





 本文介绍了如何简单地连接到Google Cloud Platform (GCP)的谷歌云盘,原文作者为Anish Mahapatra,主要面向数据科学和云计算的用户。
本文介绍了如何简单地连接到Google Cloud Platform (GCP)的谷歌云盘,原文作者为Anish Mahapatra,主要面向数据科学和云计算的用户。
gcp怎么连接谷歌云盘
The Cloud is a complicated space. It’s not a simple plug and play as most people would imagine. We have folks from various backgrounds such as developers, network engineers, machine learning engineers, data architects etc. who would have mastery over certain components of the cloud.
云是一个复杂的空间。 这不是大多数人想象的简单的即插即用功能。 我们有来自不同背景的人员,例如开发人员,网络工程师,机器学习工程师,数据架构师等,他们将精通云的某些组件。
When working in an enterprise environment, it is critical that experts are working on the various relevant components and everybody has a place in the data and model pipeline lifecycle. This can include roles such as:
在企业环境中工作时,至关重要的是专家们在研究各种相关组件,并且每个人都在数据和模型管道生命周期中占有一席之地。 这可以包括以下角色:
Security: Handling of Identity and Access Management (IAM)
安全性 :身份和访问管理(IAM)的处理
Data Architecture: Understanding the interaction between various cloud services and in-depth understanding of on-prem services & requirements
数据体系结构 :了解各种云服务之间的交互以及对本地服务和需求的深入了解
Model Operationalization: Hands-on understanding of IaaS, PaaS, SaaS features on the Cloud; pipeline automation, optimization, deployment, monitoring and scaling
模型操作化 :对云上IaaS,PaaS,SaaS功能的动手理解; 管道自动化,优化,部署,监视和扩展
Infrastructure: Dynamic requirements of various projects and products to minimize the cost to the company along with agility in application
基础架构 :各种项目和产品的动态需求,以最小化公司成本以及应用程序的灵活性
Support: End to end knowledge of the Cloud platform being leveraged from professionals to save time on debugging (knowing over learning)
支持 :专业人士利用云平台的端到端知识,以节省调试时间(了解学习情况)
A healthy mix of the above skillsets can lead to a successful movement to move from legacy systems to scaling on the cloud.
上述技能组合的健康组合可以导致成功从旧式系统迁移到云上的扩展。
GCP上的数据生命周期 (The Data Lifecycle on GCP)
Google has been in the internet game for a long time. Along the way, they have built multiple great products. When your efforts are experimental and not streamlined, to begin with, it becomes evident in the product portfolio offering.
Google从事互联网游戏已有很长时间了。 一路走来,他们制造了多种出色的产品。 首先,如果您的工作是试验性的而不是精简的,则在产品组合产品中将显而易见。
The same workflow can be achieved on the cloud in multiple ways. The optimization and right choices made is what makes one a Google Cloud Data Professional.
可以通过多种方式在云上实现相同的工作流程。 做出的优化和正确的选择使Google Cloud Data Professional成为最佳选择。
Data Lifecycle is the cycle of data from initial collection to final visualization. It consists of the following steps:
数据生命周期是数据从初始收集到最终可视化的周期。 它包括以下步骤:
Data Ingestion: Pull in the raw data from the source — this is generally real-time data or batch data
数据提取:从源中提取原始数据-这通常是实时数据或批处理数据
Storage: The data needs to be stored in the appropriate format. Data has to be reliable and accessible.
存储 :数据需要以适当的格式存储。 数据必须可靠且可访问。
Data Processing: The data has to be processed to be able to draw actionable insights
数据处理 :必须对数据进行处理才能得出可行的见解
Data Exploration and Visualization: Depending on the consumption of the data, it has to be showcased appropriately to stakeholders
数据探索和可视化 :根据数据的使用情况,必须将其适当地展示给利益相关者
1.数据存储 (1. Data Storage)
Data Storage on the Cloud is a value-offering that enterprises should leverage. Multiple features cannot be achieved with an on-premise storage option. Fault Tolerance, Multi-regional support for reduced latency, elasticity based on increased workloads, Preemptible VM instances, pay-per-usage and reduced maintenance costs among many more advantages.
云上的数据存储是企业应利用的价值提供。 使用本地存储选项无法实现多种功能。 容错,支持减少延迟的多区域支持,基于增加的工作负载的弹性,可抢占的VM实例 ,按使用量付费和降低的维护成本等诸多优势。
Having said this, GCP has multiple offerings in terms of data storage. Choosing the right service is as important as the optimizing for the cloud.
话虽如此,GCP在数据存储方面有多种产品。 选择正确的服务与优化云同样重要。
Google Cloud Platform的Data Lake:Google Cloud Storage (The Data Lake of Google Cloud Platform: Google Cloud Storage)

