





deel t410安装
Lipschitz函数是什么? (What are Lipschitz functions?)
Named after Rudolf Lipschitz, a function is said to be k-Lipschitz, when its first derivatives are bounded by some constant k. The minimum value for such k is called the Lipschitz constant of the function. Such a function has interesting properties, among those:
以鲁道夫·利普希茨(Rudolf Lipschitz)命名的函数被称为k-Lipschitz,当时它的一阶导数以某个常数k为界。 这种k的最小值称为函数的Lipschitz常数。 这样的功能具有有趣的特性,其中包括:
This means that if x1 and x2 are close to each others, then, their predictions f(x1) and f(x2) will be close too. As neural networks approximate functions, we will focus on 1-Lipschitz networks.
这意味着如果x1和x2彼此接近,则它们的预测f(x1)和f(x2)也将接近。 随着神经网络逼近功能,我们将重点关注1-Lipschitz网络。
为什么Lipschitz网络常数很重要 (Why does Lipschitz constant of networks matter)
These kinds of networks find many uses in modern machine learning: they have been proven to be robust to adversarial attacks [1].
这些类型的网络在现代机器学习中有许多用途:已被证明对对抗攻击具有鲁棒性[1]。
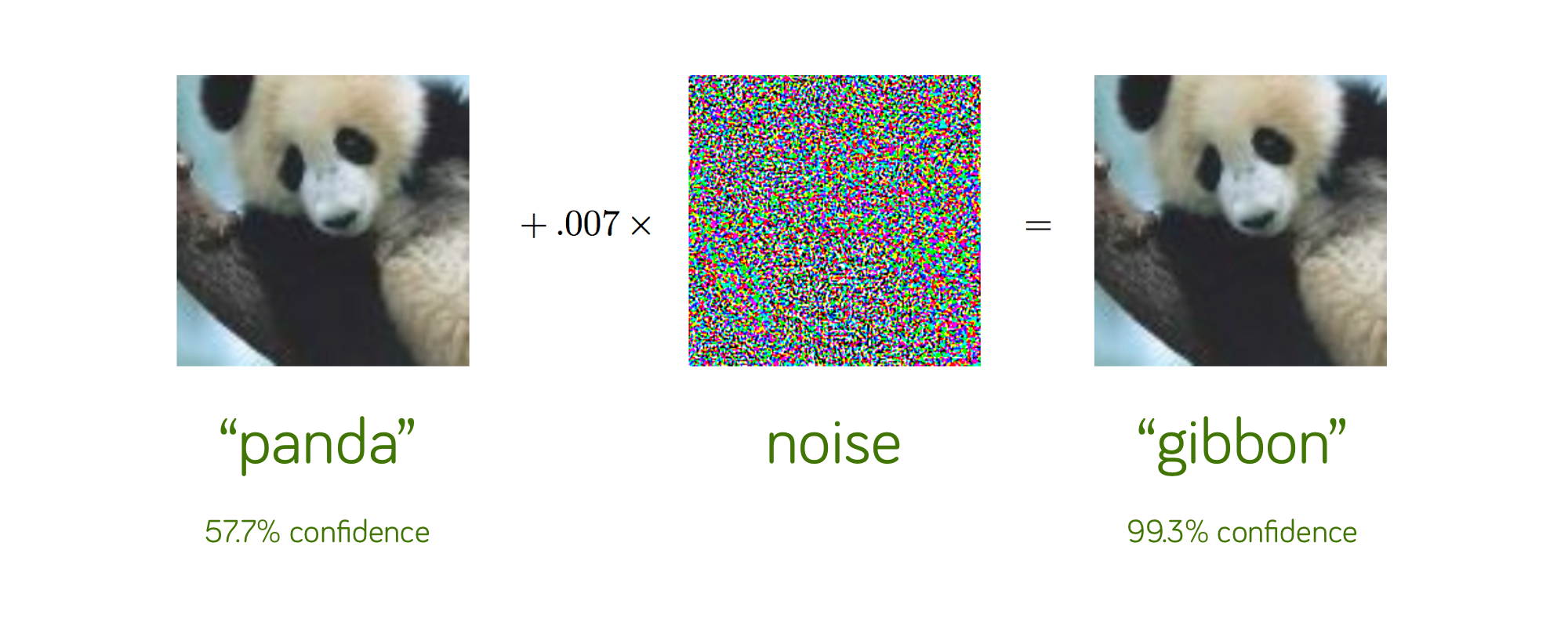
An adversarial attack is the act of finding an x2 (the “gibbon” image) close to our original x1 (the “panda” image), such that their predictions f(x1) and f(x2) differs. The main problem is that the added noise to build such adversarial example is very small. Controlling the Lipschitz constant of a network has a great impact on adversarial robustness: the lower the Lipschitz constant is, the more noise is needed in order to build an adversarial example. Feel free to see this gentle introduction to adversarial robustness to learn more about this topic.
