





v8内部实现
With this blog post, I am starting V8 Deep Dives series dedicated to my experiments and findings in V8, which is, no doubt, a well-engineered and sophisticated software. Hopefully, you will find this blog post valuable and share your ideas for the next topic.
通过此博客文章,我将开始专门针对V8的实验和发现的V8 Deep Dives系列,这无疑是一款精心设计和完善的软件。 希望您会发现此博客文章很有价值,并就下一个主题分享您的想法。
介绍 (Intro)
ECMAScript 2015, also known as ES6, introduced many built-in collections, such as Map, Set, WeakMap, and WeakSet. They appeared to be an excellent addition to the standard JS library and got widely adopted in libraries, applications, and Node.js core. Today we are going to focus on Map collection and try to understand V8 implementation details, as well as make some practical conclusions.
ECMAScript 2015 (也称为ES6)引入了许多内置集合,例如Map,Set,WeakMap和WeakSet。 它们似乎是对标准JS库的出色补充,并在库,应用程序和Node.js核心中被广泛采用。 今天,我们将专注于Map收集,并尝试了解V8的实现细节,并得出一些实际的结论。
The spec does not dictate a precise algorithm used to implement Map support, but instead gives some hints for possible implementations and expected performance characteristics:
该规范并未规定用于实现Map支持的精确算法,而是为可能的实现和预期的性能特征提供了一些提示:
Map object must be implemented using either hash tables or other mechanisms that, on average, provide access times that are sublinear on the number of elements in the collection. The data structures used in this Map objects specification is only intended to describe the required observable semantics of Map objects. It is not intended to be a viable implementation model.
映射对象必须使用哈希表或其他机制来实现,这些机制通常提供的访问时间与集合中元素的数量成线性关系。 本Map对象规范中使用的数据结构仅用于描述Map对象所需的可观察语义。 它并非旨在成为可行的实施模型。
As we see here, the spec leaves a lot of room for each implementer, i.e., JS engine, but does not give a lot of certainty on the exact algorithm, its performance, or memory footprint of the implementation. If your application deals with Maps on its hot path or you store a lot of data in a Map, such details may be certainly of great help.
正如我们在此处看到的,该规范为每个实现者(即JS引擎)留出了很大的空间,但并未对确切的算法,其性能或实现的内存占用量提供很多确定性。 如果您的应用程序在其热路径上处理地图,或者您在地图中存储了大量数据,那么这些详细信息无疑会带来很大的帮助。
As a developer with a Java background, I got used to Java collections, where one can choose between multiple implementations of Map interface and even fine-tune it if the selected class supports that. Moreover, in Java it is always possible to the open source code of any class from the standard library and get familiar with the implementation (which, of course, may change across versions, but only in a more efficient direction). So, that is why I could not stand not to learn how Maps work in V8.
作为具有Java背景的开发人员,我习惯了Java集合,可以在其中选择Map接口的多个实现,甚至在所选类支持的情况下对其进行微调。 此外,在Java中,始终可以从标准库中获取任何类的开放源代码并熟悉其实现(当然,实现可能会在各个版本之间发生变化,但只会朝着更有效的方向发展)。 因此,这就是为什么我不能忍受不学习Maps在V8中的工作方式。
Now, let’s start the dive.
现在,让我们开始潜水。
Disclaimer. What’s written below is implementation details specific to V8 8.4 bundled with a recent dev version of Node.js (commit 238104c to be more precise). You should not expect any behavior beyond the spec.
免责声明 下面写的是特定于V8 8.4的实现细节,它与Node.js的最新开发版本捆绑在一起(更精确地说, 提交238104c )。 您不应期望超出规范的任何行为。
底层算法 (Underlying Algorithm)
First of all, Maps in V8 are built on top of hash tables. The subsequent text assumes that you understand how hash tables work. If you are not familiar with the concept, you should learn it first (e.g., by reading this wiki page) and then return here.