Considered the ultimate staging area, Google Cloud Storage is flexible to accept all data formats, any type and can be used to store real-time as well as archived data at reduced costs
Google云端存储被视为最终的过渡区域,可以灵活地接受所有数据格式,任何类型,并且可以以较低的成本存储实时数据和存档数据
Google Cloud Storage is a RESTful online file storage web service for storing and accessing data on Google Cloud Platform infrastructure. The service combines the performance and scalability of Google’s cloud with advanced security and sharing capabilities.
Google Cloud Storage是RESTful在线文件存储Web服务,用于在Google Cloud Platform基础结构上存储和访问数据。 该服务将Google云的性能和可扩展性与高级安全性和共享功能结合在一起。
Consider Google Cloud Storage as the Web File System Equivalent, it is reliable, can accept anything you throw at it and is flexible in costs depending on your data needs — Standard, Nearline, Coldline, Archive
将Google Cloud Storage视为等效的Web文件系统,它可靠,可以接受您扔给它的任何东西,并且根据您的数据需求 (标准,近线,冷线,存档)灵活调整成本
Google Cloud SQL (Google Cloud SQL)

Google Cloud SQL is a fully-managed database service that helps you set up, maintain, manage, and administer your relational databases.
Google Cloud SQL是一项完全托管的数据库服务,可帮助您设置,维护,管理和管理关系数据库。
Use-cases: Structured Data based on a Web Framework. For example, Warehouse Records, Articles
用例:基于Web框架的结构化数据。 例如,仓库记录,文章
Cloud SQL can be leveraged when opting for a direct lift and shift of traditional SQL Workloads with the maintenance stack managed for you.
选择直接提升和转移传统SQL工作负载并为您管理的维护堆栈时,可以利用Cloud SQL。
Best Practices: More, Smaller Tables rather than fewer, larger tables
最佳做法:更多,更小的表而不是更少,更大的表
Google Cloud数据存储 (Google Cloud Datastore)

Google Cloud Datastore is a highly scalable, fully managed NoSQL database service.
Google Cloud Datastore是高度可扩展的,完全托管的NoSQL数据库服务。
Use-cases: Semi-Structured Data; used for key-value type data. For example, storage of Product SKU Catalogs and storing Gaming checkpoints
用例 :半结构化数据; 用于键值类型数据。 例如,存储产品SKU目录和存储游戏检查点
Cloud Datastore can be utilized as a No Ops, Highly Scalable non-relational database. The structure of the data can be defined per the business requirement.
Cloud Datastore可用作无操作,高度可扩展的非关系数据库。 可以根据业务需求定义数据的结构。
Google Cloud Bigtable (Google Cloud Bigtable)

