





数据结构和机器学习哪个更难
If the machine learning projects are icebergs, then the parts that are underwater are the labelling and other data efforts that go into the project. The good news is techniques like transfer learning and active learning could help in reducing the effort.
如果机器学习项目是冰山一角,那么位于水下的部分就是进入该项目的标签和其他数据工作。 好消息是像转移学习和主动学习这样的技术可以帮助减少工作量。
Active learning has been part of the toolbox of ML industry practitioners for a while but rarely covered in any of the data science / ML courses. Reading the book Human in the loop machine learning by Robert Munro, helped me formalise some ( and helped me learn many ) of the active learning concepts that I had been using intuitively for my ML projects.
一段时间以来,主动学习一直是机器学习行业从业者工具箱的一部分,但很少在任何数据科学/机器学习课程中涉及。 阅读Robert Munro的《人在循环机器学习》一书,帮助我规范化了一些(并帮助我学习了很多)我一直在直观地用于ML项目的主动学习概念。
The intent of this article is to introduce you to a simple active learning method called ‘Uncertainty sampling with entropy’ and demonstrate its usefulness with an example. For the demonstration, I have used Active learning to utilize only 23% of the actual training dataset ( ATIS intent classification dataset) to achieve the same result as training on 100% of the dataset.
本文的目的是向您介绍一种简单的主动学习方法,称为“带有熵的不确定性采样”,并通过示例演示其实用性。 在演示中,我使用主动学习仅利用23%的实际训练数据集( ATIS意向分类数据集)来获得与100%的数据集训练相同的结果。
Too curious? Jump straight to the demo. Want to first understand how it works? Read on.
太好奇了吗? 直接跳到演示。 想首先了解它是如何工作的? 继续阅读。
什么是主动学习? (What is active learning?)
Active learning is about training our models preferentially on the labelled examples that could give the biggest bang for our buck rather than on the examples with very less “learning signal”. The estimation of an example’s learning signal is done using the feedback from the model.
主动学习是关于优先在有标签的示例上训练我们的模型,这些示例可能会给我们带来最大的收益,而不是在带有很少“学习信号”的示例上。 使用来自模型的反馈来完成示例学习信号的估计。
This is akin to a teacher asking a student about the concepts that she is hazy about and giving preference to those concepts, rather than teaching all of the curricula.
这类似于老师向学生询问她对模糊的概念并偏爱这些概念,而不是教授所有课程。
Since active learning is an iterative process, you would have to go through multiple rounds of training. Steps involved in active learning are:
