





深度搜索算法确定人名地名
Learning to solve AI Planning Problems with Deterministic Search Algorithms
学习使用确定性搜索算法解决AI规划问题
Read previous post to understand the generic implementation of Deterministic-search algorithms.
阅读上一篇文章,了解确定性搜索算法的一般实现。
To understand more easily we use real life examples, a game, to visualize how the algorithms solve the planning problems.
为了更容易理解,我们使用现实生活中的示例(游戏)来可视化算法如何解决计划问题。
The example that we will use here is Pacman Game. You can read the link for the details of the gameplay and other information. In short, the mission of Pacman is to eat all smaller dots (foods) while avoiding ghosts.
我们将在此处使用的示例是Pacman Game。 您可以阅读该链接,以了解游戏的详细信息和其他信息。 简而言之,吃豆子的任务是吃掉所有较小的点(食物),同时避免鬼魂。
If Pacman meets a ghost, it loses. It wins after it has eaten all foods.
如果吃豆子遇到鬼,它就会输。 吃完所有食物,它就赢了。
The bigger dots are capsules which when eaten by Pacman, gives temporary power to Pacman to eat the ghosts.
在B igger点是胶囊,当由吃豆子吃,给临时电源,以吃豆子吃鬼。
You can search in Github to find the implementation of Pacman game engine written in Python.
您可以在Github中搜索以找到用Python编写的Pacman游戏引擎的实现。
吃豆人世界代表 (Pacman World Representation)
For us to solve planning problems in Pacman, first we need to represent how Pacman World looks like. The following are all the objects in Pacman World:
为了解决“吃豆人”中的规划问题,首先我们需要说明“吃豆人世界”的外观。 以下是《吃豆人世界》中的所有对象:
- Pacman 吃豆子
- Ghosts鬼魂
- Foods食品类
- Capsules胶囊
- Walls墙
Walls are rigid, the positions and number of walls are fixed. Foods and Capsules are fixed in positions but the number of them can reduce.
墙壁是刚性的,墙壁的位置和数量是固定的。 食品和胶囊的位置固定,但数量可以减少。
Pacman and ghosts do not reduce in number but their positions can change throughout the game.
吃豆人和幽灵的数量并没有减少,但是他们的位置可以在整个游戏中改变。
class PacmanWorld:
def __init__(self, game_state: GameState = None):
self._ghosts = {}
self._pacman_position = None
self._capsules = None
self._foods = None
self._walls = None
self._pacman_position = game_state.get_pacman_position()
self._num_of_ghosts = game_state.get_num_of_agents() - 1
index = 0
for ghost_pos in game_state.get_ghost_positions():
self._ghosts[index] = ghost_pos
index = index + 1
self._pacman_position = game_state.get_pacman_position()
self._capsules = game_state.get_capsules()
self._foods = game_state.get_food()
self._walls = game_state.get_walls()
self._score = game_state.get_score()
