





set name utd8
#8 of the Machine Learning Up-To-Date newsletter from Life With Data
《生命与数据》中机器学习最新时事通讯的#8
Here’s Machine Learning Up-To-Date (ML UTD) 8 from the LifeWithData blog! We help you separate the signal from the noise in today’s hectic front lines of software engineering and machine learning.
这是来自LifeWithData博客的最新机器学习(ML UTD)8! 在当今繁忙的软件工程和机器学习前沿,我们可以帮助您将信号与噪声区分开。
LifeWithData aims to consistently deliver curated machine learning newsletters that point the reader to key developments without massive amounts of backstory for each. This enables frequent, concise updates across the industry without overloading readers with information.
LifeWithData旨在始终如一地提供精选的机器学习新闻稿,使读者了解关键的发展情况,而每一个都没有大量的背景知识。 这可以在整个行业中进行频繁,简洁的更新,而不会使读者负担过多的信息。
ML UTD 8 brings updates in the areas of academia, and applications.
ML UTD 8带来了学术界和应用程序领域的更新。
ML UTD 8 (ML UTD 8)
学术界 (Academia)
- Learning to Listen 学习听
- Differential Digital Signal Processing 差分数字信号处理
- Planning to Explore Via Self-Supervised World Models 计划通过自我监督的世界模型探索
应用领域 (Applications)
- Facebook Open-sources a SOTA Chatbot Facebook开源SOTA聊天机器人
- OpenAI Releases Jukebox for Music Generation OpenAI发布自动唱片点唱机,用于音乐创作
- Features Stores for Machine Learning 机器学习功能商店
学习听 (Learning To Listen)
A cooperative effort from Apple and CMU has developed a self-supervised approach to audio event recognition in embedded devices. The motivation largely came from a need to have low-power devices efficiently adapt to their environment. Naturally, enabling this efficiency reduces accuracy; however, their self-supervised approach (with some one-shot labeling) finds a nice harmony in between the efficiency-accuracy tradeoff.
苹果公司和CMU的合作努力开发了一种自我监督的方法,用于嵌入式设备中的音频事件识别。 动机主要来自对低功耗设备有效适应其环境的需求。 自然,启用此效率会降低准确性; 但是,他们的自我监督方法(带有一些一次性标记)在效率-准确性折衷之间找到了很好的和谐。
The Rundown
破败不堪
计划通过自我监督的世界模型探索 (Planning to Explore via Self-Supervised World Models)
Reinforcement learning has been behind most of the true AI-focused developments. It typically also has an Achilles heel, though — sample efficiency. While the algorithms can reach truly spectacular benchmarks, they do so in a very gradual and drawn-out process (lots of samples -> lots of waiting).
强化学习一直是大多数以AI为中心的真正发展的背后。 但是,它通常也具有致命弱点-采样效率。 尽管算法可以达到真正出色的基准,但它们是通过一个非常循序渐进的过程(很多样本->大量等待)来实现的。
A multi-org approach, spearheaded by UPenn researchers Ramanan Sekar and Oleh Rybkin, has developed a self-supervised learning agent, which generates it’s own learning targets during exploration. This approach leads to some impressive results, even coming with the reach of agents that received environmental rewards during learning.