首先,V8中的Maps建立在哈希表之上。 后续文本假定您了解哈希表如何工作。 如果您不熟悉此概念,则应首先学习它(例如,通过阅读Wiki页面 ),然后再返回此处。
If you have substantial experience with Maps, you might already notice a contradiction here. Hash tables do not provide any order guarantees for iteration, while ES6 spec requires implementations to keep the insertion order while iterating over a Map. So, the “classical” algorithm is not suitable for Maps. But it appears that it is still possible to use it with a slight variation.
如果您在Google地图方面有丰富的经验,那么您可能已经注意到这里存在矛盾。 哈希表不为迭代提供任何顺序保证,而ES6规范要求实现在迭代Map时保持插入顺序。 因此,“经典”算法不适用于地图。 但是似乎仍然可以使用它并稍作改动。
V8 uses the so-called deterministic hash tables algorithm proposed by Tyler Close. The following TypeScript-based pseudo-code shows main data structures used by this algorithm:
V8使用Tyler Close提出的所谓的确定性哈希表算法 。 以下基于TypeScript的伪代码显示了此算法使用的主要数据结构:
Here CloseTable interface stands for the hash table. It contains hashTable array, which size is equal to the number of buckets. The Nth element of the array stands for the Nth bucket and holds an index of the bucket’s head element in the dataTable array. In its turn, dataTable array contains entries in the insertion order. Finally, each Entry has chain property, which points to the next entry in the bucket’s chain (or singly linked list, to be more precise).
这里CloseTable接口代表哈希表。 它包含hashTable数组,其大小等于存储桶数。 数组的第N个元素代表第N个存储桶,并在dataTable数组中保存存储桶的head元素的索引。 依次, dataTable数组按插入顺序包含条目。 最后,每个Entry都具有chain属性,该属性指向存储桶链中的下一个条目(或更精确地说,是单链列表)。
Each time when a new entry is inserted into the table, it is stored in the dataTable array under the nextSlot index. This process also requires an update in the chain of the corresponding bucket, so the inserted entry becomes the new tail.
每次将新条目插入表中时,它将存储在nextSlot索引下的dataTable数组中。 此过程还需要更新相应存储桶的链,因此插入的条目将成为新的尾部。
When an entry is deleted from the hash table, it is removed from the dataTable (e.g., by setting both key and value to undefined). Then the previous and the next entries in the chain are updated so that they are linked directly. As you might already notice, this means that all deleted entries still occupy space in the dataTable.
从哈希表中删除条目时,会将其从dataTable删除(例如,通过将key和value都设置为undefined )。 然后更新链中的上一个和下一个条目,以便直接链接它们。 您可能已经注意到,这意味着所有已删除的条目仍然在dataTable占据空间。
As the last piece of the puzzle, when a table gets full of entries (both present and deleted), it needs to be rehashed (rebuilt) with a bigger (or smaller) size.
作为难题的最后一部分,当一个表中充满了所有条目(既存在又删除了)时,需要以更大(或更小)的大小来重新整理(重建)它。
With this approach, iteration over a Map is just a matter of looping through the dataTable. That guarantees the insertion order requirement for iteration. Considering this, I expect most JS engines (if not all of them) to use deterministic hash tables as the building block behind Maps.
使用这种方法,在Map上进行迭代仅是遍历dataTable 。 这保证了迭代的插入顺序要求。 考虑到这一点,我希望大多数JS引擎(如果不是全部)都将确定性哈希表用作Maps的基础。
实践中的算法 (Algorithm in Practice)
Let’s go through more examples to see how the algorithm works. Say, we have a CloseTable with 2 buckets (hashTable.length) and total capacity of 4 (dataTable.length) and the hash table is populated with the following contents:
让我们来看更多示例,以了解算法的工作原理。 假设,我们有一个带有2个存储桶( hashTable.length )且总容量为4( dataTable.length )的CloseTable ,并且该哈希表填充了以下内容:
In this example, the internal table representation can be expressed like the following:
在此示例中,内部表表示可以如下表示:
If we delete an entry by calling table.delete(0), the table turns into this one:
如果我们通过调用table.delete(0)删除一项,则该表将变成这一行:
If we insert two more entries, the hash table will require rehashing. We will discuss this process in more detail a bit later.