self._pacman_game_state = game_state.deepcopy()
def closest_food_pos(self):
closest_distance = None
closest = None
for y in range(0, self._foods.height, 1):
for x in range(0, self._foods.width, 1):
if self._foods[x][y]:
pos = (x, y)
manhattan_distance = 0
for a, b in zip(pos, self._pacman_position):
manhattan_distance = manhattan_distance + abs(a - b)
if closest_distance is None or manhattan_distance < closest_distance:
closest_distance = manhattan_distance
closest = (x, y)
return closest
def distance_to_ghosts(self, ignore_scared_ghost=True):
dist_to_ghosts = {}
if self._ghosts is None:
return dist_to_ghosts
for key, value in self._ghosts.items():
if self._pacman_game_state and ignore_scared_ghost:
must_ignore = False
for ghost in self._pacman_game_state.get_ghost_states():
if ghost.getPosition() == value and ghost.scaredTimer > 0:
must_ignore = True
break
if must_ignore:
continue
dist_to_ghosts[key] = 0
for a, b in zip(value, self._pacman_position):
dist_to_ghosts[key] = dist_to_ghosts[key] + abs(a - b)
return dist_to_ghosts
def closest_capsule_pos(self):
closest = None
closest_distance = None
for capsule in self._capsules:
manhattan_distance = 0
for a, b in zip(capsule, self._pacman_position):
manhattan_distance = manhattan_distance + abs(a - b)
if closest_distance is None or manhattan_distance < closest_distance:
closest_distance = manhattan_distance
closest = capsule
return closest
@property
def game_state(self):
return self._pacman_game_state
@property
def score(self):
return self._score
@property
def ghosts(self):
return self._ghosts
@property
def capsules(self):
return self._capsules
@property
def foods(self):
return self._foods
@property
def pacman_position(self):
return self._pacman_position
@property
def pacman_pos_only(self):
return self._pacman_position_only
@property
def include_score(self):
return self._include_score
@property
def num_of_ghosts(self):
return self._num_of_ghosts
def __eq__(self, other):
if self._num_of_ghosts:
if self._num_of_ghosts != other.num_of_ghosts:
return False
if self._capsules:
if self._capsules != other.capsules:
return False
if self._foods:
if self._foods != other.foods:
return False
if self._include_score and self._score:
if self._score != other.score:
return False
if self._pacman_position:
if self._pacman_position != other.pacman_position:
