






用于自己学习记录,如有错误,欢迎大家讨论!!!!!
研究背景
1.机器人的控制策略主要有3大类别:
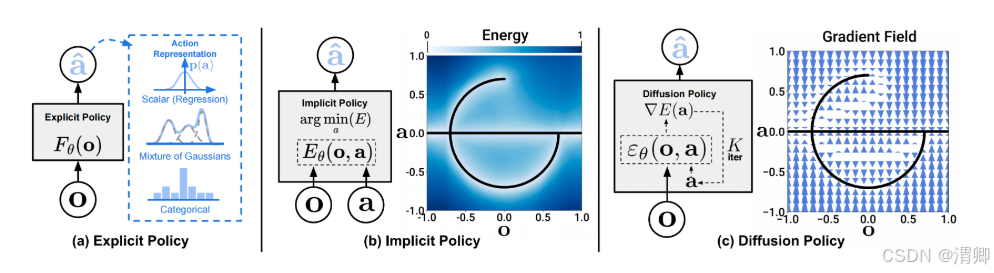
(1) 显式方程的动作策略,根据条件(这里说的视觉,还可以是wrench)给出动作策略。
(2) 隐式方程的动作策略,根据当前条件、动作的得分,优化出动作策略
(3) 条件去噪扩散动作生成,根据条件,带噪声的动作,生成动作策略
2. 扩散策略的三大重要特征(优点)
(1)多模态动作分布表示:这意味着它能够生成多种可能的动作序列,即使这些序列在动作空间 中不是连续的或者有多个峰值(即多模态)
(2)高维输出空间:这意味着策略不仅能够决定单一步骤的动作,还能够推断出一系列未来动作 (高维),这对于保持动作的连贯性和避免短视的决策至关重要。
(3)稳定训练:不需要进行负采样来估计归一化常数,通过直接学习能量函数的梯度,绕过了对 归一化常数的估计,从而实现了更稳定的训练过程(需要了解强化学习)。
3.为了将模型更好地应用在real机器人上:
(1)闭环动作序列:很好地结合了预测高维动作策略序列的能力和递推视觉控制,实现策略以闭 环方式持续重新规划其动作,同时保持时间上的动作一致性,从而在长视距规划和响应性之间 实现平衡。
(2)视觉条件化:引入了一种视觉条件化扩散策略,其中视觉观测被视为条件而不是联合数据分 布的一部分(这里就是说的是传统GMM策略表示中机器人状态-动作的联合分布),策略只需 提取一次视觉表示,而无需考虑去噪迭代(这里说的是如果作为被训练数据的话,需要反复迭 代优化),从而大大减少了计算量,并实现了实时动作推理。
(3)时间序列扩散transformer:提出了一个transformer为基础框架的扩散模型,为了克服CNN 扩散模型存在的过平滑影响。能做出快速响应。
4.视觉运动的扩散策略学习(原理)
(1)扩散过程(DDPM)的回顾:
(a)从高斯噪声中采样出Xk开始,执行K次去噪迭代,以生成一系列噪声逐渐减少的中间动 作 (Xk-1,….X0),直到形成所需的无噪声输出X0.

(b)上述的去噪过程可以看作一个单一的噪声梯度下降过程:
![]()
这里解释了噪声估计网络对噪声的预测,其实相当于预测到了能量函数的梯度场,从而 调整X(动作)的位置(就是在整个动作值域内的取值)。公式中E(X)就相当于能量函 数,▽E(x)就是能量函数的梯度,也是噪声。
(c)训练噪声预测模型过程:
首先从数据集中随机抽取未修改的样本X0,开始设置K次迭代。在每次迭代过程中,采样 一个具有适当方差的随机噪声ek(这里的k是代表第k次),然后要求噪声估计网络从添加噪声的数 据样本中预测噪声,损失函数使用MSE:
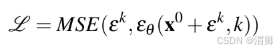

