





 这篇博客翻译自Medium的文章,介绍了如何在两周内开始使用Spark NLP,适合初学者快速掌握。
这篇博客翻译自Medium的文章,介绍了如何在两周内开始使用Spark NLP,适合初学者快速掌握。
spark-nlp
If you want to make a head start in enterprise NLP, but have no clue about Spark, this article is for you. I have seen many colleagues wanting to step to this domain but disheartened due to the initial learning overhead that comes with Spark. It may seem inconspicuous at first glance since Spark code is a bit different than your regular Python script. However, Spark and Spark NLP basics aren’t really hard to learn. If you axiomatically accept this assertion, I will show you how easy the basics are and will provide a road map to pave the way to learn key elements, which will satisfy most use cases of an intermediate level practitioner. Due to impeccable modularity that comes with Spark NLP pipelines, for an average learner, -mark my words- two weeks will be enough to build basic models. Roll up your sleeves, here we start!
如果您想在企业级NLP中领先,但是对Spark毫无头绪,那么本文适合您。 我已经看到许多同事希望踏入这一领域,但由于Spark带来的最初学习开销而灰心。 乍一看似乎不太明显,因为Spark代码与常规Python脚本有点不同。 但是,Spark和Spark NLP基础知识并不难学习。 如果您公理地接受此主张,我将向您展示基础知识有多么简单,并将提供路线图,为学习关键要素铺平道路,这将满足中级从业人员的大多数用例。 由于Spark NLP管道随附无可挑剔的模块化,对于普通学习者来说,请记住我的话,两周就足以建立基本模型。 卷起袖子,我们开始!
Why Spark NLP?Supply and Demand is the answer: It Is The Most Widely Used Library In Enterprises! Here are a few reasons why. Common NLP packages today have been designed by academics and they favor ease of prototyping over runtime performance, eclipsing scalability, error handling, target frugal memory consumption and code reuse. Although some libraries like ‘the industrial-strength NLP library — spaCy’ might be considered an exception (since they are designed to get things done rather than doing research), they may fall short of enterprise targets when it comes to dealing with data in volume.
为什么选择Spark NLP? 供求关系就是答案:它是企业中使用最广泛的图书馆! 原因如下 。 如今,常见的NLP软件包是由学者设计的,它们倾向于简化原型设计而不是运行时性能,使可伸缩性,错误处理,目标节俭的内存消耗和代码重用黯然失色。 尽管某些库(例如“具有行业实力的NLP库-spaCy”)可能会被视为例外(因为它们是为完成任务而不是进行研究而设计的),但在处理海量数据时,它们可能无法达到企业目标。
We are going to have a different strategy here. Rather than following the crowds in the routine, we will use basic libraries to brush up ‘basics’ and then jump directly to address the enterprise sector. Our final aim is to target the niche by building continental pipelines, which are impossible to resolve with standard libraries, albeit their capacity in their league.
我们将在这里采取不同的策略 。 我们将使用基本库来整理“基础知识”,然后直接跳转到企业领域,而不是在日常工作中随波逐流。 我们的最终目标是通过建立大陆式管道来瞄准利基市场,尽管它们在同盟中是有能力的,但是标准管道无法解决这些问题。
If you are not convinced yet, please read this article for benchmarking and comparison with spaCy, which will give you five good reasons to start with Spark NLP. First of all Spark NLP has the innate trait of scalability it inherits from Spark, which was primarily used for distributed applications, it is designed to be scalable. Spark NLP benefits from this since it can scale on any Spark cluster as well as on-premise and with any cloud provider. Furthermore, Spark NLP optimizations are done in such a way that it could run orders of magnitude faster than what the inherent design limitations of legacy libraries allow. It provides the concepts of annotators and it includes more than what other NLP libs include. It includes sentence detection, tokenization, stemming, lemmatization, POS Tagger, NER, dependency parse, text matcher, date matcher, chunking, context-aware spell checking, sentiment detector, pre-trained models, and training models with very high accuracy according to academic peer-reviewed results. Spark NLP also includes production-ready implementation of BERT embeddings for named entity recognition. For example, it makes much fewer errors on NER compared to spaCy, which we tested in the second part of this article. Also, worthy of notice, Spark NLP includes features that provide full Python API, supports training on GPU, user-defined deep learning networks, Spark, and Hadoop.
