





 本文探讨了将机器学习模型部署到生产环境中的实际困难,特别是与网页应用结合时,涉及数据处理、模型更新、性能优化等多个方面。
本文探讨了将机器学习模型部署到生产环境中的实际困难,特别是与网页应用结合时,涉及数据处理、模型更新、性能优化等多个方面。
机器学习模型部署到网页
Also published on my website.
还发布在 我的网站上 。
目录 (Table of contents)
Traditional Software Development vs Machine LearningMachine Learning WorkflowStage #1: Data Management- Large Data Size- High Quality- Data Versioning- Location- Security & ComplianceStage #2: Experimentation- Constant Research and Experimentation Workflow- Tracking Experiments- Code Quality- Training Time & Troubleshooting- Model Accuracy Evaluation- Retraining- Infrastructure RequirementsStage #3: Production Deployment- Offline/Online Prediction- Monitoring & AlertingConclusion
传统软件开发与机器学习 机器学习工作流程 第1阶段:数据管理 - 大数据量 - 高质量 - 数据版本控制 - 位置 - 安全性和合规性 阶段2:实验 - 不断进行研究和实验工作流 - 跟踪实验 - 代码质量 - 培训时间和故障排除 - 模型准确性评估 - 再培训 - 基础结构需求 阶段3 :生产部署 - 离线/在线预测 - 监视和警报 结论
One of the known truths of the Machine Learning(ML) world is that it takes a lot longer to deploy ML models to production than to develop it. According to the famous paper “Hidden Technical Debt in Machine Learning Systems”:
机器学习(ML)世界的一个已知真理是,将ML模型部署到生产中比开发它要花费更长的时间。 根据著名的论文“ 机器学习系统中的隐藏技术债务 ”:
“Only a small fraction of real-world ML systems is composed of the ML code, as shown by the small black box in the middle(see diagram below). The required surrounding infrastructure is vast and complex.”
“现实世界中只有一小部分ML系统由ML代码组成,如中间的小黑框所示(请参见下图)。 所需的周围基础设施庞大而复杂。”
传统软件开发与机器学习 (Traditional Software Development vs Machine Learning)
If you were to think of traditional software development in juxtaposition with Machine Learning, you can very clearly see where the latter diverges in diagram #2 below. Even though that’s the case most of the principles and practices of traditional software development can be applied to Machine Learning but there are certain unique ML specific challenges that need to be handled differently. We will talk about those unique challenges that make it difficult to deploy ML models to production in this article.
如果您想将传统软件开发与机器学习并置在一起,则可以很清楚地看到后者在下面的图2中的区别。 即使是这种情况,传统软件开发的大多数原理和实践都可以应用到机器学习中,但是某些特定于ML的独特挑战需要以不同的方式处理。 在本文中,我们将讨论那些难以将ML模型部署到生产中的独特挑战。

机器学习工作流程 (Machine Learning Workflow)
Typical ML workflow includes Data Management, Experimentation, and Production Deployment as seen in the workflow below.
