









写在前面的话
真是觉得数学决定了人工智能的上限,不得不佩服数学专业的大佬,WGAN还是比较经典的GAN网络,其结果也蛮好的(跑的MNIST数据集),但是损失看了代码也没看懂咋算的,所以还是得从数学原理上详细推导一下,然而很多博客一知半解,有幸看到介绍很完善的推导,尝试记录一些学习理解到的内容,能力有限,如有理解错误还请指出,不胜感激。
1. 范数
L-P范数,p可以为任意自然数
L p = ∣ ∣ x ∣ ∣ p = ∑ i = 1 n x i p p , x = ( x 1 , x 2 , … , x n ) L_p = ||x||_p = \sqrt[p]{\sum_{i=1}^{n}x_i^p} \,, \quad \quad x = (x_1, x_2, \ldots, x_n) Lp=∣∣x∣∣p=pi=1∑nxip,x=(x1,x2,…,xn)
简单来说,0范数就是非0元素的个数,1范数就是各个元素绝对值之和……
2. 泛化
在深度学习中,总是提到网络的泛化能力,其实就是指模型对输入扰动是不敏感的。如图像二分类来说,只改变一个像素值就分成不同的类别,这就说明模型过拟合,对输入过于敏感。
稳定性包含两种含义:
- 参数扰动的稳定性
f w + Δ w ( x ) ≈ f w ( x ) f_{w+\Delta w}(x) \approx f_{w}(x) fw+Δw(x)≈fw(x) - 输入扰动的稳定性
f w ( x + Δ x ) ≈ f w ( x ) f_w(x+\Delta x) \approx f_{w}(x) fw(x+Δx)≈fw(x)
对于神经网络模型,都是希望对输入的变动不敏感,即希望 ∣ ∣ x 1 − x 2 ∣ ∣ ||x_1 - x_2|| ∣∣x1−x2∣∣ 很小时, ∣ ∣ f w ( x 1 ) − f w ( x 2 ) ∣ ∣ ||f_w(x_1) - f_w(x_2)|| ∣∣fw(x1)−fw(x2)∣∣ 也尽可能地小
2.1. Lipschitz约束与L约束
我理解的两者其实表示同一种约束或是包含关系,之所以分开表述是因为还是有细微的差别
- Lipschitz 约束,式中左侧采用的是函数值差异,也可以是各阶梯度值的差异,右侧的 L L L 是常数
∣ ∣ f w ( x 1 ) − f w ( x 2 ) ∣ ∣ ≤ L ⋅ ∣ x 1 − x 2 ∣ ∣ ||f_w(x_1) - f_w(x_2)|| \leq L · |x_1 - x_2|| ∣∣fw(x1)−fw(x2)∣∣≤L⋅∣x1−x2∣∣
如下图是用在函数值上的约束,是为了不让函数值变化的太快,将函数约束在粉色区域内
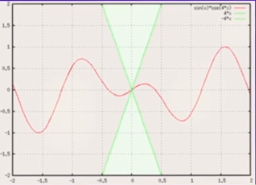
如果梯度是L-Lipschitz的,拿二次来说,就有了一个二次函数的上界
f
(
x
)
≤
f
(
x
0
)
+
<
∇
f
(
x
0
)
,
x
−
x
0
>
+
L
2
∣
∣
x
−
x
0
∣
∣
2
,
∀
x
f(x)\leq f(x_0) + <\nabla f(x_0), \ x - x_0> + \frac{L}{2} ||x - x_0||^2, \quad \forall x
f(x)≤f(x0)+<∇f(x0), x−x0>+2L∣∣x−x0∣∣2,∀x
如果函数是严格凸函数,那么就有了一个二次函数的下界
<
∇
f
(
x
0
)
,
x
−
x
0
>
+
μ
2
∣
∣
x
−
x
0
∣
∣
2
≤
f
(
x
)
,
∀
x
<\nabla f(x_0), \ x - x_0> + \frac{\mu}{2} ||x - x_0||^2 \leq f(x), \quad \forall x
<∇f(x0), x−x0>+2μ∣∣x−x0∣∣2≤f(x),∀x
这样就可以将目标函数约束到一个二次函数的范围内,同理,这个二次函数可以推广到更高次的函数
- L 约束
∣ ∣ f w ( x 1 ) − f w ( x 2 ) ∣ ∣ ≤ C ( w ) ⋅ ∣ x 1 − x 2 ∣ ∣ ||f_w(x_1) - f_w(x_2)|| \leq C(w) · |x_1 - x_2|| ∣∣fw(x1)−fw(x2)∣∣≤C(w)⋅∣x1−x2∣∣