如果您还不确定,请阅读本文以进行spaCy的基准测试和比较,这将为您提供五个从Spark NLP开始的良好理由。 首先,Spark NLP具有可扩展性的先天特性,它继承自Spark,Spark主要用于分布式应用程序,并且设计为可扩展的 。 Spark NLP可以从中受益,因为它可以在任何Spark集群以及内部部署和任何云提供商上进行扩展。 此外,Spark NLP优化以一种比传统库固有的设计限制所允许的运行速度快几个数量级的方式进行。 它提供了注释器的概念,并且比其他NLP库包含的内容更多。 它包括句子检测,标记化,词干提取,词形化,POS Tagger,NER,依赖性解析,文本匹配器,日期匹配器,分块,上下文感知拼写检查,情感检测器,预训练模型以及根据以下目的非常高精度的训练模型学术同行评审的结果。 Spark NLP还包括用于命名实体识别的BERT嵌入的生产就绪型实现。 例如,与spaCy相比,它在NER上产生的错误要少得多,我们在本文的第二部分对此进行了测试。 另外,值得注意的是,Spark NLP包括提供完整Python API的功能,支持有关GPU,用户定义的深度学习网络,Spark和Hadoop的培训。
The library comes with a production-ready implementation of BERT embeddings and uses transfer learning for data extraction. Transfer learning is a highly-effective method of extracting data that can leverage even small amounts of data. As a result, there’s no need to collect large amounts of data to train SOTA models.
该库带有可直接用于BERT嵌入的生产环境的实现,并使用传输学习进行数据提取。 转移学习是一种提取数据的高效方法,可以利用少量数据。 结果,无需收集大量数据即可训练SOTA模型。
Also, John Snow labs Slack channel provides top tier support that is beneficial because developers and new learners tend to band together and create resources that every one of them can benefit from. You will get answers to your questions right from the developers with dedication. I have been there a few times, can attest that they are quick and accurate in their response. Additionally, anyone finding themselves stuck can quickly get help from people that have had similar problems through Stack Overflow or similar platforms.
另外,John Snow实验室的Slack频道提供了顶级支持,这是有益的,因为开发人员和新学习者倾向于联合起来并创建每个人都可以从中受益的资源。 您将全心全意地从开发人员那里得到问题的答案。 我去过几次,可以证明他们的React是快速而准确的。 此外,任何发现自己陷入困境的人都可以通过Stack Overflow或类似平台Swift从遇到类似问题的人那里获得帮助。
Famous “Facts” About Spark That Are Wrong
关于星火的著名“事实”是错误的
- Spark is cluster computing so it can’t be run on local machines
-Spark是集群计算,因此无法在本地计算机上运行
Wrong! You can run Spark on your local machine, and each CPU core will be used to the core! That’s how it looks like when Spark NLP is in action:
