





Many of us start our careers in Data Science without a strong software engineering background. While this might not be a problem at first, your notebook will get much slower and you will struggle to maintain it as your code gets more and more complex. The goal of this post is to help you write clean, readable, and yet performant code. This post is not meant to be an exhaustive guide on how to be a better programmer, but I hope you can find something useful in it to improve your coding skill.
我们中的许多人在没有强大软件工程背景的情况下就开始了数据科学事业。 虽然起初这可能不是问题,但随着代码变得越来越复杂,您的笔记本将变得越来越慢,并且您将难以维护它。 这篇文章的目的是帮助您编写简洁,可读且性能卓越的代码。 这篇文章并不是要成为如何成为一个更好的程序员的详尽指南,但我希望您能从中找到有用的东西来提高您的编码技能。
1.循环遍历DataFrame行(简短答案:不要!) (1. Looping over DataFrame rows (Short answer: Don’t! ))
I think this is one of the most common mistakes of someone who does analytical programming for the first time. This answer from StackOverflow explained it quite nicely.
我认为这是第一次进行分析编程的人中最常见的错误之一。 他从StackOverflow得到的答案很好地解释了这一点。
Iteration in pandas is an anti-pattern, and is something you should only do when you have exhausted every other option. You should not use any function with “iter” in its name for more than a few thousand rows or you will have to get used to a *lot* of waiting.
熊猫中的迭代是一种反模式,只有在用尽所有其他选项后才应执行此操作。 您不应在名称中使用带有“ iter”功能的函数超过数千行,否则您将不得不习惯大量的等待。
In my opinion, you are most likely doing something wrong if you are iterating over rows on your data. To speed up your data processes, you need to use the built-in pandas or numpy functions because it’s so much faster and easier.
我认为,如果要遍历数据中的行,则很可能会出错。 为了加快数据处理速度,您需要使用内置的pandas或numpy函数,因为它是如此的快捷和简便。
For example, take a look at this for-loop:
例如,看一下这个for循环:
for index, row in df.iterrows():
if row['room_size'] <= 36
row['category'] = 'small'
else:
row['category'] = 'large'This can be done easily using numpy:
这可以使用numpy轻松完成:
df['category'] = np.where(df['room_size'] <= 36, 'small', 'large')Probably the best benefit of using numpy/pandas function is that they are magnitudes faster than a for-loop. Take a look at the chart comparing running time of pandas function vs iteration below. If you use pandas or numpy functions, your code will be vectorised under the hood. This means that instead of working on a single value at a time, these libraries perform an operation on all your rows at once which makes your data processes blazing fast.
使用numpy / pandas函数的最大好处可能是它们比for循环快很多。 请看下面的图表,比较熊猫函数与迭代的运行时间。 如果使用pandas或numpy函数,则代码将在后台进行矢量化处理。 这意味着这些库不是一次处理单个值,而是一次对所有行执行一个操作,这使您的数据处理快速进行。
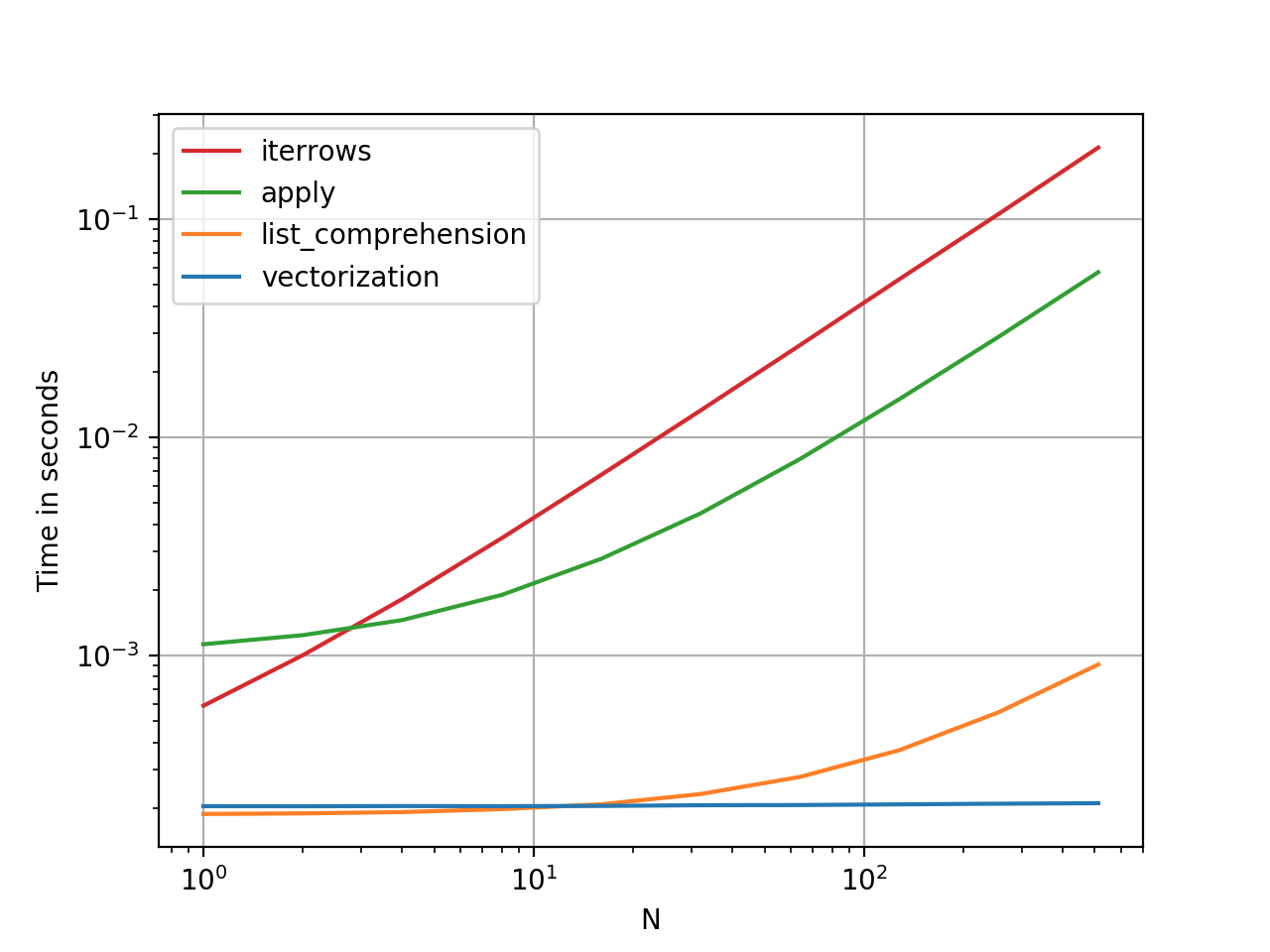
Here are some other examples of DataFrame operations which you can do using pandas:
以下是一些其他可以使用pandas进行的DataFrame操作示例:
根据其他列的操作创建一个新列: (Creating a new column based on operations of other columns :)
df['c4'] = (df['c1'] — df['c2']) * df['c3']/100向上或向下移动列: (Shifting a column up or down :)
df['c1'] = df['c1'].shift(periods=1) # Shifting up one column
df['c1'] = df['c1'].shift(periods=-1) # Shifting down one column切片列: (Slicing a column :)
df = df[start_index:end_index].copy()填充N / A值: (Filling N/A value :)
df.fillna('bfill',inplace=True)The great thing is, you can do most data manipulation using pandas or numpy built-in functions. I can only think of a few use cases which can only be done using iteration such as training your ML model or doing RegEx. So do check numpy or pandas documentation (or StackOverflow) if you want to do a data manipulation that you haven't done before.
很棒的是,您可以使用pandas或numpy内置函数来执行大多数数据操作。 我只能想到一些只能通过迭代来完成的用例,例如训练您的ML模型或执行RegEx。 因此,如果要执行以前从未做过的数据操作,请检查numpy或pandas文档(或StackOverflow)。
2. SettingWithCopyWarning(),了解视图与副本 (2. SettingWithCopyWarning(), understanding views vs copies)
If you have worked using pandas, you might have encountered this warning before.
