





Today, we will discuss an unorthodox paper by NVIDIA Labs on Vehicle Re Identification.
今天,我们将讨论NVIDIA Labs关于车辆再识别的非常规论文。
I would like to point out that the paper doesn’t propose a novel research idea instead present an interesting engineering approach to solve vehicle re-identification problem.
我想指出的是,本文并未提出新颖的研究思路,而是提出了一种解决车辆重新识别问题的有趣的工程方法。
Let’s jump right in.
让我们跳进去。
目录 (Table Of Contents)
- Introduction 介绍
- Novel Contributions 新颖的贡献
- Literature Review 文献评论
- Approach 方法
- Dataset 数据集
- Results 结果
- Code 码
- Conclusion 结论
介绍 (Introduction)
The paper attempts to solve a long standing problem of vehicle re-identification.
本文试图解决长期存在的车辆重新识别问题。
What is vehicle re-identification? Why is it required?
什么是车辆重新识别? 为什么需要它?
Consider vehicle re-identification as facial recognition problem except it is for vehicles. You see a vehicle and then look for a similar vehicle in database and say whether you got a match or not.
将车辆重新识别视为面部识别问题,除了针对车辆。 您看到一辆汽车,然后在数据库中寻找相似的汽车,然后说出是否有匹配项。
There are plethora of applications in vehicle ReID(re-identification) space like matching vehicles in entry and exit of parking lots, automatic toll collection, criminal investigations, traffic control etc.
在车辆ReID(重新识别)空间中有大量应用,例如在停车场的出入口匹配车辆,自动收费,刑事调查,交通控制等。
What are different challenges faced by researchers while solving vehicle re-id problem?
研究人员在解决车辆re-id问题时面临哪些不同挑战?
Vehicle ReID is an open research problem with many researchers working extremely hard to devise new algorithms to solve it. However, there are many challenges to address to overcome them in diverse situations.
Vehicle ReID是一个开放的研究问题,许多研究人员非常努力地设计新的算法来解决它。 但是,在多种情况下要克服这些挑战有很多挑战。
Challenges:-
挑战:
- high intra-class variability (caused by the dependency of shape and appearance on viewpoint), and 类内变异性高(由形状和外观对视点的依赖性引起),以及
- small inter-class variability (caused by the similarity in shape and appearance between vehicles produced by different manufacturers).[1] 组间差异小(由不同制造商生产的车辆在形状和外观上相似)引起。[1]
- Due to limited number of colour options and cars in any particular region, matching poses a problem as they might look similar but, are different. 由于在任何特定区域中颜色选项和汽车的数量有限,匹配会带来问题,因为它们看上去很相似,但有所不同。
Despite these challenges, there has been great research work in past couple of years to effectively tackle the problem at scale.
尽管存在这些挑战,但过去几年中仍在进行大量研究以有效地大规模解决该问题。
Why can’t we use license plates to match vehicles?
为什么我们不能使用车牌来匹配车辆?
In many scenarios, the camera viewpoints or low resolution are not suitable to read lp’s. For eg : cctv cameras are placed at an oblique angle on street lights. In such cases, we need a matching mechanism that uses unique car features like colour, headlights, bonet etc. Hence, vehicle re-identification comes into picture
在许多情况下,摄像机视点或低分辨率都不适合读取lp。 例如:闭路电视摄像机倾斜放置在路灯上。 在这种情况下,我们需要一种匹配机制,该机制需要使用独特的汽车功能,例如颜色,前灯,骨头等。因此,重新识别车辆成为现实
新颖贡献 (Novel Contribution)
The authors point out that person ReID problem has seen tremendous advancements as compared to vehicle ReID due to largely available annotated person data.
作者指出,由于具有大量可用注释的人数据,与车辆ReID相比,人ReID问题已取得了巨大进步。
To recognize a vehicle with another, authors identify few cues that are distinguishable across different vehicles. The authors believe that the key to vehicle ReID is to exploit viewpoint-invariant information such as color, type, and deformable shape models encoding pose.[1]
为了识别其他车辆,作者识别出在不同车辆之间可区别的线索。 作者认为,车辆ReID的关键是利用视点不变的信息,例如颜色 , 类型和编码姿态的可变形形状模型。[1]
In this work, the authors propose a novel framework named PAMTRI, for Pose-Aware Multi-Task Re-Identification.