由于主动学习是一个反复的过程,因此您必须经历多轮培训。 主动学习涉及的步骤包括:
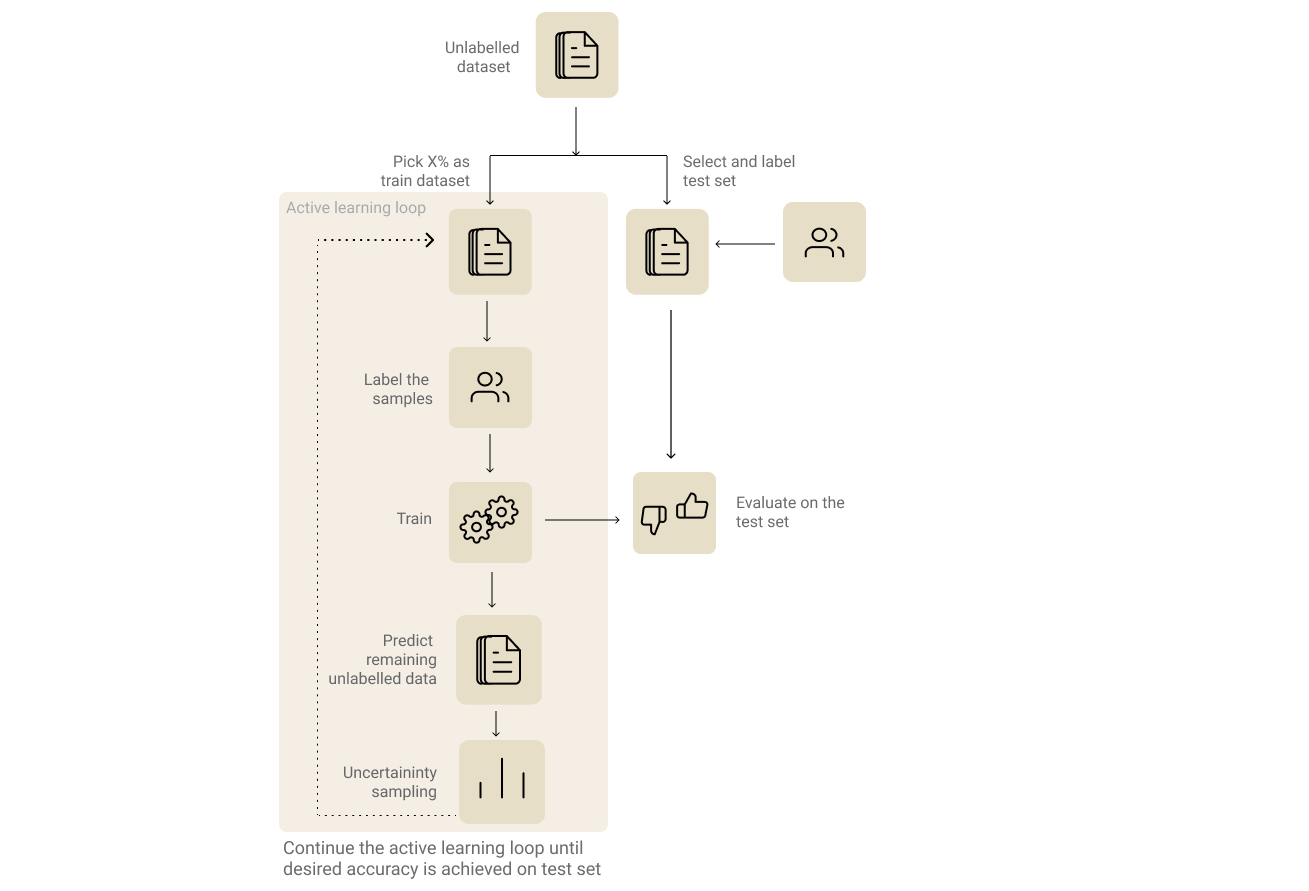
1.识别并标记您的评估数据集。(1. Identify and label your evaluation dataset.)
It goes without saying that choosing an evaluation set is the most important step in any machine learning process. This becomes even more crucial when it comes to active learning since this will be our measure of how well our model performance improves during our iterative labelling process. Furthermore, it also helps us decide when to stop iterating.
毫无疑问,选择评估集是任何机器学习过程中最重要的一步。 对于主动学习,这变得尤为重要,因为这将衡量我们在迭代标注过程中模型性能的提高情况。 此外,它还有助于我们确定何时停止迭代。
The straight forward approach would be to randomly split the unlabelled dataset and pick your evaluation set from that split dataset. But based on the complexity or the business need, it is also good to have multiple evaluation sets. For example, If your business need dictates that a sentiment analysis model should handle sarcasm well, you could have two separate evaluation sets — one for generic sentiment analysis and other for sarcasm specific samples.
直接的方法是随机分割未标记的数据集,然后从该分割的数据集中选择评估集。 但是根据复杂性或业务需求,最好有多个评估集。 例如,如果您的业务需求要求情感分析模型应该很好地处理讽刺,则可以有两个单独的评估集-一个用于一般情感分析,另一个用于讽刺特定样本。
2.确定并标记您的初始训练数据集。 (2. Identify and label your initial training dataset.)
Now pick X% of the unlabeled dataset as the initial training dataset. The value of X could vary based on the model and the complexity of the approach. Pick a value that is quick enough for multiple iterations and also big enough for your models to train on initially. If you are going with a transfer learning approach and the distribution of the dataset is close to the pre-training dataset of the base model, then a lower value of X would be good enough to kick start the process.
现在,选择X%的未标记数据集作为初始训练数据集。 X的值可能会因模型和方法的复杂性而异。 选择一个足够快的值来进行多次迭代,并且选择一个足够大的值以使模型可以在最初进行训练。 如果您要使用迁移学习方法,并且数据集的分布接近基本模型的预训练数据集,那么较低的X值足以启动该过程。
It would also be a good practice to avoid class-imbalance in the initial training dataset. If it’s an NLP problem, you could consider a keyword-based search to identify samples from a particular class to label and maintain class balance.