(2)DDPM的改造(针对机器人的):
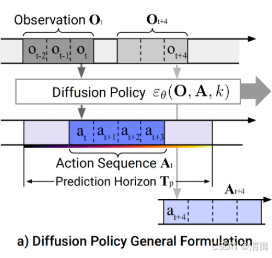
(a)闭环动作序列预测:
在时间步骤![]() ,策略将最新的
,策略将最新的![]() 个观察数据
个观察数据![]() 作为输入,并预测
作为输入,并预测![]() 个动作,其中
个动作,其中![]() 个 动作在不重新规划的情况下在机器人上执行
个 动作在不重新规划的情况下在机器人上执行
(在此定义中,![]() 表示观测范围,
表示观测范围,![]() 表示动作预测范围,而
表示动作预测范围,而![]() 则代表了动作执行范围)
则代表了动作执行范围)
(b)视觉观察条件化:
使用DDPM(扩散去除噪声过程模型)来近似条件动作分布![]() ,使得模型能够 在 不推断未来状态的情况下预测基于观察的动作。而不是建模一个条件-动作的总的分布。
,使得模型能够 在 不推断未来状态的情况下预测基于观察的动作。而不是建模一个条件-动作的总的分布。
去除噪声的公式:
![]()
噪声模型的损失函数:
![]()
(3)关键的设计:
(a)噪声估计模型的网路结构:
CNN的(当期望的动作序列随着时间快速而急剧变化时(如velocity命令动作空间),它的 表 现很差)
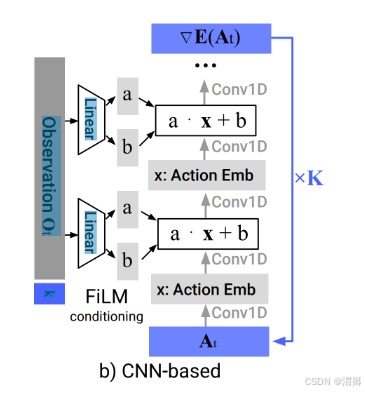
使用特征线性调制的办法,根据状态(observation)条件(迭代次数K,观察)给出缩放和 偏移的参数:a 、 b; 对动作信息的特征进行修饰,修饰后的特征经过连续的卷积神经网络, 得到当前状态和动作(带噪声)下的噪声,对当前动作(带噪声)去除噪声,生成更清晰的动 作,循环K次,生成动作。
但是这种结构的diffusion model,对需要快速反应的任务效果不好,可能是因为卷积对低频信 号更友好。
Transformer结构的
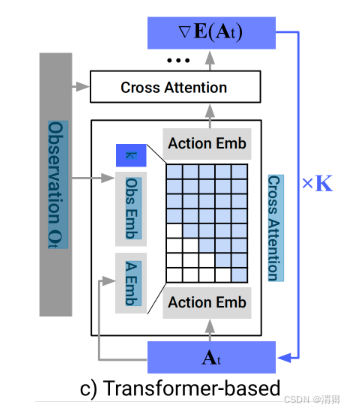
为了解决基于CNN的diffusion modle存在过度平滑,无法快速动作的缺陷。设计了基于 transformer的diffusion modle。迭代次数K、条件嵌入(embeding)、动作嵌入(embeding)作 为transformer解码器的输入特征,同时动作嵌入(embeding)也作为解码器的输入token。这样 解码器会生成当前条件下的噪声序列。
(4)视觉条件编码器:
文中使用修改的resnet18作为编码器,将图像序列编码为嵌入条件特征。修改主要是两个部 分:使用空间softmax池化代替全局池化、使用GroupNorm代替BatchNorm。
(5)噪声调节器
使用平方余弦调度,用来调节在denoise过程中:三个参数。
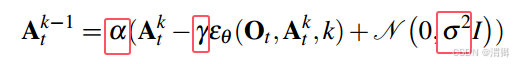
(6)快速推理
解耦了训练和推理过程中denoise的迭代次数,允许在推理时,使用较少的推理次数,保证 闭环控制的有效。
5. diffsion policy 主要解决问题:
(1)一种新的策略的表示,有效建模了多模态动作分布,相较于以往的分类分布、GMM等表达方式具有更高的精度,而且避免了不同规模之间的震荡。
分类分布对于低维的动作,有一定的效果,但是当动作的维度变大以后,动作的类别呈指数上升。模型会很大。为了解决这一问题,研究人员将动作各维度信息进行解耦,针对每一维信息进行采样,然后组合成N维的动作,这样会产生很多本来不存在的动作模态,如{(1,2)(4,5)},解耦以后{(1,4),(1,5),(2,4)(2,5)}
GMM这种多高斯混合模型的方法,将n维动作信息和“加一维”信息(如空间、时间)用多个N+1维高斯模型模拟,然后根据给定的加1维信息选择合适的高斯模型,进行采样得到N维动作。
Diffusion policy可以建模多模态动作分布的内在原因在于:随机初始化和随机采样。
(2)提供了一种训练方法:
之前的训练方法是基于能量函数的,要训练出能量函数,和归一化常数。
![]()
但是归一化常数难以估计,故才采用下面的办法,构造损失函数:
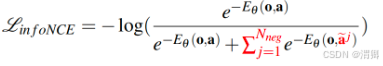
这样就只用估计能量函数,能够使得好的样本,能量小,损失小
坏的动作样本,能量大,损失大。但是需要收集大量负样本,尤其是动作维度多时,负样本会很多,很难收集,这会造成收敛难,因此diffusion的训练过程的平稳性相较于强化学习要好的多。
而diffsion policy,估计的噪声就相当于估计能量函数的梯度,不用收集负样本。
6. 实验设计:
(1)在仿真实验中,在6个任务上进行了对比实验:展示了各种方法最好的表现/最后10个checkpoint的平均表现,实验分居于视觉的,基于状态的,进行了两大组实验。
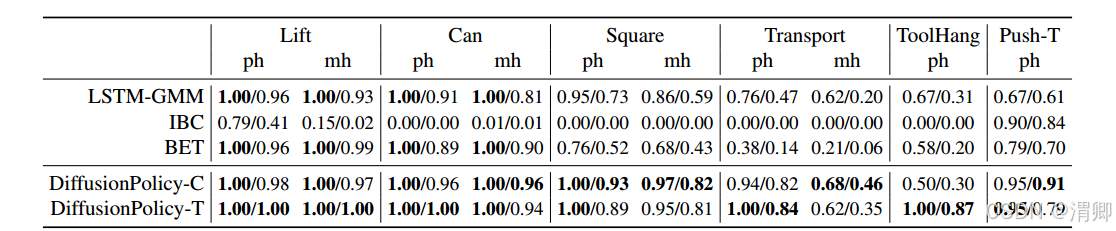