错误! 您可以在本地计算机上运行Spark,并且每个CPU内核都将用于该内核! 这就是运行Spark NLP时的样子:
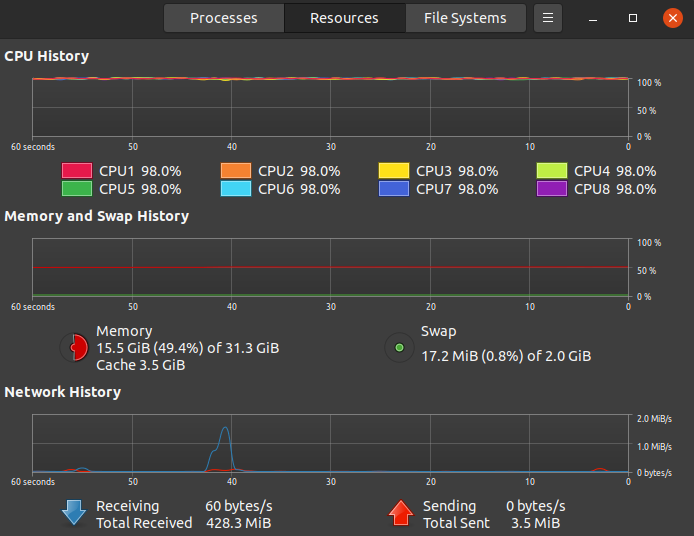
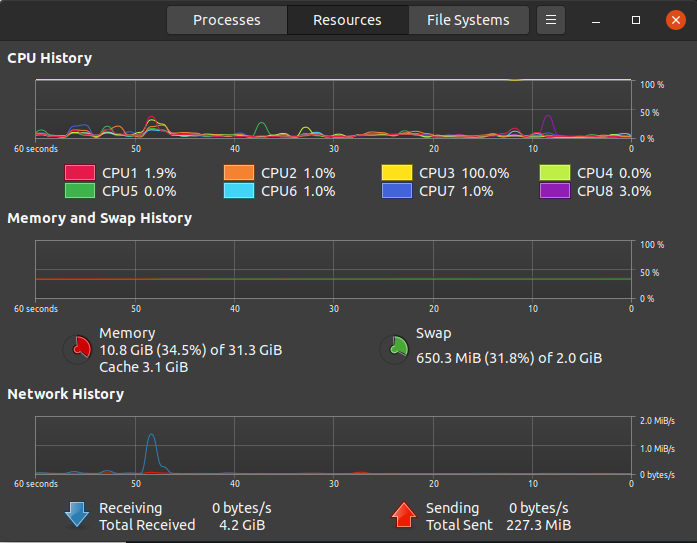
What’s even more, you can run Spark on GPU.
更重要的是,您可以在GPU上运行Spark。
- Spark is yet another language to learn!
-Spark是另一种需要学习的语言!
Well, if you know SQL, PySpark and Spark NLP is not going to feel like another language at all. SQL and Regex are all languages on their own, but it wasn’t hard to learn their basics, right?
好吧,如果您知道SQL,PySpark和Spark NLP根本不会像另一种语言。 SQL和Regex都是语言,但是学习它们的基础并不难,对吧?
- Spark is built for big data, so Spark NLP is only good for big data.
-Spark专为大数据而构建,因此Spark NLP仅适用于大数据。
Yes, there is a significant overhead used for Spark internals, but Spark NLP introduces a ‘Light Pipeline’ for smaller datasets.
是的,Spark内部使用大量开销,但是Spark NLP为较小的数据集引入了“轻管道”。
At first, Spark seems like another challenging language to learn. Spark isn’t the easiest library to comprehend, but what we will be doing in the NLP domain has been skillfully crafted in Spark NLP’s infrastructure provided by a simple API that can be easily interacted with.
最初,Spark似乎是另一种具有挑战性的语言。 Spark并不是最容易理解的库,但是我们将在NLP领域中做的事情是在Spark NLP的基础结构中精心制作的,该基础结构由易于交互的简单API提供。
While being one of the sharpest pencils in a data scientist’s toolbox, Pandas uses only a single CPU core, and in essence, it is not fast or robust enough to handle bigger datasets. Spark was designed to hurdle those deficiencies using cluster computing, and you can even run it on your local machine, assigning as many CPU cores as you want! Unfortunately, even though it runs on a local machine, pip install Pyspark is not enough to set it up, and a series of dependencies must be installed on PC and Mac. For those who want to jump into action as quickly as possible, I recommend the use of Google Colab.