在这项工作中,作者提出了一个名为PAMTRI的新颖框架,用于识别姿势的多任务重新识别 。
1. PAMTRI embeds keypoints, heatmaps and segments from pose estimation into the multi-task learning pipeline for vehicle ReID, to guide the network to pay attention to viewpoint-related information. [1]
1. PAMTRI将姿势估计的关键点 , 热图和片段嵌入到车辆ReID的多任务学习管道中,以指导网络注意与视点相关的信息。 [1]
2. PAMTRI is trained with large-scale synthetic data that include randomized vehicle models, color and orientation under different backgrounds, lighting conditions and occlusion. Annotations of vehicle identity, color, type and 2D pose are automatically generated for training.The dataset is created using unity engine. [1
2. PAMTRI被训练与包括随机车辆模型 ,在不同的背景结肠 r和取向 ,照明条件和闭塞大规模合成数据 。 车辆身份,颜色,类型和2D姿态的注释会自动生成以进行训练。使用统一引擎创建数据集。 [1
3. Our proposed method achieves significant improvement over the state-of-the-art on two mainstream benchmarks: VeRi and CityFlow-ReID . [1]
3.我们提出的方法在两个主流基准( VeRi和CityFlow-ReID)上比现有技术有了显着改进。 [1]
Additional experiments validate that the unique architecture exploiting explicit pose information, along with use of randomized synthetic data for training, are key to the method’s state of the art results.
额外的实验证明,利用显式姿态信息的独特体系结构以及将随机合成数据用于训练是该方法最新技术成果的关键。
文献评论 (Literature Review)
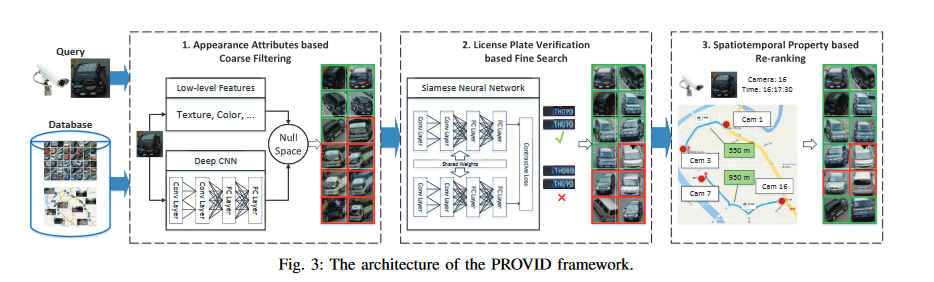
The first well known approach for solving vehicle re-identification was given by PROVID: Progressive and Multimodal Vehicle Reidentification for Large-Scale Urban Surveillance paper.
PROVID提供了解决车辆重新识别的第一种众所周知的方法:大型城市监视的渐进式和多模式车辆重新识别 纸。
The paper showcased the concept of using contrastive loss for training a siamese neural network.
该论文展示了使用对比损失训练暹罗神经网络的概念。
They also introduced the VeRi dataset (first large scale dataset for vehicle reid)
他们还介绍了VeRi数据集(第一个用于车辆残渣的大规模数据集)
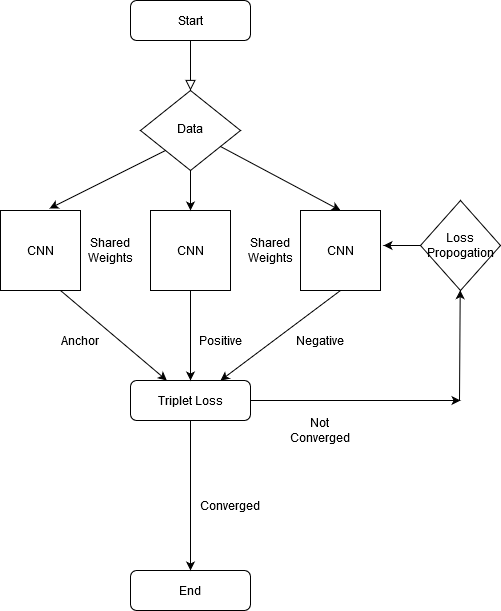
Furthermore, In defense of the triplet loss for person re-identification extends the idea of popular triplet loss to the vehicle ReID task.
此外, 为防止人员重新识别的三元组丢失 ,将流行的三元组丢失概念扩展到了车辆ReID任务。
Other approaches tried to focus on multi viewpoint invariant features (multi camera target tracking).
