






数学建模优化类算法分类
This article explains a new method for clustering disease data by both subtype and stage called SuStaIn (Subtype & Stage Inference). It explains the concept, summarises the maths, and provides a link to the python code.
本文介绍了一种通过以下方法对疾病数据进行聚类的新方法 子类型和阶段都称为SuStaIn(子类型和阶段推断)。 它解释了概念,总结了数学,并提供了python代码的链接。
Classic clustering algorithms like K-Means and Gaussian Mixture Model (GMM) are great for modelling data when we want to find cross-sectional subtypes (aka clusters). This kind of subtyping is used a lot in medicine. A well-known general example is that of subtyping diabetes into “Type I” and “Type II” using a single blood sugar measurement. This can help doctors decide whether to prescribe insulin injections or lifestyle changes.
当我们要查找横截面子类型(又称为聚类)时,像K-Means和高斯混合模型(GMM)这样的经典聚类算法非常适合对数据建模。 这种子类型在医学中被大量使用。 众所周知的一般示例是使用单次血糖测量将糖尿病分为“ I型”和“ II型” 。 这可以帮助医生决定是否开胰岛素注射或改变生活方式。
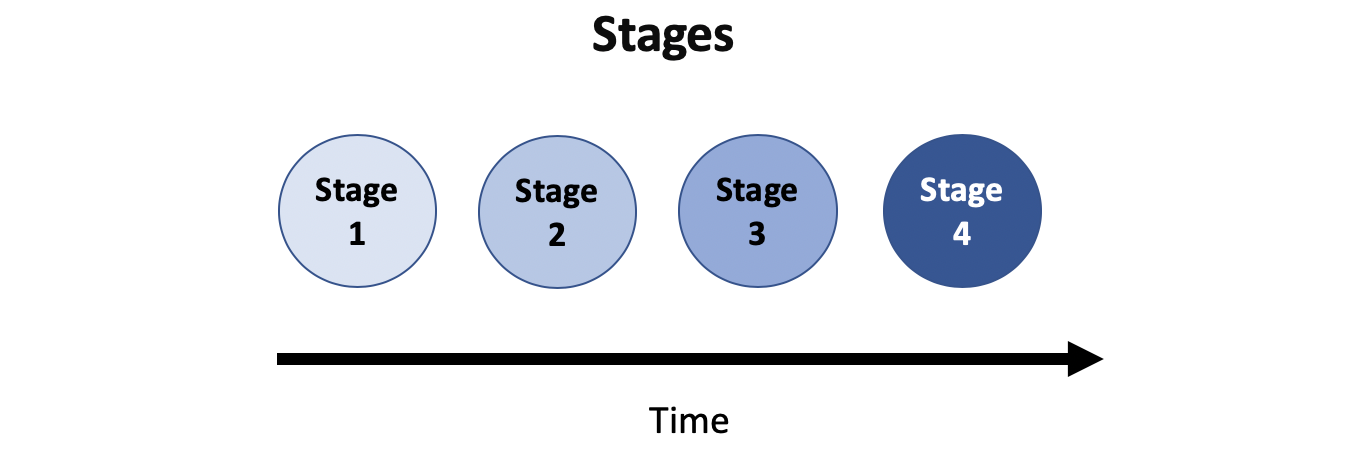
Grouping a disease by stage is also very useful in medicine, this time for modelling disease progression. For example, a model for grouping cancer into stages 1–4 was developed using longitudinal data (multiple measurements from the same person over time). The model itself was developed using longitudinal data but once developed, allowed doctors to determine which stage a patient is at using only a single cross sectional measurement (i.e., tumour size in millimetres). Knowing the stage of cancer may help doctors decide whether radiotherapy or chemotherapy is needed.
在医学中,将疾病按阶段分组也是非常有用的,这一次可以模拟疾病的进展。 例如,使用纵向数据(一段时间内同一个人的多次测量)开发了将癌症分为1至4期的模型。 该模型本身是使用纵向数据开发的,但是一旦开发,医生就可以使用单个横截面测量(即,以毫米为单位的肿瘤大小)来确定患者处于哪个阶段。 了解癌症的阶段可能有助于医生确定是否需要放疗或化疗。
The downside of these kinds of staging models is that they assume all patients come from the same type of the disease. I.e., they account for disease progression, but there is no account of disease subtypes.
这些分期模型的缺点是,它们假定所有患者都来自同一类型的疾病。 即,它们解释了疾病的进展,但没有解释疾病的亚型。
Conversely, the “Cross-sectional subtypes” mentioned previously explain subtypes but not progression. I.e., they assume all patients are at the same stage.