典型的ML工作流程包括数据管理,实验和生产部署,如下面的工作流程所示。
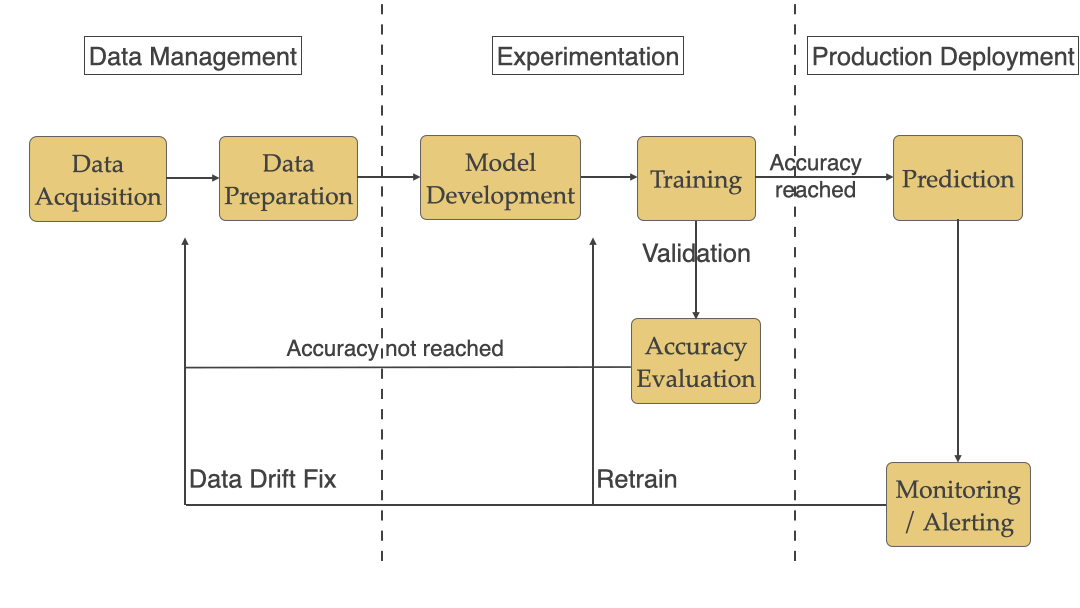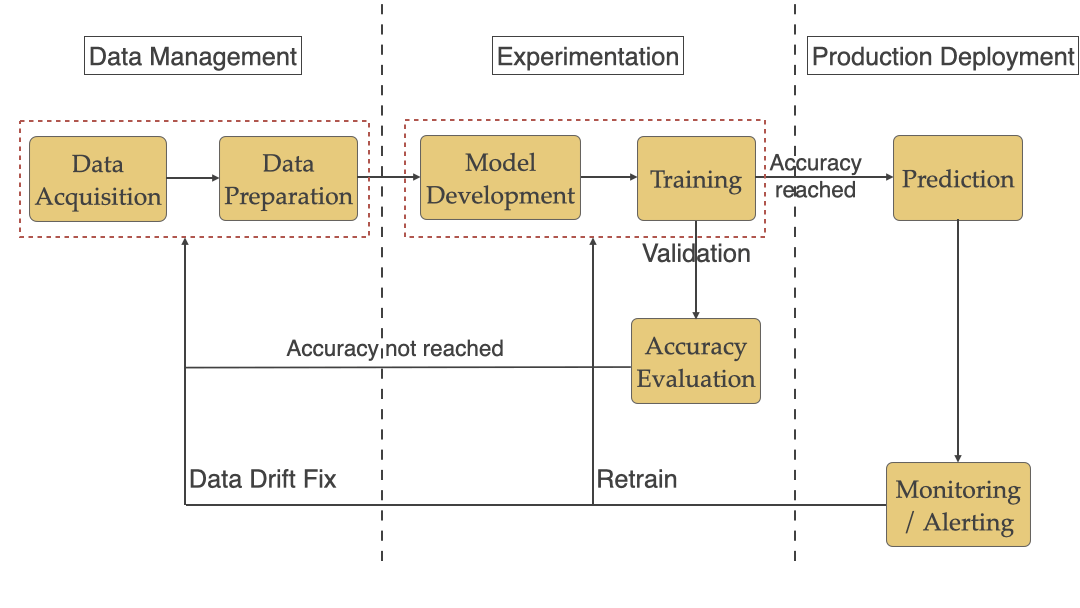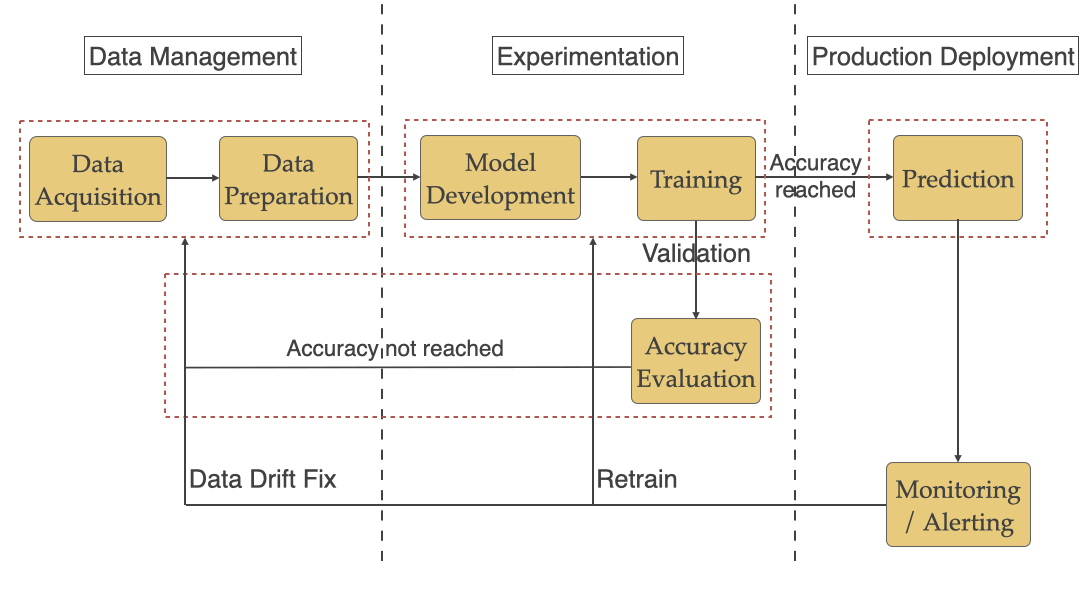