避免初始训练数据集中的班级不平衡也是一个好习惯。 如果是NLP问题,则可以考虑使用基于关键字的搜索来识别特定类别中的样本,以标记和维护类别平衡。
3.训练迭代 (3. Training Iteration)
Now that we have the initial training and evaluation dataset, we can go ahead and do the first training iteration. Usually, one cannot infer much by evaluating the first model. But the results from the step could help us see how the predictions improve over the iterations. Use the model to predict labels of the remaining unlabelled samples.
现在我们有了初始的训练和评估数据集,我们可以继续进行第一次训练迭代。 通常,不能通过评估第一个模型来推断太多。 但是该步骤的结果可以帮助我们了解预测如何在迭代过程中得到改善。 使用模型预测剩余未标记样品的标记。
4.从上一步中选择要标记的样品子集。 (4. Choose the subset of samples to be labelled from the previous step.)
This is a crucial step where you select samples with the most learning signals for labelling processes. There are several ways to go about doing it (as explained in the book). In the interest of brevity, we will see the method that I felt to be most intuitive of all — Uncertainty sampling based on entropy.
这是至关重要的一步,您可以选择学习信号最多的样本进行标记过程。 有几种方法可以做到这一点(如书中所述)。 为了简洁起见,我们将看到我认为最直观的方法-基于熵的不确定性采样。
Entropy-based Uncertainty Sampling :
基于熵的不确定性采样:
Uncertainty sampling is a strategy to pick samples that the model is most uncertain/confused about. There are several ways to calculate the uncertainty. The most common way is to use the classification probability (softmax) values from the final layer of the neural network.
不确定性抽样是一种选择模型中最不确定/最困惑的样本的策略。 有几种计算不确定度的方法。 最常见的方法是使用神经网络最后一层的分类概率(softmax)值。
If there is no clear winner (i.e all the probabilities are almost the same), it means that the model is uncertain about the sample. Entropy exactly gives us a measure of that. If there is a tie between all the classes, entropy of the distribution will be high and if there is a clear winner amongst the classes, the entropy of the distribution will be low.
如果没有明确的获胜者(即所有概率都几乎相同),则意味着该模型不确定样本。 熵恰恰给了我们一个度量。 如果所有类别之间都有联系,则分布的熵将很高;如果各个类别之间有明显的获胜者,则分布的熵将较低。
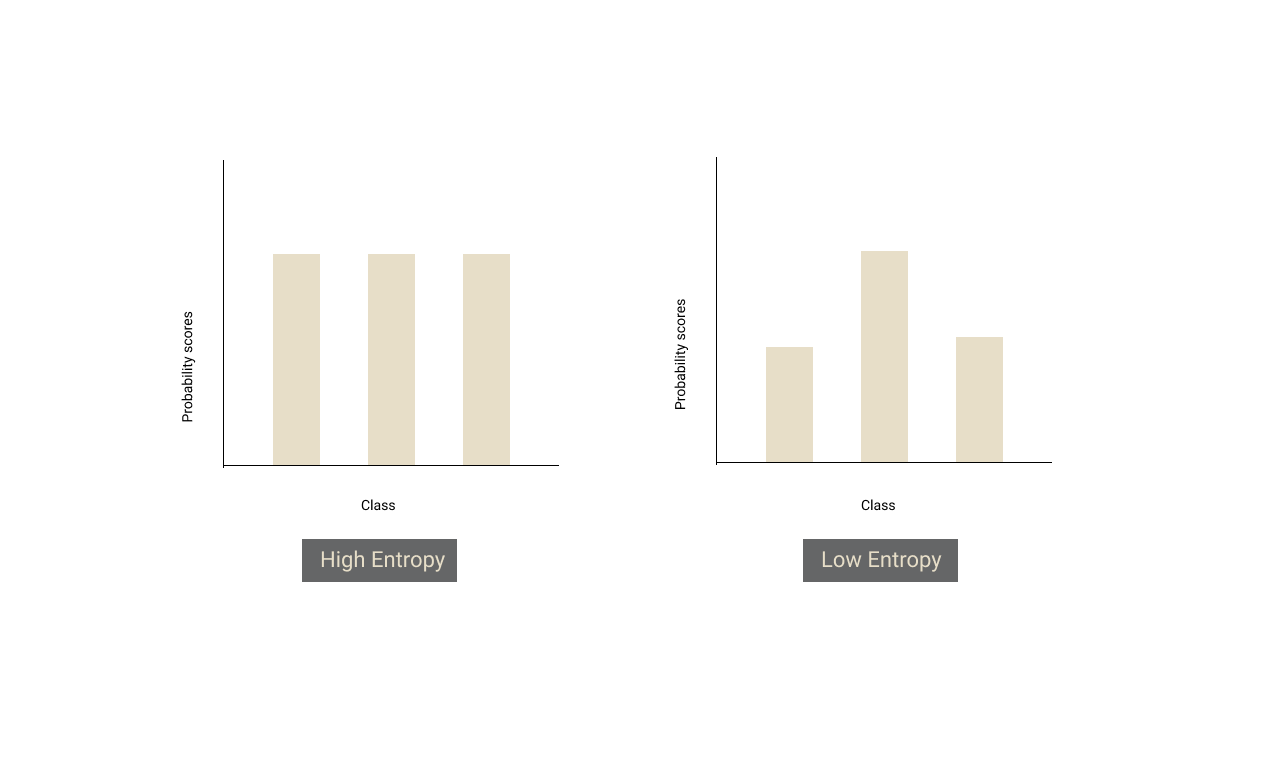
From the model’s predictions of the unlabelled dataset, we should sort the samples in descending order of entropy and pick some Y% of top samples to annotate.
根据模型对未标记数据集的预测,我们应该按熵降序对样本进行排序,并选择顶部样本的Y%进行注释。
