





It’s been a while since I wrote my first post on What is Machine Learning (ML) and How Programming paradigms have changed over time and describing some use cases/applications. This time, I am sharing how Machine Learning and AI can be seen from different perspectives, specifically covering the following two areas:
自从我写了第一篇关于什么是机器学习(ML)和编程范例如何随着时间变化并描述一些用例/应用程序以来 , 已经有一段时间了 。 这次,我将分享如何从不同的角度看待机器学习和AI,特别是涵盖以下两个领域:
1. How much human interaction is involved in the training process of different ML algorithms.
1.不同的机器学习算法的训练过程涉及多少人机交互。
2. How the training is performed.
2.如何进行培训。
Before moving into each of these areas, let’s clarify a few concepts around the Machine Learning Process. If you are familiar with how Machine Learning works, you can skip this section.
在进入每个领域之前,让我们澄清一下有关机器学习过程的一些概念。 如果您熟悉机器学习的工作原理,则可以跳过本节。
A high-level definition of Machine Learning can be seen as:
机器学习的高级定义可以看作是:
Given some data representative of an area (sales, politics, education) you are analysing and an algorithm, the ability of a computer can learn from this data and detect certain patterns on it. Followed by being able to tell (predict) you and determine the type of new data or at least an approximation of it.
给定您正在分析的代表某个地区(销售,政治,教育)的一些数据以及一种算法 ,计算机的能力可以从该数据中学习并检测其上的某些模式 。 然后能够告诉( 预测 )您并确定新数据的类型或至少近似值。
Take this concept with a pinch of salt, as there is too much involved in the background about how ML is actually performed.
稍微加一点盐就可以理解这个概念,因为在背景中实际执行ML的方式太多了。
In other words, the computer is able to detect patterns by training (learning) from the input data. This process is highly iterative and needs lots of tuning. For example, It needs to check how far or close the prediction is from the real value, then correct itself by adjusting its parameters until reaching a point where the model is certainly accurate enough to be used.
换句话说,计算机能够通过从输入数据中进行训练 (学习)来检测图案 。 此过程是高度迭代的,需要大量调整。 例如,它需要检查预测与实际值之间的距离或接近程度,然后通过调整其参数进行校正,直到达到可以肯定使用模型的准确点为止。
Ok, now that we have an overview of the process. Let’s jump into types of Machine Learning.
好的,现在我们对该过程进行了概述。 让我们跳入机器学习的类型。
机器学习算法和人工干预。 (ML Algorithms and Human intervention.)
Machine Learning systems in this area could be seen as the amount of ”Supervision” a.k.a Human Interaction those will have over the training process. These are divided into 3 main categories, I will try to illustrate the following definitions with examples.
这方面的机器学习系统可以看作是在培训过程中将要进行的“监督”或“人机交互” 。 这些分为3个主要类别,我将尝试通过示例来说明以下定义。
1.监督学习 (1. Supervised Learning)
Imagine you are the owner of a local bookshop.
假设您是一家本地书店的所有者。

Your daughter Ana is a Data Scientist and she has offered to take books dataset recorded in your inventory system and implement a new system to speed up registration of new books arriving for sale.
您的女儿Ana是一名数据科学家,她已经提出要获取您库存系统中记录的图书数据集,并实施一个新系统来加快即将到来的新书的注册。
Ana knows some characteristics of the books:
安娜知道这些书的一些特征:
- Genre ( Fiction, Non-Fiction, Fantasy, Thriller ) 类型(小说,非小说,幻想,惊悚片)
- Hardcover, if a book is available on Hardcover 精装书(如果有精装书)
- ISBN, the commercial id for the book ISBN,这本书的商业编号
- Title, Number of Pages 标题,页数
- Extract of the book or Cover picture 书摘或封面图片
- Author 作者
Now, Imagine having to allocate one book in a bookshelf. This is easy if you look up the metadata online and place the book on the Fiction shelf.