return False
return True
def __ne__(self, other):
return not (self == other)We can write the Pacman World like shown in the code snippet above. You can see that we have all the objects implemented in our class along with their getters.
我们可以像上面的代码片段所示编写“吃豆人世界”。 您可以看到我们在类中实现了所有对象以及它们的getter。
The most important thing is the implementation of the equality operators (== and !=), which will be used frequently by the algorithms to compare the states of the world.
最重要的是等式运算符(==和!=)的实现,算法将经常使用它们比较世界的状态。
动作模板和状态预测器 (Action Templates and State Predictor)
The next bit that we need is the action template and its state predictor. There are 4 actions that Pacman can do, they are:
我们需要的下一个位是动作模板及其状态预测器。 Pacman可以执行4种操作,它们是:
- Go up (north) 往北走
- Go down (south)往南走
- Go left (west)向左走(西)
- Go right (east) 向右走(东)
The implementation of action template looks like this:
操作模板的实现如下所示:
class PacmanSimpleActionTemplate(ActionTemplate):
def __init__(self):
actions = [Directions.EAST, Directions.NORTH, Directions.SOUTH, Directions.WEST]
precondition_table = {Directions.EAST: self.go_right_pre,
Directions.NORTH: self.go_up_pre,
Directions.SOUTH: self.go_down_pre,
Directions.WEST: self.go_left_pre}
effect_table = {Directions.EAST: self.go_right_eff,
Directions.NORTH: self.go_up_eff,
Directions.SOUTH: self.go_down_eff,
Directions.WEST: self.go_left_eff}
super().__init__(actions, precondition_table, effect_table)
def cost(self, action, world_state):
current_score = world_state.score
predicted_state = world_state.game_state.generate_successor(0, action)
predicted_score = predicted_state.get_score()
cost = current_score - predicted_score
if self._meeting_ghost(action, world_state):
cost = 1000
return cost
@staticmethod
def _meeting_ghost(action, world_state):
predicted_state = world_state.game_state.generate_successor(0, action)
predicted_world_state = PacmanWorld(predicted_state, world_state.pacman_pos_only)
distance_to_ghosts = predicted_world_state.distance_to_ghosts()
for key, distance in distance_to_ghosts.items():
if distance <= 1:
for k, ghost_position in predicted_world_state.ghosts.items():
if k != key:
continue
x = ghost_position[0] - predicted_world_state.pacman_position[0]
y = ghost_position[1] - predicted_world_state.pacman_position[1]
vector = (x, y)
