









四个类别:第0类 train:10000张 test:1685张 第1类:train:10000张 test:1250张 第2类:train:10000张 test:3553张 第3类:train:10000张 test:3639张
合计:train:40000张 test:10127张 图片要相同尺寸
一、生成label.txt
#include<iostream>
#include<string>
int main()
{
FILE *fid1;
fid1 = fopen("train_labels10.9.txt", "w");
int label0 = 0, label1 = 1,label2=2,label3=3;
char name[15], label[2], black[] = "\r\n";
memset(name, 0, sizeof(name));
for (int i = 0; i < 40000; ++i)
{
itoa(i, name, 10);
strcat(name, ".jpg ");
if (i<10000)
itoa(label0, label, 10);
else if (i>=10000 & i<20000)
itoa(label1, label, 10);
else if (i >= 20000 & i<30000)
itoa(label2, label, 10);
else
itoa(label3, label, 10);
strcat(name, label);
printf("%s", name);
fwrite(name, sizeof(name), 1, fid1);
fwrite(black, strlen(black), 1, fid1);
memset(name, 0, sizeof(name));
memset(label, 0, sizeof(label));
}
fclose(fid1);
return 0;
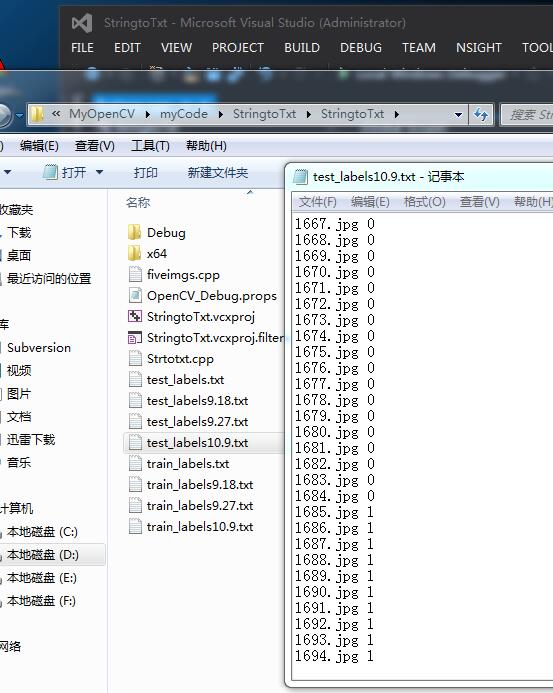
}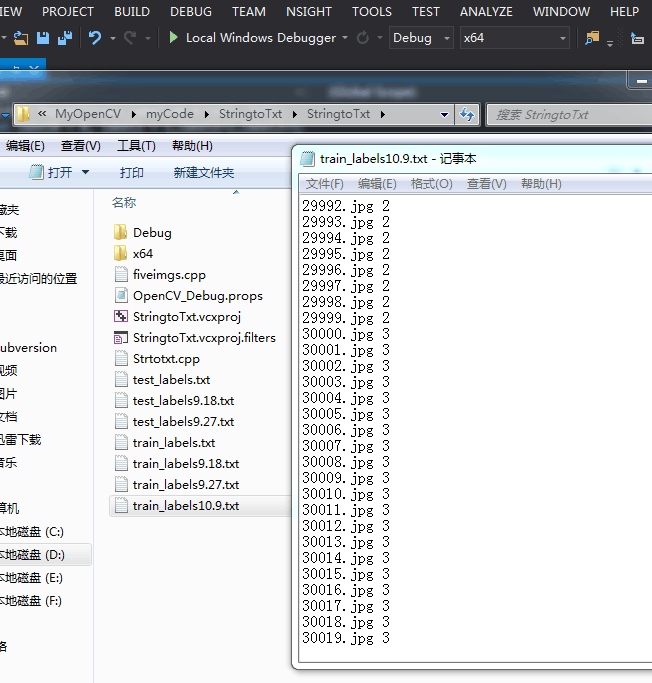 test文件夹也一样生成标签的txt
test文件夹也一样生成标签的txt

二、转化为lmdb
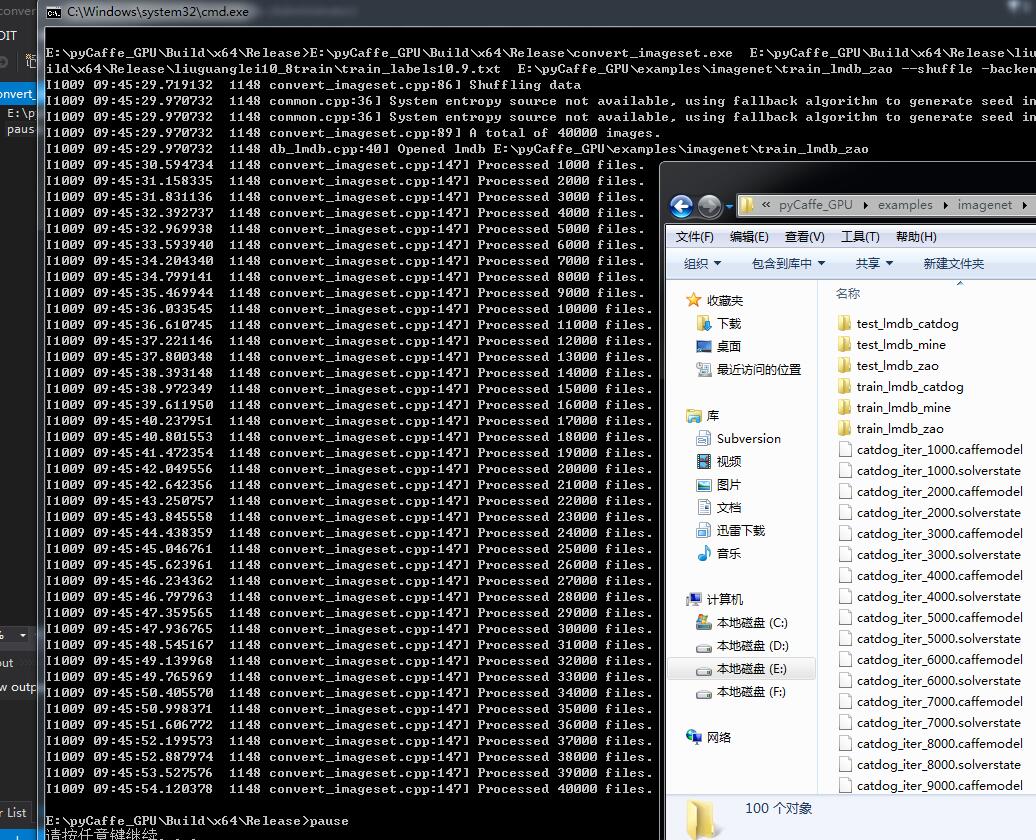
E:\pyCaffe_GPU\Build\x64\Release\convert_imageset.exe E:\pyCaffe_GPU\Build\x64\Release\liuguanglei10_8train\ E:\pyCaffe_GPU\Build\x64\Release\liuguanglei10_8train\train_labels10.9.txt E:\pyCaffe_GPU\examples\imagenet\train_lmdb_zao --shuffle -backend=lmdb
pause
三、计算train和test的mean.binaryproto