现在,想象一下必须在书架中分配一本书。 如果您在线查找元数据并将书籍放在小说架子上,这很容易。
However, in reality, if you receive up to 200 books per day, you cannot do this job on your own, manually entering data on the system is prone to errors and you might end up putting books on the wrong shelf. This misplacement might end up in lower revenue as when a new customer comes incomes in and leaves unsatisfied because they cannot find the book even though it was actually on the store.
但是,实际上,如果每天接收多达200本书,则您将无法独自完成此工作,在系统上手动输入数据容易出错,并且最终可能会将书籍放在错误的书架上。 当新客户进帐而又不满意时,这种错位可能最终导致收入降低,因为即使实际上是在商店中,他们也找不到书。
Ana’s new system is as easy as feeding the system with an extract or the cover of the book you are looking for and can tell you which shelf this should be placed on.
Ana的新系统就像向系统中提供您要查找的摘录或书的封面一样容易,并且可以告诉您应该将该书放在哪个书架上。
This particular example is called Classification because the system is just helping you to classify (organise) some data based on certain characteristics that you as user presented to it.
这个特定的示例称为“ 分类”,因为系统只是在帮助您根据用户呈现给您的某些特征对某些数据进行分类(组织)。
A real example of this kind of system is Google Photos.
这种系统的一个真实示例是Google相册。
Yet another type of Supervised algorithm is about predicting a numeric value, given a set of features or characteristics called predictors.
监督算法的另一种类型是关于给定一组称为预测变量的特征或特性的预测数值。
Now, you might actually ask how this happens?
现在,您实际上可能会问这是怎么发生的?
An example of this is using Regression. A common and widely used algorithm known as Linear Regression and the purpose is to predict a continuous value as a result.
一个例子就是使用Regression 。 一种通用且广泛使用的算法,称为线性回归,其目的是预测结果的连续值。
This actually translates to having a set of features or variables, and a set of labels that match this input features and all you want the algorithm to do is to learn how to “fit” the weights (parameters) associated with these features to give the approximate value that is closer to the real value.
实际上,这意味着具有一组功能或变量,并且一组与该输入功能匹配的标签,而您希望算法执行的所有操作就是学习如何“ 拟合 ”与这些功能关联的权重( 参数 ),从而得出接近实际值的近似值。
2.无监督学习。 (2. Unsupervised Learning.)
Unsupervised algorithms cover all cases when we do not have a label or real value to compare against. Instead, we do have sets of data, and the model will be trained and predicted based on how the data is grouped together, how it detects patterns, and if it shows certain behaviours.
无监督 当我们没有可比较的标签或实际值时,算法会涵盖所有情况。 相反,我们确实有数据集,并且模型将基于数据如何组合在一起,如何检测模式以及是否显示某些行为来进行训练和预测。
A typical example of this type of Machine Learning is Clustering, where you group your data based on similarity. Real examples include Recommender Systems such as:
此类机器学习的典型示例是集群 ,您可以在其中基于相似性对数据进行分组。 真实的例子包括推荐系统,例如:
- Retailer websites, like Amazon and Zalando. 零售商网站,例如Amazon和Zalando。
- Media / Streaming systems, like Netflix, Youtube among others. 媒体/流媒体系统,例如Netflix,Youtube等。
There are lots of other algorithms that are used within this type, for example, Anomaly detection which might cover credit card fraud or account takeover situations that can be prevented and predicted with the use of ML.
此类型中还使用了许多其他算法,例如,异常检测可能涵盖可以通过使用ML预防和预测的信用卡欺诈或帐户接管情况。
Yet another of my favourite types of unsupervised learning algorithms that I’ve discovered recently are those used for data visualization, like t-SNE or t-Distributed Stochastic Neighbor Embedding.
我最近发现的我最喜欢的另一类无监督学习算法是用于数据可视化的算法,例如t-SNE或t-Distributed随机邻居嵌入。
I have used t-SNE in a couple of pet projects for sentiment analysis visualization and you could actually see the clusters forming within itself in high dimensional space using at the same time dimensionality reduction.
我在几个宠物项目中使用了t-SNE进行情感分析可视化,并且实际上您可以同时使用降维来看到在高维空间中自身内部形成的簇。
3.强化学习。 (3. Reinforcement Learning.)