Google Cloud Bigtable is a fully managed, scalable NoSQL database Singe-Region service for large analytical and operational workloads. It is not compatible with multi-region deployments.
Google Cloud Bigtable是一项完全托管的,可扩展的NoSQL数据库Singe-Region服务,用于大型分析和操作工作负载。 它与多区域部署不兼容。
Use-cases: High Throughput Analytics, sub-10ms response time with million reads/write per second. Used for Finance, IoT etc.
用例:高吞吐量分析,响应时间低于10毫秒,每秒读取/写入百万次。 用于金融,物联网等
Cloud Bigtable is Not No Ops compliant, changing disk type (HDD/ SDD) requires a new instance. Recognized through one identifier, row key.
Cloud Bigtable不符合No Ops的要求,更改磁盘类型(HDD / SDD)需要一个新实例。 通过一个标识符(行键)识别。
Good Row keys lead to distributed load and Poor row keys lead to hot-spotting. Indicators of poor row keys: Domain Names, Sequential IDs, Timestamps.
行键好会导致负载分散,行键差会导致热点 。 行键不良的指示符:域名,顺序ID,时间戳。
Google Cloud Spanner (Google Cloud Spanner)

Google Cloud Spanner is a fully managed relational database with unlimited scale, strong consistency & up to 99.999% availability. It is essentially built for pure scale with minimal downtime and complete reliability.
Google Cloud Spanner是一个完全托管的关系数据库,具有无限扩展,强大的一致性和高达99.999%的可用性。 它本质上是为纯规模构建的,具有最小的停机时间和完全的可靠性。
Use-cases: RDBMS and high scale transactions. For example, Global Supply Chain, Retail tracking of PoS etc.
用例: RDBMS和大规模事务。 例如,全球供应链,PoS的零售跟踪等。
Cloud Spanner is a fully managed, highly scalable/ available relational database with strong transactional consistency (ACID Compliance).
Cloud Spanner是一个完全托管,高度可扩展/可用的关系数据库,具有强大的事务一致性(符合ACID)。
Google BigQuery(存储) (Google BigQuery (Storage))

