





Threads, Processes, Cluster — What to choose when
线程,进程,群集-何时选择
In the previous story, we had a deep dive into the dask dataframes. We saw how they are lazy and will perform computations only when forced to, using the .compute() method. Otherwise, they just generate the task graph of the computation to be performed. However, does .compute() guarantee that the task is parallelized using the most efficient way? Not always. In this post, we will have a look at the different schedulers that can be employed to parallelize code execution and determine which scheduler to use when.
在上一个故事中 ,我们深入研究了dask数据框。 我们看到了它们是多么懒惰,并且只有在被迫使用.compute()方法时才会执行计算。 否则,它们只是生成要执行的计算的任务图。 但是, .compute()保证使用最有效的方法并行化任务? 不总是。 在本文中,我们将介绍可用于并行化代码执行并确定何时使用哪个调度程序的不同调度程序。
目录: (Table of Contents:)
-
-
--
-
--
-
--
Visualizing the difference between threads and processes using Task Manager
机器规格: (Machine Specifications:)
The machine specifications are as follows:
机器规格如下:
- RAM: 12 GB 内存:12 GB
- Number of Cores: 4 核心数:4
- Processor: Intel Core i7 8565 U 处理器:Intel Core i7 8565 U
- Processor speed: 1.8 GHz (up to 4.6 GHz) 处理器速度:1.8 GHz(最高4.6 GHz)
Each core has two threads, so a maximum of 8 threads are possible.
每个内核有两个线程,因此最多可以有8个线程。
调度程序的类型: (Types of Schedulers:)