虽然Pandas是数据科学家工具箱中最敏锐的铅笔之一,但它仅使用单个CPU内核,从本质上讲,它不够快或不够强大,无法处理更大的数据集。 Spark旨在通过使用群集计算来克服这些缺陷, 您甚至可以在本地计算机上运行它 , 并根据需要分配尽可能多的CPU内核! 不幸的是,即使它在本地计算机上运行,pip install Pyspark仍然不足以对其进行设置,并且必须在PC和Mac上安装一系列依赖项。 对于那些想尽快采取行动的人,我建议使用Google Colab。
1) Setting up on Mac or LinuxTo utilize Spark NLP, Apache Spark version 2.4.3 and higher must be installed. Assuming that you haven’t installed Apache Spark yet, let’s start with Java installation at first. Just go to the official website and from “Java SE Development Kit 8u191”, and install JDK 8. A necessary command-line script can be found in detail here.
1)在Mac或Linux上设置要使用Spark NLP,必须安装Apache Spark 2.4.3及更高版本。 假设尚未安装Apache Spark,首先让我们开始Java安装。 只需访问官方网站并从“ Java SE Development Kit 8u191”中安装JDK 8即可 。 可以在此处详细找到必要的命令行脚本。
2) Setting up Spark on a PC can be a little bit tricky. Having tried many methods, I found this article to be the only one that works. It also includes a clear and concise video. In addition to the provided documentation, this blog page also helped me.
2)在PC上设置Spark可能有些棘手。 尝试了许多方法之后,我发现本文是唯一可行的方法。 它还包括清晰简洁的视频。 除了提供的文档之外,此博客页面还为我提供了帮助。
3) Unless you have to run Spark on your local machine, the easiest way to get started with PySpark is using Google Colab. Since it is essentially a Jupyter Notebook that runs on Google server, you don’t need to install anything in our system locally.
3) 除非您必须在本地计算机上运行Spark,否则开始使用PySpark的最简单方法是使用Google Colab。 由于本质上是在Google服务器上运行的Jupyter Notebook,因此您无需在我们的系统中本地安装任何内容。
To run spark in Colab, first, we need to install all the dependencies in the Colab environment such as Apache Spark 2.3.2 with Hadoop 2.7, Java 8, and Findspark to locate the spark in the system. Please refer to this article for further details.
要在Colab中运行spark,首先,我们需要在Colab环境中安装所有依赖项,例如具有Hadoop 2.7,Java 8和Findspark的Apache Spark 2.3.2,以在系统中定位spark。 请参阅本文以获取更多详细信息。
import os# Install java
! apt-get install -y openjdk-8-jdk-headless -qq > /dev/null
os.environ["JAVA_HOME"] = "/usr/lib/jvm/java-8-openjdk-amd64"
os.environ["PATH"] = os.environ["JAVA_HOME"] + "/bin:" + os.environ["PATH"]
! java -version# Install pyspark
! pip install --ignore-installed -q pyspark==2.4.4# Install Spark NLP
! pip install --ignore-installed -q spark-nlp==2.4.5For PC users who don’t want to run their notebooks on Colab, I recommend installing Spark NLP on a dual boot Linux system or using WSL 2, however, this benchmarking article reflects some performance loss with WSL 2. To be more precise, I had my best Spark NLP experience after a dual boot Ubuntu 20.04 installation.
对于不想在Colab上运行笔记本电脑的PC用户,我建议在双引导Linux系统上或使用WSL 2安装Spark NLP,但是, 此基准测试文章反映了WSL 2的一些性能损失。在双重启动Ubuntu 20.04安装后,我拥有最好的Spark NLP体验。
Day 2: Spark Basics, RDD Structure, and NLP Baby Steps with Spark
第2天:Spark的Spark基础知识,RDD结构和NLP入门步骤
As previously mentioned, Apache Spark is a distributed cluster computing framework that is highly efficient for large data sets using in-memory computations for lightning-fast data processing. It is also considered to be more efficient than MapReduce for the complex application running on Disk.
如前所述,Apache Spark是一个分布式集群计算框架,对于使用内存计算进行闪电般快速数据处理的大型数据集,该框架非常高效。 对于在磁盘上运行的复杂应用程序,它也被认为比MapReduce更有效。
While libraries like pandas are adequate for most everyday operations, big data requires a cluster computing framework due to the volume, variety, and velocity, which are three defining properties or dimensions of big data.