Google BigQuery is a fully-managed, serverless data warehouse that enables scalable analysis over petabytes of data. It is a serverless Software as a Service that supports querying using ANSI SQL. It also has built-in machine learning capabilities.
Google BigQuery是一个完全托管的无服务器数据仓库,可对PB级数据进行可扩展的分析。 它是一种无服务器软件即服务,支持使用ANSI SQL进行查询。 它还具有内置的机器学习功能。
Use-cases: Mission-critical apps that require scale and consistency. Used for Large Data Analytics processing using SQL.
用例:需要规模和一致性的关键任务应用程序。 用于使用SQL的大数据分析处理。
Google BigQuery supports limited machine learning implementations too.
Google BigQuery也支持有限的机器学习实施。
Great job! You have understood a fair bit about the storage within the Google Cloud Platform. The below image illustrates how it all comes together.
很好! 您已经对Google Cloud Platform中的存储有一定了解。 下图说明了它们如何组合在一起。
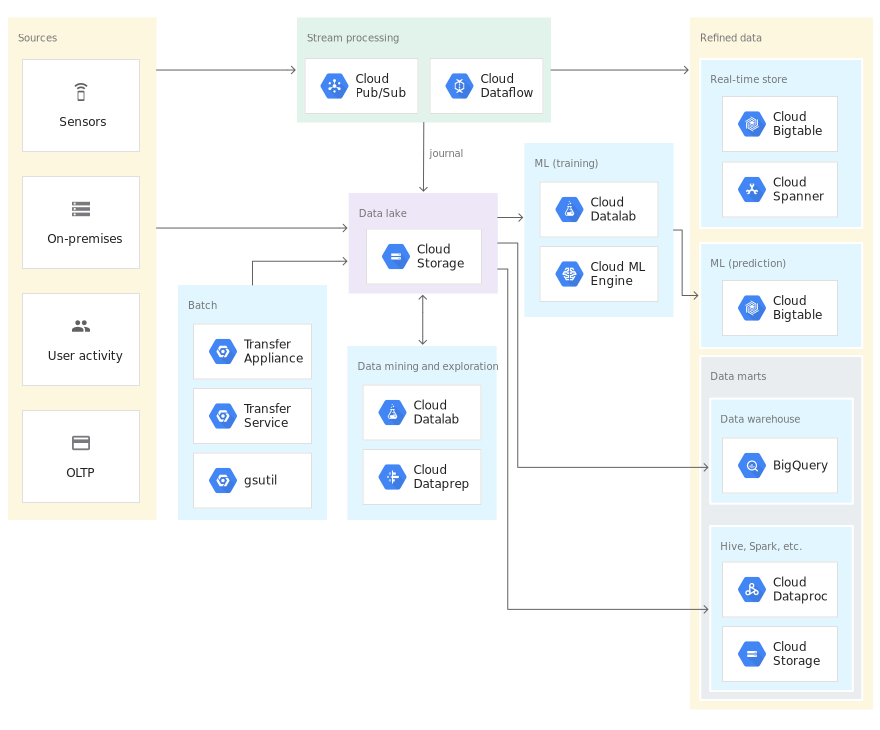
I would like to reiterate here, a similar workflow and workload can be performed on GCP in multiple ways, but the choice of which way would be most optimal depends on the short-term and long-term plans of scaling and usage of the project/ organization.
我想在这里重申,可以通过多种方式在GCP上执行类似的工作流程和工作量,但是哪种方式最合适则取决于项目/规模/用途的短期和长期计划组织。
2.设置数据管道 (2. Setting up Data Pipelines)
Now with the above section that we know where our data is going, the next question to tackle is how do we get our data there. This is known as a Data Pipeline. We have to start building our data pipelines to ensure that the data used at any point is per the expectations of the end-user.
现在,通过以上部分,我们知道了数据的去向,接下来要解决的问题是如何将数据存储到那里。 这就是所谓的数据管道。 我们必须开始构建数据管道,以确保在任何时候使用的数据都符合最终用户的期望。
The three main types of data are:
数据的三种主要类型是:
Historical/ Archive data: This is the old data that might be used at some point. We upload all these data to GCP via the methods available
Streaming (or real-time) data: This would include the data that is generated in real-time and one that we would like to analyze in near real-time, like financial data
流(或实时)数据:这将包括实时生成的数据以及我们希望近实时分析的数据,例如财务数据
Batch (or bulk) data: This would include data that is updated in batches with low latency not being a priority
批次(或批量)数据:这将包括以低延迟(不是优先级)的批次更新的数据
Let us now understand how Google Cloud Platform provisions this with their various services.
现在,让我们了解Google Cloud Platform如何通过其各种服务进行配置。
Google Cloud发布/订阅: (Google Cloud Pub/Sub:)

Google Pub/Sub stands for Publisher and Subscriber. This service lets you stream data from the source in real-time. The open-source equivalent is Apache Kafka.
Google Pub / Sub代表发布者和订阅者。 此服务使您可以实时从源流式传输数据。 开源等效项是Apache Kafka 。
Pub/Sub is an asynchronous messaging service that decouples services that produce events from services that process events.
发布/订阅是异步消息传递服务,它将产生事件的服务与处理事件的服务分离。
Use-Cases: Stream Analytics, Asynchronous microservices integration. For example, streaming IoT data from various manufacturing machine units.
用例:流分析,异步微服务集成。 例如,来自各种制造机器单元的IoT数据流。

This service can be used for streaming data when fast action is necessary to quickly collect data, gain insights and take action for instances such as credit card fraud.
当需要快速采取行动以快速收集数据,获取见解并针对信用卡欺诈等情况采取行动时,此服务可用于流式传输数据。
Google Cloud Dataflow (Google Cloud Dataflow)

