





 本文探讨了在强化学习中,折扣率作为一个重要的概念,如何影响学习过程和长期奖励的权衡。通过调整折扣率,可以对短期和长期的回报进行不同程度的惩罚,从而影响智能体的行为策略。
本文探讨了在强化学习中,折扣率作为一个重要的概念,如何影响学习过程和长期奖励的权衡。通过调整折扣率,可以对短期和长期的回报进行不同程度的惩罚,从而影响智能体的行为策略。
强化学习 折扣率
This post deals with the key parameter I found as a high influence: the discount factor. It discusses the time-based penalization to achieve better performances, where discount factor is modified accordingly.
这篇文章处理了我发现有很大影响力的关键参数:折扣系数。 它讨论了基于时间的惩罚以实现更好的性能,在此基础上对折现因子进行了相应的修改。
I assume that if you land on this post, you are already familiar with the RL terminology. If it is not the case, then I highly recommend these blogs which provide a great background, before you continue: Intro1 and Intro2.
我认为,如果您登陆这篇文章,您已经熟悉RL术语。 如果不是这种情况,那么在继续之前,我强烈建议您提供这些博客,它们提供了很好的背景知识: Intro1和Intro2 。
折扣因子在RL中起什么作用? (What is the role of the discount factor in RL?)
The discount factor, 𝛾, is a real value ∈ [0, 1], cares for the rewards agent achieved in the past, present, and future. In different words, it relates the rewards to the time domain. Let’s explore the two following cases:
折扣因子,γ,是实值∈[0,1],对于奖励剂在过去,现在和未来的实现的忧虑。 换句话说,它将奖励与时域相关。 让我们研究以下两种情况:
If 𝛾 = 0, the agent cares for his first reward only.
如果𝛾 = 0,则代理仅关心其第一笔报酬。
If 𝛾 = 1, the agent cares for all future rewards.
如果𝛾 = 1,则代理将照顾所有将来的奖励。
Generally, the designer should predefine the discount factor for the scenario episode. This might raise many stability problems and can be ended without achieving the desired goal. However, by exploring some parameters many problems can be solved with converged solutions. For further reading on the discount factor and the rule of thumb for selecting it for robotics applications, I recommend reading: resource3.
通常,设计人员应为场景情节预定义折扣因子。 这可能会引起许多稳定性问题,并且可能在未达到预期目标的情况下结束。 但是,通过探索一些参数,可以用收敛解解决许多问题。 为了进一步阅读折扣因子以及为机器人应用选择它的经验法则,我建议阅读: resource3 。
为什么要惩罚它? (Why penalize it?)
Once the designer chooses the discount factor, it is uniform for the entire scenario, which is not the optimal case for continuous-discrete problems (and more, but let’s focus on this). Robotic dynamic is a continuous process, that we observe through various noisy sensors and by processing its information in a discrete manner (computers after all…). So, we solve a continuous problem by using discrete tools. As such numerical errors are involved. Moreover, the various sensors are corrupted with their noise which adds built-in errors. Lastly, the dynamic model we assumed (for example the states we define) is also suffering from uncertainty and includes additional errors.
一旦设计人员选择了折现率,它就适用于整个情况,这并不是连续离散问题(更多,但让我们关注这一点)的最佳方案。 机器人动力学是一个连续的过程,我们通过各种噪声传感器并以离散方式(毕竟是计算机……)处理其信息来进行观察。 因此,我们使用离散工具解决了一个连续的问题。 因此,涉及数字误差。 此外,各种传感器的噪声会损坏这些噪声,从而增加了内置错误。 最后,我们假设的动态模型(例如,我们定义的状态)也遭受不确定性的影响,并包含其他误差。
Hence, by assuming a uniform discount factor we assume a uniform behavior of these error sources, which are non-uniform-behaviors. Compensating for these issues can be done by penalizing the discount factor and weigh the achieved rewards accordingly.
因此,通过假设一个统一的折现因子,我们假设这些误差源的行为是统一的,它们是不统一的。 可以通过对折现系数进行惩罚并相应地权衡所获得的回报来补偿这些问题。
关于采样时间的惩罚 (Penalizing with respect to the sampling time)
One common way to penalize the discount factor with respect to the sampling time (defined as the elapsed time between two successive measurements) is explained with the following example:
以下示例说明了一种相对于采样时间(定义为两次连续测量之间的经过时间)惩罚折现因子的常见方法:
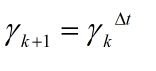
As the sampling interval is small, the discount goes to 1 — in the limit, (thanks to Or Rivlin for the correction), and when the sampling interval is large, such that a long time passes between two successive measurements, the sampling interval is changed accordingly. Remember, the discount factor lies between 0 and 1, so a large sampling interval is translated to a small discount factor (and vice versa). The formula to update the discount factor is just a suggestion to demonstrate the idea, as many other forms can be adapted.
