





 本文探讨了简单线性回归的概念,这是一种用于理解变量间关系的统计方法。通过线性方程来建立预测模型,适用于数据分析和机器学习领域。
本文探讨了简单线性回归的概念,这是一种用于理解变量间关系的统计方法。通过线性方程来建立预测模型,适用于数据分析和机器学习领域。
简单线性回归
机器学习 (MACHINE LEARNING)
After finishing with the deep history and introduction to machine learning, I am hungry now and want to make some pancakes. But wait! every time I make pancakes, I either overcook or undercook them. I wonder if machine learning can help me in making better pancakes by predicting the time for which I need to cook them?
在了解了很深的历史并介绍了机器学习之后,我现在很饿,想做点煎饼。 可是等等! 每次我做薄煎饼时,我都会煮过或煮不到。 我想知道机器学习是否可以通过预测需要煮的时间来帮助我制作更好的煎饼?
From statistics, we know that correlation is a technique that can show how and how much pairs of variables are interrelated with each other. In simple words, how a change in one variable related to a component induces a change in the other variable of the same.
从统计数据中,我们知道关联是一种可以显示变量对如何相互关联的技术。 简而言之,与组件相关的一个变量的更改如何引起该组件的另一个变量的更改。
The proportion of ingredients, the thickness of pancakes, the temperature of the stove, the thickness of pan, humidity level, size of chimney, number of birds in the sky and many other factors are inducing a change in the cooking time of my pancakes. How to know which factor is most correlated?
食材的比例,煎饼的厚度,炉子的温度,锅的厚度,湿度,烟囱的大小,天空中的鸟类数量以及许多其他因素正在改变我的煎饼的烹饪时间。 如何知道哪个因素最相关?
There are different types of correlation techniques that help in determining the extent of known factors being interrelated with another factor.
有多种类型的相关技术可帮助确定已知因素与另一因素相关的程度。
Pearson r correlation: This is the most widely used correlation statistic to measure the degree of the relationship between linearly related variables. We can calculate r by using the below formula
皮尔逊相关性:这是使用最广泛的相关性统计量,用于度量线性相关变量之间的关系程度。 我们可以使用以下公式计算r

rxy = Pearson r correlation coefficient between x and yn = number of observationsxi = value of x (for ith observation)yi = value of y (for ith observation)
rxy =皮尔逊r x和y之间的相关系数n =观测次数xi = x的值(对于第i个观测值) yi = y的值(对于第i个观测值)
Kendall rank correlation: It is a non-parametric test that is used to measure the strength of interrelation between two variables. Considering two samples, a and b, where each sample size is n, we get the total number of pairings with a b equal to n(n-1)/2. Kendall rank correlation can be calculated using the below formula:
肯德尔等级相关:这是一种非参数检验,用于测量两个变量之间的相互关系强度。 考虑两个样本a和b,其中每个样本大小为n ,我们得到ab等于n ( n -1)/ 2的配对总数。 肯德尔等级相关性可以使用以下公式计算:
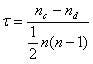
nc= number of concordantnd= Number of discordant
nc =一致数=不一致数
The above-explained techniques help us in determining the known variables which are influencing the unknown variable the most. In my pancake’s case, it is its thickness. Now, I just have to predict the time I need to cook them with respect to its thickness.
以上解释的技术有助于我们确定对未知变量影响最大的已知变量。 以我的煎饼为例,就是它的厚度。 现在,我只需要根据其厚度来预测烹饪时间。
Linear regression is a technique that helps us in modelling the relationship between the known variable (independent variable) and unknown variable (dependent variable) linearly. That is what will be the value of the dependent variable when the value of an independent variable is changing.
线性回归是一种帮助我们线性建模已知变量(独立变量)和未知变量(因变量)之间关系的技术。 当自变量的值改变时,这就是因变量的值。