其他方法尝试着重于多视点不变特征(多摄像机目标跟踪)。
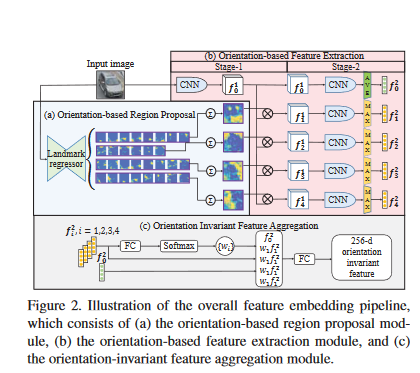
Orientation Invariant Feature Embedding and Spatial Temporal Regularization for Vehicle Re-identification embeds local region features from extracted vehicle key-points for training with cross-entropy loss.[1]
车辆重新识别的方向不变特征嵌入和时空正则化嵌入了从提取的车辆关键点提取的局部区域特征,用于交叉熵损失训练。[1]
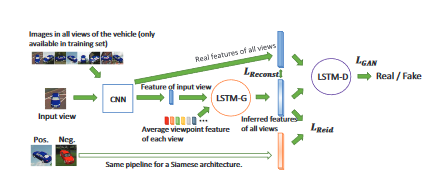
Vehicle Re-identification by Adversarial Bi-directional LSTM Network use a generative adversarial network (GAN) to generate multi view features to be selected by a viewpoint-aware attention model. [1]
通过对抗性双向LSTM网络进行的车辆重新识别使用生成性对抗性网络(GAN)生成多视图特征,以通过可感知点的注意力模型进行选择。 [1]
方法 (Approach)
The authors have taken a multi task learning method to solve the vehicle re-id problem. They use different cues like viewpoint information(pose), type(eg : sedan) and color (eg : blue) to create a strong and distinct vehicle representation.
作者采用了一种多任务学习方法来解决车辆重新识别问题。 他们使用不同的线索,例如视点信息(姿势),类型(例如轿车)和颜色(例如蓝色)来创建强烈而独特的车辆表示形式 。
Three main pillars to the approach presented in the paper are
本文介绍的方法的三个主要Struts是
Synthetic Data Generation
综合数据生成
It is highly unfeasible to annotate 36 keypoint structure for car images given the time and effort constraint to get a decent quantity of dataset. Hence, the authors generated a synthetic dataset.
给定时间和精力约束来获得可观数量的数据集,为汽车图像注释36个关键点结构是非常不可行的。 因此,作者生成了一个综合数据集。
A popular approach to overcome the so-called reality gap is domain randomization , in which a model is trained with extreme visual variety so that when presented with a real-world image the model treats it as just another variation.[1]
克服所谓的现实鸿沟的一种流行方法是域随机化,该模型在训练模型时具有极大的视觉多样性,因此当呈现真实世界的图像时,模型会将其视为另一种变化。[1]
Synthetic data, if generated as per the context, can give considerable boost to the accuracy of the model.
如果根据上下文生成综合数据,则可以大大提高模型的准确性。
Entire process of how the synthetic data is generated is mentioned in 3.1 section of the paper. I am skipping this part as I feel there are too many unnecessary details which might derail the focus from the main approach.
本文第3.1节提到了如何生成综合数据的整个过程。 我跳过了这一部分,因为我觉得有太多不必要的细节可能会使重点偏离主要方法。
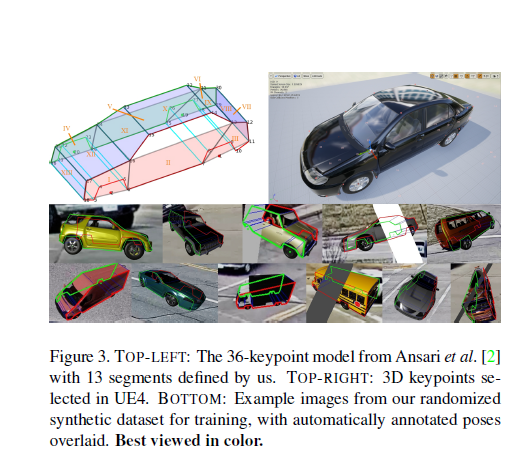
There are 36 keypoints and 13 segments per vehicle. Each segment a particular portion of vehicle like windshield, bottom, side glass etc.
每辆车有36个关键点和13个细分 。 每个部分都划分为车辆的特定部分,例如挡风玻璃,底部,侧玻璃等。
Vehicle Pose Estimation
车辆姿势估计
The idea behind doing the pose estimation is to get relevant viewpoint information of the vehicle during matching. Especially, during multi camera matching where the viewpoint can be quite different, the intersecting pose points can help.