尽管像熊猫这样的库已足以满足大多数日常操作的需要,但由于 数量,种类和速度这是大数据的三个定义属性或维度,因此大数据需要集群计算框架 。
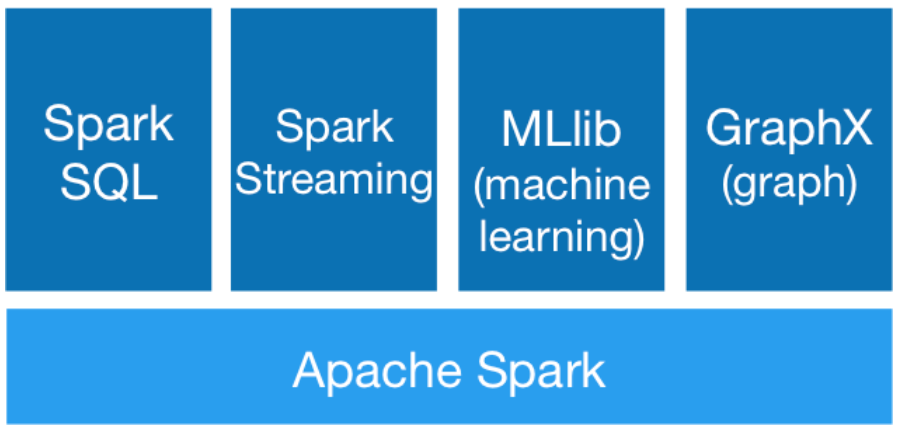
At the center of Spark is the Spark Core — the foundation of the overall project, on top of which the rest of Spark libraries are built. Spark SQL lets you query structured data inside Spark programs, using either SQL or a familiar DataFrame API.
Spark的核心是Spark Core,它是整个项目的基础,其余的Spark库则在此基础上构建。 Spark SQL可让您使用SQL或熟悉的DataFrame API在Spark程序中查询结构化数据。
MLlib fits into Spark’s APIs and interoperates with NumPy in Python and R libraries. You can use any Hadoop data source, making it easy to plug into Hadoop workflows. Spark excels at iterative computation, enabling MLlib to run fast — up to 100x faster than MapReduce.
MLlib适用于Spark的API,并与Python和R库中的NumPy互操作。 您可以使用任何Hadoop数据源,从而轻松插入Hadoop工作流。 Spark擅长于迭代计算,从而使MLlib能够快速运行-比MapReduce快100倍。
Spark Mllib contains the legacy API built on top of RDDs. Although I find Spark Mllib and RDD structure easier to use as a Python practitioner, as of Spark 2.0, the RDD-based APIs in the Spark.MLlib package has entered maintenance mode. The primary Machine Learning API for Spark is now the DataFrame-based API in the Spark ML package.
Spark Mllib包含构建在RDD之上的旧版API。 尽管我发现Spark Mllib和RDD结构更易于用作Python练习者,但从Spark 2.0开始,Spark.MLlib软件包中基于RDD的API已进入维护模式。 Spark的主要机器学习API现在是Spark ML软件包中基于DataFrame的API。
Transformations create new RDDs and actions to perform calculations. Lambda, Map, and Filter are some of the basic functions. Real datasets are generally key, value pairs similar to Python dictionaries but are represented like tuples. Please observe the code below for creating bigrams and word counts to see how similar to Python code it is. I would highly recommend this course for further details.