Google Cloud Dataflow is a unified stream and batch data processing that’s serverless, fast, and cost-effective.
Google Cloud Dataflow是一种无服务器,快速且经济高效的统一流和批处理数据处理。
The open-source equivalent of Dataflow is Apache Beam.
数据流的开源等效项是Apache Beam 。
Use-cases: Stream Analytics, Real-Time AI, Anomaly Detection, Predictive Forecasting, Sensor and Log processing
用例:流分析,实时AI,异常检测,预测性预测,传感器和日志处理
Handling mishaps from Cloud Pub/Sub are all done in Google Cloud Dataflow. The process can be managed to decide up until what point we will accept the data and how to monitor the same.
处理来自Cloud Pub / Sub的事故都是在Google Cloud Dataflow中完成的。 可以管理该过程以决定直到我们将接受数据的哪一点以及如何监视它们。

Google Cloud Dataflow takes in multiple instances of streaming data into the required workflow and handles multiple consistency edge cases and streamlines data for pre-processing in near real-time analysis.
Google Cloud Dataflow将流式数据的多个实例纳入所需的工作流程中,并处理多个一致性边缘案例,并简化了数据以进行近实时分析中的预处理。
Google Cloud Dataproc (Google Cloud Dataproc)

Google Dataproc makes open-source data and analytics processing fast, easy, and more secure in the cloud. This service enables automated Cluster Management that spins up and down automatically based on triggers. This makes them extremely cost-efficient, yet effective for multiple use-cases.
Google Dataproc使云中的开放源代码数据和分析处理快速,轻松且更安全。 该服务启用了自动集群管理,该集群管理将基于触发器自动上下旋转。 这使得它们极具成本效益,但对于多个用例却有效。
Use-cases: Can be used to run Machine Learning tasks, PySpark for NLP etc. For instance, running customer churn analysis on Telecom data.
用例:可用于运行机器学习任务,用于NLP的PySpark等。例如,对电信数据进行客户流失分析。
Resizable clusters, Autoscaling features, versioning, highly available, cluster scheduled deletion, custom images, flexible VMs, Component Gateway and notebook access from assigned Dataproc cluster are a few of the features that are industry-leading for Dataproc clusters.
可调整大小的群集,自动缩放功能,版本控制,高可用性,群集计划的删除,自定义映像,灵活的VM,组件网关和从分配的Dataproc群集访问笔记本的功能是Dataproc群集行业领先的一些功能。
Cloud Dataproc is one of the best services to run processes. AI Platform is another great option as well. The latest benefit of Cloud Data proc is that with Google Cloud Composer (Apache Airflow), Dataproc clusters can be spun up and spun down in an agile and scalable manner. This becomes a lean process as well as cost decreases and efficiency increases.
Cloud Dataproc是运行流程的最佳服务之一。 AI平台也是另一个不错的选择。 Cloud Data proc的最新优势是,借助Google Cloud Composer(Apache Airflow),可以以敏捷和可扩展的方式启动和关闭Dataproc集群。 这将成为精益流程,同时成本也会降低,效率也会提高。

Google BigQuery(管道) (Google BigQuery (Pipeline))
Notice that BigQuery is being brought in a second time due to its efficiency in setting up analytical pipelines as well
请注意,由于BigQuery同样有效地设置了分析管道,因此第二次引入
Google BigQuery is a fully-managed Data warehousing, auto-scaling and serverless service that works with near real-time analysis of petabyte-scale databases. Data stored within BigQuery should be column-optimized and should be used for analytics more often, archive data should be stored in Google Cloud Storage.
Google BigQuery是一项完全托管的数据仓库,自动扩展和无服务器服务,可对PB级数据库进行近乎实时的分析。 BigQuery中存储的数据应进行列优化,并应更频繁地用于分析,归档数据应存储在Google Cloud Storage中。


The type of data is relevant and affects query performance and speed, and ultimately cost.
数据类型是相关的,并且会影响查询性能和速度,并最终影响成本。
Apache Avro is the type of data that has the best performance and Json are comparatively slower for analytical tasks on BigQuery. This can be used via the Cloud Shell or the Web UI.
Apache Avro是性能最佳的数据类型,而Json在BigQuery上进行分析任务的速度相对较慢。 可以通过Cloud Shell或Web UI使用它。
Google Cloud Composer (Google Cloud Composer)