如果我们再插入两个条目,则哈希表将需要重新哈希。 我们将在稍后详细讨论此过程。
The same algorithm can be applied to Sets. The only difference is that Set entries do not need value property.
可以将相同的算法应用于集合。 唯一的区别是Set条目不需要value属性。
Now, when we have an understanding of the algorithm behind Maps in V8, we are ready to take a deeper dive.
现在,当我们了解了V8中Maps背后的算法时,我们就可以进行更深入的研究了。
实施细节 (Implementation Details)
The Map implementation in V8 is written in C++ and then exposed to JS code. The main part of it is defined in OrderedHashTable and OrderedHashMap classes. We already learned how these classes work, but if you want to read the code yourself, you may find it here, here, and, finally, here.
V8中的Map实现是用C ++编写的,然后公开给JS代码。 它的主要部分在OrderedHashTable和OrderedHashMap类中定义。 我们已经学习了这些类的工作方式,但是如果您想自己阅读代码,则可以在此处 , 此处以及最后在此处找到 。
As we are focused on the practical details of V8’s Map implementation, we need to understand how table capacity is selected.
当我们专注于V8的Map实现的实际细节时,我们需要了解如何选择表容量。
容量 (Capacity)
In V8, hash table (Map) capacity is always equal to a power of two. As for the load factor, it is a constant equal to 2, which means that max capacity of a table is 2 * number_of_buckets. When you create an empty Map, its internal hash table has 2 buckets. Thus the capacity of such a Map is 4 entries.
在V8中,哈希表(Map)的容量始终等于2的幂。 至于负载系数,它是一个等于2的常数,这意味着表的最大容量为2 * number_of_buckets 。 创建空Map时,其内部哈希表有2个存储桶。 因此,这种映射的容量为4个条目。
There is also a limit for the max capacity. On a 64-bit system that number would be ²²⁷, which means that you can not store more than around 16.7M entries in a Map. This restriction comes from the on-heap representation used for Maps, but we will discuss this aspect a bit later.
最大容量也有限制。 在64位系统上,该数字将为“²”,这意味着您在Map中最多可以存储1670万个条目。 此限制来自于用于Maps的堆上表示形式,但稍后我们将对此方面进行讨论。
Finally, the grow/shrink factor used for rehashing is equal to 2. So, as soon as a Map gets 4 entries, the next insert will lead to a rehashing process where a new hash table of a twice as big (or less) size will be built.
最后,用于重新哈希处理的增长/收缩因子等于2。因此,一旦Map获得4个条目,则下一个插入将导致重新哈希处理,在此过程中,新哈希表的大小将是(或小于)两倍的大小将被建造。
To have a confirmation of what may be seen in the source code, I have modified V8 bundled in Node.js to expose the number of buckets as a custom buckets property available on Maps. You may find the result here. With this custom Node.js build we can run the following script:
为了确认源代码中可能显示的内容,我修改了Node.js中捆绑的V8,以将存储桶数公开为Maps上的自定义buckets属性。 您可以在这里找到结果。 通过此自定义Node.js构建,我们可以运行以下脚本:
The above script simply inserts 100 entries into an empty Map. It produces the following output:
上面的脚本仅将100个条目插入到一个空的Map中。 它产生以下输出:
As we see here, the Map grows as a power of two when map capacity is reached. So, our theory is now confirmed. Now, let’s try to shrink a Map by deleting all items from it:
正如我们在此处看到的,当达到地图容量时,地图以2的幂数增长。 因此,我们的理论现已得到证实。 现在,让我们尝试通过删除地图中的所有项目来缩小地图:
This script produces the following output:
该脚本产生以下输出:
Again, we see that the Map shrinks as a power of two, once there are fewer remaining entries than number_of_buckets / 2.
同样,一旦剩余条目数少于number_of_buckets / 2 ,则Map缩小为2的幂。
散列函数 (Hash Function)
So far, we did not discuss how V8 calculates hash codes for keys stored in Maps, while this is a good topic.
到目前为止,我们尚未讨论V8如何为存储在Maps中的键计算哈希码,但这是一个很好的话题。
For number-like values (Smis and heap numbers, BigInts, and other similar internal stuff), it uses one or another well-known hash function with low collision probability.
