






 本文介绍了推荐系统系列的第六部分,重点讨论了GAN的几种变体,并详细阐述了如何将这些变体应用于协作过滤中,以提升推荐系统的性能。
本文介绍了推荐系统系列的第六部分,重点讨论了GAN的几种变体,并详细阐述了如何将这些变体应用于协作过滤中,以提升推荐系统的性能。
gan的几种变体
RECSYS系列 (RECSYS SERIES)
Update: This article is part of a series where I explore recommendation systems in academia and industry. Check out the full series: Part 1, Part 2, Part 3, Part 4, Part 5, and Part 6.
更新: 本文是我探索学术界和行业推荐系统的系列文章的一部分。 查看完整的系列文章: 第1部分 , 第2部分 , 第3 部分 , 第4 部分 , 第5 部分 和 第6部分 。
Many recommendation models have been proposed during the last few years. However, they all have their limitations in dealing with data sparsity and cold-start issues.
在最近几年中已经提出了许多推荐模型。 但是,它们在处理数据稀疏性和冷启动问题方面都有其局限性。
The data sparsity occurs when the recommendation performance drops significantly if the interactions between users and items are very sparse.
如果用户和项目之间的交互非常稀疏,则推荐性能显着下降时,就会发生数据稀疏 。
The cold-start issues occur when the model can’t recommend new users and new items.
当模型无法推荐新用户和新项目时,就会出现冷启动问题 。
To solve these problems, recent approaches have exploited side information about users or items. However, the improvement of the recommendation performance is not significant due to the limitations of such models in capturing the user preferences and item features.
为了解决这些问题,最近的方法已经利用了有关用户或物品的辅助信息。 然而,由于这种模型在捕获用户偏好和项目特征方面的局限性,因此推荐性能的提高并不明显。
Auto-encoder is a type of neural network suited for unsupervised learning tasks, including generative modeling, dimensionality reduction, and efficient coding. It has shown its superiority in learning underlying feature representation in many domains, including computer vision, speech recognition, and language modeling. Given that knowledge, new recommendation architectures have incorporated autoencoder and thus brought more opportunities in re-inventing user experiences to satisfy customers.
自动编码器是一种神经网络,适用于无监督学习任务,包括生成建模,降维和有效编码。 它已显示出在许多领域中学习基础特征表示的优势,包括计算机视觉,语音识别和语言建模。 有了这些知识,新的推荐体系结构已合并了自动编码器,从而在重新发明用户体验以满足客户方面带来了更多机会。
While traditional models deal only with a single data source (rating or text), auto-encoder based models can handle heterogeneous data sources (rating, audio, visual, video).
虽然传统模型仅处理单个数据源(评级或文本),但是基于自动编码器的模型可以处理异构数据源(评级,音频,视觉,视频)。
Auto-encoder has a better understanding of the user demands and item features, thus leading to higher recommendation accuracy than traditional models.
自动编码器对用户需求和商品功能有更好的了解 ,因此比传统型号具有更高的推荐准确性。
Furthermore, auto-encoder helps the recommendation model to be more adaptable in multi-media scenarios and more effective in handling input noises than traditional models.
此外,与传统模型相比,自动编码器可以帮助推荐模型在多媒体场景中更加适应 ,并在处理输入噪声方面更加有效。
In this post and those to follow, I will be walking through the creation and training of recommendation systems, as I am currently working on this topic for my Master Thesis.
在本博文以及后续博文中,我将逐步介绍推荐系统的创建和培训,因为我目前正在为我的硕士论文处理该主题。
Part 1 provided a high-level overview of recommendation systems, how to build them, and how they can be used to improve businesses across industries.
第1部分概述了推荐系统,如何构建它们以及如何将其用于改善整个行业的业务。
Part 2 provided a careful review of the ongoing research initiatives concerning the strengths and application scenarios of these models.
第2部分仔细审查了有关这些模型的优势和应用场景的正在进行的研究计划。
Part 3 provided a couple of research directions that might be relevant to the recommendation system scholar community.