E:\pyCaffe_GPU\Build\x64\Release\compute_image_mean.exe E:\pyCaffe_GPU\examples\imagenet\train_lmdb_zao E:\pyCaffe_GPU\examples\imagenet\mean_zao_train.binaryproto
pause 
四、写两个prototxt属性文件
name: "CaffeNet"
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
crop_size: 190
mean_file: "E:/pyCaffe_GPU/examples/imagenet/mean_zao_train.binaryproto"
}
data_param {
source: "E:/pyCaffe_GPU/examples/imagenet/train_lmdb_zao/"
batch_size: 100
backend: LMDB
}
}
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mirror: false
crop_size: 190
mean_file: "E:/pyCaffe_GPU/examples/imagenet/mean_zao_test.binaryproto"
}
data_param {
source: "E:/pyCaffe_GPU/examples/imagenet/test_lmdb_zao/"
batch_size: 20
backend: LMDB
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 13
kernel_size: 5
stride: 5
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "conv1"
top: "conv1"
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 5
stride: 3
}
}
layer {
name: "norm1"
type: "LRN"
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "norm1"
top: "conv2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 26
kernel_size: 3
stride: 1
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu2"
type: "ReLU"
bottom: "conv2"
top: "conv2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 3
stride: 1
}
}
layer {
name: "norm2"
type: "LRN"
bottom: "pool2"