转换会创建新的RDD和执行计算的操作。 Lambda,Map和Filter是一些基本功能。 真实数据集通常是类似于Python字典的键,值对,但表示为元组。 请观察下面的代码来创建双字母组和单词计数,以了解它与Python代码有多相似。 我会极力推荐此课程以获取更多详细信息。
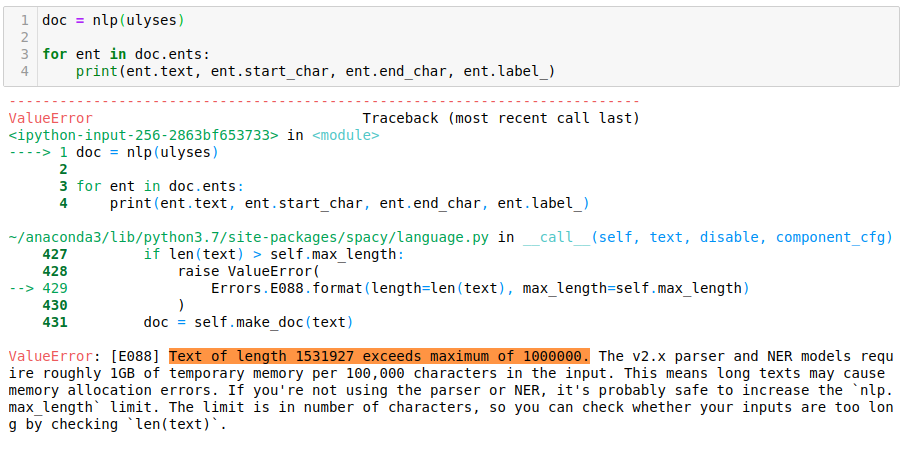
import resentences = sc.textFile(“ulyses.txt”) \
.glom() \
.map(lambda x: “ “.join(x)) \
.flatMap(lambda x: x.split(“.”)).map(lambda x: re.sub(‘[^a-zA-Z\s]’,’’,x))bigrams = sentences.map(lambda x:x.split()) \
.flatMap(lambda x: [((x[i],x[i+1]),1) for i in range(0,len(x)-1) \
if all([x[i].lower() not in stop_words,x[i+1].lower() not in stop_words])])freq_bigrams = bigrams.reduceByKey(lambda x,y:x+y) \
.map(lambda x:(x[1],x[0])) \
.sortByKey(False)In [1]:freq_bigrams.take(10)Out[1]:(1, ('Author', 'James')),
(1, ('Joyce', 'Release')),
(1, ('EBook', 'Last')),
(1, ('Last', 'Updated')),
(1, ('December', 'Language')),
(1, ('English', 'Character')),
(1, ('Character', 'set')),
(1, ('set', 'encoding')),
(1, ('UTF', 'START')),
(1, ('II', 'III'))]# word count exampletext_file = sc.textFile(“example_text1.txt”)
counts_rdd = text_file.flatMap(lambda line: line.split(“ “)) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)# print the word frequencies in descending ordercounts_rdd.map(lambda x: (x[1], x[0])) \
.sortByKey(ascending=False)\
.collect()[:10]Output
输出量
Out [3]: [(988, 'the'),
(693, 'and'),
(623, 'of'),
(604, 'to'),
(513, 'I'),
(450, 'a'),
(441, 'my'),
(387, 'in'),
(378, 'HAMLET'),
(356, 'you')]Day 3/4: Feature Engineering / Cleaning Data with Pyspark
第3/4天:使用Pyspark进行功能工程/清洁数据
Spark ML provides higher-level API built on top of DataFrames for constructing ML pipelines, standardizing APIs for machine learning algorithms to make it easier to combine multiple algorithms into a single workflow. Here we will cover the key concepts introduced by the Spark ML API.
Spark ML提供了在DataFrames之上构建的高层API,用于构建ML管道,标准化了机器学习算法的API,从而可以更轻松地将多种算法组合到单个工作流程中。 在这里,我们将介绍Spark ML API引入的关键概念。
Machine learning steps can be applied to from Spark SQL to support a variety of data types under a unified Dataset concept. A SchemaRDD can be created either implicitly or explicitly from a regular RDD.
可以在Spark SQL中应用机器学习步骤,以在统一的数据集概念下支持各种数据类型。 可以从常规RDD隐式或显式创建SchemaRDD 。
A Transformer is an abstraction which includes feature transformers and learned models, implementing a method transform() which converts one SchemaRDD into another, generally by appending one or more columns.
Transformer是一种抽象,其中包括功能转换器和学习的模型,实现了方法transform() ,该方法通常通过附加一个或多个列将一个SchemaRDD转换为另一个。
An Estimator abstracts the concept of a learning algorithm or any algorithm which fits or trains on data, implementing a method fit() which accepts a SchemaRDD and produces a Transformer. For example, a learning algorithm such as LogisticRegression is an Estimator, and calling fit() trains a LogisticRegressionModel, which is a Transformer.