Google Cloud Composer is a fully managed workflow orchestration service that empowers you to author, schedule, and monitor pipelines that span across clouds and on-premises data centres.
Google Cloud Composer是一项完全托管的工作流程流程服务,可让您编写,计划和监视跨云和本地数据中心的管道。
Built on the popular Apache Airflow open source project and operated using the Python programming language, Cloud Composer is free from lock-in and easy to use.
Cloud Composer建立在广受欢迎的Apache Airflow开源项目上,并使用Python编程语言进行操作,免于锁定且易于使用。
Let me pique your interest. Netflix uses this architecture. It is bleeding edge and extremely scalable.
让我激起您的兴趣。 Netflix使用此架构。 它是前沿技术,具有极强的可扩展性。
你为什么要在乎呢? (Why should you care?)
If you have worked on Ubuntu; bash scripting, the way we schedule tasks are using cron jobs, where we can automate any tasks done manually. If you have worked on Excel, macros are the equivalent what Apache Airflow is capable fo doing, but at a Cloud Level.
如果您曾经在Ubuntu上工作过; bash脚本,我们安排任务的方式是使用cron作业 ,在这里我们可以自动执行任何手动完成的任务。 如果您使用过Excel,则宏等效于Apache Airflow能够执行的功能,但是在云级别。
This level of automation can be mind-boggling. Essentially, you can set up scripts (in python and bash) to pull the latest data from Google Cloud Storage, spin-up a cluster in Google Dataproc, Perform Data Pre-processing, shut-down the cluster, implement a data model on AI Platform and output the result onto BigQuery.
这种自动化水平可能令人难以置信。 本质上,您可以设置脚本(使用python和bash)以从Google Cloud Storage中获取最新数据,在Google Dataproc中启动集群,执行数据预处理,关闭集群,在AI上实现数据模型平台化并将结果输出到BigQuery。
You are a rockstar! Great job on understanding Data Storage and various implementations of Data Flow pipelines on Google Cloud Storage. Now that you’re here, I would suggest you go back up and refresh your memory to see how much you recall.
你是摇滚明星! 在了解数据存储以及Google Cloud Storage上数据流管道的各种实现方面做得非常出色。 现在您在这里,我建议您备份并刷新一下内存,以查看您记得多少。
Let us now proceed to understand how we can leverage the data we have stored and the pipelines we have made.
现在让我们继续了解如何利用已存储的数据和已建立的管道。
Google Cloud Datalab (Google Cloud Datalab)

Google Cloud Datalab is an easy-to-use interactive tool for data exploration, analysis, visualization, and machine learning.
Google Cloud Datalab是一个易于使用的交互式工具,用于数据探索,分析,可视化和机器学习。
Datalab enables powerful data exploration, integrated and open-source, scalable data management and visualization along with Machine learning with lifecycle support.
Datalab支持功能强大的数据探索,集成和开源,可扩展的数据管理和可视化,以及具有生命周期支持的机器学习。
你为什么要在乎呢? (Why should you care?)
As a Data Scientist, this is the equivalent of Jupyter Notebooks, where the data can lie within various components within GCP. You can connect via SSH from the cloud shell and run it via port 8081 (ignore if this does not make sense).
作为数据科学家,这相当于Jupyter笔记本,其中数据可以位于GCP的各个组件中。 您可以从云外壳通过SSH连接并通过端口8081运行它(如果这没有意义,请忽略)。

Cloud Datalab is an online Jupyter Notebook to
Cloud Datalab是一个在线Jupyter Notebook,用于
Google Cloud Dataprep (Google Cloud Dataprep)