第3部分提供了一些与推荐系统学者社区有关的研究方向。
Part 4 provided the nitty-gritty mathematical details of 7 variants of matrix factorization that you can construct: ranging from the use of clever side features to the application of Bayesian methods.
第4部分详细介绍了可以构造的7种矩阵分解的变体的数学细节:从使用巧妙的辅助功能到应用贝叶斯方法,不一而足。
Part 5 provided the architecture design of 5 variants of multi-layer perceptron based collaborative filtering models, which are discriminative models that can interpret the features in a non-linear fashion.
第5部分提供了基于多层感知器的协作过滤模型的5种变体的体系结构设计,这些模型是可以以非线性方式解释特征的判别模型。
In Part 6, I explore the use of Auto-Encoders for collaborative filtering. More specifically, I will dissect six principled papers that incorporate Auto-Encoders into their recommendation architecture. But first, let’s walk through a primer on auto-encoder and its variants.
在第6部分中,我将探讨如何使用自动编码器进行协作过滤。 更具体地说,我将剖析六篇将自动编码器纳入其推荐体系结构的原理性论文。 但是首先,让我们逐步了解一下自动编码器及其变体。
自动编码器入门及其变体 (A Primer on Auto-encoder and Its Variants)
As illustrated in the diagram below, a vanilla auto-encoder consists of an input layer, a hidden layer, and an output layer. The input data is passed into the input layer. The input layer and the hidden layer constructs an encoder. The hidden layer and the output layer constructs a decoder. The output data comes out of the output layer.
如下图所示,香草自动编码器由输入层,隐藏层和输出层组成。 输入数据被传递到输入层。 输入层和隐藏层构成一个编码器。 隐藏层和输出层构成解码器。 输出数据来自输出层。
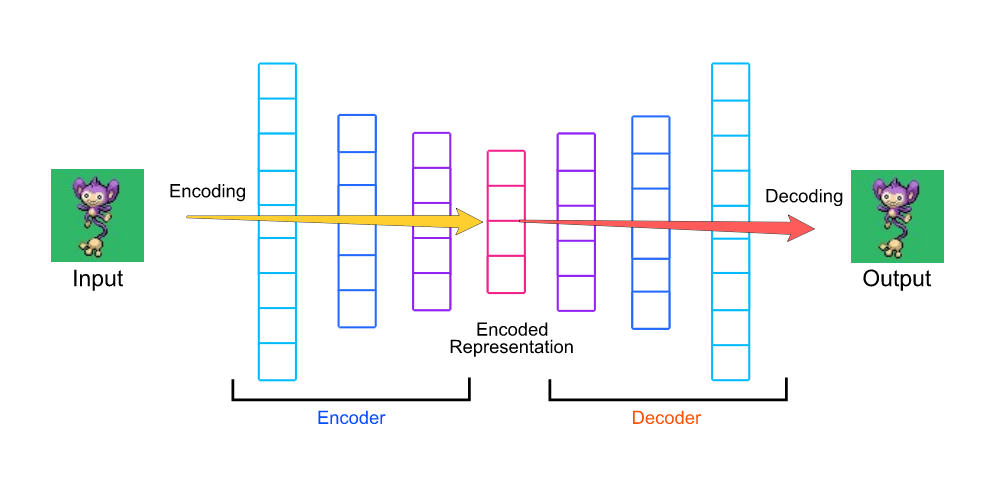
The encoder encodes the high-dimensional input data x into a lower-dimensional hidden representation h with a function f:
编码器使用函数f将高维输入数据x编码为低维隐藏表示h:
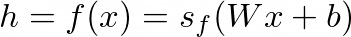
where s_f is an activation function, W is the weight matrix, and b is the bias vector.
其中s_f是激活函数,W是权重矩阵,b是偏置矢量。
The decoder decodes the hidden representation h back to a reconstruction x’ by another function g:
解码器通过另一个函数g将隐藏的表示h解码回重建x':
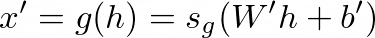
where s_g is an activation function, W’ is the weight matrix, and b’ is the bias vector.