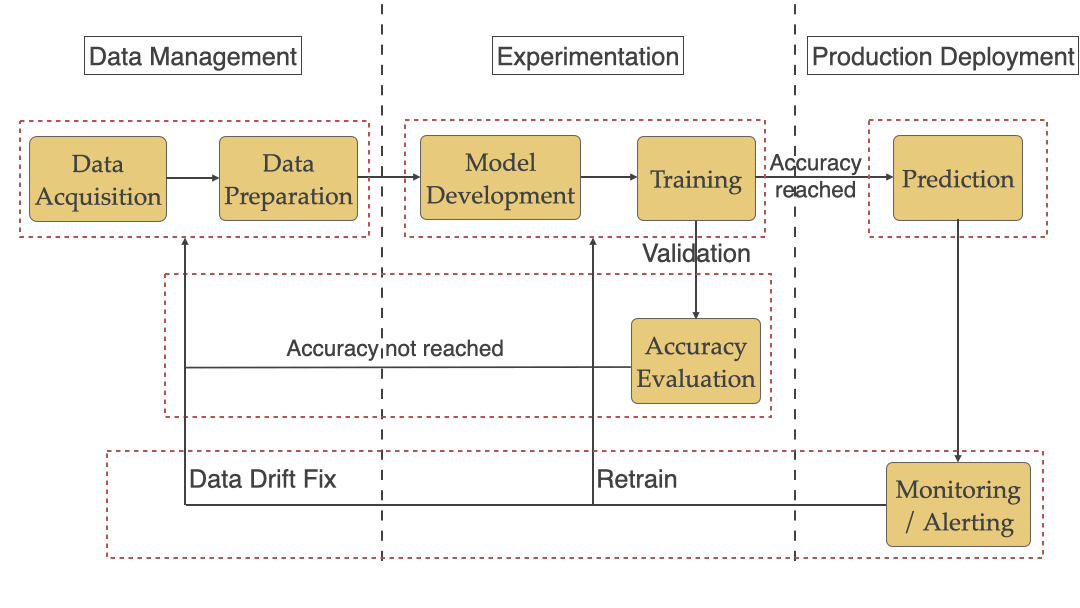
We will be looking at each stage below and the ML specific challenges that teams face with each of them.