额外的两个仿真实验:
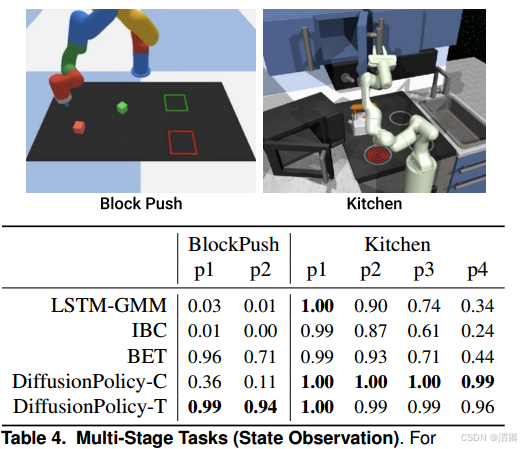
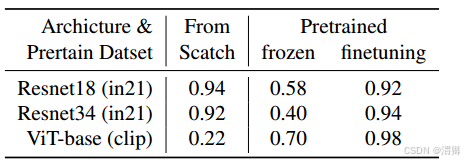
(2) 对视觉条件编码器的选择做了消融
(3)在realwork task中做了Push-T Task、Mug Flipping Task、Sauce Pouring and Spreading实验
注:会在其他文章讲解lstm-gmm、IBC 、BET的基本原理

















 116
116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