进行姿势估计的思想是在匹配过程中获取车辆的相关视点信息。 特别是在多摄像机匹配中,视点可能会完全不同,相交的姿势点会有所帮助。
The training is done using the synthetic data.
训练是使用综合数据完成的。
Instead of explicitly locating keypoint coordinates, the pose estimation network is trained for estimating response maps only, and semantic attributes are not exploited in their framework.
代替显式地定位关键点坐标,训练了姿势估计网络仅用于估计响应图 ,并且在其框架中未利用语义属性。
The architecture design choice for the pose estimation network is HRNet instead of the stacked hourglass network. The reason behind exclusion of stacked hourglass type of architecture is because of it’s unilateral pathway from low to high resolution whereas the HRNet maintains high-resolution representations and gradually add high-to-low resolution sub-networks with multi-scale fusion.
姿势估计网络的体系结构设计选择是HRNet,而不是堆叠的沙漏网络。 排除堆叠沙漏式架构的原因是因为它是从低分辨率到高分辨率的单边路径,而HRNet保持高分辨率表示并逐渐添加具有多尺度融合的高分辨率到低分辨率子网。
As a result, the predicted keypoints and heatmaps are more accurate and spatially more precise, which benefit our embedding for multi-task learning.[1]
结果,预测的关键点和热图更加准确,空间上也更加精确,这有利于我们在多任务学习中的嵌入。[1]
The authors present two approaches to account for viewpoint information from pose estimation network
作者提出了两种解决姿态估计网络中视点信息的方法
In one approach, after the final deconvolutional layer, we extract the 36 heatmaps for each of the keypoints used to capture the vehicle shape and pose.
在一种方法中,在最后的反卷积层之后,我们为用于捕获车辆形状和姿态的每个关键点提取了36个热图。
In the other approach, the predicted keypoint coordinates from the finalfully-connected (FC) layer are used to segment the vehicle body. There are predefined 13 segmentation masks based on keypoint information. If a certain keypoint is not visible, then the segment is set to blank.
在另一种方法中,来自最终连接(FC)层的预测关键点坐标用于分割车身。 基于关键点信息,预定义了13个细分掩码。 如果某个关键点不可见,则该段设置为空白。
The feedback of heatmaps or segments from the pose estimation network is then scaled and appended to the original RGB channels for further processing.
然后缩放来自姿态估计网络的热图或片段的反馈,并将其附加到原始RGB通道中,以进行进一步处理。
Multi Task Learning for ReID
ReID的多任务学习
Pose-aware representations are beneficial to both ReID and attribute classification tasks.
姿势感知表示形式对ReID和属性分类任务均有利。
Vehicle pose describes the 3D shape model that is invariant to the camera
车辆姿态描述了相机不变的3D形状模型
Vehicle pose describes the 3D shape model that is invariant to the cameraviewpoint, and thus the ReID sub-branch can learn to relate features from different views.
车辆姿态描述了不会改变相机视点的3D形状模型,因此ReID子分支可以学习从不同视图关联特征。
Second, the vehicle shape is directly connected with the car type to which the target belongs.
其次,车辆形状与目标所属的汽车类型直接相关。
Third, the segments by 2D keypoints enable the color classification sub-branch to extract the main vehicle color while neglecting the non-painted areas such as windshields and wheels.
第三,按2D关键点划分的分段使颜色分类子分支能够提取主要的汽车颜色,而忽略诸如挡风玻璃和车轮之类的未上漆区域。
The end goal is to create a strong vehicle representation using color, type and pose information that can be used for vehicle re-identification
最终目标是使用颜色,类型和姿势信息创建可用于车辆重新识别的强大车辆表示
建筑信息 (Architecture Information)
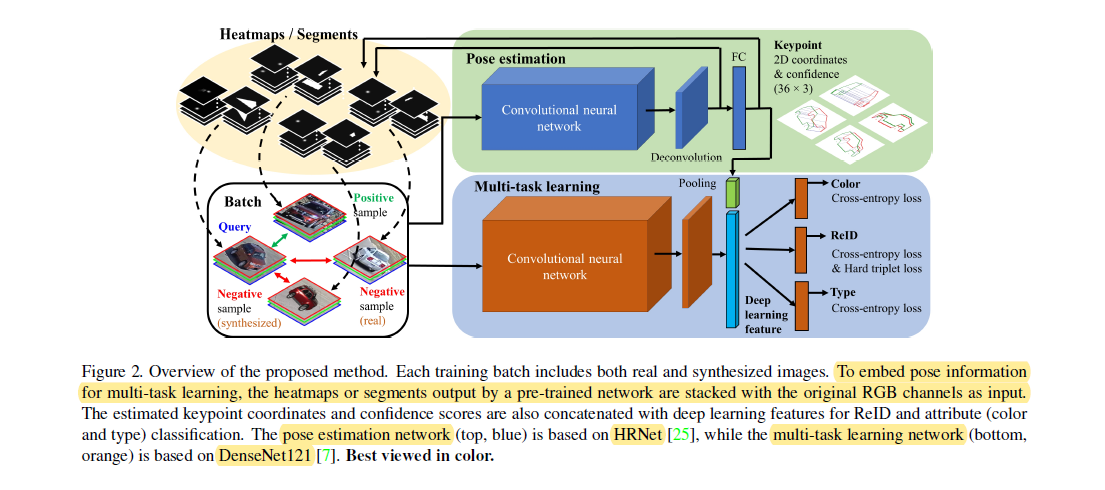
The backbone used for multitask learning (type/color) is modified version of DenseNet121. The authors modified the initial layer to incorporate features from pose estimation network and stack them.
