



 本文介绍了如何从OpenAI的Glow模型中生成COCO数据集格式的示例,帮助理解数据集的构建过程。
本文介绍了如何从OpenAI的Glow模型中生成COCO数据集格式的示例,帮助理解数据集的构建过程。
coco数据集格式示例
I recently started a new newsletter focus on AI education. TheSequence is a no-BS( meaning no hype, no news etc) AI-focused newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers and concepts. Please give it a try by subscribing below:
我最近开始了一份有关AI教育的新时事通讯。 TheSequence是无BS(意味着没有炒作,没有新闻等),它是专注于AI的新闻通讯,需要5分钟的阅读时间。 目标是让您了解机器学习项目,研究论文和概念的最新动态。 请通过以下订阅尝试一下:
Since the early days of machine learning, artificial intelligence scenarios have faced with two big challenges in order to experience mainstream adoption. First, we have the data efficiency problem that requires machine or deep learning models to be trained using large and accurate datasets which, as we know, are really expensive to build and maintain. Secondly, we have the generalization problem which AI agents face in order to build new knowledge that is different from the training data. Humans, by contrast, are incredibly efficient learning with minimum supervision and rapidly generalizing knowledge from a few data examples.
从机器学习的早期开始,人工智能场景就面临两个重大挑战,以体验主流应用。 首先,我们存在数据效率问题,这要求使用大型且准确的数据集来训练机器或深度学习模型,而众所周知,这些数据集的构建和维护成本确实很高。 其次,为了建立不同于训练数据的新知识,我们遇到了AI代理面临的泛化问题。 相比之下,人类在最小的监督下获得了令人难以置信的高效学习,并且从一些数据示例中快速总结了知识。
Generative models are one of the deep learning disciplines that focuses on addressing the two challenges mentioned above. Conceptually, generative models are focused on observing an initial dataset, like a set of pictures, and try to learn how the data was generated. Using more mathematical terms, generative models try to infer all dependencies within very high-dimensional input data, usually specified in the form of a full joint probability distribution. Entire deep learning areas such as speech synthesis or semi-supervised learning are based on generative models. Recently, generative models such as generative adversarial networks(GANs) have become extremely popular within the deep learning community. Recently, OpenAI experimented with a not-very well-known technique called Flow-Based Generative Models in order to improve over existing methods. The result was the creation of Glow, a new flow-based generative model that is able to generate high quality datasets from a few training examples. The findings were captured in a recent research paper as well as an open source release in Github. You can see Glow in action in the following animation:
生成模型是专注于解决上述两个挑战的深度学习学科之一。 从概念上讲,生成模型侧重于观察初始数据集(例如一组图片),并尝试了解数据是如何生成的。 生成模型使用更多的数学术语来尝试推断超高维输入数据中的所有依赖关系,这些数据通常以完整联合概率分布的形式指定。 整个深度学习领域(例如语音合成或半监督学习)都基于生成模型。 近年来,诸如生成对抗网络(GAN)之类的生成模型在深度学习社区中变得极为流行。 最近,OpenAI尝试了一种不太鲜为人知的技术,称为“基于流的生成模型”,以改进现有方法。 结果就是创建了Glow,这是一个基于流程的新生成模型,该模型能够从一些训练示例中生成高质量的数据集。 最新的研究论文以及Github中的开源版本都记录了这些发现。 您可以在以下动画中看到“发光”:
For some unexplainable reason, flow-based generative models have not been as popular as some of its counterparts like GANs. However, this type of techniques offers some tangible advantages compared to alternatives:
由于某些无法解释的原因,基于流的生成模型没有像GANs这样的同类模型流行。 但是,与替代方法相比,这种技术提供了一些明显的优势:
Exact latent-variable inference and log-likelihood evaluation: Most generative methods are only able to approximate the value of the latent variables that correspond to a data point. Others like GAN’s have no encoder at all to infer the latents. In reversible generative models, this can be done exactly without approximation. Not only does this lead to accurate inference, it also enables optimization of the exact log-likelihood of the data, instead of a lower bound of it.
精确的潜在变量推论和对数似然评估:大多数生成方法仅能够近似与数据点相对应的潜在变量的值。 其他诸如GAN的编码器根本没有任何编码器来推断潜伏性。 在可逆的生成模型中,这可以精确地完成而无需近似。 这不仅可以导致准确的推断,还可以优化数据的精确对数似然性,而不是对其下限进行优化。
Efficient inference and efficient synthesis: Flow-based generative models like Glow (and RealNVP) are efficient to parallelize for both inference and synthesis.