我们将研究下面的每个阶段,以及每个团队面临的ML特定挑战。
阶段1:数据管理 (Stage #1: Data Management)
Training data is one of the fundamental factors that determine how well a model performs. This stage typically includes data acquisition and preparation. You need to be aware of the following challenges while working with ML data:
训练数据是确定模型执行情况的基本因素之一。 该阶段通常包括数据采集和准备。 使用ML数据时,您需要意识到以下挑战:
Large Data Size: Models usually need large datasets during the training process to improve its accuracy during prediction against live data. Datasets can be in hundreds of Gigabytes or even larger. This brings up some unique challenges like moving around data is not as easy and there is usually a heavy cost associated with data transfer and is time-consuming.
大数据量:在训练过程中,模型通常需要大数据集,以提高针对实时数据进行预测时的准确性。 数据集可以是数百GB甚至更大。 这带来了一些独特的挑战,例如,移动数据并不那么容易,通常与数据传输相关的成本很高,而且很耗时。
High Quality: Having a large dataset is of no use if the quality of data is bad. Finding the right data of high quality is pretty important for model accuracy. Fetching data from the correct source and having enough validation to make sure that the quality is high helps the cause. Making sure your Model is not biased based on aspects like Race, Gender, Age, Income Groups, etc. is critical too. For that, you need to make sure you have Model Bias and Fairness Validation of your data.
高质量:如果数据质量不好,则拥有大型数据集将毫无用处。 找到正确的高质量数据对于模型准确性非常重要。 从正确的来源获取数据并进行足够的验证以确保质量很高,这有助于解决问题。 确保您的模型不因种族,性别,年龄,收入群体等方面的偏见也至关重要。 为此,您需要确保数据具有模型偏差和公平性验证 。
Data Versioning: Replicating how the model was trained is helpful for data scientists. For that, the dataset that was used during each training run needs to be versioned and tracked. This also gives data scientists the flexibility to go back to a previous version of the dataset and analyze it.
数据版本控制:复制模型的训练方式对数据科学家很有帮助。 为此,需要对每次训练运行中使用的数据集进行版本控制和跟踪。 这也使数据科学家可以灵活地返回到数据集的先前版本并对其进行分析。
Location: Depending on the use case these datasets reside at various locations and as mentioned above they might be of larger size. Because of these reasons, it might make sense to run the training and in some cases prediction closer to where the data is instead of transferring large data sets across locations.
位置:根据使用情况,这些数据集位于不同的位置,如上所述,它们可能更大。 由于这些原因,可能需要进行训练,并且在某些情况下更靠近数据的位置进行预测,而不是跨位置传输大型数据集。
Caution: Make sure this is worth the effort. If you can manage without adding this complexity and run things centrally I would recommend you do that.
警告: 确保这样做值得您付出努力。 如果您可以在不增加这种复杂性的情况下进行管理并集中运行,那么我建议您这样做。
Security & Compliance: In some cases, data being used might be sensitive or need to meet certain compliance standards (like HIPAA, PCI, or GDPR). You need to keep this in mind when you are supporting ML systems.
安全性和合规性:在某些情况下,正在使用的数据可能很敏感,或者需要满足某些合规性标准(例如HIPAA,PCI或GDPR)。 支持ML系统时,请记住这一点。
阶段2:实验 (Stage #2: Experimentation)
This stage includes Model development where Data Scientists focus a lot of their time researching various architectures to see what fits their needs. For example, for Semantic Segmentation here are various architectures available. Data Scientists write code to use the data from the previous stage and use that to train the model and then do an evaluation to see if it meets the accuracy standards they are looking for. See below some of the challenges that you will face during this stage.