The official dask documentation is an excellent resource for this section. Specifically for a single machine, you have the following options available:
正式的dask文档是本节的绝佳资源。 专门针对单台计算机,您可以使用以下选项:
流程: (Processes:)
Processes are independent programs. Processes, in fact, further parallelize their operations using threads. They are more resource-hungry and their creation and termination take more time than threads. They don’t exchange data, memory, or resources. As per the dask documentation, when parallelizing tasks using processes,
流程是独立的程序。 实际上,进程使用线程进一步并行化其操作。 它们比资源消耗更多的资源,并且它们的创建和终止花费更多的时间。 它们不交换数据,内存或资源。 根据最新文档,在使用流程并行化任务时,
Every task and all of its dependencies are shipped to a local process, executed, and then their result is shipped back to the main process.
每个任务及其所有依赖项都被传送到本地进程,执行,然后其结果被传送回主进程。
Evidently, the processes have higher task overheads than threads. One important thing to note is that a process is isolated from other processes. It has its own memory space and the OS makes sure that it remains isolated.
显然,进程比线程具有更高的任务开销。 需要注意的重要一件事是一个进程与其他进程是隔离的。 它具有自己的内存空间,并且OS确保保持隔离状态。
线程数: (Threads:)
Threads are what allow a process to execute its tasks parallelly. They are essentially segments of a process. They are less resource-hungry and can be created and terminated quickly. They can share data, memory, and resources. They have very little task overheads (~50us). This means that if a task takes x seconds to execute, running it on a thread will take x seconds + 50us.
线程允许进程并行执行其任务。 它们本质上是过程的一部分。 它们消耗的资源较少,可以快速创建和终止。 他们可以共享数据,内存和资源。 他们的任务开销很小(〜50us)。 这意味着,如果一项任务需要x秒才能执行,那么在线程上运行该任务将花费x秒+ 50us。
Dask分布式(单机): (Dask Distributed (Single Machine):)
You can consider this as a clone of dask distributed running on a cluster of machines. It gives you higher flexibility. You can set the number of workers (processes), define the number of threads per process, and so on. It also provides you with a diagnostic dashboard to view the progress of the computation. Also, it provides an asynchronous API, Futures. This is helpful because you can then perform the computation in the background in a non-blocking mode. You can submit a computation to the cluster and it will return a Future. The cluster will then perform the computation in the background and you can carry on with your other computations. Whenever required, you can query the results of the cluster computation using the .result() method on the Future. If the result is ready, it will be returned. To know more about how to create a cluster on your local machine, you can go through this short tutorial.
您可以将其视为在机器集群上运行的dask分布式副本。 它给您更高的灵活性。 您可以设置工作程序(进程)的数量,定义每个进程的线程数量,等等。 它还为您提供了一个诊断仪表板,以查看计算进度。 而且,它提供了一个异步API,即Futures 。 这很有用,因为您随后可以在非阻塞模式下在后台执行计算。 您可以将计算提交到集群,它将返回一个Future。 然后,群集将在后台执行计算,您可以继续进行其他计算。 无论何时需要,都可以在Future上使用.result()方法查询集群计算的.result() 。 如果结果准备好,它将被返回。 要了解有关如何在本地计算机上创建集群的更多信息,可以阅读本简短教程 。
So while dask distributed does provide some useful features, at the core of the computations lie processes and threads. Thus, how fast your computation will run will depend on how it is organized into processes and threads. So let’s focus on these two.
因此,虽然分布式分布式确实提供了一些有用的功能,但计算的核心在于进程和线程。 因此,您的计算运行速度将取决于如何将其组织到进程和线程中。 因此,让我们专注于这两个。
Reading the above descriptions would have convinced you that threads are superior compared to processes. They have lower overheads, consume fewer resources, and can even share data. Then why are we even considering processes? This is because of the limitations imposed by Python’s Global Interpreter Lock (GIL).
阅读上面的描述将使您确信线程比进程优越。 它们的开销较低,消耗的资源更少,甚至可以共享数据。 那我们为什么还要考虑流程呢? 这是由于Python的全局解释器锁定(GIL)施加的限制。
Spoilsport — Python的全局解释器锁定: (The Spoilsport — Python’s Global Interpreter Lock:)
In layman terms, python’s GIL ensures that only one python instruction is carried out across all threads of a process at a time. So if a process has 5 threads which want to, say find the lengths of different strings. At any given time, only one thread will be able to perform that operation while the others will wait for this thread to finish. So essentially, that kills parallelism using threads if you are performing a python task. If you want to learn more about GIL in python, especially why it exists in the first place, you can refer to the several results that show up with a quick Google search. A detailed study of python’s GIL is beyond the scope of this post.
用外行术语来说,python的GIL确保一次只能跨进程的所有线程执行一条python指令。 因此,如果一个进程有5个想要的线程,则说找到不同字符串的长度。 在任何给定时间,只有一个线程将能够执行该操作,而其他线程将等待该线程完成。 因此,从本质上讲,如果您正在执行python任务,则使用线程会杀死并行性。 如果您想了解有关python中GIL的更多信息,尤其是为什么它首先存在,您可以参考快速Google搜索显示的几个结果。 python的GIL的详细研究超出了本文的范围。
Dask’s documentation states that we should use threads to parallelize operation only when our tasks are dominated by non-Python code. However, if you just call .compute() on a dask dataframe, it will by default use threads to parallelize the execution. To use processes, you need to specify the scheduler as an argument, like .compute(scheduler=’processes’).
Dask的文档指出,仅当我们的任务由非Python代码主导时,才应使用线程来并行化操作。 但是,如果仅在dask数据帧上调用.compute() ,则默认情况下它将使用线程来并行执行。 要使用进程,您需要将调度程序指定为参数,例如.compute(scheduler='processes') 。
Let us look at an example to understand the difference between threads and processes in more detail.
让我们看一个示例,以更详细地了解线程和进程之间的区别。
示例—延迟和计算: (Example — Delays and Computations:)
We will use a short version of the dataframe used in the previous post. We have taken the first 50,000 rows of that dataframe and stored them in a new CSV called ‘lat_lon_short.csv’. Let us load that CSV into a dask dataframe, set the index, and partition it.
我们将使用上一篇文章中使用的数据框的简短版本。 我们已经获取了该数据帧的前50,000行,并将它们存储在名为“ lat_lon_short.csv”的新CSV中。 让我们将该CSV加载到dask数据框中,设置索引并对其进行分区。
dfdask = dd.read_csv('data/lat_lon_short.csv')
dfdask = dfdask.set_index('serial_no',sorted=True)
dfdask = dfdask.repartition(npartitions=8)Now we will perform two rather weird operations on this dataframe. Weird because you won’t generally perform such operations on a real dataframe. However, these operations help illustrate the point.
现在,我们将在此数据帧上执行两个相当奇怪的操作。 很奇怪,因为您通常不会在真实数据帧上执行此类操作。 但是,这些操作有助于说明这一点。
操作一: (Operation 1:)
dfdask['test1'] = dfdask.apply(lambda row: str(row.latitude)+'-'+str(test_fun()),axis=1, meta=('str'))Here we are applying a lambda function on the dataframe, which converts the latitude into a string and appends the output of the test_fun function to that string, and stores the result in a new column. The test_fun is defined as follows:
在这里,我们在数据帧上应用lambda函数,该函数将纬度转换为字符串,并将test_fun函数的输出附加到该字符串,然后将结果存储在新列中。 test_fun的定义如下:
def test_fun():
time.sleep(0.01)
return 5So the test_fun returns a value of 5 after a delay of 10 ms.
因此,test_fun在延迟10毫秒后返回值5。
操作2: (Operation 2:)
dfdask['test2'] = dfdask.apply(lambda row: len(row.test1),axis=1, meta=('int'))This operation just outputs the length of the string created in the previous operation, and stores it in a new column.
此操作仅输出在上一个操作中创建的字符串的长度,并将其存储在新列中。
Now let us look at the results:
现在让我们看一下结果:
结果: (Results:)
Time taken (in s) for .compute() when only operation 1 is performed:
仅执行操作1时 .compute()花费的时间(以秒为单位):