由于采样间隔较小,因此折扣为1(在限制范围内)(感谢Or Rivlin进行校正),并且当采样间隔较大时(如两次连续测量之间经过很长时间),采样间隔为相应地进行了更改。 请记住,折扣系数介于0和1之间,因此较大的采样间隔会转换为较小的折扣系数(反之亦然)。 更新折现系数的公式只是一个证明这一想法的建议,因为可以修改许多其他形式。
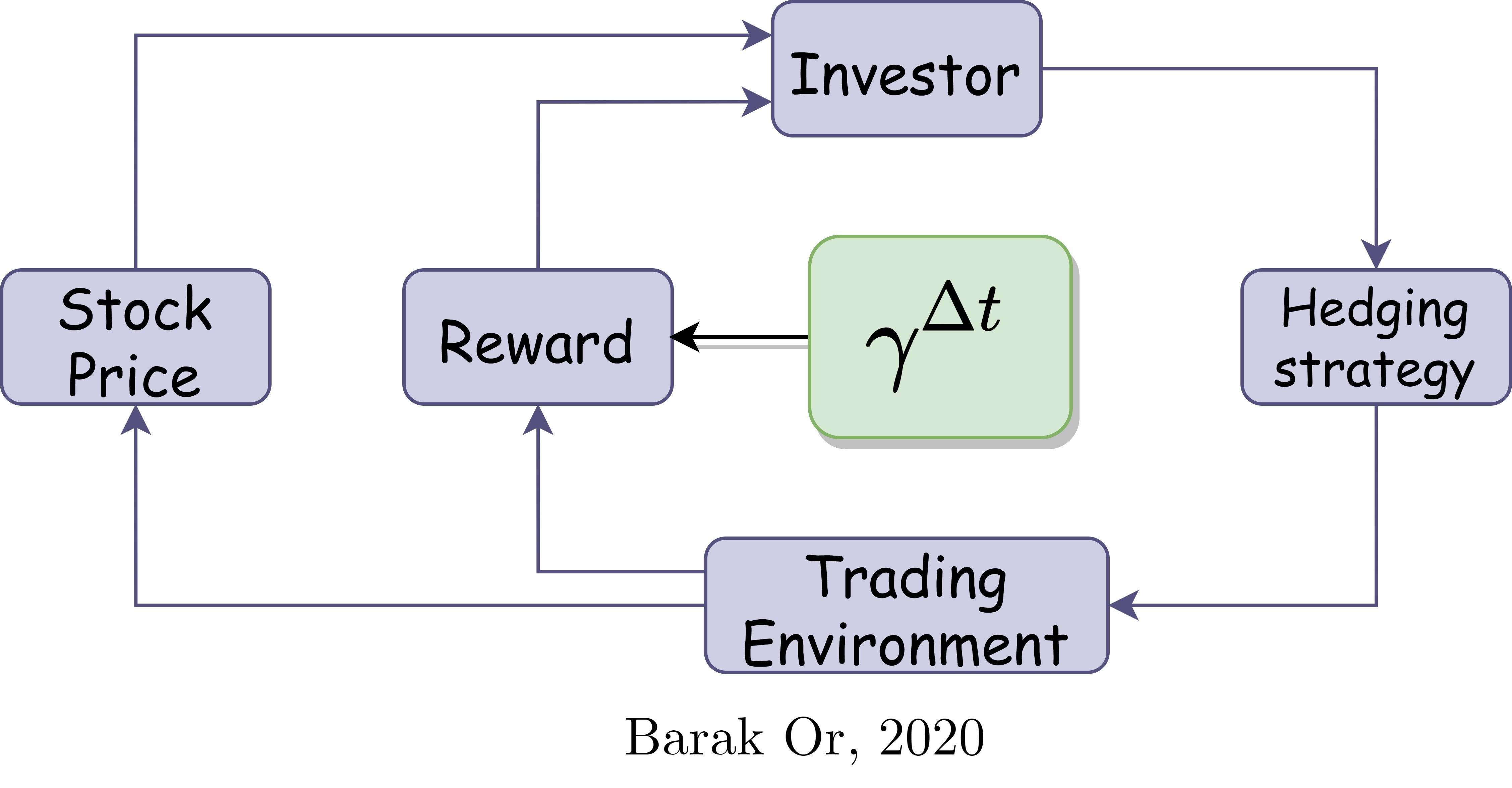
一个Algotrding的例子 (An Algotrding example)
Consider an Algo-trading scenario where the investor (agent) controls his hedging strategy (actions) in the trading market (environment), where the stock prices (states) are changed via time. If a long time passes since the occurrence of the latest investment, the reward cannot be modeled the same, as many changes might happen during that time. Hence, a modified discount factor might lead to better performance, as it cares about the passed time between the events.
考虑一个算法交易场景,其中投资者(代理人)控制着他在交易市场(环境)中的对冲策略(行动),其中股价(状态)随时间变化。 如果自最近一次投资发生以来已经过了很长一段时间,则奖励无法以相同的方式建模,因为在此期间可能会发生许多变化。 因此,修改后的折扣系数可能会导致更好的性能,因为它关心事件之间的经过时间。
That's it…hope you enjoyed reading this post! please feel free to reach me out for further questions/discussion,
就是这样...希望您喜欢阅读本文! 请随时与我联系以提出进一步的问题/讨论,
Barak
巴拉克
翻译自: https://towardsdatascience.com/penalizing-the-discount-factor-in-reinforcement-learning-d672e3a38ffe
强化学习 折扣率

















 426
426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