如果您使用过熊猫,那么您以前可能会遇到此警告。
SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value insteadThis warning can result from many things but I think the most common cause stems from an unclear understanding of view and copy. A view is, as the term suggests, a view into the original data, so modifying the view may modify the original object. For example:
该警告可能是由许多原因引起的,但我认为最常见的原因是由于对视图和复制的理解不清楚。 视图是,顾名思义,视图成原来的数据,因此要修改的视图可以修改原始对象。 例如:
# df2 will return a view
df2 = df[['A']]
df2['A'] /= 2The operation above will result in SettingWithCopyWarning. Code above will change the value of column A on df even though you only do an operation on df2. To fix this, you must use .copy() to create a new object based on df[‘A’] to df2
上面的操作将导致SettingWithCopyWarning 。 即使您仅对df2进行操作,上述代码也会更改df A列的值。 要解决此问题,必须使用.copy()创建基于df['A']到df2的新对象
# df2 will return a copy
df2 = df[['A']].copy()
df2['A'] /= 2The code above will return a copy, which is an entirely new object. In the code above, changing df2 will not change df. In fact, you should use .copy() everytime you create a new dataframe based on an existing dataframe to avoid the infamousSettingWithCopyWarning.
上面的代码将返回一个copy ,这是一个全新的对象。 在上面的代码中,更改df2不会更改df 。 实际上,每次基于现有数据SettingWithCopyWarning创建新数据.copy() ,都应使用.copy()以避免臭名昭著的SettingWithCopyWarning 。
3.编写干净的代码 (3. Write clean code)
It is widely known that Data Scientists write terrible code. This is not surprising because much of the code written by data scientists are for EDA, rapid prototyping, and one-off analyses. The fact that your code might someday be modified or read by other people probably doesn’t cross your mind. To quote a better programmer than me, “Code is read much more often than it is written, so plan accordingly”. Here are a few tips from me on how to write better code.
众所周知,数据科学家会编写糟糕的代码。 这不足为奇,因为数据科学家编写的许多代码都用于EDA,快速原型设计和一次性分析。 您的代码有一天可能会被其他人修改或读取的事实可能并没有引起您的注意。 用比我更好的程序员的话来说,“代码的读取次数比编写的要多,因此要相应地计划”。 这里有一些关于如何编写更好代码的提示。
避免使用非描述性的变量名 (Avoid non-descriptive variable names)
Never write short and non-descriptive variable names like i, j, X, Y in your code. Instead, write descriptive variable name such as row_index, column_index, train_data, test_data. This will make you type your variable longer but trust me it will save you a lot of time in the future when you are trying to modify/debug your code.
切勿在代码中编写简短的,非描述性的变量名,例如i , j , X , Y 。 而是编写描述性变量名称,例如row_index , column_index , train_data和test_data 。 这将使您键入变量的时间更长,但是请相信我,它将在将来尝试修改/调试代码时为您节省很多时间。
# Avoid (❌) - Non-descriptive variable names
n, x, y = data.shape# Prefer (✅) - Clear, descriptive variable names
no_of_images, image_width, image_height = data.shape命名和格式约定 (Naming and formatting conventions)
Having consistent naming guidelines will be beneficial to you and your team. It will make anyone who reads your code understand it faster and make your code generally much better to look at. Since most data science code is written in python, I’m going to share a few of the PEP8 naming convention:
拥有一致的命名准则将对您和您的团队有益。 它将使任何阅读您的代码的人都更快地理解它,并使您的代码通常看起来更好。 由于大多数数据科学代码都是用python编写的,因此我将分享一些PEP8命名约定:
Variable/function names are lower_case and separated_with_underscores
变量/函数名称为小写和分隔的_下划线
Constant names are in ALL_CAPITAL_LETTERS
常量名称在ALL_CAPITAL_LETTERS中
Class names should normally use the CamelCase
类名通常应使用CamelCase
As for formatting, since python disallows mixing the use of tabs and spaces for indentation it is better to stick to one format. PEP8 has a very opinionated view on python formatting, a few of them are:
至于格式,由于python不允许混合使用制表符和空格进行缩进,因此最好坚持一种格式。 PEP8对python格式有很坚定的看法,其中一些是:
Use 4-spaces instead of tabs (if you use VS Code you can automatically convert tabs to spaces)
使用4个空格而不是制表符(如果使用VS Code,则可以将制表符自动转换为空格)
- Surround top-level function and class definitions with two blank lines. 用两个空行包围顶级函数和类定义。
- Wrap long lines by using Python’s implied line continuation inside parentheses, brackets and braces 通过在括号,方括号和大括号内使用Python的隐含行连续来换行
# Long function
foo = long_function_name(var_one, var_two,
var_three, var_four)保持您的代码干燥(不要重复自己) (Keep your code DRY (Don’t repeat yourself))
Consider refactoring the same value you use throughout your code to a single variable in a separate section of your code, or better yet, in a separate JSON file. It will save you a lot of time in the future because if you want to change that same value throughout your code, you can do so by changing one variable. This practice will also avoid a common coding anti-pattern called magic number in which unique values with unexplained meaning are hard-coded directly in the source code.