action = Actions.vectorToDirection(vector)
if action not in predicted_world_state.game_state.get_legal_actions():
return False
else:
return True
return False
def go_up_pre(self, state):
if Directions.NORTH not in state.game_state.get_legal_actions():
return False
if self._meeting_ghost(Directions.NORTH, state):
return False
return True
@staticmethod
def go_up_eff(state):
game_state = state.game_state.generate_successor(0, Directions.NORTH)
return PacmanWorld(game_state, state.pacman_pos_only)
def go_down_pre(self, state):
if Directions.SOUTH not in state.game_state.get_legal_actions():
return False
if self._meeting_ghost(Directions.SOUTH, state):
return False
return True
@staticmethod
def go_down_eff(state):
game_state = state.game_state.generate_successor(0, Directions.SOUTH)
return PacmanWorld(game_state, state.pacman_pos_only)
def go_left_pre(self, state):
if Directions.WEST not in state.game_state.get_legal_actions():
return False
if self._meeting_ghost(Directions.WEST, state):
return False
return True
@staticmethod
def go_left_eff(state):
game_state = state.game_state.generate_successor(0, Directions.WEST)
return PacmanWorld(game_state, state.pacman_pos_only)
def go_right_pre(self, state):
if Directions.EAST not in state.game_state.get_legal_actions():
return False
if self._meeting_ghost(Directions.EAST, state):
return False
return True
@staticmethod
def go_right_eff(state):
game_state = state.game_state.generate_successor(0, Directions.EAST)
return PacmanWorld(game_state, state.pacman_pos_only)Recall that the action templates has input parameters, preconditions and effects. Read this post:
回想一下,动作模板具有输入参数,前提条件和效果。 阅读这篇文章:
When the algorithm looks for applicable actions, it simply calls precondition functions and to get the predicted state of the world, it simply call effect function.
当算法寻找适用的动作时,它简单地调用前提条件函数并获得预测的世界状态,它简单地调用效果函数。
for action in actions:
if action.pre(pacman_world):
predicted_pacman_world = action.eff()The preconditions of all simple actions that we have are:
我们拥有的所有简单操作的前提是:
- the action is legal (not moving towards the wall) 该行为是合法的(不得向墙外移动)
- will not meet ghost 不会遇见鬼
Another thing worth noting here is we provide the cost incurred to perform the action as well to the search algorithm.
在这里需要注意的另一件事是,我们还向搜索算法提供了执行操作所需的费用。
规划问题 (Planning Problem)
