









Pointwise(二分类):
- 把排序问题当二分类问题
- 输入样本:三元组(q,c,y)
- q:查询题目
- c:查询结果(候选答案当中的一个)
- y:判断c是否为q的正确答案(0<y<1)
- 训练阶段:对于一个q
- 结果正确:c=1
- 结果错误:c=0
- 损失函数:交叉熵
- 测试阶段:
- 二分类模型h:预测每一个候选结果
- argmax:取得最佳结果
Pairwise(度量):
- 考虑查询结果之间的关系
- 输入样本:三元组(q,c+,c-)
- q:查询题目
- c+:正确查询结果(候选答案当中的一个)
- c-:错误查询结果(候选答案当中的一个)
- 损失函数:

- max:不会取到负值
- m:边界阈值:使c+和c-之间的距离不会过大
- 损失函数换种写法:
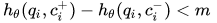
Listwise(多分类):
- pairwise和pointwise忽略了一个事实:从一系列候选中选择答案
- 输入样本: q+所有c
- q:查询题目
- C(c1,c2,c3,...,c4)
- 模型输出:
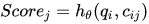
- 归一化:S:
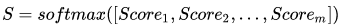
- 标签归一化:Y:
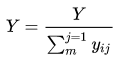
- 训练目标:最小化S和Y的KL散度
-
第二弹理解
- 如果从采样的角度理解(可能存在错误)
- point-wise: 其实不用负样本(虽然有些地方说,是从某个地方隔断然后 后面的是负样本)。
- pair-wise: 一个正样本。
- list-wise:一个负样本。


















 1741
1741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