对抗攻击是找到与原始x1 (“熊猫”图像)接近的x2 (“长臂猿”图像)的行为,以使它们的预测f(x1)和f(x2)不同。 主要的问题是,建立这种对抗性例子所产生的噪音很小。 控制网络的Lipschitz常数对对抗性的鲁棒性有很大影响:Lipschitz常数越低,则需要更多的噪声来构建对抗性示例。 您可以随意查看有关对抗性鲁棒性的温和介绍,以了解有关此主题的更多信息。
But this is not the only use of Lipschitz networks: these are also used in Wasserstein distance estimation. The Wasserstein metric allows to measure the distance between two distributions. Computing this metric requires optimizing 1-Lipschitz networks. This is notably used in Wasserstein-GAN [2].
但这不是Lipschitz网络的唯一用途:Wasserstein距离估计中也使用了这些网络。 Wasserstein度量允许测量两个分布之间的距离。 计算此指标需要优化1-Lipschitz网络。 Wasserstein-GAN [2]中特别使用了这种方法。
不同级别的Lipschitz约束 (Different levels of Lipschitz constraints)
The previous equation tells us that the gradient of our function is at most equal to 1. But enforcing this constraint doesn’t necessarily mean that the gradient will effectively reach 1 at some point.
前面的等式告诉我们,函数的梯度最多等于1。但是强制执行此约束并不一定意味着该梯度将在某个点有效达到1。
Depending on the use case, we might require different levels of Lipschitz constraints:
根据使用情况,我们可能需要不同级别的Lipschitz约束:
- “soft” 1-Lipschitz constraint: we force the gradient function to be close to one and equal to one on average. In this case, the gradient can be greater than one at some specific points of the input domain. Using such constraints during training does not guarantee that the final networks will be 1-Lipschitz but allow to regularizing training. “软” 1-Lipschitz约束:我们迫使梯度函数接近于1且平均等于1。 在这种情况下,梯度可以在输入域的某些特定点处大于一。 在训练期间使用此类约束条件并不能保证最终的网络将是1-Lipschitz,但可以使训练正规化。
- “hard” 1-Lipschitz constraint: forcing the gradient to be lower or equal to one at every point of the input domain. The gradient can be lower than one at some points. This is used when dealing with adversarial robustness. “硬” 1-Lipschitz约束:在输入域的每个点上强制梯度小于或等于1。 在某些情况下,梯度可能会小于1。 在处理对抗性鲁棒性时使用。
- “Gradient equal to one almost everywhere”: forcing the gradient to be equal to 1 almost everywhere. This particular class of networks is not suitable for traditional ML. However it is necessary when working with Wasserstein distance estimation [3]. “几乎在任何地方都等于1的梯度”:迫使几乎在所有地方都等于1的梯度。 此类特定网络不适用于传统ML。 但是,在使用Wasserstein距离估计[3]时是必要的。
We will focus on the last two levels of constraints.
我们将重点关注约束的最后两个级别。
我们如何将这些约束应用于神经网络 (How do we apply these constraints on Neural Networks)
Computing the Lipschitz constant of a neural network is known to be an NP-hard problem. However, several methods have been proposed to enforce such “hard” constraints during training. Most of these methods rely on constraining the Lipschitz constant of each layer, and the following composition property can then be used:
计算神经网络的Lipschitz常数已知是一个NP难题。 但是,已经提出了几种在训练过程中强制执行此类“硬”约束的方法。 这些方法大多数都依赖于约束每一层的Lipschitz常数,然后可以使用以下组成属性:

For linear layers, such as Dense layers, there are numerous ways of achieving this property, like weight clipping or normalization.