Time taken (in s) for .compute() when both operations are performed:
执行两个操作时 .compute()花费的时间(以秒为单位):

推论: (Inferences:)
There is a lot to unpack here. Let’s go over the inferences one by one.
这里有很多要解压的东西。 让我们一一介绍一下推论。
The time with processes was lower when performing both operations, but it was higher when performing just operation 1.
在执行这两项操作时,使用进程的时间减少,但仅执行一项操作时,处理时间增加。
This observation is the most important to understand the difference between processes and threads. You need to understand that a delay introduced by time.sleep() is rather a lack of instruction. The thread remains idle for the duration of that delay. Therefore, other threads can execute in that period. Therefore, with operation 1 alone, threads can operate in parallel, just like the processes. Hence, the only differentiating factor is the overhead, which is higher for processes than for threads. Therefore, with only operation 1, the threads are faster than the processes.
这种观察对于理解进程和线程之间的差异是最重要的。 您需要了解time.sleep()引入的延迟是缺乏指令的。 在该延迟期间,线程保持空闲状态。 因此,其他线程可以在该时间段内执行。 因此,仅使用操作1,线程就可以并行运行,就像进程一样。 因此,唯一的区别因素是开销,进程的开销比线程的开销高。 因此,仅使用操作1,线程比进程快。
Operation 2, however, involves python instructions. Therefore, python’s GIL swings into action and ensures that only one thread executes the instruction at a time. Therefore, threads perform operation 2 serially. On the other hand, processes are independent, and therefore, they perform operation 2 parallelly and return the results much faster with operation 2. Thus, when both the operations are performed, the time saved by processes during operation 2 compensates for the extra overhead. Therefore, the result is that processes take lesser time than threads when performing both the operations.
但是,操作2涉及python指令。 因此,Python的GIL付诸行动,并确保一次只有一个线程执行该指令。 因此,线程串行执行操作2。 另一方面,进程是独立的,因此它们并行执行操作2,并通过操作2更快地返回结果。因此,当同时执行两个操作时,操作2期间进程节省的时间补偿了额外的开销。 因此,结果是在执行这两个操作时,进程所花费的时间少于线程。
The time, as expected, did not change on increasing the number of partitions beyond 8.
如所预期的,时间不会因将分区数增加到8以上而改变。
As explained in the Machine Specifications section, the machine has 4 cores and therefore a maximum of 8 threads/ processes can be run in parallel.
如“机器规格”部分所述,该机器具有4个核心,因此最多可以并行运行8个线程/进程。