We’ll look at one example of Planning Problem, start with a simple one.
我们将从一个简单的例子开始,看一个规划问题的例子。
From this initial state with 4 foods in the corner and without ghosts.
从此初始状态开始,拐角处有4种食物且没有鬼影。
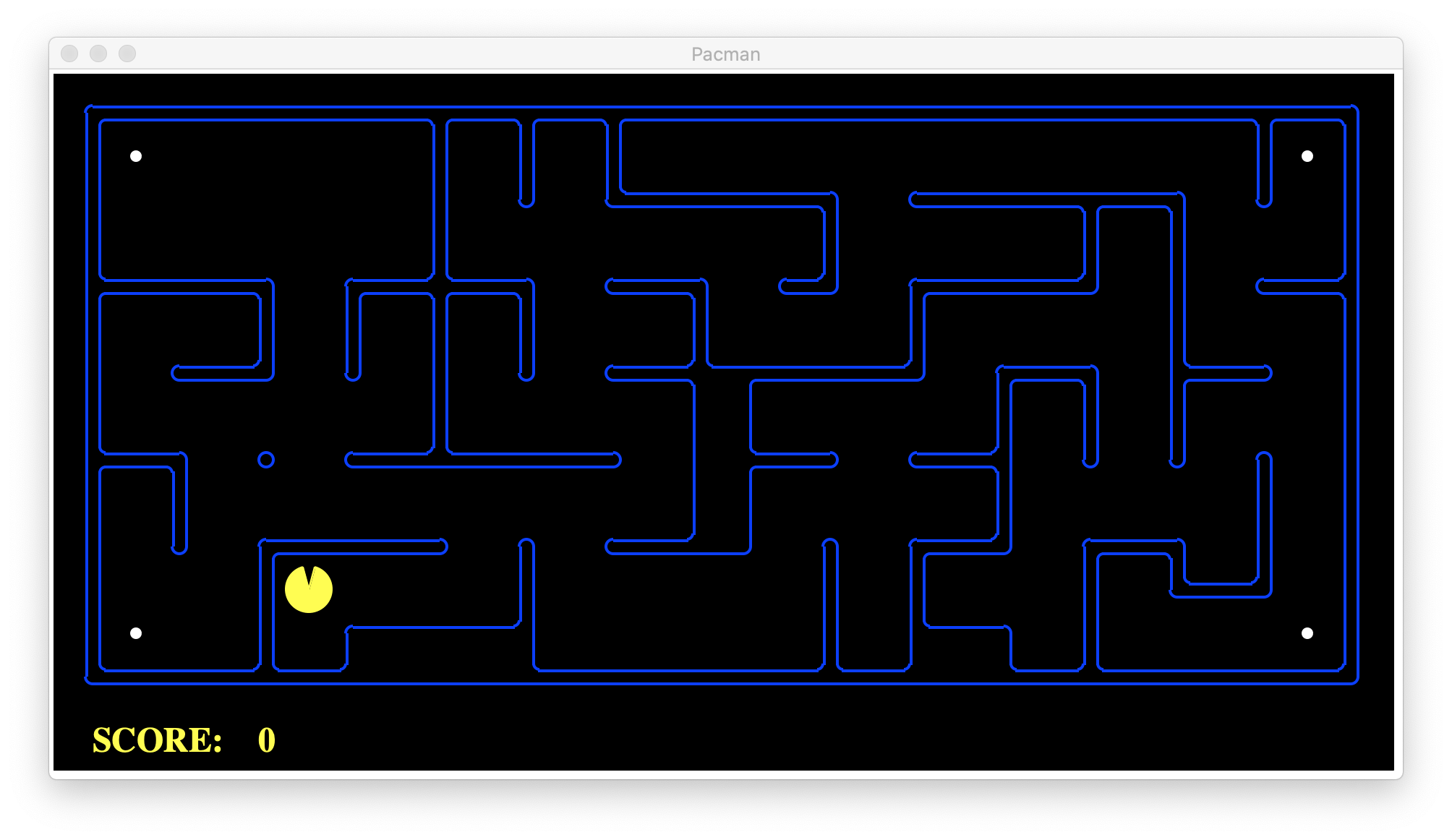
We want to have this goal state with 0 food, which means our AI agent, Pacman, has to eat all 4 foods intelligently.
我们希望使目标状态包含0种食物,这意味着我们的AI代理商Pacman必须明智地食用所有4种食物。
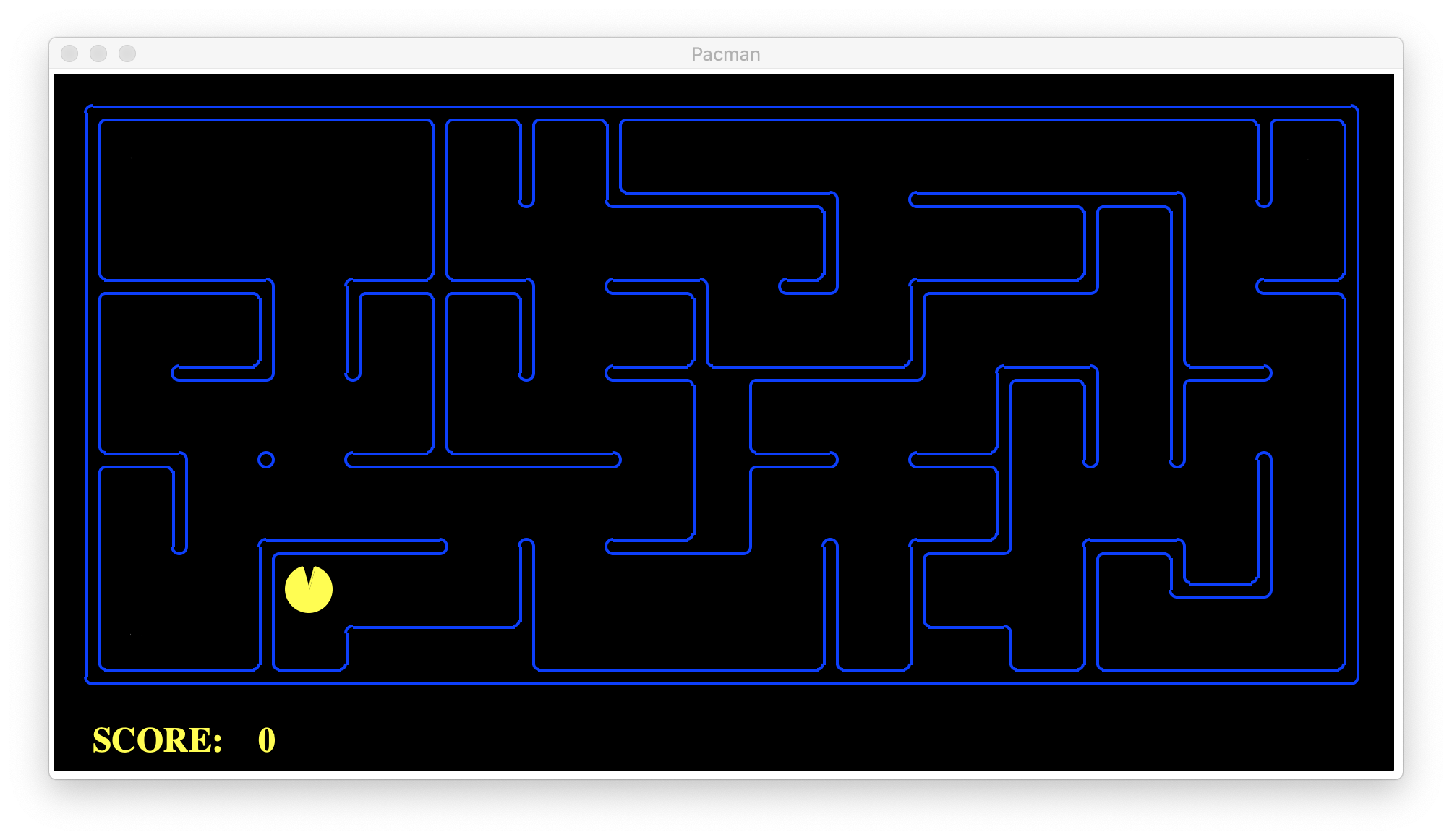
演算法(Algorithms)
Let’s look at how deterministic search algorithms solve this problem. In these implementations we are not using heuristics. Heuristics will be discussed in a separate post.
让我们看看确定性搜索算法如何解决此问题。 在这些实现中,我们不使用启发式。 启发式将在另一篇文章中讨论。
广度优先搜索 (Breadth-first Search)
We implement BFS as an instance of Deterministic search algorithm with node selection and node pruning as follows:
我们将BFS用作确定性搜索算法的实例,并通过以下步骤选择节点并进行节点修剪:
Node selection
节点选择
Choose a node with shortest length
选择长度最短的节点
Pruning
修剪
Remove from Children and Frontier nodes which are already in Expanded
从“展开”中的“子级”和“边境”节点中删除
class BreadthFirstSearch(DeterministicSearch):
def __init__(self, show_path=True, show_expanded=True):
super().__init__(show_path, show_expanded)
self._name = "BreadthFirstSearch"
def select_node(self, frontier, problem):
selected_node = None
index = None
for node in frontier:
if selected_node is None or len(node.actions) < len(selected_node.actions):
selected_node = node
index = frontier.index(selected_node)
elif len(node.actions) == len(selected_node.actions):
if node.heuristic < selected_node.heuristic:
selected_node = node
index = frontier.index(selected_node)
return selected_node, index
def prune(self, children, frontier, expanded, problem):
invalid_children = []
invalid_frontier = []
for child in children:
for expanded_node in expanded:
if child.state == expanded_node.state:
invalid_children.append(child)
break
for node in frontier:
for expanded_node in expanded:
if node.state == expanded_node.state:
invalid_frontier.append(node)
break
for invalid_node in invalid_children:
children.remove(invalid_node)
for invalid_node in invalid_frontier:
frontier.remove(invalid_node)When running this algorithm on our planning problem we will get optimal solution but long planning time. For relative comparisons, I will write each algorithm’s planning time when I ran it.