C ( w ) C(w) C(w) 只与参数有关,与输入无关,希望 C ( w ) C(w) C(w) 越小越好,越小意味着它对输入扰动越不敏感,泛化性越好
考虑单层的全连接
f
(
W
x
+
b
)
f(Wx+b)
f(Wx+b),让
x
1
,
x
2
x1,x2
x1,x2 充分接近,那么就可以将左边用一阶项近似得到(假设两式相减后b消掉了)
∂
f
∂
x
W
(
x
1
−
x
2
)
≤
C
(
w
,
b
)
⋅
∣
∣
x
1
−
x
2
∣
∣
\frac{\partial f}{\partial x} W(x_1 - x_2) \leq C(w, b)\ · \ ||x_1 - x_2||
∂x∂fW(x1−x2)≤C(w,b) ⋅ ∣∣x1−x2∣∣
∂
f
∂
x
\frac {∂f} {∂x}
∂x∂f 这一项(每个元素)的绝对值必须不超过某个常数,这就要求我们要使用“导数有上下界”的激活函数,不过我们目前常用的激活函数,比如sigmoid、tanh、relu等,都满足这个条件。神经网络均可以看作是全连接的结果,因此问题可以转换为
∣
∣
W
(
x
1
−
x
2
)
∣
∣
≤
C
∣
∣
x
1
−
x
2
∣
∣
(
1
)
||W(x_1 - x_2)|| \leq C||x_1 - x_2|| \quad \quad \quad \quad (1)
∣∣W(x1−x2)∣∣≤C∣∣x1−x2∣∣(1)
为使上式恒成立,那么要尽可能使 C C C 小,从而给参数带来一个正则化项 C 2 C^2 C2
这时候需要引入一个新的范数,Frobenius范数,简称F范数
∣
∣
W
∣
∣
F
=
∑
i
,
j
w
i
j
2
||W||_F = \sqrt[]{\sum_{i,j}w_{ij}^{2}}
∣∣W∣∣F=i,j∑wij2
由柯西不等式可证明(不是数学专业,早忘柯西了)
∣
∣
W
x
∣
∣
≤
∣
∣
W
∣
∣
F
⋅
∣
∣
x
∣
∣
||Wx|| \leq ||W||_F \ · \ ||x||
∣∣Wx∣∣≤∣∣W∣∣F ⋅ ∣∣x∣∣
因此,如果不大关心精准度,直接可以取 C = ∥ W ∥ F C=∥W∥_F C=∥W∥F
2.2 正则项
在原博客中 ∥ W ∥ 2 ∥W∥_2 ∥W∥2 是式(1)中最准确的 C C C(所有满足式(1)的 C C C 中最小的那个),我不理解,但是我又证不出来
为了使神经网络尽可能好地满足L约束,我们应当希望 $ C=∥W∥_2$ 尽可能小,我们可以把C2作为一个正则项加入到损失函数中。还没有算出谱范数
∥
W
∥
2
∥W∥_2
∥W∥2 ,但算出了一个更大的上界
∥
W
∥
F
∥W∥_F
∥W∥F ,所以我们可以得到新的loss
l
o
s
s
=
l
o
s
s
(
y
,
f
w
(
x
)
)
+
λ
∥
W
∥
F
2
loss = loss(y,f_w(x)) + λ∥W∥^2_F
loss=loss(y,fw(x))+λ∥W∥F2
带入表达式可以得到实际上就是 l2正则化,表明L2正则化能使得模型更好地满足L约束,从而降低模型对输入扰动的敏感性,增强模型的泛化性能。
3. 思考
才看了关于WGAN优化的详细推导,其中涉及到 1-Lipschitz 连续问题,这也是之前一直疑惑的地方,因此对于其详细原理又进行了学习。关于Lipschitz连续的问题,前提是明白Lipschitz条件是用来做什么,我用一句话概括就是通过该条件为最优化问题提供一个上界的约束,从而使函数优化更高效且更稳定,当满足Lipschitz连续后则使整个网络得到稳定的训练,因此GAN网络中更加需要这样的条件吧。
在之前的博客中提到的SAGAN中提到了谱归一化,当时仅明白其计算,但是详细实现我还未看源码,我也需要跑一下其代码好好理解一下用法和思想。
4. 参考链接
[1] 苏剑林. (2018, Oct 07). 《深度学习中的Lipschitz约束:泛化与生成模型 》[Blog post].
[2] 非凸优化基石:Lipschitz Condition
[3] 论文就不放了















 9223
9223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