Estimator抽象学习算法或适合或训练数据的任何算法的概念,实现一种接受SchemaRDD并生成Transformer的方法fit() 。 例如,诸如LogisticRegression类的学习算法是Estimator ,调用fit()训练LogisticRegressionModel ,后者是Transformer 。
In machine learning, it is common to run a sequence of algorithms to process and learn from data such as splitting each document text into words, converting words into a numerical feature vector, and training a prediction model using the feature vectors and labels. Spark ML represents such workflows as Pipelines, which consist of a sequence of Transformers and Estimators to be run in a specific order, calling transform() and fit() methods respectively, to produce a Transformer (which becomes part of the PipelineModel, or fitted Pipeline), and that Transformer’s transform() method is called on the dataset.
在机器学习中,通常需要运行一系列算法来处理和学习数据,例如将每个文档文本拆分为单词,将单词转换为数字特征向量以及使用特征向量和标签训练预测模型。 Spark ML表示这样的工作流,如Pipeline s ,它由一系列Transformers和Estimators组成,这些Transformers和Estimators以特定顺序运行,分别调用transform()和fit()方法,以生成Transformer (成为PipelineModel一部分,或者拟合Pipeline ),然后在数据集上调用Transformer的transform()方法。
A Pipeline is an Estimator. Thus, after a Pipeline’s fit() method runs, it produces a PipelineModel which is a Transformer. Once the PipelineModel’s transform() method is called on a test dataset, the data passes through the Pipeline in order, updating the data set as each stage’s transform() method updates it and passes it to the next stage.
Pipeline是Estimator 。 因此,在运行Pipeline的fit()方法之后,它将生成一个PipelineModel ,它是一个Transformer 。 在测试数据集上调用PipelineModel的transform()方法后,数据将按顺序传递通过Pipeline在每个阶段的transform()方法更新数据集并将其传递到下一个阶段时更新数据集。

Pipelines and PipelineModels help to ensure that training and test data go through identical feature processing steps. Below is an example of a pipeline model. Please note that data preprocessing is carried out on a Pandas Dataframe.
Pipeline和PipelineModel有助于确保训练和测试数据经过相同的特征处理步骤。 下面是管道模型的示例。 请注意,数据预处理是在Pandas Dataframe上进行的。
#define regex pattern for preprocessing
pat1 = r’@[A-Za-z0–9_]+’
pat2 = r’https?://[^ ]+’
combined_pat = r’|’.join((pat1,pat2))
www_pat = r’www.[^ ]+’
negations_dic = {“isn’t”:”is not”, “aren’t”:”are not”, “wasn’t”:”was not”, “weren’t”:”were not”,
“haven’t”:”have not”,”hasn’t”:”has not”,”hadn’t”:”had not”,”won’t”:”will not”,
“wouldn’t”:”would not”, “don’t”:”do not”, “doesn’t”:”does not”,”didn’t”:”did not”,
“can’t”:”can not”,”couldn’t”:”could not”,”shouldn’t”:”should not”,”mightn’t”:”might not”,
“mustn’t”:”must not”}
neg_pattern = re.compile(r’\b(‘ + ‘|’.join(negations_dic.keys()) + r’)\b’)def pre_processing(column):
first_process = re.sub(combined_pat, ‘’, column)
second_process = re.sub(www_pat, ‘’, first_process)
third_process = second_process.lower()
fourth_process = neg_pattern.sub(lambda x:\
negations_dic[x.group()], third_process)
result = re.sub(r’[^A-Za-z ]’,’’,fourth_process)
return result.strip()df[‘text’]=df.iloc[:,:].text.apply(lambda x: pre_processing(x))
df=df[~(df[‘text’]==’’)]# shuffle the data
df = df.sample(frac=1).reset_index(drop=True)
# set the random seed and split train and test with 99 to 1 ratio
np.random.seed(777)
msk = np.random.rand(len(df)) < 0.99