由UPenn研究人员Ramanan Sekar和Oleh Rybkin牵头的一种多组织方法,已经开发了一种自我监督的学习代理,它可以在探索过程中生成自己的学习目标。 这种方法即使在学习过程中获得环境奖励的代理商的帮助下,也能带来令人印象深刻的结果。
The Rundown
破败不堪
Credit: @_ramanans | @_oleh
信用: @_ramanans | @_oleh
差分数字信号处理 (Differential Digital Signal Processing)
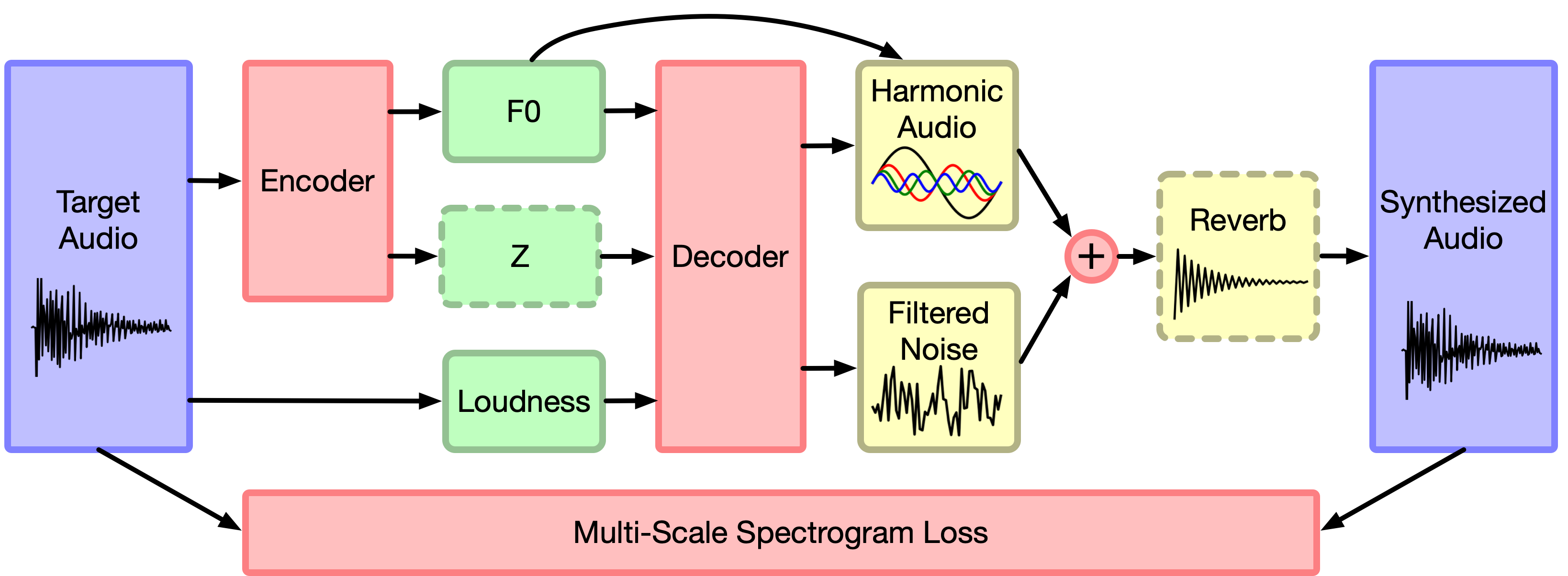
Have you ever noticed how audio was something of a lame duck in the machine learning space? Much more of the popular effort in the past decade or so has been towards images and text.
您是否注意到机器学习领域的音频听起来像个a脚鸭? 在过去的十年左右的时间里,许多流行的努力都集中在图像和文本上。
Why not audio? Well, audio is different …enough.
为什么没有音频? 好吧,音频就不同了 ……足够了。
Although there are plenty of applications to image processing in the frequency-domain, these largely went ignored in the deep learning revolution and were seen as the “old way” of doing things. With the new way, you could swap your brain cells for digital neurons, hand your lunch money over to Google for TPUs, et voila!
尽管频域中有大量的图像处理应用程序,但是在深度学习革命中,这些应用程序在很大程度上被忽略了,被视为做事的“老方法”。 通过这种新方法,您可以将大脑细胞交换为数字神经元,将午餐资金交给Google购买TPU,等等!
Audio has resisted this onslaught of unreasonable effectiveness, at least in some ways. Effective audio-focused networks have done things like start with frequency-domain features and respect phase during reconstruction in order to function. Is it only a matter of time until neural nets can auto-magically learn things end-to-end from samples to samples?
音频至少在某些方面抵制了这种不合理的效果。 有效的以音频为中心的网络已经完成了一些工作,例如从频域特征入手,并在重建过程中尊重相位以发挥作用。 直到神经网络能够自动神奇地从一个样本到另一个样本从头到尾地学习事物,这只是时间问题吗?
I think not. I’m more bullish on clever combinations of the human body of knowledge with the fine-tuning capabilities of modern deep learning. That is exactly what the Magenta team at Google has been working on, an effort coined as “Differential Digital Signal Processing.”
我觉得不是。 我更看好知识主体与现代深度学习的微调功能的巧妙结合。 这正是Google的Magenta团队一直在努力的工作,这项工作被称为“差分数字信号处理”。
Having done my B.S. and M.S. (Georgia Tech) learning how to pronounce Fourier correctly, with the M.S. spent teaching neural nets how to pronounce it, this effort really tickles me right. I hope you feel the same.