Y = dependent variable
Y =因变量
X = independent variable
X =自变量
a = random error
a =随机误差
b = regression coefficient
b =回归系数
Now, that i know the independent variable which is inducing change to the dependent variable and the logic of Linear Regression, I can move ahead and build a model that can predict the time to cook a pancake.
现在,我知道了导致变量变化的自变量和线性回归的逻辑,我可以继续构建一个可以预测煮煎饼时间的模型。
Should I code it using Python or should I code it using R, I can use Java too. (The options while selecting a language for coding a machine learning model is overwhelming)
我应该使用Python编码还是使用R编码,我也可以使用Java。 (在选择用于编码机器学习模型的语言时,选项太多了)
- Python is the most popular programming language used for coding, it has plenty of libraries like Teano, Keras, scikit-learn and TensorFlow making it easier for beginners of Machine Learning. Python是用于编码的最流行的编程语言,它具有诸如Teano,Keras,scikit-learn和TensorFlow之类的大量库,这使得机器学习的初学者更加容易。
- R is mostly used for data analysis and statistics computation. It is best for data visualization and can also be used for Regression and Classification. R主要用于数据分析和统计计算。 它最适合用于数据可视化,也可以用于回归和分类。
- Using Java provides simplification to large projects, better user interaction and is the most secure language due to its byte-code and sandboxes. 使用Java可以简化大型项目,实现更好的用户交互,并且由于其字节码和沙箱而成为最安全的语言。
I am using Python for making my Regression model predict the time for cooking my pancakes. You can choose any language based on the requirements.
我正在使用Python使我的回归模型预测烹饪薄煎饼的时间。 您可以根据要求选择任何语言。
- First I need to import the data libraries 首先,我需要导入数据库
# importing data libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pdNumpy — Numpy provides a high-performance multidimensional array and basic tools to compute with and manipulate the arrays
Numpy — Numpy提供了高性能的多维数组和基本工具,可用于计算和操作数组
matplotlib.pyplot — matplotlib. pyplot is a collection of command style functions that make matplotlib work like MATLAB
matplotlib.pyplot — matplotlib。 pyplot是使matplotlib像MATLAB一样工作的命令样式函数的集合
pandas — pandas offer data structures and operations for manipulating numerical tables and time series.
熊猫 -熊猫提供用于操纵数字表和时间序列的数据结构和操作。
2. Then, we need to import the dataset that we are using to train our regression model. I am importing a .csv file hence I am using .read_csv() function.
2.然后,我们需要导入用于训练回归模型的数据集。 我正在导入.csv文件,因此正在使用.read_csv()函数。
# importing data
dataset = pd.read_csv(‘Pancakes_Data.csv’)
X = dataset.iloc[:, :-1].values
Y = dataset.iloc[:,1].values3. Now, we need to split the imported dataset into training and test dataset, we usually prefer 2:1 ratio for the size of training and test dataset.
3.现在,我们需要将导入的数据集分为训练和测试数据集,对于训练和测试数据集的大小,我们通常首选2:1的比率。
# Splitting the dataset into training and test sets
from sklearn.model_selection import train_test_split
X_tain, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 1/3, random_state = 0 )4. To make sure that the values in my data set are not too large or not too small, I will use the feature scaling technique. It is basically used for normalising the range of independent variables of data and is a general step of data preprocessing.
4.为确保数据集中的值不会太大或太小,我将使用要素缩放技术。 它基本上用于标准化数据自变量的范围,并且是数据预处理的一般步骤。
# Feature Scaling
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_tain = sc_X.fit_transform(X_tain)
X_test = sc_X.transform(X_test)5. Now, this the step where our regression model trained, we are doing this by importing the LinearRegression from skLearn library.
5.现在,这是我们的回归模型训练的步骤,我们通过从skLearn库中导入LinearRegression来做到这一点。
# Fitting simple linear regression to the training set
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
regressor.fit(X_tain, Y_train)6. Since we are done with the training step, we can now predict the dependent variable using the trained regression model.
6.由于我们完成了训练步骤,因此我们现在可以使用训练后的回归模型预测因变量。
# Predicting the test set results
Y_pred = regressor.predict(X_test)BONUS STEP
奖励步骤
7. We can visualise the errors with the help of a scatter plot.
7.我们可以借助散点图可视化错误。
# Visualising the training set error
plt.scatter(X_tain, Y_train, color = ‘red’)
plt.plot(X_tain, regressor.predict(X_tain), color = ‘blue’)
plt.show()# Visualising the test set error
plt.scatter(X_test, Y_test, color = ‘red’)
plt.plot(X_tain, regressor.predict(X_tain), color = ‘blue’)
plt.show()Finally, I have a regression model that can predict the time needed to cook my pancakes. It will definitely help me in making better pancakes and it can help you too in solving linear real-world problems.
最后,我有一个回归模型,可以预测煮薄煎饼所需的时间。 它肯定会帮助我制作更好的煎饼,也可以帮助您解决线性现实问题。
We will continue to look at similar topics in future blogs as well. So stay tuned and let us know your thoughts on the article in the comment section below!
我们还将在以后的博客中继续关注类似的主题。 因此,请继续关注,并在下面的评论部分中告诉我们您对本文的看法!
翻译自: https://medium.com/image-vision/correlation-and-simple-linear-regression-9e9064c1fde0
简单线性回归















 142
142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