对于类似数字的值(Smis和堆数字,BigInts和其他类似的内部对象),它使用一个或另一个众所周知的哈希函数,且冲突概率较低。
For string-like values (strings and symbols), it calculates hash code based on the string contents and then caches it in the internal header.
对于类似字符串的值(字符串和符号),它将根据字符串内容计算哈希码,然后将其缓存在内部标头中。
Finally, for objects, V8 calculates the hash code based on a random number and then caches it in the internal header.
最后,对于对象,V8根据随机数计算哈希码,然后将其缓存在内部标头中。
时间复杂度 (Time Complexity)
Most Map operations, like set or delete, require a lookup. Just like with the “classical” hash table, the lookup has O(1) time complexity.
大多数Map操作(例如set或delete )都需要查找。 就像使用“经典”哈希表一样,查找具有O(1)时间复杂度。
Let’s consider the worst-case when the table has N out of N entries (it is full), all entries belong to a single bucket, and the required entry is located at the tail. In such a scenario, a lookup requires N moves through the chain elements.
让我们考虑最坏的情况,即该表的N个条目中有N个(已满),所有条目都属于一个存储桶,而所需的条目位于尾部。 在这种情况下,查找需要N个通过链元素的移动。
On the other hand, in the best possible scenario when the table is full, but each bucket has 2 entries, a lookup will require up to 2 moves.
另一方面,在表已满但每个存储桶都有2个条目的最佳情况下,查找最多需要2个移动。
It is a well-known fact that while individual operations in hash tables are “cheap”, rehashing is not. Rehashing has O(N) time complexity and requires allocation of the new hash table on the heap. Moreover, rehashing is performed as a part of insertion or deletion operations, when necessary. So, for instance, a map.set() call could be more expensive than you would expect. Luckily, rehashing is a relatively infrequent operation.
众所周知的事实是,虽然哈希表中的各个操作“便宜”,但重新哈希不是。 重新哈希的时间复杂度为O(N),需要在堆上分配新的哈希表。 此外,在必要时,将重新哈希处理作为插入或删除操作的一部分进行。 因此,例如, map.set()调用可能比您预期的要昂贵。 幸运的是,重新哈希处理是相对少见的操作。
内存占用 (Memory Footprint)
Of course, the underlying hash table has to be somehow stored on the heap, in a so-called “backing store”. And here comes another interesting fact. The whole table (and thus, Map) is stored as a single array of fixed length. The array layout may be illustrated with the below diagram.
当然,底层哈希表必须以某种方式存储在堆中,即所谓的“后备存储”中。 这是另一个有趣的事实。 整个表(因此也就是Map)存储为固定长度的单个数组。 下图可以说明阵列的布局。