这个阶段包括模型开发,在此阶段,数据科学家花费大量时间研究各种架构,以了解适合自己的需求。 例如,对于语义分割,这里有各种可用的体系结构 。 数据科学家编写代码以使用上一阶段的数据,并使用它们来训练模型,然后进行评估以查看其是否满足他们所寻找的准确性标准。 参见下面,您将在此阶段面临一些挑战。
Constant Research and Experimentation Workflow: They spend time collecting/generating data, experimenting, and trying out various architectures to see what works for their use case. They also try hyperparameter optimization and training with various datasets to see what gives more accurate results.
持续的研究和实验工作流:他们花费时间收集/生成数据,进行实验并尝试各种体系结构,以了解适用于其用例的方法。 他们还尝试通过各种数据集进行超参数优化和训练,以查看可提供更准确结果的方法。
Due to the research and experimental nature of this, the workflow that needs to be supported is different from traditional software development.
由于其研究和实验性质,需要支持的工作流程与传统软件开发不同。
Tracking Experiments: One of the key aspects of this workflow is to allow data scientists to track experiments and know what changed between various runs. They should easily be able to track dataset, architecture, code, and hyper-parameter changes between various experiments.
跟踪实验:此工作流程的关键方面之一是允许数据科学家跟踪实验并了解各种运行之间的变化。 他们应该能够轻松跟踪各种实验之间的数据集,体系结构,代码和超参数更改。
Code Quality: Due to the research and experimentation phase a lot of code written is usually not of high quality and not ready for production. Data Scientists spend a lot of time working with tools like Jupyter Notebook and making changes there directly to test out. You need to keep this in mind and handle it before deploying ML models to production.
代码质量:由于处于研究和实验阶段,因此编写的许多代码通常不是高质量的,并且尚未准备好用于生产。 数据科学家花费大量时间使用Jupyter Notebook之类的工具,并在那里直接进行更改以进行测试。 在将ML模型部署到生产之前,您需要牢记这一点并加以处理。
Training Time & Troubleshooting: Training a model typically requires hours or sometimes days to run and needs special infrastructure(see challenge #4 below). For example, a full build of Tesla Autopilot neural networks takes 70,000 GPU hours to train as per their website. Since training typically takes a lot of time you need to be able to support easy troubleshooting using aspects like monitoring, logging, alerting, and validation during the training process. If the training process errors out, providing easy ways of fixing the issue, and continuing/restarting the training is important.
训练时间和故障排除:训练模型通常需要几个小时甚至几天才能运行,并且需要特殊的基础结构(请参阅下面的挑战4)。 例如,完整的Tesla Autopilot神经网络构建需要根据其网站进行70,000个GPU小时的培训。 由于培训通常会花费大量时间,因此您需要能够在培训过程中使用监视,日志记录,警报和验证等方面来支持简单的故障排除。 如果培训过程出错,则提供简单的方法来解决问题以及继续/重新开始培训很重要。
Model Accuracy Evaluation: After training the model accuracy needs to be evaluated to see if it meets the standard required for prediction in production. As seen in diagram #3 above you reiterate through the training/data management steps to keep improving the accuracy until you reach an acceptable number.
模型准确性评估:训练后,需要评估模型准确性,以查看其是否满足生产中预测所需的标准。 如上图3所示,您重申了培训/数据管理步骤,以不断提高准确性,直到达到可接受的数量。
Retraining: In cases when you have a data drift, a bug in production, or change in requirements you might need to retrain the model. There needs to be a way to support retraining models.
重新训练:如果您遇到数据漂移 ,生产中的错误或需求变更的情况,则可能需要重新训练模型。 需要一种支持再训练模型的方法。
Infrastructure Requirements: ML workloads have certain special Infrastructure requirements like GPU & High-Density Cores. Thousands of processing cores run simultaneously in a GPU which enables training and prediction to run much faster compared to just CPUs. Since these infrastructure requirements (especially GPU) are costly and are needed mostly in periodic bursts for training, having support for elasticity and automation to scale as well as provision/de-provision infrastructure (especially when using the cloud) is a good idea.