对于线性层(例如密集层),有很多方法可以实现此属性,例如权重裁剪或归一化。
We will now explore existing methods to this for Dense layers. Recall the definition of a Dense layer as a linear operator composed with a non linear activation function:
现在,我们将探索用于密集层的现有方法。 回顾将密集层定义为由非线性激活函数组成的线性算子:
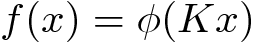
We will first focus on the linear kernel K. We will later see how to include activations functions and how to extend these methods to other types of layers.
我们将首先关注线性核K。稍后,我们将看到如何包括激活函数以及如何将这些方法扩展到其他类型的层。
减肥 (Weight clipping)
This is the naive method to enforce the Lipschitz constraint at the level of each linear layer. For instance, a dense layer with m inputs and n outputs, is 1-Lipschitz if all the weights are clipped within the following interval:
这是在每个线性层级别上强制执行Lipschitz约束的幼稚方法。 例如,如果所有权重都在以下时间间隔内裁剪,则具有m个输入和n个输出的密集层为1-Lipschitz:
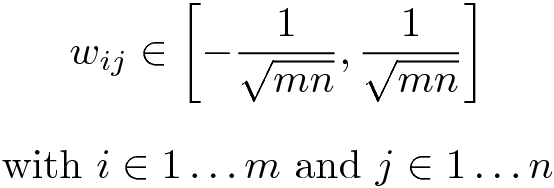
This is enough to guarantee that the Lipschitz constant of the layer is lower than 1. However, in practice, the gradient for training data points is usually much lower than 1. This is because the only way to have a gradient equal to 1 at some point is to set all weights to their clipping values, which is very restrictive. In other terms, this means that networks trained under such constraints have a Lipschitz constant smaller than 1, but many 1-Lipschitz networks do not satisfy this constraint.
这足以确保该层的Lipschitz常数小于1。但是,实际上,用于训练数据点的梯度通常远小于1。这是因为在某些情况下使梯度等于1的唯一方法重点是将所有权重设置为其裁剪值,这是非常严格的。 换句话说,这意味着在这样的约束条件下训练的网络的Lipschitz常数小于1,但是许多1-Lipschitz网络都不满足此约束条件。
Can we then find a constraint without such drawbacks?
然后我们可以找到没有这种缺点的约束吗?
频谱归一化 (Spectral Normalization)
This method tackles the limitations of weight clipping by using spectral normalization. Mathematically this type of normalization relies on the singular value decomposition:
该方法通过使用频谱归一化解决了权重裁剪的局限性。 在数学上,这种归一化依赖于奇异值分解:
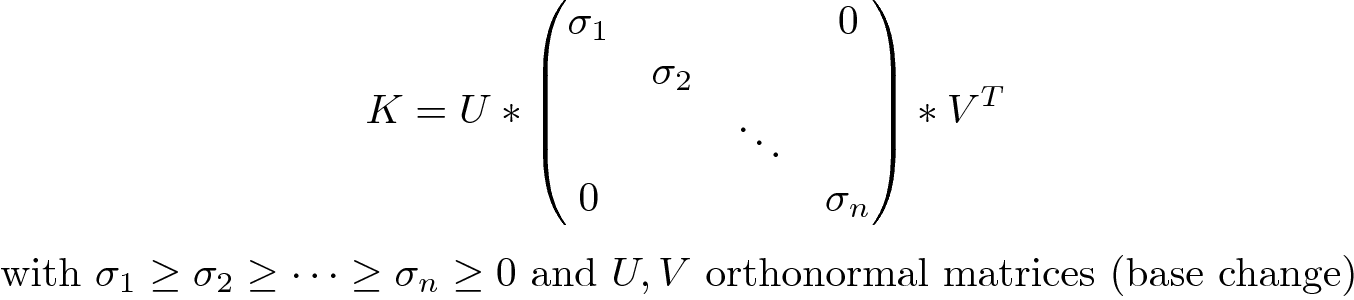
Since the center matrix is diagonal, and as U and V don’t affect the gradient of K, We can then say that the gradient of K is bounded by:
由于中心矩阵是对角线,并且由于U和V不会影响K的梯度,因此我们可以说K的梯度受以下约束:
If we divide all weights by the greatest sigma value, the gradient is then bounded by one:
如果将所有权重除以最大的sigma值,则梯度将以1为界:
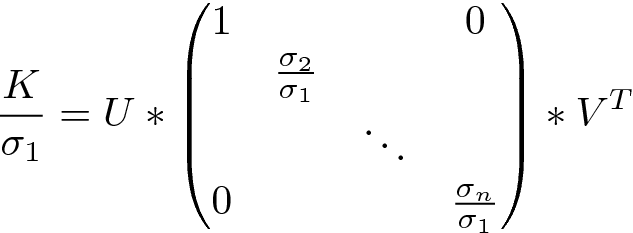
Such normalization provides very strong guarantees:
这样的规范化提供了非常有力的保证:
- The gradient cannot be greater than 1. 梯度不能大于1。
- There exists a set of points in the input domain such that the gradient will be equal to 1. 输入域中存在一组点,使得梯度等于1。
Moreover the highest singular value can be computed quickly by using the power iteration method [4].