在计划问题上运行此算法时,我们将获得最佳解决方案,但计划时间较长。 为了进行相对比较,我将在运行时编写每个算法的计划时间。
- Planning time: 185 seconds 计划时间:185秒
深度优先搜索(Depth-first Search)
Node Selection
节点选择
Choose node with longest length
选择最长的节点
Pruning
修剪
Cycle checking
循环检查
class DepthFirstSearch(DeterministicSearch):
def __init__(self, show_path=True, show_expanded=True):
super().__init__(show_path, show_expanded)
self._name = "DepthFirstSearch"
def select_node(self, frontier, problem):
selected_node = None
index = None
for node in frontier:
if selected_node is None or len(node.actions) > len(selected_node.actions):
selected_node = node
index = frontier.index(selected_node)
elif len(node.actions) == len(selected_node.actions):
if node.heuristic < selected_node.heuristic:
selected_node = node
index = frontier.index(selected_node)
return selected_node, index
def prune(self, children, frontier, expanded, problem):
invalid_children = []
for child in children:
predecessor = child.predecessor
while predecessor is not None:
if predecessor.state == child.state:
invalid_children.append(child)
break
else:
predecessor = predecessor.predecessor
for x in invalid_children:
children.remove(x)Running this algorithm on our planning problem gives us non-optimal solution but much shorter planning time.
在我们的计划问题上运行此算法会给我们带来非最优的解决方案,但会大大缩短计划时间。
- Planning time: 37 seconds 计划时间:37秒
爬山(Hill Climbing)
Node Selection
节点选择
Choose node that minimizes heuristic, for our implementation this is just any nodes because we have not implemented heuristic function
选择最小化启发式的节点,对于我们的实现,这只是任何节点,因为我们尚未实现启发式功能
Pruning
修剪
Clear Frontier so that we only follow current path
清除边界,以便我们仅遵循当前路径
As we can see in the pruning process it is not guaranteed that we will have a solution. This algorithm fails to solve our planning problem.
正如我们在修剪过程中看到的那样,不能保证我们会有解决方案。 该算法无法解决我们的计划问题。
统一成本搜索 (Uniform-cost Search)
Node Selection
节点选择
Choose node that minimizes total cost
选择使总成本最小化的节点
Pruning
修剪
Remove from Frontier and Children nodes that are already in Expanded
从“已扩展”中的“边境和子节点”中删除
class UniformCostSearch(DeterministicSearch):
def __init__(self, show_path=True, show_expanded=True):
super().__init__(show_path, show_expanded)
self._name = "UniformCostSearch"
def select_node(self, frontier, problem):
selected_node = None
index = None
for node in frontier:
if selected_node is None:
selected_node = node
index = frontier.index(selected_node)
else:
if node.cost < selected_node.cost:
selected_node = node
index = frontier.index(selected_node)
return selected_node, index
def prune(self, children, frontier, expanded, problem):
invalid_children = []
invalid_frontier = []
for child in children:
for expanded_node in expanded:
if child.state == expanded_node.state:
invalid_children.append(child)
break
for node in frontier:
for expanded_node in expanded:
if node.state == expanded_node.state:
invalid_frontier.append(node)
break
for invalid_node in invalid_children:
children.remove(invalid_node)
for invalid_node in invalid_frontier:
frontier.remove(invalid_node)This algorithm gives us optimal solution and shorter planning time compared to BFS.