基础架构要求: ML工作负载具有某些特殊的基础架构要求,例如GPU 和高密度内核 。 成千上万个处理内核在GPU中同时运行,这使得训练和预测比仅CPU更快地运行。 由于这些基础结构要求(尤其是GPU) 成本高昂 ,并且通常在定期的训练中需要,因此支持弹性和自动化以进行扩展以及提供/取消供应基础结构(尤其是在使用云时)是一个好主意。
Edge Devices (IoT, mobile, etc) like the Nvidia Jetson series are more and more used these days, and deploying to these devices is another challenge as these devices mostly use ARM architecture instead of x86 that have limited resources. Models need to be tested on these devices for accuracy as well as performance.
如今,诸如Nvidia Jetson系列之类的边缘设备(物联网,移动设备等)越来越多地被使用,并且部署到这些设备是另一个挑战,因为这些设备大多使用ARM体系结构而不是资源有限的x86 。 需要在这些设备上测试模型的准确性和性能。
Due to lack of support for certain dependencies and their latest versions for the ARM architecture having good practices around building packages/models helps.
由于缺少对某些依赖项的支持及其最新版本的ARM体系结构,因此围绕构建软件包/模型的良好实践会有所帮助。
阶段3:生产部署 (Stage #3: Production Deployment)
After the model is trained and reaches certain accuracy it gets deployed to production where it starts making predictions against live data. Here are some challenges to be aware of for this stage.
训练模型并达到一定的精度后,将其部署到生产环境中,然后开始根据实时数据进行预测。 这是现阶段要注意的一些挑战。
Offline/Online Prediction: Depending on the model and the way it is going to be used in production with live data you might have to support either offline (batch) prediction or online (real-time) prediction. You need an appropriate framework to serve the model based on the type (batch or real-time). If it’s a batch prediction make sure you can schedule the batch job appropriately and for real-time, you need to worry about processing time since the result is usually needed back synchronously.
离线/在线预测:根据模型和将其用于实时数据的生产中的使用方式,您可能必须支持离线(批量)预测或在线(实时)预测。 您需要一个适当的框架来基于类型(批处理或实时)为模型提供服务。 如果是批处理预测,请确保可以适当地实时调度批处理作业,因为通常需要同步返回结果,因此您需要担心处理时间。
Monitoring & Alerting: The model needs to be monitored in production and if there are any issues found teams need to be alerted so they can tackle the issue promptly. It’s important to have the information needed to troubleshoot & fix an issue readily available to the teams.
监视和警报:需要在生产中监视该模型,如果发现任何问题,则需要向团队发出警报,以便他们可以Swift解决问题。 重要的是要使团队可以随时获得解决和修复问题所需的信息。
结论 (Conclusion)
DevOps Principles and Practices that include all 3 aspects (People, Process & Technology) have been used effectively for mitigating challenges with traditional software. These same DevOps Principles and Practices along with some Machine Learning specific practices can be used for deploying & operating ML Systems successfully. These ML principles and practices are also known as MLOps or DevOps for Machine Learning. I will be writing follow-up articles that will look at those principles and practices that help overcome the challenges mentioned in this article.
包括所有三个方面(人,流程和技术)的DevOps原则和实践已被有效地用于缓解传统软件的挑战。 这些相同的DevOps原理和实践以及一些机器学习特定的实践可用于成功部署和操作ML系统。 这些ML原理和实践也称为机器学习的 MLOps或DevOps 。 我将撰写后续文章,探讨有助于克服本文中提到的挑战的原则和实践。
Acknowledgments: Priyanka Rao and Bobby Wagner read the draft version of this article and provided feedback to improve it.
致谢: Priyanka Rao和Bobby Wagner阅读了本文的草稿,并提供了改进意见。
机器学习模型部署到网页
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