其中s_g是激活函数,W'是权重矩阵,b'是偏差矢量。
The choices of s_f and s_g are non-linear, for example, Sigmoid, TanH, or ReLU. This allows auto-encoder to learn more useful features than other unsupervised linear approaches, say Principal Component Analysis.
s_f和s_g的选择是非线性的,例如Sigmoid,TanH或ReLU。 主成分分析说,这使自动编码器比其他无监督线性方法学习更多有用的功能。
I can train the auto-encoder to minimize the reconstruction error between x and x’ via either the squared error (for regression tasks) or the cross-entropy error (for classification tasks).
我可以通过平方误差(对于回归任务)或交叉熵误差(对于分类任务)训练自动编码器,以最小化x和x'之间的重构误差。
This is the formula for the squared error:
这是平方误差的公式:
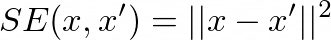
This is the formula for the cross-entropy error:
这是交叉熵误差的公式:
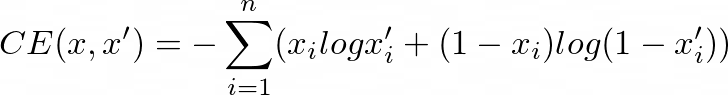
Finally, it is always a good practice to add a regularization term to the final reconstruction error of the auto-encoder:
最后,向自动编码器的最终重构错误中添加正则项始终是一个好习惯:
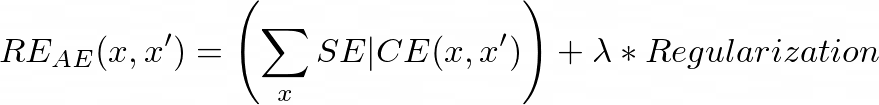
The reconstruction error function above can be optimized via either stochastic gradient descent or alternative least square.
上面的重建误差函数可以通过随机梯度下降或替代最小二乘法进行优化。
There are many variants of auto-encoders currently used in recommendation systems. The four most common are:
推荐系统中当前使用自动编码器的许多变体。 最常见的四个是:
Denoising Autoencoder (DAE) corrupts the inputs before mapping them into the hidden representation and then reconstructs the original input from its corrupted version. The idea is to force the hidden layer to acquire more robust features and to prevent the network from merely learning the identity function.
去噪自动编码器(DAE)在将输入映射到隐藏表示之前先对其进行破坏,然后从其破坏的版本中重建原始输入。 这样做的目的是迫使隐藏层获得更强大的功能,并防止网络仅学习身份功能。
Stacked Denoising Autoencoder (SDAE) stacks several denoising auto-encoder on top of each other to get higher-level representations of the inputs. The training is usually optimized with greedy algorithms, going layer by layer. The apparent disadvantages here are the high computational cost of training and the lack of scalability to high-dimensional features.
堆叠式去噪自动编码器(SDAE)彼此堆叠堆叠多个去噪自动编码器,以获得输入的更高级别表示。 训练通常使用贪心算法进行优化,并逐层进行。 这里明显的缺点是训练的计算成本高以及缺乏对高维特征的可伸缩性。
Marginalized Denoising Autoencoder (MDAE) avoids the high computational cost of SDAE by marginalizing stochastic feature corruption. Thus, it has a fast training speed, simple implementation, and scalability to high-dimensional data.