Many books and websites refer to these algorithms like the beast but I like thinking about it about the top of the ice cream. Currently being a trending topic due to the achievements that are being accomplished in the area, which I will mention in a bit.
许多书籍和网站都像野兽一样引用这些算法,但是我喜欢在冰淇淋顶部考虑它。 由于该领域已经取得的成就,当前正成为一个热门话题,我将在此稍作提及。
What would you do in this case? Most likely, you will play a couple of times, trying to investigate what are the best movements and the best route you can use to finally rescue the dogs from the shelter. This is similar to what a reinforcement algorithm will do, you can think of it as the following:
在这种情况下,您会怎么做? 您很可能会玩几次,尝试调查什么是最好的动作以及可以用来最终将狗从收容所中救出的最佳路线。 这类似于增强算法将执行的操作,您可以将其视为以下内容:
1. You are given an environment. (space in the context of the video game), representative of the state of certain variables on the space. Like roadblocks or crickets falling from the sky.
1.给你一个环境 。 (在视频游戏的上下文中为空间),表示空间上某些变量的状态。 就像路障或从天而降。
2. Actions to be performed during the event. ( movements, like going up, down, throw a ball to builders ), it’s worth noticing that some actions could be rewarded as “good”, and some others as “bad” meaning it will decrease your ability to achieve the goal.
2.活动期间要执行的操作。 (动作,例如向上,向下,向建造者投掷球),值得注意的是,某些动作可能被奖励为“ 好” ,而另一些动作则被奖励为“差”,这将降低您实现目标的能力。
3. Agents (roles in the video game, rescuer, or builder), the ones who will perform the action to achieve the goal at the minimum cost possible.
3.代理( 在视频游戏,救援人员或建筑商中的角色 ),他们将以最小的成本执行操作以实现目标。
The way it works is the Agent observes the environment, tries to perform actions, and based on these actions will get rewarded for them or not. Potentially the Agents will learn on their own what is the best approach/strategy to pursue in order to get the maximum amount of points (rewards).
代理的工作方式是观察环境,尝试执行操作,并根据这些操作获得或不获得奖励。 代理商可能会自行学习要获得最大积分(奖励)的最佳方法/策略。
One of the best systems I’ve seen so far built with it are:
到目前为止,我所见过的最好的系统之一是:
Hide and Seek, developed by OpenAI. Where they use a multi-agent approach teaching those to play hide and seek. There are 2 agents “hiders” and “seekers” and by observing the environment they were able to learn behaviour/actions that weren’t even provided, like using obstacles to pass barriers. If you are curious about how it works in depth you can watch the video below and the paper
《捉迷藏》 ,由OpenAI开发。 他们使用多代理方法教那些玩捉迷藏的人。 有两个特工“躲藏者”和“寻求者”,通过观察环境,他们能够学习甚至没有提供的行为/动作,例如使用障碍物越过障碍物。 如果您对它的深度工作感到好奇,可以观看下面的视频和本文
Video Games, like StarCraf or AlphaStar. The agents play against humans and indeed it beat the best world player or beat other agents in a matter of a couple of seconds. In order to achieve this, the group that developed AlphaStar didn’t only use Reinforcement learning but others like using Supervised learning to train the neural networks that will create the instructions to play the game. If you are curious about how it was done, you can check their blog post here.
