





v-on:监听按键事件
Eavesdropping, has nothing to do with the Garden of Eden, or Eve, or.. well you get the picture, since that bad joke is out of the way, let’s focus on Acoustic Eavesdropping.
窃听与伊甸园,夏娃或.....没什么关系,好了,您知道了,因为那个恶作剧已经过去了,让我们专注于声学窃听。
Acoustic Eavesdropping is the process of gathering information/intelligence using sound and has been used in various forms since as long as WWI, or even earlier. The picture above is a device used to listen to the sound of enemy aircraft during WWI as a warning of an air strike, this was the pre-radar era. Gathering intelligence using acoustics is quite widely used and nothing new. So I thought of using it to see if I can predict keystrokes using the sound of a computer keyboard. If you listen closely, you’ll notice that each key makes a slightly different sound. A quick Google search revealed a ton of research, which was promising. So I went about doing it.
一个 coustic窃听是利用声音收集信息/情报的过程中,因为只要一战,甚至更早已经以各种形式使用。 上图是一种设备,用于监听第一次世界大战期间敌机的声音,以警告发生空袭,这是雷达时代之前的时代。 使用声学来收集情报已被广泛使用,并且没有新内容。 因此,我想到了使用它来查看是否可以通过计算机键盘的声音来预测击键。 如果仔细聆听,您会注意到每个按键发出的声音略有不同。 Google的快速搜索显示了大量研究,这是有希望的。 所以我去做。
The basic idea is as follows;
基本思想如下:
- Capture the sound of keystrokes multiple times and build a data set. Since my laziness is one of my many virtues, I only bothered to record 8 keys (a-h) fifteen times each. Why 8 and 15? ¯\_(ツ)_/¯ 捕获多次击键声并建立数据集。 由于我的懒惰是我的许多美德之一,所以我只想每次记录15次8个按键。 为什么是8和15? ¯\ _(ツ)_ /¯
- Create a histogram of the audio clips using python (librosa¹ & matplotlib²). This is a visual representation of the audio file. 使用python(librosa¹和matplotlib²)创建音频片段的直方图。 这是音频文件的直观表示。
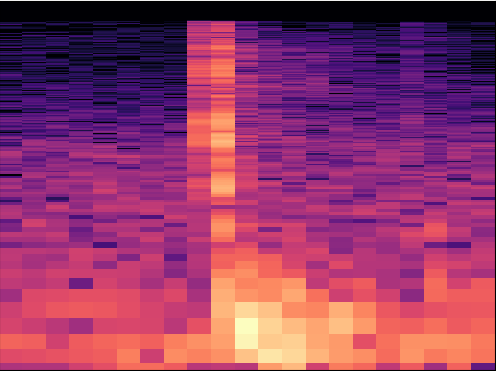
At this point, you have the required information to start training your model. I’ve decided to use Google AutoML Vision, simply because it’s easy. You can follow the AutoML documentation³ to get this part done, the steps in summary are;
此时,您已具有开始训练模型所需的信息。 我决定使用Google AutoML Vision只是因为它很容易。 您可以按照AutoML文档 ³来完成此部分,其摘要步骤为:
- Create a single-label classification dataset, since each image has one object or one character, in this case. 在这种情况下,由于每个图像都有一个对象或一个字符,因此请创建一个单标签分类数据集。
- Upload your images from a storage bucket or directly from your computer. 从存储桶或直接从计算机上载图像。
- Upload a CSV file with the list of images, if each image is used for training, validation or testing and the label for the image. The label in this case is the character associated with the sound. 如果每个图像都用于训练,验证或测试以及图像的标签,请上传包含图像列表的CSV文件。 在这种情况下,标签是与声音关联的字符。
- Train!, I suggest using at least 16 node hours or else the precision would be less. This will take a couple of hours to complete. 训练!,我建议至少使用16个节点小时,否则精度会更低。 这将需要几个小时才能完成。
Once the training is complete, Google is good enough to email you about it and also give you the code needed to test the model. You can also test it online using the web UI. To make sure your model is trained enough, record another keystroke, and convert it to a histogram and test it using the UI before using the code. You’ll be surprised, at least I was.