用于多任务学习的主干(类型/颜色)是DenseNet121的修改版本。 作者修改了初始层,以合并姿势估计网络中的特征并将其堆叠。
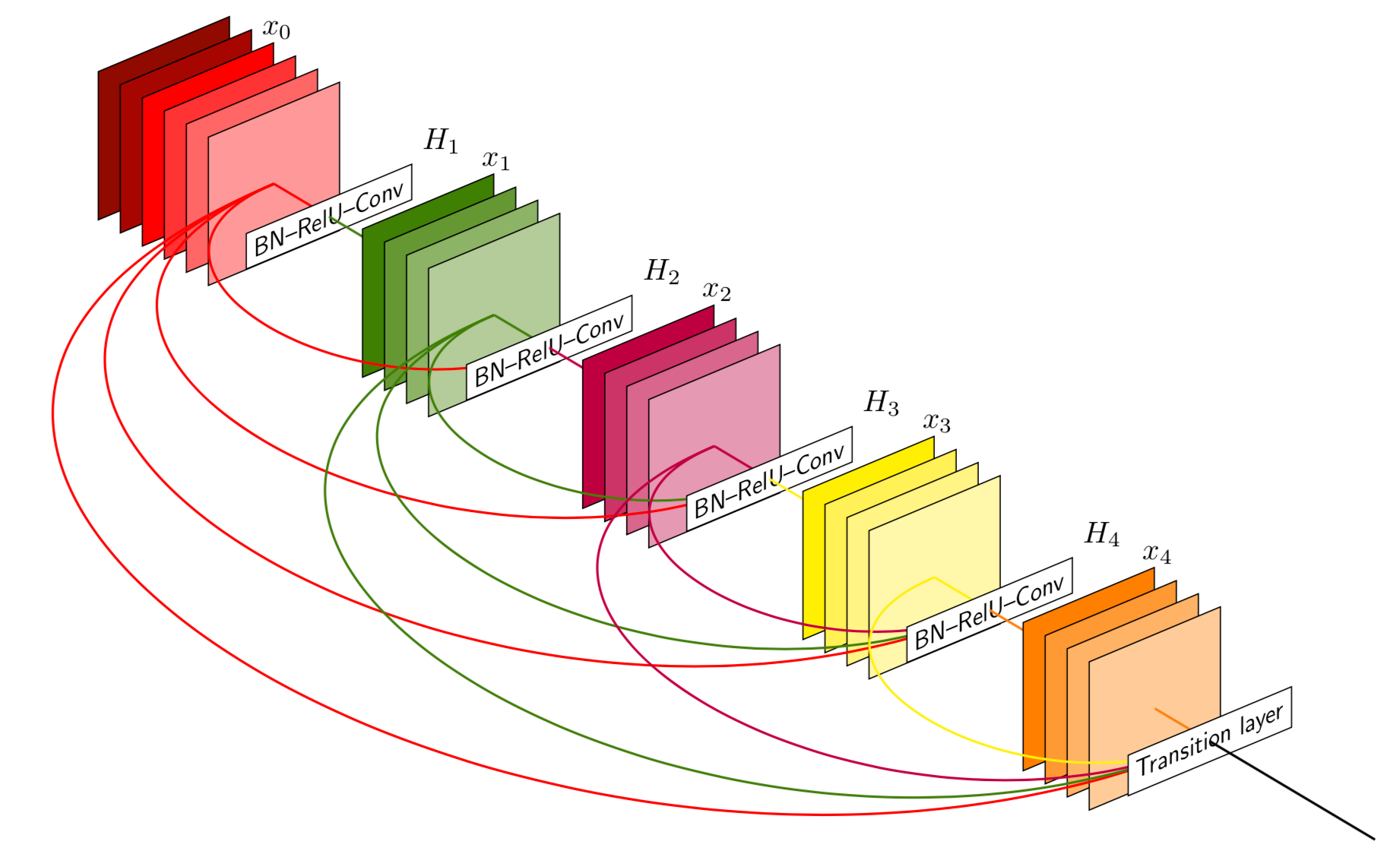
For extensive explanation on DenseNet121 architecture, please visit link.