电子游戏 ,例如StarCraf或AlphaStar。 这些特工与人类对战,实际上,它在几秒钟内就击败了世界最佳球员或击败了其他特工。 为了实现这一目标,开发AlphaStar的小组不仅使用了强化学习,还使用了监督学习来训练将创建游戏说明的神经网络。 如果您对它的完成方式感到好奇,可以在这里查看他们的博客文章。
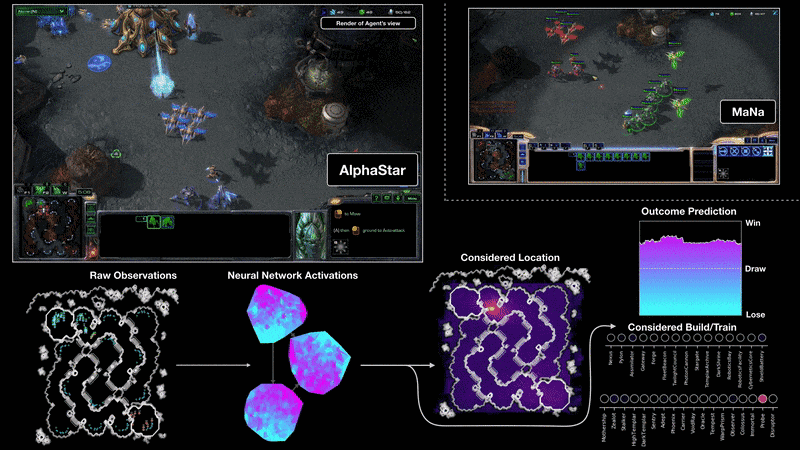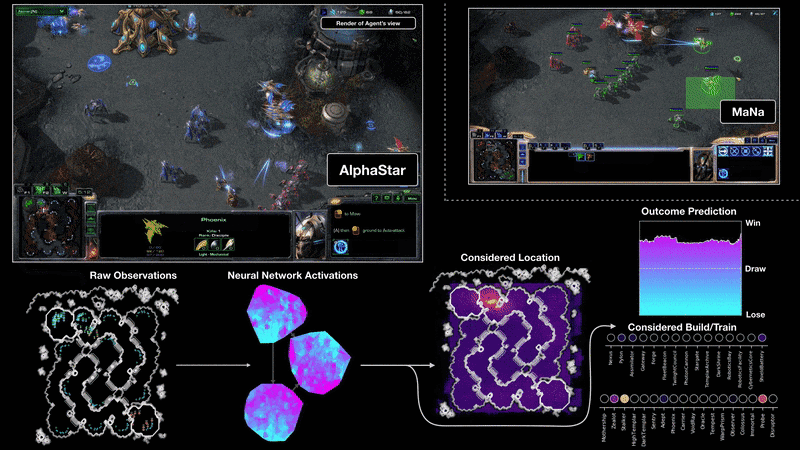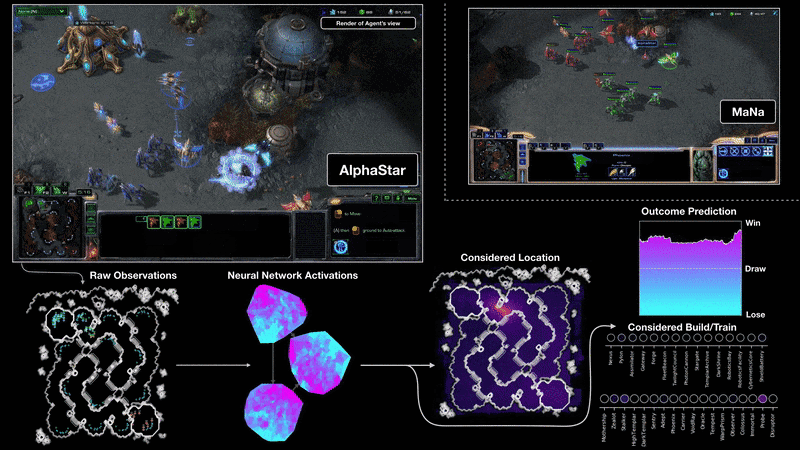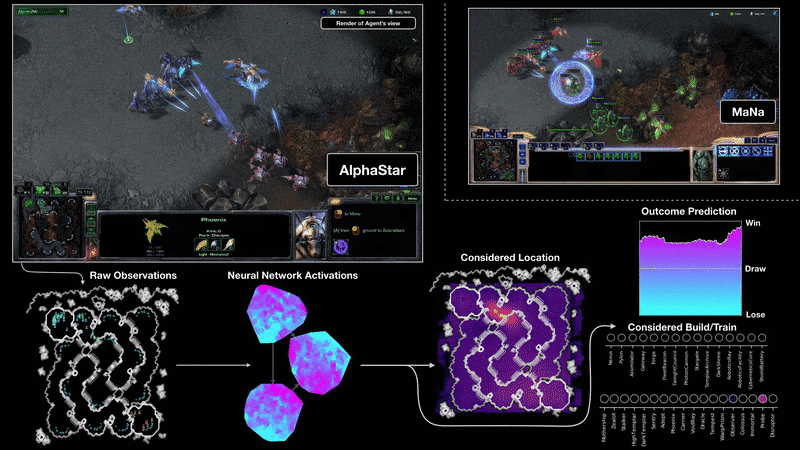
We have learned by now different types of Machine Learning systems based on how little or much the human interaction with those systems is applied. Now we can go ahead and explore the next 2.