top: "norm2"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "fc3"
type: "InnerProduct"
bottom: "pool2"
top: "fc3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 1050
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu3"
type: "ReLU"
bottom: "fc3"
top: "fc3"
}
layer {
name: "drop3"
type: "Dropout"
bottom: "fc3"
top: "fc3"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc4"
type: "InnerProduct"
bottom: "fc3"
top: "fc4"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 4
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "fc4"
bottom: "label"
top: "accuracy"
include {
phase: TRAIN
}
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "fc4"
bottom: "label"
top: "accuracy"
include {
phase: TEST
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "fc4"
bottom: "label"
top: "loss"
}
net: "E:/pyCaffe_GPU/examples/imagenet/zaotraintest.prototxt"
test_iter: 550
test_interval: 100
base_lr: 0.0001
momentum: 0.9
weight_decay: 0.0005
lr_policy: "step"
gamma: 0.1
stepsize:1000
power: 0.75
display: 10
max_iter: 20000
snapshot: 2000
snapshot_prefix: "E:/pyCaffe_GPU/examples/imagenet/zao"
solver_mode: GPUE:\pyCaffe_GPU\Build\x64\Release\caffe.exe train --solver=E:\pyCaffe_GPU\examples\imagenet\zaosolver.prototxt >zao_log.txt 2>&1
六、画accuracy及loss曲线图
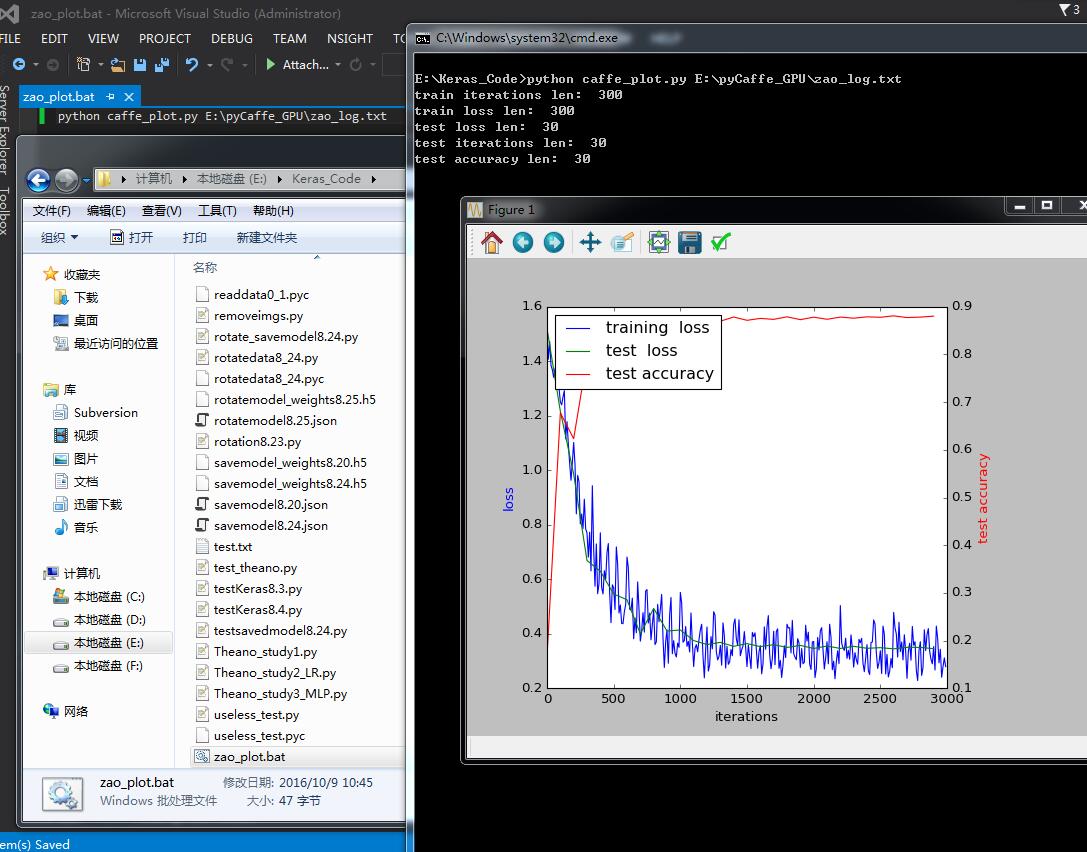
训练出了caffemodel!