有关DenseNet121架构的详细说明,请访问链接 。
The concatenated feature vector(vehicle signature) is fed to three separate branches for multi-task learning, including a branch for vehicle ReID and two other branches for color and type classification.
串联的特征向量(车辆签名)被馈送到三个单独的分支以进行多任务学习,其中包括一个用于车辆ReID的分支以及两个用于颜色和类型分类的其他分支。
损失函数 (Loss Function)
The final loss function of our network is the combined loss of the three tasks. For vehicle ReID, the hard-mining triplet loss is combined with cross-entropy loss to jointly exploit distance metric learning and identity classification
我们网络的最终损失功能是三个任务的综合损失。 对于车辆ReID,将难采的三重态损失与交叉熵损失结合起来,共同利用距离度量学习和身份分类
Final_Loss = L_ID + L_COLOR + L_TYPE
最终亏损= L_ID + L_COLOR + L_TYPE
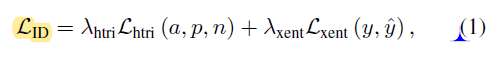
L_ID = c1*hard_triplet_loss + c2*cross_entropy_loss
L_ID = c1 * hard_triplet_loss + c2 * cross_entropy_loss
Here, c1 and c2 are regularizing coefficients.
在此,c1和c2是正则化系数。
Hard Triplet Loss is an extension of original triplet loss. The idea is to find set of triplets in a mini batch for which the model does not give good representation.
硬三元组损失是原始三元组损失的扩展。 这个想法是在一个模型不能很好表示的小批量中找到一组三胞胎。
The process is to take p samples and k images from each sample. Now from pk images, calculate triplet loss on all and sort the scores. The ones having highest loss(model performed bad on these images) in the subset of data(pk images) that corresponds to a hard mini batch as compared to randomly choosing triplets.
该过程是从每个样本中获取p个样本和k个图像。 现在从pk图像上计算所有的三重态损失并对分数进行排序。 与随机选择三胞胎相比,在对应于硬迷你批次的数据(pk图像)子集中具有最高损失(模型在这些图像上表现不好)的模型。
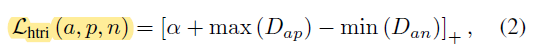
I have explained this algorithm in detail in this article.
我已经在本文中详细解释了该算法。
Cross Entropy Loss as the name suggests calculates loss between ground truth and estimation class. It is used for color and type classification as well.
顾名思义, 交叉熵损失用于计算地面实况和估计类别之间的损失。 它也用于颜色和类型分类。
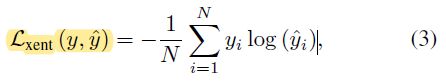
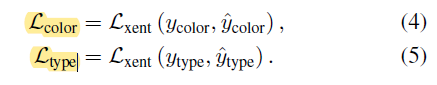
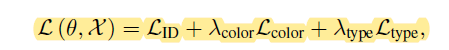
The regularizing parameter for type and color is set to a low value as compared to REID loss. This is because, in some circumstances, vehicleReID and attribute classification are conflicting tasks, i.e., two vehicles of the same color and/or type may not share the same identity. [1] The authors wanted REID loss to dominate in feature formation.
与REID损耗相比,用于类型和颜色的正则化参数设置为较低的值。 这是因为,在某些情况下,vehicleReID和属性分类是相互冲突的任务,即,相同颜色和/或类型的两辆车辆可能不会共享相同的标识。 [1]作者希望REID丢失在特征形成中占主导地位。
推理 (Inference)
At the inference stage, the final ReID classification layer is removed. For each vehicle image a 1024-dimensional feature vector is extracted from the last FC layer. The features from each pair of query and test images are compared using Euclidean distance to determine their similarity. This is a standard procedure follower for any similarity matching task using feature vector.