考虑将在整个代码中使用的相同值重构为代码的单独部分中的单个变量,或者最好将其重构为单独的JSON文件中的单个变量。 它将为您节省很多时间,因为如果您想在代码中更改相同的值,可以通过更改一个变量来实现。 这种做法还将避免使用称为幻数的通用编码反模式,在反模式中,具有无法解释含义的唯一值将直接在源代码中进行硬编码。
# Avoid (❌) - Unexplained 'magic' number
model = models.Sequential()
model.add(layers.LSTM(60, activation='relu', input_shape=(10, 3)))# Prefer (✅) - Clear value names and meaning
neurons = 60
no_of_timesteps = 10
no_of_feature = len(df.columns)
activation = 'relu'
model = models.Sequential()
model.add(layers.LSTM(neurons,
activation= activation, input_shape=(no_of_timesteps, dimensions)))This also holds true for your procedures, instead of writing long data processing procedures in your notebook, it is better to group similar procedures and refactor them to a single function instead. Then, you can call all of the refactored functions in a single chained execution using pandas .pipe() function.
这对于您的过程同样适用,与其将较长的数据处理过程写在笔记本中,不如将相似的过程分组并将其重构为单个函数,这更好。 然后,您可以使用pandas .pipe()函数在一个链式执行中调用所有重构的函数。
# Avoid (❌) - Long, sequential procedures
df = pd.read_csv(‘data/train.csv’)
df[‘price_per_sqft’] = df[‘price’] / df[‘sqft’]
df[‘c1’].fillna(0, inplace=True)
df[‘c2’].fillna(method=‘bfill’, inplace=True)
df[‘c3’].fillna(df.groupby([‘c1,c2’])[‘c3’].transform(‘mean’))# Prefer (✅) - Separation of functions and chained executions
PATH = ‘data/train.csv’def load_data(path):
return pd.read_csv(path)def calculate_price_per_sqft(df):
df[‘price_per_sqft’] = df[‘price’] / df[‘sqft’]def imputate_missing_values(df):
df[‘c1’].fillna(0, inplace=True)
df[‘c2’].fillna(method=‘bfill’, inplace=True)
df[‘c3’].fillna(df.groupby([‘c1,c2’])[‘c3’].transform(‘mean’))
return dfdf = load_data(PATH)
result = (
df.pipe(calculate_price_per_sqft)
.pipe(imputate_missing_values)
)4.将数据保存和加载到.csv文件中 (4. Saving and Loading data in a .csv file)
It is common practice to save your data to CSV using .to_csv() function as you can see in many kaggle notebooks. But CSVs are actually not a good format to store large data because it is schemaless, so you have to parse dates and numbers when you load your data. CSV file is also uncompressed which means large dataset will take up a lot of memory and will be very slow to save and load. Take a look at the chart comparing dataframe save and load time below.