七、预测验证集类别
我有验证集4127张。
1,写自己的deploy文件
name: "CaffeNet"
layer {
name: "data"
type: "Input"
top: "data"
input_param { shape: { dim: 10 dim: 3 dim: 190 dim: 190 } }
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 13
kernel_size: 5
stride: 5
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "conv1"
top: "conv1"
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 5
stride: 3
}
}
layer {
name: "norm1"
type: "LRN"
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "norm1"
top: "conv2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 26
kernel_size: 3
stride: 1
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu2"
type: "ReLU"
bottom: "conv2"
top: "conv2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 3
stride: 1
}
}
layer {
name: "norm2"
type: "LRN"
bottom: "pool2"
top: "norm2"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "fc3"
type: "InnerProduct"
bottom: "pool2"
top: "fc3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 1050
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu3"
type: "ReLU"
bottom: "fc3"
top: "fc3"
}
layer {
name: "drop3"
type: "Dropout"
bottom: "fc3"
top: "fc3"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc4"
type: "InnerProduct"
bottom: "fc3"
top: "fc4"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 4
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "prob"
type: "Softmax"
bottom: "fc4"
top: "prob"
}2、预测类别的脚本py
#http://www.111cn.net/phper/python/47504.htm
import time
start=time.clock()
import os
from myclassify1img import classify1img
import caffe
caffe.set_mode_gpu()
caffe.set_device(0)
dir_path='E:/pyCaffe_GPU/examples/imagenet/zao_val/'
imglist=[]
for path,d,filelist in os.walk(dir_path):
filelist.sort(key= lambda x:int(x[:-4]))
for filename in filelist:
mypath =dir_path + filename
imglist.append(mypath)
print imglist
net_file='E:\pyCaffe_GPU\examples\imagenet\mydeploy_zao.prototxt'
caffe_model='E:\pyCaffe_GPU\examples\imagenet\zao_iter_20000.caffemodel'
mean_file='E:\pyCaffe_GPU\examples\imagenet\mean_zao_train.binaryproto'
class_result='E:\pyCaffe_GPU\examples\imagenet\zao_class_result.txt'
net = caffe.Net(net_file,caffe_model,caffe.TEST)
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape})
transformer.set_transpose('data', (2,0,1))
#transformer.set_mean('data', np.load(mean_file).mean(1).mean(1))
mean_blob = caffe.proto.caffe_pb2.BlobProto()
mean_blob.ParseFromString(open(mean_file, 'rb').read())
mean_npy = caffe.io.blobproto_to_array(mean_blob)
b2=mean_npy[0,:,:,:]
transformer.set_mean('data',b2.mean(1).mean(1))
transformer.set_raw_scale('data', 255)
transformer.set_channel_swap('data', (2,1,0)) # if using RGB instead if BGR
#img=caffe.io.load_image('E:/Keras_Code/examples/imagenet/forclassify/test13.bmp')
imagenet_labels_filename = 'E:\pyCaffe_GPU\examples\imagenet\zao_label.txt'
allclass=[]
for file in imglist:
img=file
myclass=classify1img(imagenet_labels_filename,net,transformer,img)
allclass.append(myclass)
f=open(class_result,'w')
for ind in range(len(filelist)):
f.write(filelist[ind]+' '+allclass[ind]+'\n')
f.close()
finish=time.clock()
print "read: %f s"%(finish - start)
结果:
搞定!