在推断阶段,将删除最终的ReID分类层。 对于每个车辆图像,从最后一个FC层提取1024维特征向量。 使用欧几里得距离比较每对查询和测试图像中的特征,以确定它们的相似性。 这是使用特征向量进行任何相似性匹配任务的标准过程跟踪程序。
数据集 (Datasets)
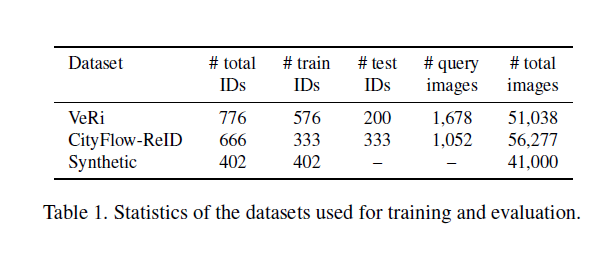
Please visit the links for detailed information about the datasets
请访问链接以获取有关数据集的详细信息
Both the datasets are available to download at the owner’s discretion for strictly academic purposes.
出于严格的学术目的,所有者可以自行决定下载这两个数据集。
The synthetic dataset is not provided by authors.
作者没有提供综合数据集。
结果 (Results)
I strongly believe that the results given in paper should not be taken very seriously because these numbers(generally speaking) are produced under specific constraints. Unless you can reproduce these numbers easily, it is hard to confirm the authenticity. Having said that, the results provided in the papers give a general idea about relativity of approach in comparison to other approaches.
我坚信,论文中给出的结果不应该被非常重视,因为这些数字(通常来说)是在特定约束下产生的。 除非您可以轻松复制这些数字,否则很难确认其真实性。 话虽如此,与其他方法相比,论文中提供的结果提供了关于方法相对性的总体思路。
Below are ReID accuracy numbers from papers for VeRi and CityFlow-ReId dataset and color/type classification results and pose estimation network(trained seperately using HRNet backbone).
以下是来自VeRi和CityFlow-ReId数据集的论文的ReID准确度数字, 颜色/类型分类结果和姿势估计网络(使用HRNet骨干分别进行训练)。
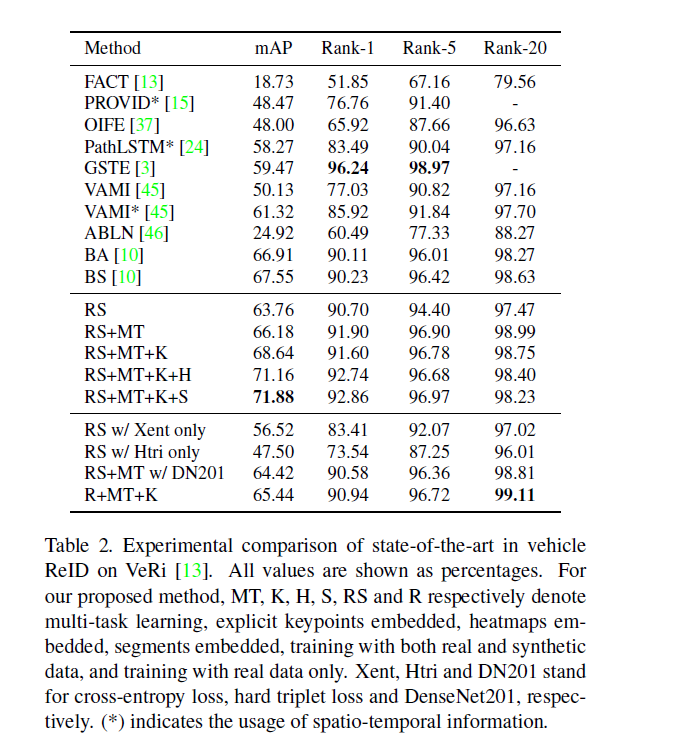
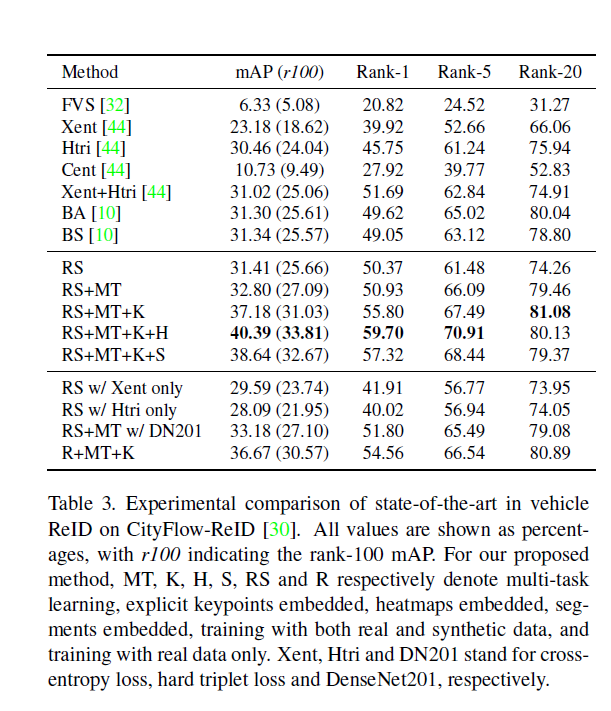
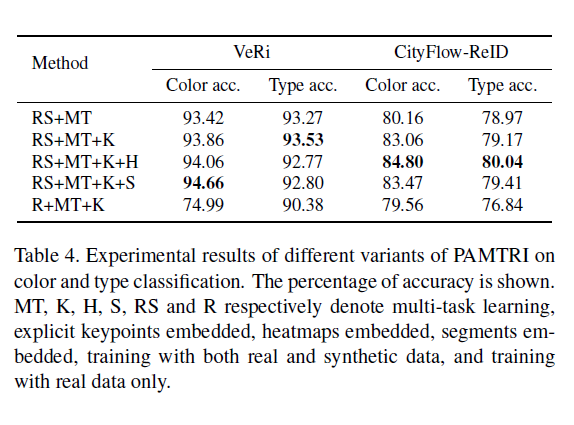