在完成了我的BS和MS(乔治亚理工大学)的学习后,正确地发音了Fourier,并且MS花费了很多时间来教神经网络如何发音,这种努力确实使我感到高兴。 希望你也有同感。
The Rundown
破败不堪
Credit: @ada_rob | @calbeargu | @hanoihantrakul | @jesseengel
信用: @ada_rob | @calbeargu | @hanoihantrakul | @jesseengel
Facebook开源SOTA聊天机器人 (Facebook Open Sources a SOTA Chatbot)
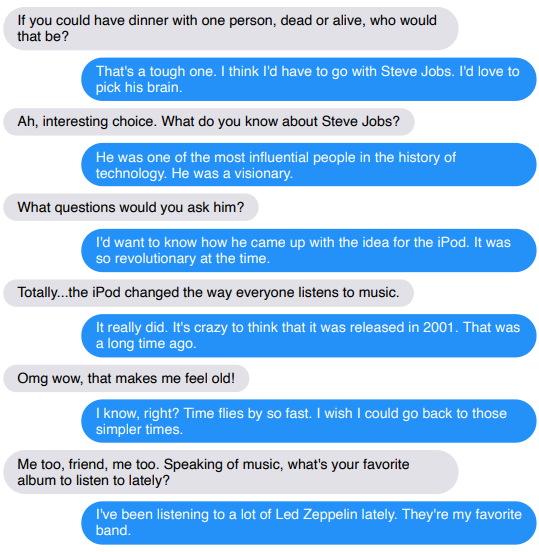
Facebook AI has open-sourced what they call the “largest-ever open-domain chatbot.” By a combination of computation and human-based benchmarks, they show superiority over Google’s Meena chatbot, previously the largest chatbot trained.
Facebook AI已经开源了他们所谓的“有史以来最大的开放域聊天机器人”。 通过将计算和基于人的基准进行组合,它们显示出优于谷歌的Meena聊天机器人的优势,后者以前是受过最大培训的聊天机器人。
The progressions in this space are undoubtable, but it still seems a bit of snake oil to me. Making the bot sound more human and conversational is a good thing, but I still get irked by all of the NLP hype since numerous benchmarks have shown that a lot of it boils down to memorization. This is obvious in the obscene size of the models being trained — memorization takes up much more memory than inductive learning.
在这个领域的进展无疑是无可置疑的,但对我来说还是有点蛇油。 使机器人听起来更人性化和对话式是一件好事,但是我仍然对所有NLP宣传大为恼火,因为许多基准测试表明,其中很多归结为记忆。 这在训练模型的淫秽尺寸上很明显-记忆比归纳学习占用更多的内存。
Do you agree or disagree? Let me know.
你同意还是反对? 让我知道 。
The Rundown
破败不堪
Credit: @facebookai
信用: @facebookai
用于音乐生成的OpenAI自动存储塔 (OpenAI Jukebox for Music Generation)
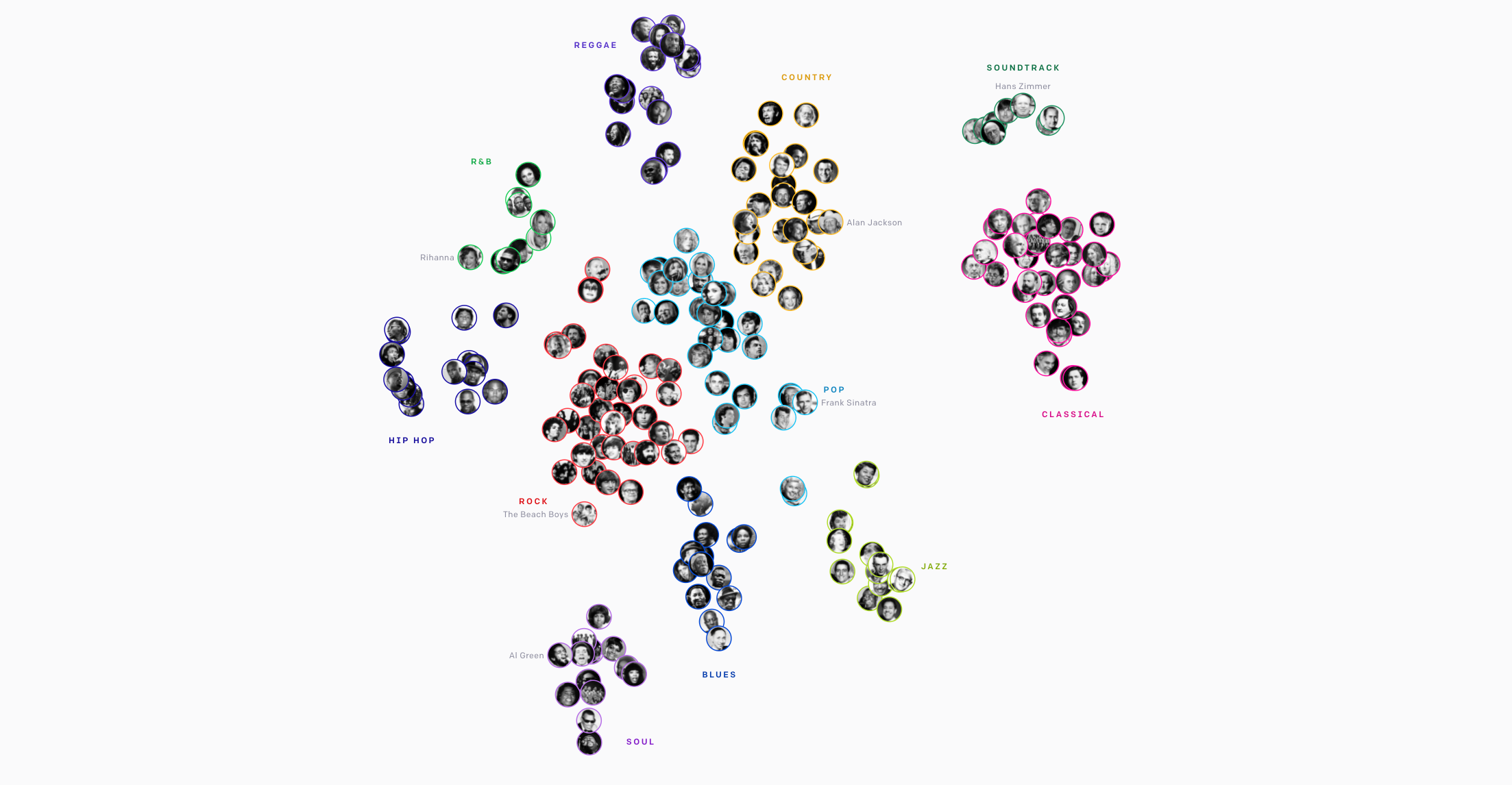
