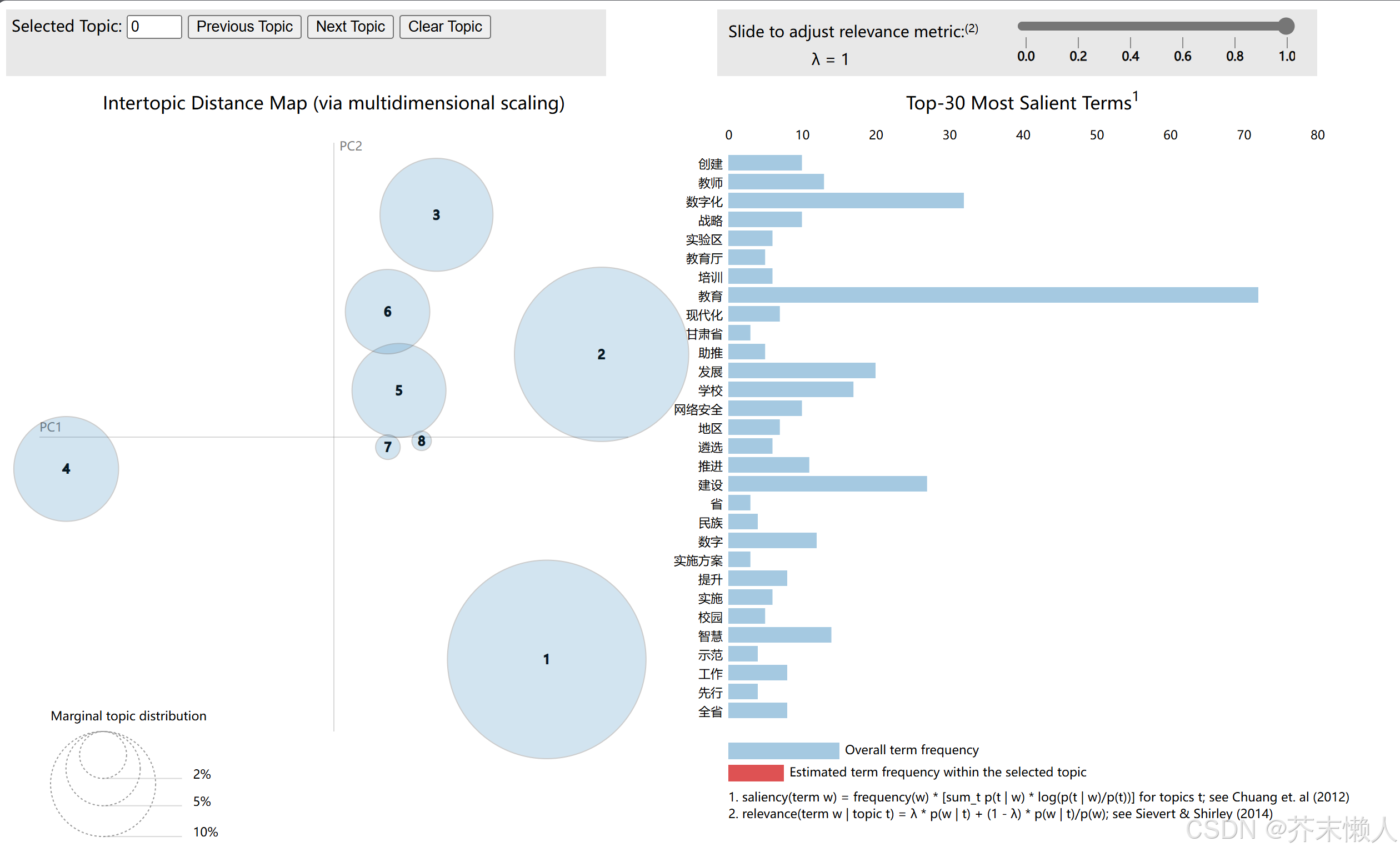
使用pyLDAvis库对LDA模型的结果进行可视化,这有助于更直观地理解主题模型的效果。
# 9. 生成文本—主题概率矩阵
# 获取每篇文档的主题分布
doc_topic_dists = []
for bow in corpus:
topic_dist = lda_model.get_document_topics(bow, minimum_probability=0.0) # 获取每篇文档的主题分布
doc_topic_dists.append([prob for _, prob in topic_dist])
# 将其转换为 DataFrame 方便查看
doc_topic_matrix = pd.DataFrame(doc_topic_dists, columns=[f'主题 {i}' for i in range(optimal_num_topics)])
print(doc_topic_matrix)
# 保存为CSV文件
# doc_topic_matrix.to_csv('doc_topic_matrix.csv', index=False)
# 6. 使用 pyLDAvis 可视化
vis = pyLDAvis.gensim_models.prepare(lda_model, corpus, dictionary, n_jobs=1)
# pyLDAvis.display(vis)
pyLDAvis.save_html(vis, 'lda_pass.html') # 将结果保存为该html文件可以得出下图结果:

















 1145
1145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