Google Cloud Dataprep is an intelligent cloud data service to visually explore, clean, and prepare data for analysis and machine learning.
Google Cloud Dataprep是一项智能的云数据服务,可以直观地探索,清理和准备数据以进行分析和机器学习。
It is a serverless service that enables fast exploration, anomaly detection, easy and powerful data exploration.
它是一项无服务器服务,可实现快速探索,异常检测,轻松强大的数据探索。
Think of Google Cloud Dataprep as a GUI on excel with intelligent suggestions.
可以将Google Cloud Dataprep视为具有智能建议的excel上的GUI。
Google AI平台 (Google AI Platform)

Google AI Platform is a managed service that enables you to easily build machine learning models, that work on any type of data, of any size. The AI Platform lets the user Prepare, Build and Run, Manage and share the machine learning end-to-end cycle for model development.
Google AI Platform是一项托管服务,可让您轻松构建适用于任何大小,任何大小的数据的机器学习模型。 AI平台使用户可以为模型开发准备,构建和运行,管理和共享机器学习端到端周期。

AI Platform is the next generation of Cloud Dataproc.
AI平台是下一代Cloud Dataproc。

AI Platform is a fully managed platform that scales to tens of CPUs/ GPUs/ TPUs where you train your model and automate it.
AI平台是一个完全托管的平台,可扩展到数十个CPU / GPU / TPU,您可以在其中训练模型并使其自动化。
Google Data Studio (Google Data Studio)

It’s simple. Google Data Studio is an online, interactive dashboarding tool with the source lying on GCP. You can synchronize work done by multiple developers on a single platform.
这很简单。 Google Data Studio是一种在线交互式仪表板工具,其源代码位于GCP上。 您可以同步多个开发人员在一个平台上完成的工作。
It is not as advanced as Power BI or Tableau, but, it can get the job done. It is a part of the G Suite and can connect to BigQuery, Cloud SQL, GCS, Google Cloud Spanner etc.
它不如Power BI或Tableau先进,但是可以完成工作。 它是G Suite的一部分,可以连接到BigQuery,Cloud SQL,GCS,Google Cloud Spanner等。
I would recommend you read and re-read the above article a few times to get a hold of The Cloud: Google Cloud Platform. As always, the best way to understand the platform is to deep-drive into the hands-on aspect of Google Cloud Platform. This took a considerable amount of effort, I would appreciate your thoughts and comments if you felt that this helped you in some way. Feel free to reach out to me to discuss further on the application of Data Science on the Cloud.
我建议您阅读并重读上述文章几次,以掌握The Cloud:Google Cloud Platform。 与往常一样,了解该平台的最佳方法是深入研究Google Cloud Platform的动手方面。 这花费了大量的精力,如果您认为这对您有所帮助,我将不胜感激。 欢迎与我联系,进一步讨论数据科学在云上的应用。
So, a little about me. I’m a Data Scientist at a top Data Science firm, currently pursuing my MS in Data Science. I spend a lot of time studying and working. Show me some love if you enjoyed this! 😄 I also write about the millennial lifestyle, consulting, chatbots and finance! If you have any questions or recommendations on this, please feel free to reach out to me on LinkedIn or follow me here, I’d love to hear your thoughts!
所以,关于我的事。 我是一家顶级数据科学公司的数据科学家,目前正在攻读数据科学硕士学位。 我花很多时间学习和工作。 给我一些爱,如果你喜欢这个! also我还写了关于千禧一代的生活方式 , 咨询 , 聊天机器人和财务的文章 ! 如果您对此有任何疑问或建议,请随时在LinkedIn上与我联系或在此处关注我,我很想听听您的想法!
As part of the next steps of this series, I shall be publishing more use-cases as to how we can leverage the Cloud in the real world. Feel Free to follow me and connect with me for more!
作为本系列后续步骤的一部分,我将发布更多关于如何在现实世界中利用云的用例。 随时关注我并与我联系以获取更多!
gcp怎么连接谷歌云盘















 1596
1596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