培训完成后,Google可以很好地向您发送电子邮件,并提供测试模型所需的代码。 您也可以使用Web UI在线对其进行测试。 为了确保模型得到足够的训练,请记录下另一个击键,然后将其转换为直方图,并在使用代码之前使用UI对其进行测试。 你会惊讶的,至少我是。
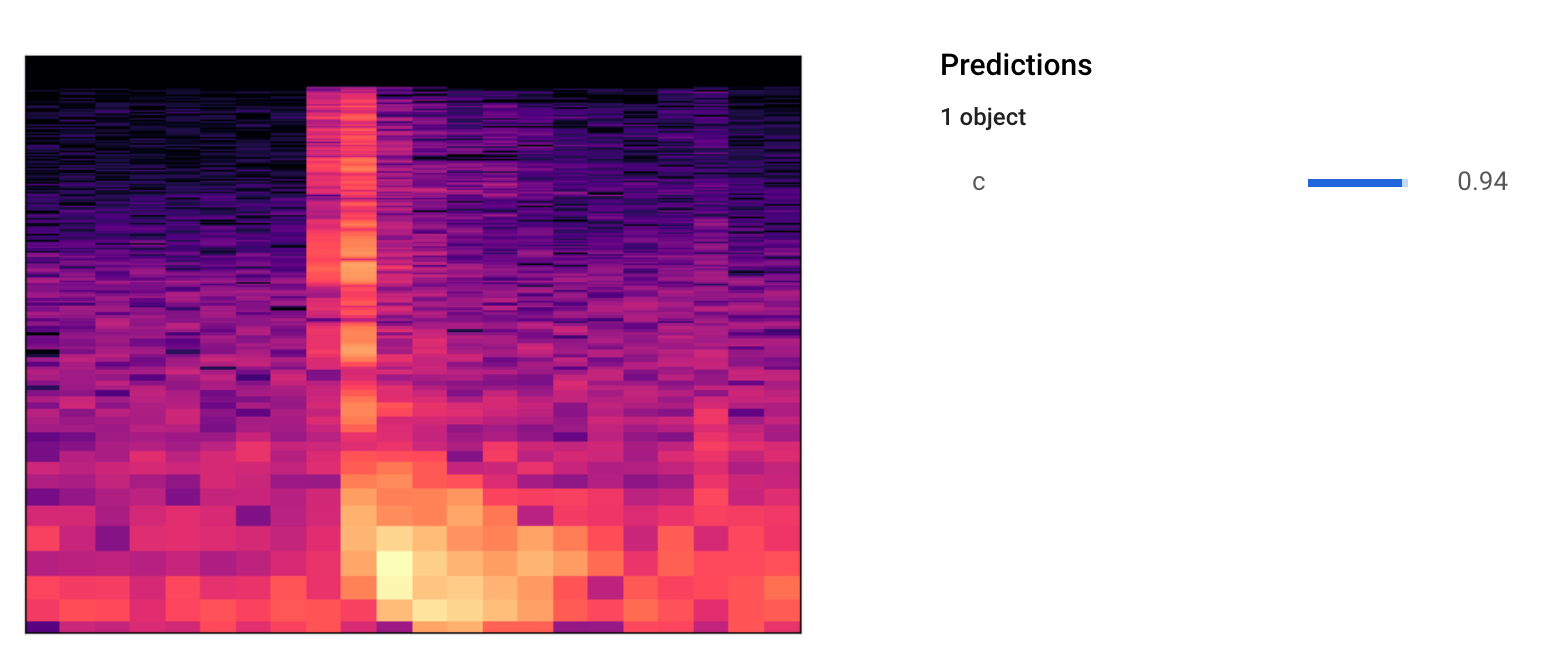
Now to put everything together, and give it a test. I have uploaded the full code on Github⁴, if you want to try it out. This was the result
现在将所有内容放在一起,并进行测试。 如果您想尝试一下,我已经在Github⁴上上传了完整的代码。 这就是结果

As far as an experiment and an initial PoC go, the results were promising. It only takes a couple of hours to hack together something which can guess what you are typing by listening. OK, so it wasn’t perfect, It didn’t recognize some of the characters, but the idea works. If you are guessing a password using a brute force attack, giving part of the password would significantly improve the chance of identifying the password.