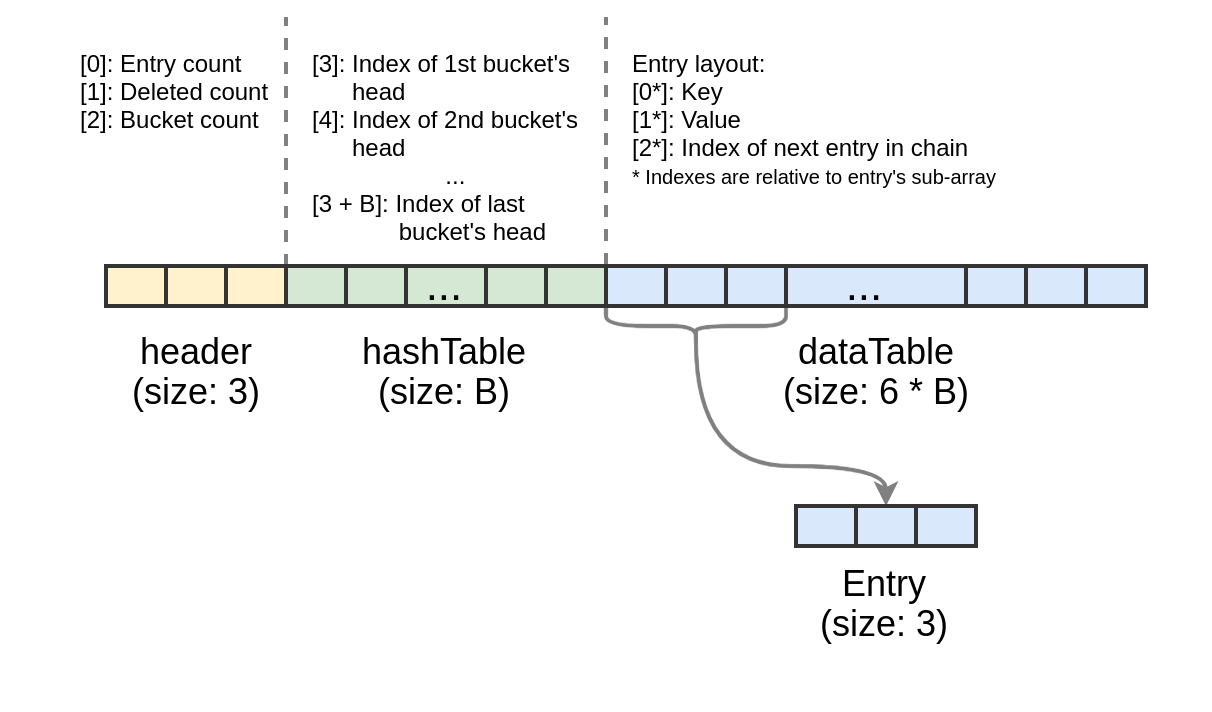
Specific fragments of the backing store array correspond to the header (contains necessary information, like bucket count or deleted entry count), buckets, and entries. Each entry of a bucket chain occupies three elements of the array: one for the key, one for the value, and one for the “pointer” to the next entry in the chain.
后备存储阵列的特定片段对应于标头(包含必要的信息,如存储区计数或已删除的条目计数),存储区和条目。 存储桶链的每个条目占用数组的三个元素:一个用于键,一个用于值,以及一个用于指向链中下一个条目的“指针”。
As for the array size, we can roughly estimate it as N * 3.5, where N is the table capacity. To have an understanding of what it means in terms of memory footprint, let’s assume that we have a 64-bit system, and pointer compression feature of V8 is disabled. In this setup, each array element requires 8 bytes, and a Map with the capacity of ²²⁰ (~1M) should take around 29 MB of heap memory.
至于数组大小,我们可以粗略地估计为N * 3.5 ,其中N是表容量。 为了了解内存占用量的含义,我们假设我们有一个64位系统,并且禁用了V8的指针压缩功能。 在此设置中,每个数组元素需要8个字节,容量为²²(〜1M)的Map应该占用大约29 MB的堆内存。
摘要 (Summary)
Gosh, that was a long journey. To wraps things up, here is a shortlist of what we have learned about Maps in V8:
天哪,那是一段漫长的旅程。 总结一下,这是我们在V8中了解到的Map的简短列表:
- V8 uses deterministic hash table algorithm to implement Maps, and it is very likely that other JS engines do so. V8使用确定性哈希表算法来实现Maps,其他JS引擎也很可能这样做。
- Maps are implemented in C++ and exposed via JS API. 地图以C ++实现,并通过JS API公开。
- Just like with “classical” hash maps, lookups required for Map operations are O(1) and rehashing is O(N). 就像使用“经典”哈希映射一样,映射操作所需的查找为O(1),重新哈希为O(N)。
- On a 64-bit system, when pointer compression is disabled, a Map with 1M entries occupies ~29 MB on the heap. 在64位系统上,如果禁用指针压缩,则具有1M条目的Map会在堆上占用约29 MB。
- Most of the things described in this blog post can also be applied to Sets. 本博客文章中描述的大多数内容也可以应用于Set。
That’s it for this time. Please share your ideas for the next V8 Deep Dive.
这次就是这样。 请分享您对下一个V8深潜的想法。
翻译自: https://itnext.io/v8-deep-dives-understanding-map-internals-45eb94a183df
v8内部实现















 738
738











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