在许多kaggle笔记本中可以看到,通常的做法是使用.to_csv()函数将数据保存为CSV。 但是CSV实际上不是存储大数据的一种好格式,因为它是无模式的,因此在加载数据时必须解析日期和数字。 CSV文件也未压缩,这意味着大型数据集将占用大量内存,并且保存和加载速度非常慢。 请看下面的图表,比较数据框的保存和加载时间。
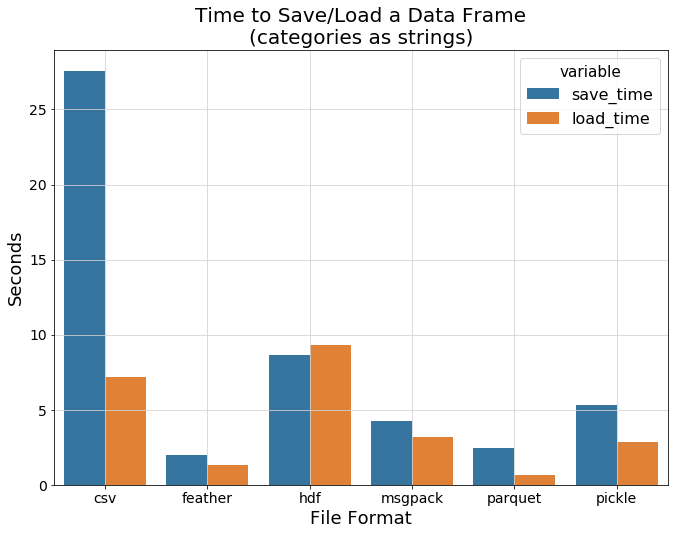
We can see that feather and parquet are magnitudes faster than CSV. How about the file size comparison?
我们可以看到羽毛和镶木地板比CSV快几个数量级。 文件大小比较如何?
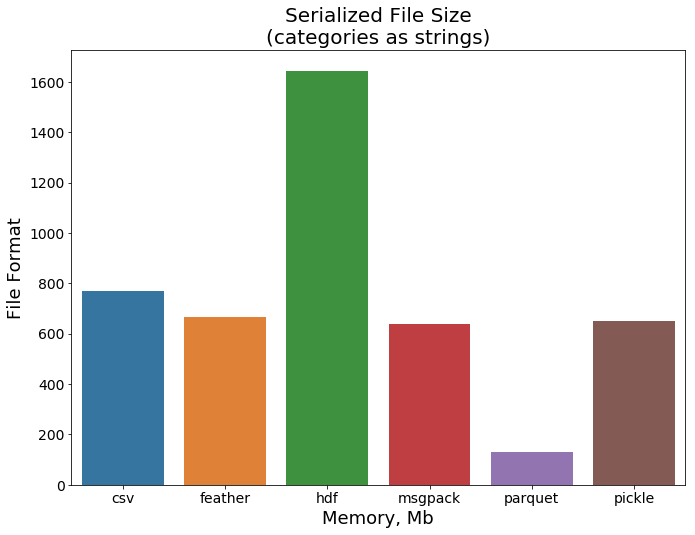
This time parquet blows other data format to the dust. Based on this comparison, I recommend to save your data in parquet format because it is a lot faster and is supported by pandas. You can save your data in .parquet by using pandas .to_parquet() function.
这次的实木复合地板把其他数据格式吹到了尘土。 基于此比较,我建议将数据保存为实木复合地板格式,因为它速度更快,并且受熊猫支持。 您可以使用pandas .to_parquet()函数将数据保存在.parquet中。
# Avoid (❌) - Saving and loading in CSV
df = pd.read_csv('raw_dataset.csv')
df.to_csv('results.csv')# Prefer (✅) - Saving and loading data using parquet
df = pd.read_parquet('raw_dataset.parquet')
df.to_parquet('results.parquet')5.构建项目 (5. Structuring your project)
Doing your analyses, visualization, feature engineering, and building your ML model in a single jupyter notebook might seem like a good idea at first. Granted, it is very easy to fire up a notebook and start working on your dataset, but if you did not structure your code carefully at the beginning things will get very messy very quickly. Structuring your project will reduce the complexity of your code and make it easier to maintain. For starter, you can put functions you create that you find useful in a separate module called data_processor.py and import it to your jupyter notebook.