此外,通过使用幂迭代方法[4]可以快速计算出最高奇异值。
It also provides a formal way to express the “gradient equals to 1 almost everywhere” constraint:
它还提供了一种正式的方式来表达“几乎在任何地方都等于1的梯度”约束:
This constraint can also be obtained in practice by using the Björck orthonormalization algorithm [5]
实际上,也可以使用Björck正交归一化算法[5]获得此约束。
那么激活功能呢? (What about activation functions ?)
To obtain a 1-Lipschitz neural network, activation functions used must also be 1-Lipschitz. Most of these are already 1-Lipschitz: ReLU ELU, sigmoid, tanh, logSigmoid… Some need to be properly parameterized, such as leakyRelu, PReLU… finally some are not 1-Lipschitz at all.
为了获得1-Lipschitz神经网络,使用的激活函数也必须是1-Lipschitz。 其中大多数已经是1-Lipschitz了:ReLU ELU,Sigmoid,tanh,logSigmoid…有些参数需要正确地设置,例如LeakyRelu,PReLU…最后,有些根本不是1-Lipschitz。
那其他层呢? (What about other layers?)
Applying the composition property on layers requires that each layer respect the 1-Lipschitz constraint. We showed examples of normalization for dense layers, but is this applicable to any layer type ?
在图层上应用合成属性要求每个图层都遵守1-Lipschitz约束。 我们展示了对稠密层进行标准化的示例,但这是否适用于任何层类型?
Convolution layers: one might think that normalizing the kernel of a convolution layer (by clipping or spectral normalization) is enough but there is a catch: convolution layers use padding, stride, dilation... All these operations have an effect on the norm of the output, thus changing the layer’s Lipschitz constant. In order to catch this phenomenon, a corrective factor can be computed accounting these parameters [6].
卷积层:人们可能会认为(通过裁剪或频谱归一化)对卷积层的内核进行归一化就足够了,但是有一个陷阱:卷积层使用填充,跨距,膨胀...所有这些操作都会影响卷积的范数输出,从而更改图层的Lipschitz常数。 为了赶上这种现象,可以考虑这些参数计算出校正因子[6]。
Pooling layers: these layers can be seen as a special case of convolutions, so we can also apply a corrective factor.
合并层:这些层可以看作是卷积的特殊情况,因此我们也可以应用校正因子。
Batch Norm: As it performs rescaling, this layer is not constrained. Besides, learning under 1-lipschitz constraint mitigate the need of such layers. Using it would only be useful to correct the bias induced after each layer which can also be done by setting the use_bias parameter of each layer.
批处理规范:在执行重新缩放时,此层不受限制。 此外,在1-lipschitz约束下学习可减轻对此类层的需求。 使用它仅对校正在每一层之后引起的偏差有用,这也可以通过设置每一层的use_bias参数来完成。
Dropout: It allows a kind of regularization, switching to zero part of layer outputs. However, at inference a scaling factor is applied to compensate the dropout factor, which breaks the Lipschitz property.
辍学:它允许一种正则化,切换到层输出的零部分。 但是,推断会应用缩放因子来补偿丢失因子,这会破坏Lipschitz属性。
使用DEEL-LIP简化了k-Lipschitz神经网络 (k-Lipschitz neural nets made easy with DEEL-LIP)
DEEL-LIP is a library built upon Tensorflow that extends the usual Keras elements such as layers, initializers or activations, allowing the user to build easily 1-Lipschitz networks. Provided layers use spectral normalizaion, and/or Björck orthonormalization. When required, the adequate corrective factor is computed and applied.
DEEL-LIP是基于Tensorflow构建的库,该库扩展了常见的Keras元素(例如层,初始化程序或激活),从而使用户可以轻松构建1-Lipschitz网络。 提供的层使用频谱归一化和/或Björck正交归一化。 需要时,将计算并应用足够的校正因子。
如何使用它? (How to use it?)