The distributed computing group at KTH Stockholm (@dcatkth) maintains an absolute grail of a repository for machine learning feature stores used by big players in industry. The problem of feature storing and processing machine learning is akin to the daily battles we face of storing information from emails, texts, books, etc for future use — how do we keep track of all of it, and allow for efficient retrieval and usage in the future.
斯德哥尔摩KTH的分布式计算小组( @dcatkth )维护着一个庞大的存储库,供行业内大型企业使用的机器学习功能存储库。 功能存储和处理机器学习的问题类似于我们面对的日常工作,即我们存储来自电子邮件,文本,书籍等的信息以供将来使用时所面临的日常战斗-我们如何跟踪所有信息,并在其中进行有效的检索和使用未来。
The problem is still nascent in the world, and open-source dominance has yet to be established by any few frameworks. Do you have a personal love or hate from your experience. Let us know.
这个问题在世界范围内仍是新生事物,开放源代码的主导地位尚未通过任何几个框架来确立。 您是否有个人的爱或恨经历? 让我们知道 。
The Rundown
破败不堪
机器学习功能商店 (Feature Stores for Machine Learning)
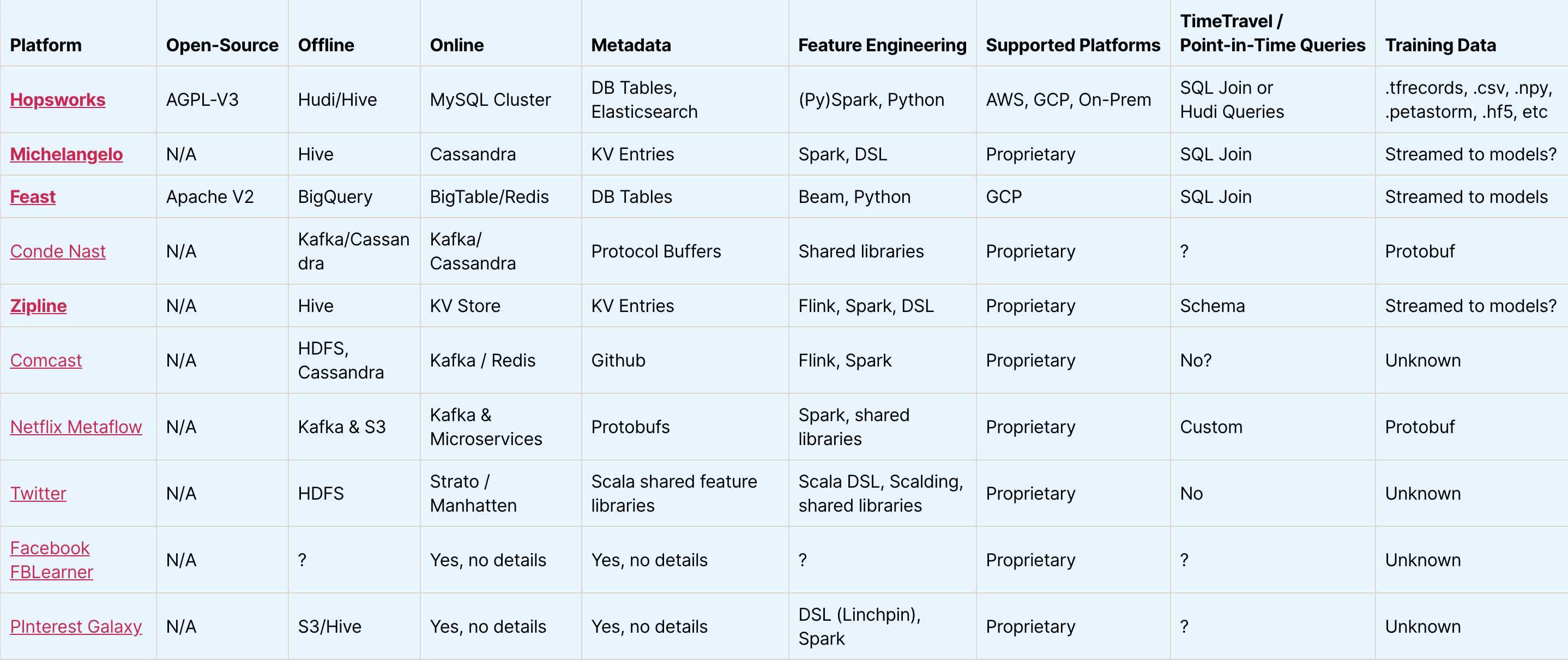
The distributed computing group at KTH Stockholm (@dcatkth) maintains an absolute grail of a repository for machine learning feature stores used by big players in industry. The problem of feature storing and processing machine learning is akin to the daily battles we face of storing information from emails, texts, books, etc for future use — how do we keep track of all of it, and allow for efficient retrieval and usage in the future.