首先,在单个jupyter笔记本中进行分析,可视化,功能工程以及构建ML模型似乎是一个好主意。 诚然,启动笔记本并开始处理数据集非常容易,但是如果您在开始时没有仔细构建代码,事情将很快变得非常混乱。 对项目进行结构化将减少代码的复杂性,并使其易于维护。 对于初学者,您可以将创建的有用函数放在一个单独的名为data_processor.py模块中,并将其导入到jupyter笔记本中。
// data_processor.pyimport pandas as pddef imputate_missing_values(df):
df['c1'].fillna(0, inplace=True)
df['c2'].fillna(method='bfill', inplace=True)
df['c3'].fillna(df.groupby(['c1','c2'])['c3'].transform('mean'))
return dfdef calculate_moving_averages(df):
df['moving_average'].fillna(0, inplace=True)
return dfIn your jupyter notebook, you can import the module that you have created and use it using .pipe() function (I’m a fan of .pipe() function).
在jupyter笔记本中,您可以导入创建的模块,并通过.pipe()函数使用它(我是.pipe()函数的粉丝)。
// your_notebook.ipynbimport data_processor.py as dpresult = (
df.pipe(calculate_price_per_sqft)
.pipe(imputate_missing_values)
)Next, you can separate them even further into modules called visualization.py, data_processing.py, build_model.py, etc.
接下来,您可以将它们进一步分离为名为visualization.py , data_processing.py , build_model.py等模块。
In fact, you can structure your projects however you want as long as each modules in your project conforms to the Single Responsibility Principle. To quote wikipedia,
实际上,只要您的项目中的每个模块都符合“单一职责原则” ,就可以根据需要构建项目。 引用维基百科,
The Single Responsibility Principle (SRP) is a computer programming principle that states that every module or class should have responsibility over a single part of the functionality provided by the software, and that responsibility should be entirely encapsulated by the class. All its services should be narrowly aligned with that responsibility.
单一职责原则(SRP)是一种计算机编程原则,它指出每个模块或类都应对软件提供的功能的单个部分负责,并且责任应由类完全封装。 它的所有服务都应严格地与这一责任保持一致。
Or if you want a ready-made template check out cookiecutter data science which does all of the things mentioned above for you.
或者,如果您想使用现成的模板,请查看cookiecutter数据科学,它可以为您完成上面提到的所有事情。
结论 (Conclusions)
This post contains the mistakes I’ve made and useful techniques I have learned along the way in my journey as a Data Scientist. I am not claiming that these methods are perfect, but I hope that this article will be helpful for beginner Data Scientists starting their career.
这篇文章包含了我在做数据科学家的过程中所犯的错误和有用的技术。 我并不是说这些方法是完美的,但我希望本文对初学者数据科学家有所帮助。
I am a beginner Data Scientist passionate in extracting value from data. You can reach me on Twitter @faisalrasbihan. I welcome constructive feedback and critics.
我是一位初学者,非常热衷于从数据中提取价值的数据科学家。 您可以通过Twitter @faisalrasbihan与我联系。 我欢迎建设性的反馈和批评。
References :[1] https://medium.com/r?url=https%3A%2F%2Ftowardsdatascience.com%2Ftop-10-coding-mistakes-made-by-data-scientists-bb5bc82faaee[2] https://towardsdatascience.com/data-scientists-your-variable-names-are-awful-heres-how-to-fix-them-89053d2855be[3] https://towardsdatascience.com/the-best-format-to-save-pandas-data-414dca023e0d
参考文献:[1] https://medium.com/r?url=https%3A%2F%2Ftowardsdatascience.com%2Ftop-10-coding-mistakes-made-by-data-scientists-bb5bc82faaee [2] https:/ /towardsdatascience.com/data-scientists-your-variable-names-are-awful-heres-how-to-fix-them-89053d2855be [3] https://towardsdatascience.com/the-best-format-to-save -pandas-data-414dca023e0d
[4] https://www.practicaldatascience.org/html/views_and_copies_in_pandas.html
[4] https://www.practicaldatascience.org/html/views_and_copies_in_pandas.html















 1734
1734

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