3、计算准确率:
#include <iostream>
#include <fstream>
using namespace std;
#define NUM 4126
int i, Datalen = -1;
double Data[NUM];
int main(void)
{
int pre_class, cor1 = 0, cor2 = 0, cor3 = 0, cor4 = 0,all3=0,all0=0,all1=0,all2=0,correct=0;
ifstream fin("zao_class_result.txt");
if (!fin)
{
cerr << "Can not open txt file." << endl;
getchar();
return 1;
};
while (!fin.eof())
{
Datalen++;
fin >> Data[Datalen];
};
fin.close();
for (i = 0; i <= NUM; i++)
{
pre_class = Data[i];
//cout << pre_class << " ";
if (i < 685)
{
++all0;
if (pre_class == 0)
++cor1;
}
else if (i >= 685 & i < 935)
{
++all1;
if (pre_class == 1)
++cor2;
}
else if (i >= 935 & i < 2488)
{
++all2;
if (pre_class == 2)
++cor3;
}
else
{
++all3;
if (pre_class == 3)
++cor4;
}
}
//cout << endl << endl;
cout << cor1 << " " << cor2 << " " << cor3 << " " << cor4 << endl;
cout << all0 << " " << all1 << " " << all2 << " " << all3 << endl;
correct = cor1 + cor2 + cor3 + cor4;
//cout << "correct number:" << correct << endl;
double ac = correct / double(NUM+1);
cout << "correct number:" << ac << endl;
return 0;
}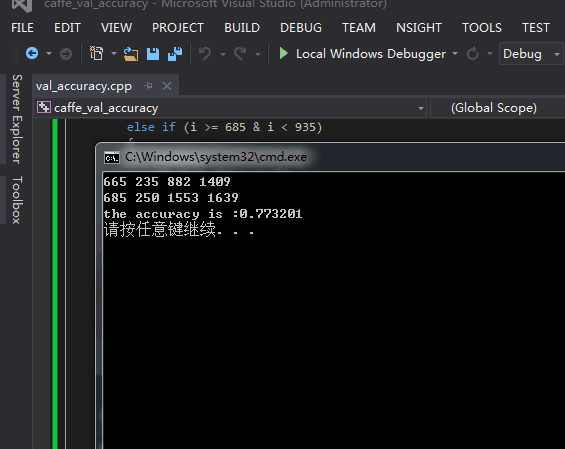 一共4127张 准确率77%
一共4127张 准确率77%
八、提取特征
#extract many images in one folder
import time
start=time.clock()
import os
import numpy as np
import matplotlib.pyplot as plt
import caffe
from useless_test import vis_square
from PIL import Image
import scipy.io as sio
caffe.set_mode_gpu()
caffe.set_device(0)
deployPrototxt ='E:\pyCaffe_GPU\examples\imagenet\mydeploy_zao.prototxt' #
modelFile ='E:\pyCaffe_GPU\examples\imagenet\zao_iter_20000.caffemodel' #
mean_file='E:\pyCaffe_GPU\examples\imagenet\mean_zao_train.binaryproto' #