相反,前面提到的“横断面亚型”解释了亚型,但没有解释进展。 即 他们假设所有患者都处于同一阶段。
So what if we want to do both, i.e. find subtypes of a disease based on how it progresses over time, and create that model using only cross-sectional data?
那么,如果我们想同时做这两种事情,即根据疾病随时间的进展找到疾病的亚型,并仅使用横截面数据来创建该模型,该怎么办?
引入Z分数SuStaIn(子类型和阶段推断)算法 (Introducing the Z-Score SuStaIn (Subtype & Stage Inference) Algorithm)
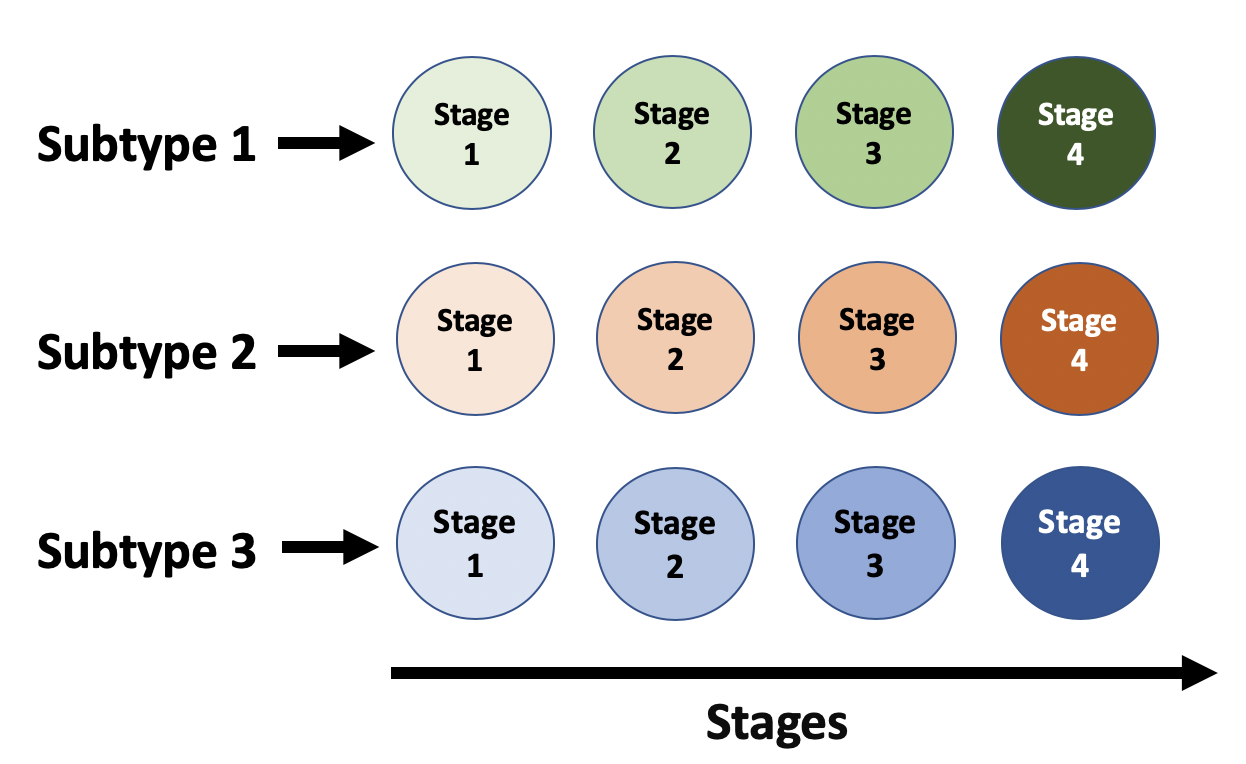
The Z-Score SuStaIn is an unsupervised machine-learning technique that identifies population subgroups (clusters) with distinct patterns of disease progression based on biomarkers. This is shown abstractly in figure 3 below.
Z-Score SuStaIn是一种无监督的机器学习技术,可基于生物标记物识别具有不同疾病进展模式的人群亚组(集群)。 如下图3所示。
Biomarker: “Any substance, structure or process that can be measured in the body or its products and can influence or predict the incidence of outcome or disease” (WHO, 2011). This includes everything from blood sugar measurements and heart rate to
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 812
812











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