就实验和初始PoC而言,结果令人鼓舞。 只需花几个小时就能破解一些东西,这些东西可以通过聆听猜出您正在输入的内容。 好的,所以它并不完美,它不能识别某些字符,但是这个想法可行。 如果您使用蛮力攻击来猜测密码,则提供部分密码将大大提高识别密码的机会。
There are also some things I can do to improve this to make it more accurate. Run noise reduction on the recording to isolate the sound of the keystroke. Also to create a much larger datasets. Google suggests at least having 1000 images per label (not going to happen son!) for better accuracy. And you can take it to the next level by analyzing the typing pattern of each user, next time you type something, be aware of how you type. I’m sure there are some keys you press harder or lighter and the duration between key combinations will be different, i.e. time between a-e and a-i would be different. Now the more observant of you would say, this is not practical, in a normal work environment there’s so much noise, you’ll never capture the sound of a single keystroke. True, I did this experiment in a room with no interference. But if you read enough, you’ll find that the audio can be scrubbed of noise, there are massive datasets that can be used to detect and remove ambient noises like A/C, fan, traffic, etc… So even in a noisy environment, isolating keystrokes is not impossible. The next time you are typing something sensitive, make sure no one is looking at your screen and also that no one is listening.
我还可以做一些事情来改进它,使其更加准确。 对录音进行降噪操作,以隔离按键声音。 还要创建更大的数据集。 Google建议每个标签至少有1000张图片(不会发生!),以提高准确性。 然后,您可以通过分析每个用户的键入模式将其带入一个新的水平,下次您键入内容时,请注意键入的方式。 我敢肯定,有些按键您会用力或更轻,并且按键组合之间的持续时间会有所不同,即AE和AI之间的时间会有所不同。 现在,您更加观察地会说,这是不切实际的,在正常的工作环境中,会有如此多的噪音,您将永远无法捕捉到单个按键的声音。 没错,我在没有干扰的房间里进行了这项实验。 但是,如果您读够了,您会发现音频可以消除噪声,有大量数据集可用于检测和消除A / C,风扇,交通等环境噪声……因此即使在嘈杂的环境中,隔离击键并不是不可能的。 下次输入敏感内容时,请确保没有人看着您的屏幕并且也没有人在听。
But here’s the moral of the story. With technology being the double-edged sword it is, the morality of it falls to the wielder of the sword. And privacy is becoming the square root of minus one. If you look at the recent trends in cybercrime, you’ll notice the attention is moving towards social engineering. The recent Twitter hack is a good example of this. When every aspect of you becomes personally identifiable information (PII), from your fingerprint, your voice, your heartbeat, the way you type, to your posture and behavior itself, Your privacy, is persona non grata, finis!.
但是,这是故事的寓意。 由于技术是双刃剑,因此其道德性就落到了剑的魔咒上。 隐私正成为减一的平方根。 如果您查看网络犯罪的最新趋势,您会注意到注意力正在转向社会工程学。 最近的Twitter黑客就是一个很好的例子。 当您的各个方面成为您的个人身份信息(PII)时,从指纹,声音,心跳,键入方式到姿势和行为本身,以及您的隐私,都是无可厚非的!
P.S. Please note that Python is not my first language, do excuse for the poor quality of work.
PS请注意,Python不是我的母语,请为工作质量差做个借口。
[1] https://pypi.org/project/librosa/
[1] https://pypi.org/project/librosa/
[3] How to guides, Google Cloud, https://cloud.google.com/vision/automl/docs/how-to
[3]指南,Google Cloud, https://cloud.google.com/vision/automl/docs/how-to
v-on:监听按键事件
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