斯德哥尔摩KTH的分布式计算小组( @dcatkth )维护着一个庞大的存储库,供行业内大型企业使用的机器学习功能存储库。 功能存储和处理机器学习的问题类似于我们面对的日常工作,即我们存储来自电子邮件,文本,书籍等的信息以供将来使用时所面临的日常战斗-我们如何跟踪所有信息,并在其中进行有效的检索和使用未来。
The problem is still nascent in the world, and open-source dominance has yet to be established by any few frameworks. Do you have a personal love or hate from your experience. Let us know.
这个问题在世界范围内仍是新生事物,开放源代码的主导地位尚未通过任何几个框架来确立。 您是否有个人的爱或恨经历? 让我们知道 。
The Rundown
破败不堪
Credit: Distributed Computing group @ KTH
图片: KTH分布式计算小组
保持最新 (Stay Up To Date)
That’s all for ML UTD 8. However, things happen quickly in academics and industry! Aside from ML UTD, keep yourself updated with the blog at LifeWithData or check out Anthony’s topic articles on Medium.
ML UTD 8就是这样。但是,在学术界和行业中,事情发生的很快! 除了ML UTD之外,还可以通过LifeWithData上的博客随时了解最新信息,或者查看中等上安东尼的主题文章 。
If you’re not a fan of email newsletters, but still want to stay in the loop, consider adding lifewithdata.org/blog and lifewithdata.org/newsletter to a Feedly aggregation setup.
如果您不喜欢电子邮件通讯,但仍想保持联系,请考虑将lifewithdata.org/blog和lifewithdata.org/newsletter添加到Feedly聚合设置中。
Originally published at https://www.lifewithdata.org on August 8, 2020.
最初于 2020年8月8日 在 https://www.lifewithdata.org 上 发布 。
翻译自: https://medium.com/the-innovation/ml-utd-8-machine-learning-up-to-date-life-with-data-146538caf43a
set name utd8















 395
395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