高效的推理和高效的综合: Glow(和RealNVP)等基于流的生成模型可以高效地并行化推理和综合。
Significant potential for memory savings: Computing gradients in reversible neural networks requires an amount of memory that is constant instead of linear in their depth as many other generative models like GANs.
节省内存的巨大潜力:可逆神经网络中的梯度计算需要一定数量的内存,而不是像许多其他生成模型(如GAN)那样,其内存深度是恒定的,而不是线性的。
发光建筑 (Glow Architecture)
The architecture of OpenAI Glow builds up on previous work such as NICE and RealNVP but it simplifies those models quite a bit. The Glow model consists of a series of steps combined in a multi-scale architecture. Each step is based on three laeyers: actnorm, followed by an invertible 1x1 convolution followed by a coupling layer.
OpenAI Glow的体系结构建立在以前的工作(例如NICE和RealNVP)的基础上,但它大大简化了这些模型。 Glow模型由一系列步骤组成,这些步骤组合成一个多尺度体系结构。 每个步骤都基于三个层:actnorm,然后是可逆的1x1卷积,然后是耦合层。
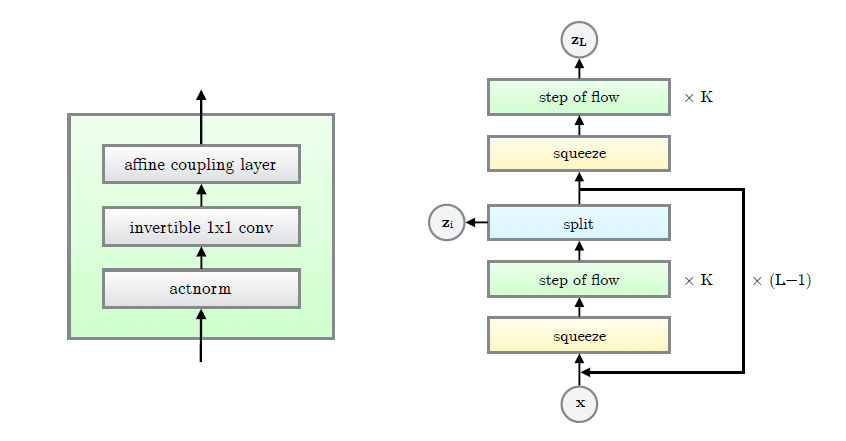
Given an input dataset, the multi-layer architecture of Glow performs the following tasks.
给定一个输入数据集,Glow的多层体系结构将执行以下任务。
- Permute the inputs by reversing their ordering across the channel dimension. 通过在通道维度上颠倒输入顺序来排列输入。
- Split the input into two parts, A and B, down the middle of the feature dimension. 在要素维的中间向下将输入分为A和B两部分。
- Feed A into a shallow convolutional neural network. Linearly transform B according to the output of the neural network. 将A馈入浅层卷积神经网络。 根据神经网络的输出对B进行线性变换。
- Concatenate A and B. 连接A和B。
发光的行动 (Glow in Action)
OpenAI performed a series of quantitive and qualitative experiments to evaluate the capabilities of Glow and some of the results are breathtaking. For instance, Glow was able to generate high resolution images using a predictable and stable performance.
OpenAI进行了一系列定量和定性实验,以评估Glow的功能,其中一些结果令人叹为观止。 例如,Glow能够使用可预测的稳定性能生成高分辨率图像。
Even more interesting is the fact that Glow learns individual features of images such as hair color or factions of the nose. Glow uses an encoder model to interpolate those individual features and generate new related images.
更有趣的是,Glow学习图像的各个特征,例如头发的颜色或鼻子的派系。 Glow使用编码器模型对那些单独的特征进行插值并生成新的相关图像。
The research behind Glow shows that flow-based methods have a lot to contribute to the space of generative models. Just like alternatives like GANs, flow-based methods can be a key block when building deep learning models that can learn from small datasets and generalize efficiently.
Glow背后的研究表明,基于流的方法对生成模型的空间有很大贡献。 就像GAN等替代方法一样,基于流的方法可能是构建可从小型数据集学习并有效推广的深度学习模型的关键要素。
coco数据集格式示例


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}