到目前为止,我们已经基于人们与这些系统交互的应用程度而了解了不同类型的机器学习系统。 现在我们可以继续探索下一个2。
机器学习算法和训练过程。 (ML Algorithms and Training process.)
In previous sections, we outlined that the training process is how your algorithm will “learn” the best parameters to make a prediction. Having said that, training itself is an art and can be performed differently depending on the use case, resources available, and the data itself.
在前面的部分中,我们概述了训练过程是算法如何“学习”最佳参数以进行预测的过程。 话虽如此,培训本身是一门艺术,可以根据用例,可用资源和数据本身进行不同的操作。
This is divided into two:
这分为两个:
- Batch Learning. 批量学习。
- Online Learning, also known as Incremental Learning. 在线学习,也称为增量学习。
Let’s see how those work:
让我们看看它们是如何工作的:
1.批量学习 (1. Batch Learning)
Batch learning is about training your model with all the data that is available at once rather than doing it incrementally. Usually performing this action takes a lot of time. Imagine having to train Terabytes if not bigger of data all at once. But why would you need to do that?
批处理学习涉及使用一次性可用的所有数据来训练模型,而不是逐步进行。 通常执行此操作会花费很多时间。 想象一下,如果不是一次全部读取更大的数据,就必须训练TB。 但是,为什么需要这样做呢?
Due to the nature of the Business or use case, for example, reports or decisions that are delivered with a certain frequency like weekly/monthly might not need training on a real-time basis.
由于业务或用例的性质,例如,以一定频率(例如每周/每月)发送的报告或决策可能不需要实时培训。
This type of training is usually done offline, as it takes a very long time (hours/days/weeks) to complete.
这种类型的培训通常是离线进行的,因为它需要很长的时间(小时/天/周)才能完成。
How does training occur?
培训如何进行?
- The model is trained. 模型经过训练。
- The model gets deployed and launched to Production. 该模型已部署并启动生产。
- The model is running continuously without further “learning”. 该模型连续运行,无需进一步的“学习”。
All this process is called offline learning. Now you might wonder, what happens if my data or use case has changed? You need to train your model again against incorporating the new data or features.
所有这些过程称为离线学习。 现在您可能想知道,如果我的数据或用例发生了变化会怎样? 您需要针对合并新数据或功能再次训练模型。
A practical example, in my previous job, some of the models were deployed to production in a batch learning fashion and some models didn’t need to be refreshed so often, so It could happen once every week or so. Yet another reason to generate a new model was by looking at metrics deployed in the monitoring system and checking if the performance of the model was being degraded.
一个实际的例子是,在我之前的工作中,一些模型以批量学习的方式部署到生产中,而某些模型不需要那么频繁地刷新,因此它可能每周大约发生一次。 生成新模型的另一个原因是查看监视系统中部署的指标,并检查模型的性能是否下降。
These types of models are tightly related to resources such as IO, CPU, Memory, or Network among others, so having this in mind before deciding on which approach to take is hugely important. Nowadays this might be really expensive but at the same time, you could take advantage of Cloud platforms offering solutions out of the box for doing this, such as AWS Batch, Azure Machine Learning — Batch Prediction, or Google Cloud AI Platform.