train = df[msk].reset_index(drop=True)
test = df[~msk].reset_index(drop=True)
# save both train and test as CSV files
train.to_csv(‘pyspark_train_data.csv’)
test.to_csv(‘pyspark_test_data.csv’)tokenizer = [Tokenizer(inputCol='text',outputCol='words')]ngrams = [NGram(n=i, inputCol='words',
outputCol='{}_grams'.format(i)) for i in range(1,4)]cv =[CountVectorizer(vocabSize=5460,inputCol='{}_grams'.format(i),\
outputCol='{}_tf'.format(i)) for i in range(1,4)]idf = [IDF(inputCol='{}_tf'.format(i),\
outputCol='{}_tfidf'.format(i), minDocFreq=5) \
for i in range(1,4)]assembler = [VectorAssembler(inputCols=['{}_tfidf'.format(i)\
for i in range(1,4)], outputCol='features')]label_stringIdx = [StringIndexer(inputCol='sentiment', \
outputCol='label')]lr = [LogisticRegression()]pipeline = Pipeline(stages=tokenizer+ngrams+cv+idf+assembler+\
label_stringIdx+lr)model = pipeline.fit(train_set)predictions = model.transform(test_set)In PySpark, interactions with SparkSQL through DataFrame API and SQL queries are priority subjects to learn. Pyspark.sql module must be perused for a better understanding of basic operations. DataFrame transformations and actions are not too hard to construct programmatically and operations on DataFrames can also be done using SQL queries. If you have time to take only one course, please spend it on Feature Engineering with Pyspark course by John Hogue. This course is also recommended, time permitting (Day 5).
在PySpark中,通过DataFrame API和SQL查询与SparkSQL的交互是需要学习的优先主题。 必须仔细阅读Pyspark.sql模块才能更好地了解基本操作。 DataFrame的转换和操作不太容易以编程方式构造,并且对DataFrame的操作也可以使用SQL查询来完成。 如果您只有时间参加一门课程,请在John Hogue的“ 功能工程与Pyspark课程”上花费。 在时间允许的情况下(第5天),也建议您参加此课程 。
Day 6/7: Practice Makes Perfect
第6/7天:练习变得完美
The best way to learn is practice. You will need a hardened skill set for next week. Try to deep dive into Pyspark modules, since you will be extensively using them. To re-iterate “First Steps With PySpark and Big Data Processing”, please follow these exercises. It is a recommended practice to download some datasets from Kaggle or Project Gutenberg and solve pre-processing problems, as well as others. Please follow this excellent notebook from the creators of Spark NLP. For additional resources, please observe this notebook and this article.
最好的学习方法是练习。 下周您将需要强化技能。 尝试深入研究Pyspark模块,因为您将广泛使用它们。 要重复“使用PySpark和大数据处理的第一步” ,请遵循以下练习 。 建议您从Kaggle或Project Gutenberg下载一些数据集并解决预处理问题以及其他问题。 请关注Spark NLP创作者的这款出色笔记本 。 有关其他资源,请阅读本笔记本和本文 。
Next Up: Part II — How to Wrap Your Head Around Spark NLP. In this part, we will understand “Annotators /Transformers in Spark NLP” and emphasize “Text Preprocessing with Spark”, “Pretrained Models” and “Text Classifiers” using numerous notebooks. Moreover, we will run a complete pipeline with spaCy and SparkNLP and compare the results.
下一步:第二部分-如何绕过Spark NLP。 在这一部分中,我们将了解“ Spark NLP中的注释器/变形器”,并着重介绍使用大量笔记本的“使用Spark进行文本预处理”,“预训练模型”和“文本分类器”。 此外,我们将使用spaCy和SparkNLP运行完整的管道并比较结果。
翻译自: https://towardsdatascience.com/how-to-get-started-with-sparknlp-in-2-weeks-cb47b2ba994d
spark-nlp















 391
391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