与BFS相比,该算法为我们提供了最佳解决方案,并缩短了计划时间。
- Planning time: 106 seconds 计划时间:106秒
一种*(A*)
Node Selection
节点选择
Choose node that minimizes f(v) = cost + heuristic. For our current implementation this will be exactly the same as Uniform-cost search because we have not implemented heuristics
选择最小化f(v)=成本+启发式的节点。 对于我们当前的实现,这将与统一成本搜索完全相同,因为我们尚未实现启发式
Pruning
修剪
Remove duplicated paths with higher cost
以更高的成本删除重复的路径
class AStarSearch(DeterministicSearch):
def __init__(self, show_path=True, show_expanded=True):
super().__init__(show_path, show_expanded)
self._name = "AStarSearch"
def select_node(self, frontier, problem):
selected_node = None
index = None
for node in frontier:
if selected_node is None:
selected_node = node
index = frontier.index(selected_node)
else:
if (node.cost + node.heuristic) < (selected_node.cost + selected_node.heuristic):
selected_node = node
index = frontier.index(selected_node)
return selected_node, index
def prune(self, children, frontier, expanded, problem):
current_node = expanded[-1]
found_in_children = []
found_in_frontier = []
empty_list = True
for node in children:
if node.state == current_node.state:
found_in_children.append(node)
empty_list = False
for node in frontier:
if node.state == current_node.state:
found_in_frontier.append(node)
empty_list = False
# check lowest cost, remove duplicates with higher cost
if not empty_list:
min_cost_node = min(found_in_children + found_in_frontier, key=lambda p: p.cost)
extra_found = 0
for node in found_in_frontier:
if node.cost != min_cost_node.cost or extra_found >= 1:
frontier.remove(node)
else:
extra_found = extra_found + 1
for node in found_in_children:
if node.cost != min_cost_node.cost or extra_found >= 1:
children.remove(node)
else:
extra_found = extra_found + 1Because of the pruning process, the planning time is shorter than Uniform-cost search. The result is optimal.
由于修剪过程,计划时间比统一成本搜索要短。 结果是最佳的。
- Planning time: 24 seconds 计划时间:24秒
深度优先分支定界(DFSBB) (Depth-first Branch and Bound (DFSBB))
This algorithm evaluates all possible paths in DFS and get the best. However, for our planning problem this algorithm takes too long to run. We’ll skip this algorithm this time.
该算法评估DFS中所有可能的路径并获得最佳路径。 但是,对于我们的计划问题,该算法需要花费很长时间才能运行。 这次我们将跳过此算法。
贪婪的最佳优先搜索(GBFS) (Greedy Best-First Search (GBFS))
Node Selection
节点选择
Choose node that minimizes heuristic
选择最小化启发式的节点
Pruning
修剪
Same as A*
与A *相同
class GreedyBestFirstSearch(DeterministicSearch):
def __init__(self, show_path=True, show_expanded=True):
super().__init__(show_path, show_expanded)
self._name = "GreedyBestFirstSearch"
def select_node(self, frontier, problem):
selected_node = None
index = None
for node in frontier:
if selected_node is None:
selected_node = node
index = frontier.index(selected_node)
else:
if node.heuristic < selected_node.heuristic:
selected_node = node
index = frontier.index(selected_node)
return selected_node, index
def prune(self, children, frontier, expanded, problem):
current_node = expanded[-1]
found_in_children = []
found_in_frontier = []
empty_list = True
for node in children:
if node.state == current_node.state:
found_in_children.append(node)
empty_list = False
for node in frontier:
if node.state == current_node.state:
found_in_frontier.append(node)
empty_list = False
# check lowest cost, remove duplicates with higher cost
if not empty_list:
min_cost = min(found_in_children + found_in_frontier, key=lambda p: p.cost)
extra_found = 0
for node in found_in_frontier:
if node.cost != min_cost.cost or extra_found >= 1:
frontier.remove(node)
else:
extra_found = extra_found + 1
for node in found_in_children:
if node.cost != min_cost.cost or extra_found >= 1:
children.remove(node)
else:
extra_found = extra_found + 1Normally this algorithm runs quicker than A*, however because we haven’t implemented heuristic, the planning time is a little bit longer.
通常,此算法的运行速度比A *快,但是由于我们尚未实现启发式算法,因此计划时间会更长一些。
- Planning time: 51 seconds 计划时间:51秒
Now we have looked into different algorithms to solve our first simple planning problem. In the next posts, we’ll solve more difficult planning problems and techniques to solve them.
现在,我们研究了不同的算法来解决第一个简单的计划问题。 在下一篇文章中,我们将解决更困难的计划问题和解决问题的技术。
翻译自: https://medium.com/ai-in-plain-english/deterministic-search-algorithms-part-1-cbb0c6a8ecda
深度搜索算法确定人名地名















 3557
3557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}