这些类型的模型与IO,CPU,内存或网络等资源紧密相关,因此在决定采用哪种方法之前要牢记这一点非常重要。 如今,这可能确实很昂贵,但与此同时,您可以利用Cloud平台提供开箱即用的解决方案,例如AWS Batch , Azure Machine Learning-Batch Prediction或Google Cloud AI Platform 。
Moving on, let’s talk now about Online Learning
继续,让我们现在谈论在线学习
2.在线学习 (2. Online Learning)
Have you wondered how Netflix, Disney, Amazon Prime Video are recommending you what to watch? Or Why Zalando and Amazon keep telling you to buy these amazing trousers that might go with a pair of white shoes? You are probably telling, yeah Recommender Systems, but more than that, how it can be done so quickly? How does the system adapt so quickly to change?
您是否想知道Netflix,迪士尼,亚马逊Prime Video如何推荐您观看什么? 或为什么Zalando和Amazon总是告诉您购买这些可能搭配一双白鞋的惊人裤子? 是的,您可能正在告诉我们Recommender Systems,但是,如何做到如此之快呢? 系统如何快速适应变化?
You probably got it right again, this is done because Training occurs on the fly, meaning data is processed as it’s arriving in the system. This approach is suitable for systems that are receiving data continuously, like retailers, or systems that need to adapt to changes quickly like a News website, or Stock market.
您可能会再次正确,这是因为培训是即时进行的,这意味着数据在到达系统时即得到处理。 这种方法适用于连续不断接收数据的系统(例如零售商)或需要快速适应变化的系统(例如新闻网站或股市)。
In terms of how training is performed is as follows:
在如何进行培训方面如下:
- Data is chunked into pieces or mini-batches. 数据分块或分段。
- Train the model ( continuously). 训练模型(连续)。
- Continuous evaluation / monitoring. 持续评估/监测。
- Deployment to production. 部署到生产。
One of the advantages of doing online learning is that if you don’t have enough computation resources or storage, you can discard the data as you train. Saving you a huge deal of resources. On the other hand, if you need to replay the data you might want to store it for a certain amount of time.
进行在线学习的优势之一是,如果您没有足够的计算资源或存储空间,则可以在训练时丢弃数据。 为您节省大量资源。 另一方面,如果您需要重播数据,则可能需要将其存储一段时间。
As with every system we deal with, this type of training has its strengths and weaknesses. One of the downsides of dealing with this approach is that the Performance of the model might degrade quickly or eventually as the data might change quickly you might notice drops in prediction accuracy at some point in time. For this reason and -barely a topic I have seen talked about often- is having in place good monitoring systems. Those will help your team or company to prevent and understand when to start changing or tuning the models to make them effective.
与我们处理的每个系统一样,这种培训有其优点和缺点。 处理这种方法的缺点之一是,模型的性能可能会Swift下降,或者最终会随着数据的快速变化而下降,您可能会注意到预测准确性在某个时间点下降。 由于这个原因,而且-我很少见到经常谈论的话题-已经建立了良好的监视系统。 这些将帮助您的团队或公司防止并了解何时开始更改或调整模型以使其有效。
强调 (Highlights)
You have come this far and I hope you have enjoyed it. Initially, we talked about how machine learning works to then dive into how Machine Learning is divided according to the perspective of Humans interact with the Algorithms. Ultimately, I tried to describe as much as possible each of these types Supervised, Unsupervised, and Reinforcement Learning with cool examples and applications I have seen around.
您已经走了这么远,希望您喜欢它。 最初,我们讨论了机器学习的工作原理,然后深入研究了如何根据人类与算法交互的角度来划分机器学习。 最终,我尝试用我看过的酷示例和应用程序尽可能多地描述“监督式”,“非监督式”和“强化学习”中的每种类型。
I’ll probably start posting more practical things that I’ve learned on the journey and would love to share. #SharingIsCaring.
我可能会开始发布我在旅途中学到的并且愿意分享的更多实用的东西。 #SharingIsCaring。
Stay well and see you soon.
保持身体健康,很快再见。
翻译自: https://towardsdatascience.com/types-of-machine-learning-ddb20d3199f4














 866
866











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