Firstly the library can be installed with pip
首先,可以使用pip安装库
Now the following code demonstrates how to build and compile a neural networks with DEEL-LIP. It is quite similar to standard Keras code.
现在,以下代码演示了如何使用DEEL-LIP构建和编译神经网络。 它与标准Keras代码非常相似。
DEEL-LIP has been developed to be simple to use for Keras users:
开发的DEEL-LIP易于Keras用户使用:
- DEEL-LIP follows the same package structure as Tensorflow/Keras. DEEL-LIP遵循与Tensorflow / Keras相同的封装结构。
- All elements (layers, activations, initializers…) are compatible with standard Keras elements. 所有元素(层,激活,初始化器...)都与标准Keras元素兼容。
- When a layer overrides a standard Keras element, it implements the same interface, with the same parameters. The only difference lies in the parameter that controls the Lipschitz constant of the layer. 当图层覆盖标准Keras元素时,它将使用相同的参数实现相同的接口。 唯一的区别在于控制图层的Lipschitz常数的参数。
处理Lipschitz图层时重要的是什么? (What’s important when dealing with Lipschitz layers?)
As the Lipschitz constant of the network is the product of the constants of each layer, so every single layer must respect the Lipschitz constraint. Adding a single layer that does not satisfy the Lipschitz constraint is enough to break the Lipschitz constraint of the whole network.
由于网络的Lipschitz常数是每一层常数的乘积,因此每个单层都必须遵守Lipschitz约束。 添加不满足Lipschitz约束的单层足以打破整个网络的Lipschitz约束。
In order to make things more convenient, any layer imported from DEEL-LIP is safe to use: if you can import it, you can use it. This is also true for the parameters of layers: wrong settings (i.e. breaking the Lipschitz constraint) on a layer will raise an error.
为了使事情更方便,从DEEL-LIP导入的任何层都可以安全使用:如果可以导入,则可以使用它。 对于图层的参数也是如此:错误的设置(即破坏Lipschitz约束)将引发错误。
A complete list of available layers can be found in the documentation.
可用层的完整列表可以在文档中找到。
反向传播/推理期间的开销是多少? (What is the overhead during backpropagation/inference?)
During backpropagation, the normalization of the weights adds an overhead at each iteration. However, the spectral normalization algorithm is added directly into the graph during backpropagation. This is called differentiable constraint, which yields much more efficient optimization steps.
在反向传播期间,权重的归一化在每次迭代时都会增加开销。 但是,在反向传播期间,将光谱归一化算法直接添加到图形中。 这称为可微分约束,可产生更有效的优化步骤。
During inference, no overhead is added at all: the normalization is mandatory only during backpropagation. DEEL-LIP provides an export feature that can be used to create a standard Keras model from a deep-lip one. Each Dense or Conv2D layers is then converted to a standard Keras layer. By exporting models, it is possible to use networks trained using DEEL-LIP for inference without even requiring the installation of DEEL-LIP.
在推论过程中 ,根本不增加任何开销:仅在反向传播期间才必须进行规范化。 DEEL-LIP提供了一种导出功能,可用于从深层模型创建标准Keras模型。 然后将每个Dense或Conv2D图层转换为标准Keras图层。 通过导出模型,可以使用经过DEEL-LIP训练的网络进行推理,甚至不需要安装DEEL-LIP。
结论 (Conclusions)
Lipschitz constrained networks are neural networks with bounded derivatives. They have many applications ranging from adversarial robustness to Wasserstein distance estimation. There are various ways to enforce such constraints. The spectral normalization and the Björck orthonormalization are among the most efficient methods, the DEEL-LIP library provide an easy way to train and use these constrained layers.
Lipschitz约束网络是带有有界导数的神经网络。 它们具有从对抗性鲁棒性到Wasserstein距离估计的许多应用。 有多种方法可以强制执行此类约束。 频谱归一化和Björck正交归一化是最有效的方法,DEEL-LIP库提供了一种简单的方法来训练和使用这些受约束的层。
谢谢阅读! (Thanks for reading!)
翻译自: https://towardsdatascience.com/building-lipschitz-networks-with-deel-lip-68452d7bc2bc
deel t410安装














 310
310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