边缘化降噪自动编码器(MDAE)通过边缘化随机特征损坏来避免SDAE的高计算成本。 因此,它具有快速的训练速度,简单的实现以及对高维数据的可伸缩性。
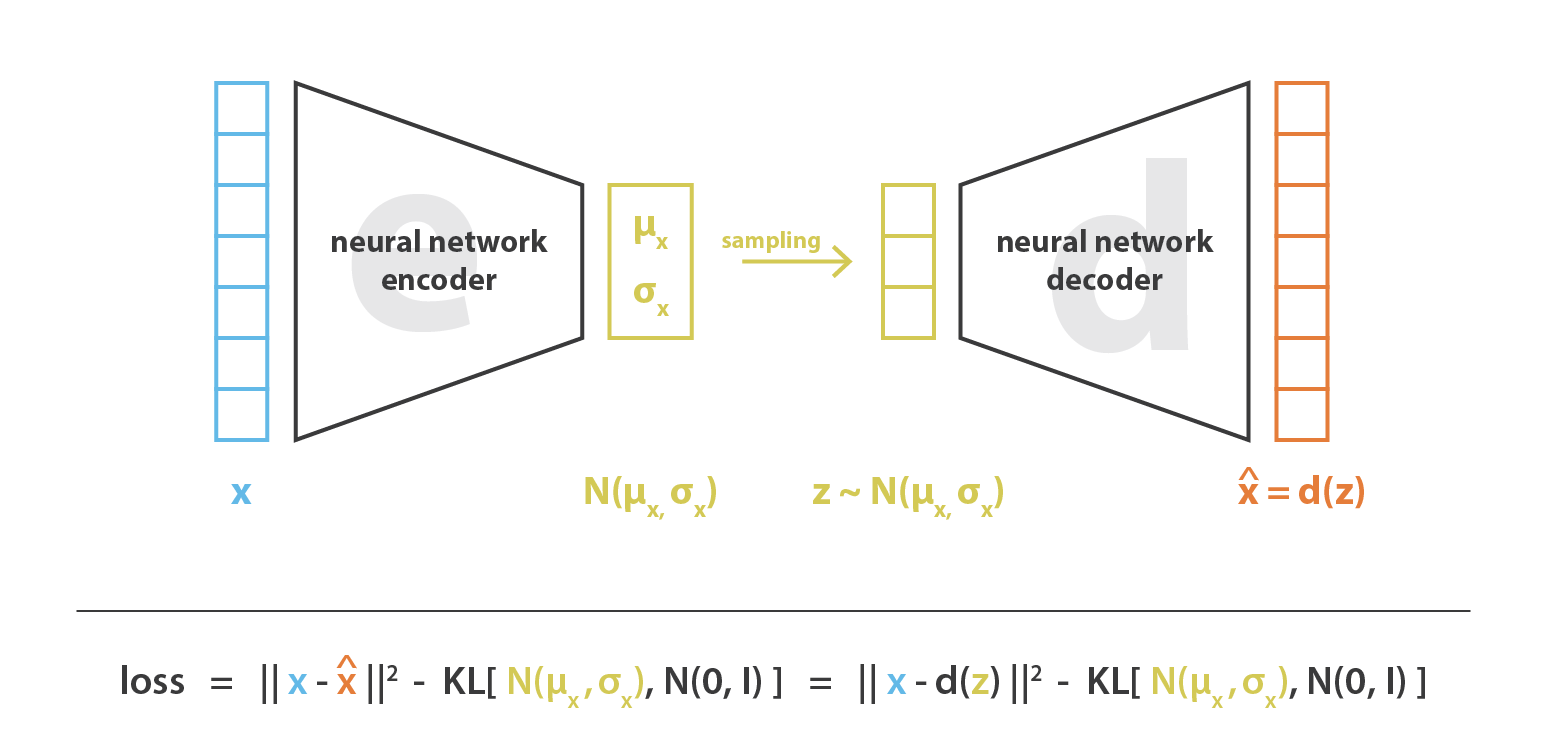
Variational Autoencoder (VAE) is an unsupervised latent variable model that learns a deep representation from high-dimensional data. The idea is to encode the input as a probability distribution rather than a point estimate as in vanilla auto-encoder. Then VAE uses a decoder to reconstruct the original input by using samples from that probability distribution.
变分自动编码器(VAE)是一种无监督的潜在变量模型,可从高维数据中学习深度表示。 想法是将输入编码为概率分布,而不是像普通自动编码器那样将点估算为编码。 然后,VAE使用解码器通过使用来自该概率分布的样本来重建原始输入。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 618
618

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