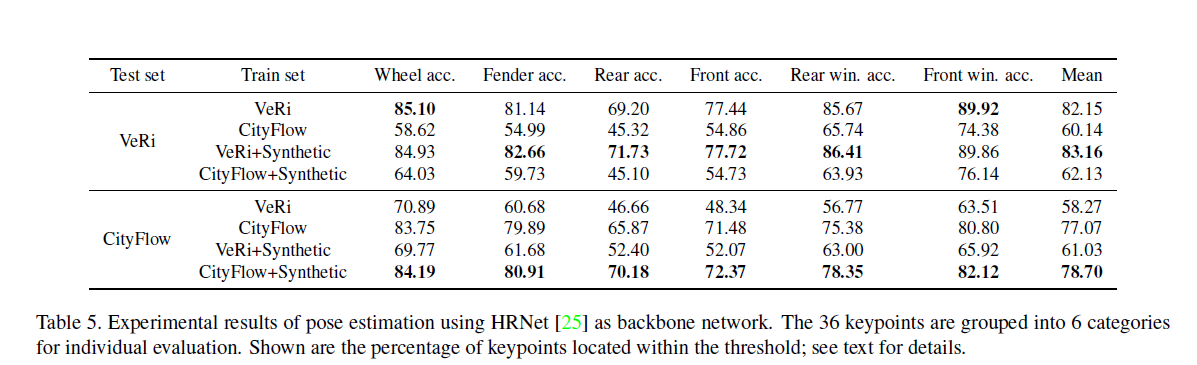
The training hyper parameters are given in the paper. All the findings are clearly stated in the section 4 of the paper.
本文给出了训练超参数。 所有发现均在论文的第4节中明确说明。
If you have any queries about results, please mention in the comment section below.
如果您对结果有任何疑问,请在下面的评论部分中提及。
码 (Code)
The authors have provided official code repository to replicate the training and testing setup Github Link
作者提供了官方代码存储库来复制培训和测试设置Github Link
结论 (Conclusion)
The vehicle attributes such as color and type are highly related to the deformable vehicle shape expressed through pose representations.
诸如颜色和类型之类的车辆属性与通过姿态表示表达的可变形车辆形状高度相关。
Estimated heatmaps or segments are embedded with input batch images for training, and the predicted keypoint coordinates and confidence are concatenated with the deep learning features for multi-task learning.
估计的热图或分段将与输入批处理图像一起嵌入以进行训练,并将预测的关键点坐标和置信度与深度学习功能相结合,以进行多任务学习。
The idea has merit as it takes into account the pose features for viewpoint information, color and type for exhaustive attributes as well. However, as the synthetic data is not made public by authors, it will be difficult to believe this results unless you generate similar data by yourself.
这个想法有其优点,因为它考虑了视点信息的姿势特征,颜色和详尽属性的类型。 但是,由于综合数据未由作者公开,因此除非您自己生成类似数据,否则很难相信这一结果。














 1620
1620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