5.冲洗并重复: (5. Rinse & Repeat :)
We need to append the training dataset from this iteration with the new samples that we labelled and repeat the process from step 3, until we reach the desired performance on our evaluation set or our evaluation performance plateaus.
我们需要将此迭代的训练数据集附加我们标记的新样本,并重复步骤3的过程,直到我们在评估集或评估绩效平稳期达到所需的绩效。
演示版 (Demo)
For the sake of experiment and demonstration, we will use ATIS intent classification dataset. Let’s consider the training dataset as unlabelled. We start by taking a random 5% of the labelled training dataset for our first iteration. At the end of each iteration, we use entropy-based uncertainty sampling to pick top 10% of the samples and use their labels (simulating the annotation process in the real world) for training in the next iteration.
为了进行实验和演示,我们将使用ATIS意图分类数据集。 让我们将训练数据集视为未标记。 首先,我们从第一次训练中随机抽取5%的标记训练数据集。 在每次迭代的末尾,我们使用基于熵的不确定性采样来挑选前10%的样本,并使用它们的标签(模拟现实世界中的注释过程)在下一次迭代中进行训练。
To evaluate our models during each iteration of active learning, we also take the test set from the dataset since the data in the test set is already labelled.
为了在主动学习的每次迭代期间评估我们的模型,我们还从数据集中获取了测试集,因为测试集中的数据已被标记。
Demo and code is available in the notebook below:
演示和代码在下面的笔记本中可用:
References :
参考文献:
David D. Lewis and William A. Gale. 1994. A Sequential Algorithm for Training Text Classifiers. SIGIR’94, https://arxiv.org/pdf/cmp-lg/9407020.pdf
David D. Lewis和William A. Gale。 1994。一种用于训练文本分类器的顺序算法。 SIGIR'94, https: //arxiv.org/pdf/cmp-lg/9407020.pdf
Thanks to Sriram Pasupathi for taking a greater effort in proofreading this article than what it took me to write this article 🙏
感谢Sriram Pasupathi在校对本文方面比在撰写本文时花了更多的精力🙏
P.S: I would be really glad to hear your feedback on this article, that would also push me to write the other articles in the series on “How to do more with less data”, Please do comment your feedback or DM me at @logesh_umapathi. 👋
PS:我很高兴听到您对本文的反馈,这也促使我撰写该系列文章“如何用更少的数据做更多的事”中的其他文章,请发表您的反馈意见或通过@logesh_umapathi向我发送电子邮件。 👋
翻译自: https://towardsdatascience.com/how-to-do-more-with-less-data-active-learning-240ffe1f7cb9
数据结构和机器学习哪个更难














 882
882











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}