net = caffe.Net(deployPrototxt, modelFile,caffe.TEST)
#for layer_name, blob in net.blobs.iteritems():
# print layer_name + '\t' + str(blob.data.shape)
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape})
transformer.set_transpose('data', (2,0,1))
mean_blob = caffe.proto.caffe_pb2.BlobProto()
mean_blob.ParseFromString(open(mean_file, 'rb').read())
mean_npy = caffe.io.blobproto_to_array(mean_blob)
b2=mean_npy[0,:,:,:]
transformer.set_mean('data',b2.mean(1).mean(1))
transformer.set_raw_scale('data', 255)
transformer.set_channel_swap('data', (2,1,0))
net.blobs['data'].reshape(1,3,190,190) #
dir_path='E:/pyCaffe_GPU/examples/imagenet/zao_val' #
filelists=os.listdir(dir_path)
#print filelists
#dim=4096 changed by you
features = np.empty((len(filelists),1050),dtype="float32") #
for ind,everyimg in enumerate(filelists):
theimg='E:/pyCaffe_GPU/examples/imagenet/zao_val/'+everyimg
net.blobs['data'].data[...] = transformer.preprocess('data',caffe.io.load_image(theimg))
net.forward()
feat_fc= net.blobs['fc3'].data[0]
feat_fc.shape=(1050,1) #
row_feat_fc=np.transpose(feat_fc)
features[ind,:]=row_feat_fc
#np.savetxt("E:/Keras_Code/examples/imagenet/savefeatures.txt",row_feat_fc)
sio.savemat("E:/pyCaffe_GPU/examples/imagenet/zao_imgsfeatures.mat", {'feature':features}) #
finish=time.clock()
print "read: %f s"%(finish - start)
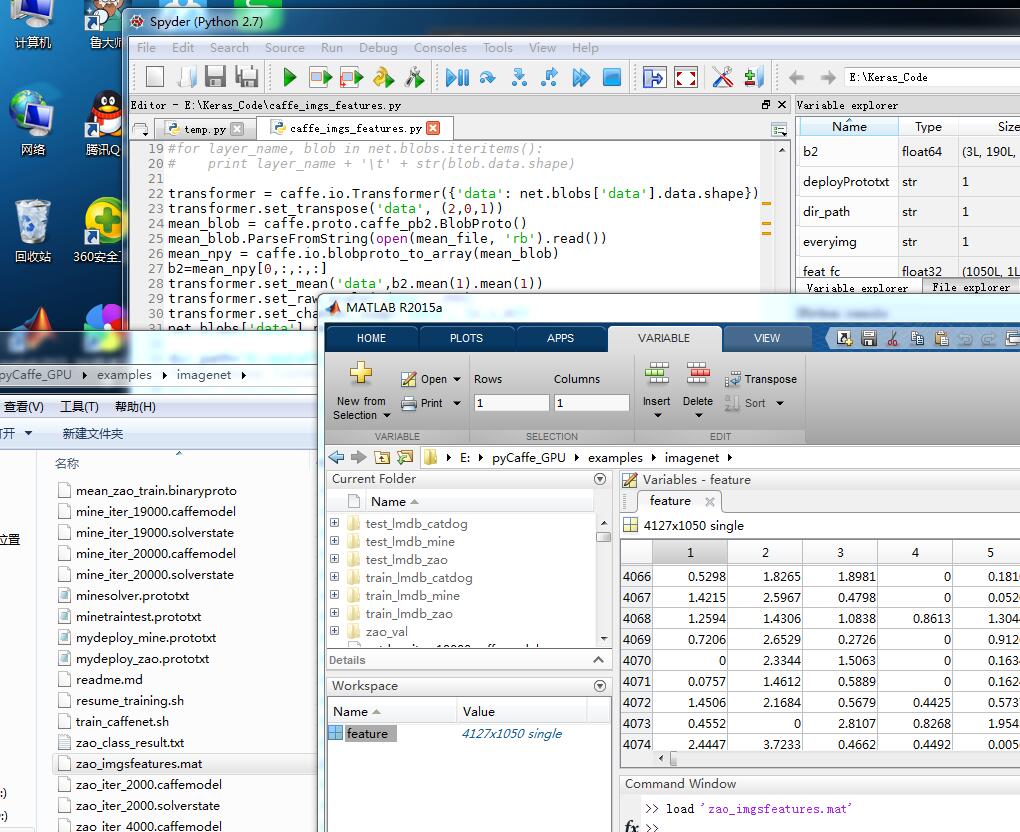 OK啦!
OK啦!
/
最讨厌星期一!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!不想上班!!!!!要是有坐在家里收钱的工作就好了!!!!!!!!
















 917
917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