The time difference between threads and processes is nearly constant (3–4 seconds) when only operation 1 is performed
仅执行操作1时,线程和进程之间的时间差几乎恒定(3-4秒)
Once again, since the only difference between threads and processes is going to be because of overheads when performing operation 1, it is independent of the number of partitions. When there is 1 partition, only one process is created. When there are 8 partitions, 8 processes are created. But the overhead is equal to the overhead of 1 partition. This is because all 8 are running in parallel. When there are more than 8 partitions, again, only 8 processes are created because of hardware limitations. Each process handles multiple partitions. That’s what the time difference suggests.
再一次,由于线程和进程之间的唯一区别将是执行操作1时的开销,因此它与分区数无关。 当有1个分区时,仅创建一个进程。 当有8个分区时,将创建8个进程。 但是开销等于1个分区的开销。 这是因为所有8个都并行运行。 当分区多于8个时,由于硬件限制,只能创建8个进程。 每个进程处理多个分区。 那就是时差所暗示的。
使用任务管理器可视化线程和进程之间的差异 (Visualizing the difference between threads and processes using Task Manager)
If you are on a Windows machine, the Task Manager also illustrates the difference between threads and processes.
如果您使用的是Windows计算机,则任务管理器还会说明线程和进程之间的区别。
When you are running threads, the task manager will look something like this:
当您运行线程时,任务管理器将如下所示:
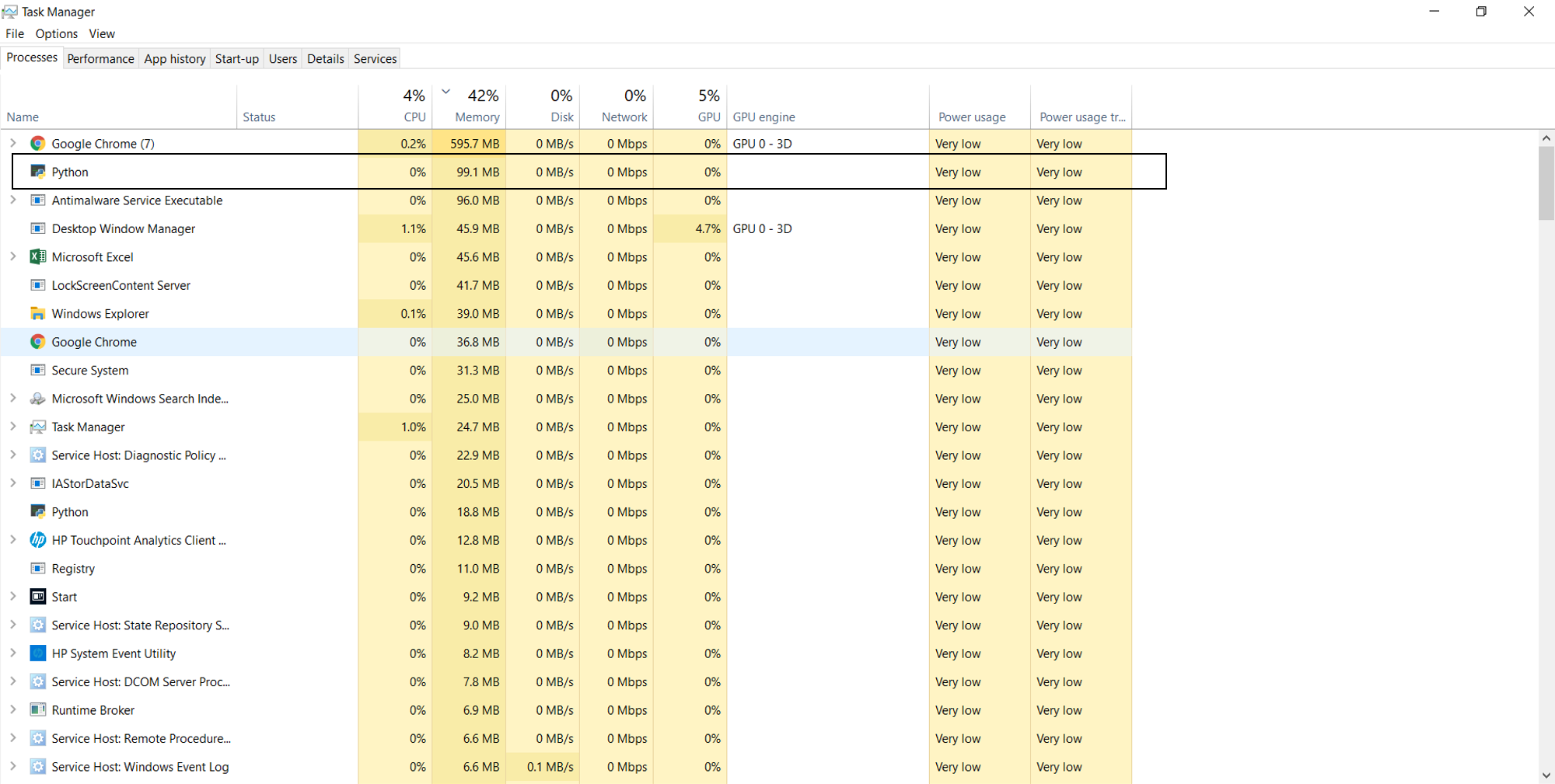
When running processes, the task manager will look something like this:
运行进程时,任务管理器将如下所示:

As you can see, only a single process exists when running threads, whereas 8 processes are created when running processes.
如您所见,运行线程时仅存在一个进程,而运行进程时将创建8个进程。
底线: (The Bottom Line:)
The above example would have made the difference between threads and processes clear. Whenever performing python computations, it is best to use processes. If your computation is dominated by non-python instructions, you can use threads for lower overheads.
上面的示例将使线程和进程之间的区别清晰可见。 每当执行python计算时,最好使用进程。 如果您的计算以非python指令为主,则可以使用线程来降低开销。
You can use the dask.distributed client for sophisticated features like a monitoring dashboard and asynchronous futures. But I’ve found that to be slightly slower than processes when running python instructions.
您可以将dask.distributed客户端用于复杂功能,例如监视仪表板和异步期货。 但是我发现这比运行python指令时的进程要慢一些。















 1383
1383











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









