





keras设置超参数
In my previous article, I had explained how to build a small and nimble image classifier and what are the advantages of having variable input dimensions in a convolutional neural network. However, after going through the model building code and training routine, one can ask questions such as:
在我的前一篇文章中 ,我已经解释了如何构建一个小巧的图像分类器,以及在卷积神经网络中具有可变输入尺寸的优点。 但是,在完成了模型构建代码和培训例程后,您可以提出以下问题:
- How to choose the number of layers in a neural network? 如何选择神经网络中的层数?
- How to choose the optimal number of units/filters in each layer? 如何在每一层中选择最佳的单位/滤波器数量?
- What would be the best data augmentation strategy for my dataset? 什么是我的数据集的最佳数据扩充策略?
- What batch size and learning rate would be appropriate? 合适的批量大小和学习速度是多少?
Building or training a neural network involves figuring out the answers to the above questions. You may have an intuition for CNNs, for example, as we go deeper the number of filters in each layer should increase as the neural network learns to extract more and more complex features built on simpler features extracted in the earlier layers. However, there might be a more optimal model (for your dataset) with a lesser number of parameters that might outperform the model that you have designed based on your intuition.
建立或训练神经网络涉及找出以上问题的答案。 例如,您可能对CNN有一个直觉,随着我们越深入,随着神经网络学会提取基于在较早层中提取的较简单特征而构建的越来越复杂的特征,每层中的过滤器数量应增加。 但是,可能存在一个更优化的模型(针对您的数据集),而参数数量较少,这些参数可能会胜过根据您的直觉设计的模型。
In this article, I’ll explain what these parameters are and how do they affect the training of a machine learning model. I’ll explain how do machine learning engineers choose these parameters and how can we automate this process using a simple mathematical concept. I’ll be starting with the same model architecture from my previous article and will be modifying it to make most of the training and architectural parameters tunable.
在本文中,我将解释这些参数是什么以及它们如何影响机器学习模型的训练。 我将说明机器学习工程师如何选择这些参数,以及如何使用简单的数学概念来自动化该过程。 我将从上一篇文章中的相同模型架构开始,并将对其进行修改以使大多数训练和架构参数可调整。
什么是超参数? (What is a hyperparameter?)
A hyperparameter is a training parameter set by a machine learning engineer before training the model. These parameters are not learned by the machine learning model during the training process. Examples include batch size, learning rate, number of layers and corresponding units, etc. The parameters that are learned by the machine learning model, from the data, during the training process are called model parameters.
超参数是机器学习工程师在训练模型之前设置的训练参数。 在训练过程中,机器学习模型不会学习这些参数 。 示例包括批处理大小,学习率,层数和相应的单位等。机器学习模型在训练过程中从数据中学习的参数称为模型参数。
Why hyperparameters are important?
为什么超参数很重要?
When training a machine learning model the main goal is to get the best performing model that has the best performance on the validation set. We focus on the validation set as it represents how well the model generalizes (performance on unseen data). Hyperparameters form the premise of the training process. For eg., if the learning rate is set too high then the model might never converge to the minima as it will take too large steps after every iteration. On the other hand, if the learning rate is set too low it will take a long time for the model to reach the minima.
在训练机器学习模型时,主要目标是获得在验证集上具有最佳性能的最佳性能模型。 我们将重点放在验证集上,因为它代表了模型的概括程度(针对看不见的数据的性能)。 超参数构成训练过程的前提 。 例如,如果将学习速率设置得太高,则该模型可能永远不会收敛到最小值,因为在每次迭代之后它将采取太大的步骤。 另一方面,如果学习率设置得太低,则模型要花很长时间才能达到最小值。
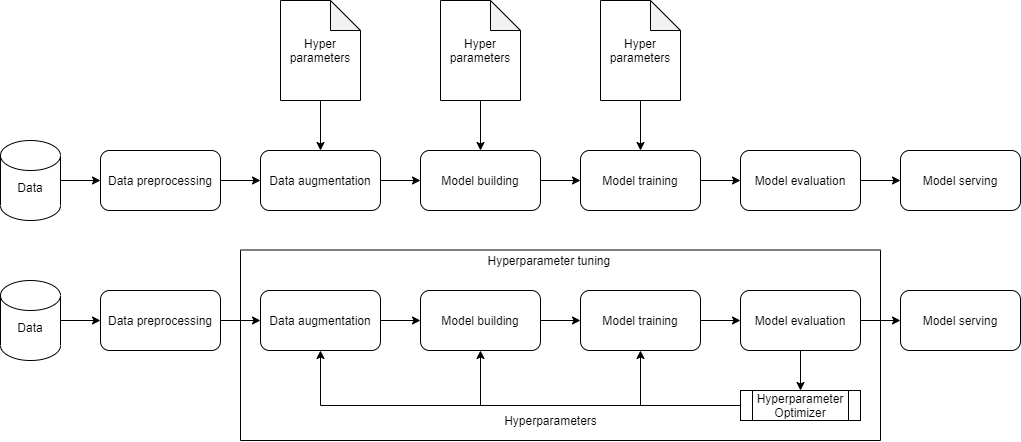
Why is it difficult to choose hyperparameters?
为什么很难选择超参数?
Finding the right learning rate involves choosing a value, training a model, evaluating it, and trying again. Every dataset is unique on its own and with so many parameters to choose from, a beginner can easily get confused. Machine learning engineers who have had many failed training attempts eventually develop an intuition of how a hyperparameter affects a given training process. However, that intuition doesn’t generalize to all the datasets and a new use case usually needs some experiments before settling with convincing hyperparameters. And yet, it’s possible to miss out on best or optimal parameters.
要找到合适的学习率,需要选择一个值,训练一个模型,对其进行评估,然后重试。 每个数据集都是唯一的,并且具有众多参数可供选择,因此初学者很容易感到困惑。 经历了许多失败的训练尝试的机器学习工程师最终会直观地了解超参数如何影响给定的训练过程。 但是,这种直觉并不能推广到所有数据集,在使用令人信服的超参数之前,通常需要一些新的用例进行实验。 但是,有可能错过最佳或最佳参数。
We want to choose the hyperparameters such that, after the training process is complete, we have a model that is both precise and generalized. When dealing with neural networks evaluating the objective function can be very expensive as training takes a long time and trying out different hyperparameters manually may take days. This becomes a difficult task to do by hand.
我们希望选择超参数,以便在训练过程完成后,我们得到一个既精确又通用的模型 。 在处理神经网络时,评估目标函数可能会非常昂贵,因为训练需要很长时间,而手动尝试不同的超参数可能需要几天的时间。 手工完成这项工作变得困难。
超参数调整/优化 (Hyperparameter tuning/optimization)
Hyperparameter tuning can be considered as a black-box optimization problem where we try to find a minimum of a function f(x) without knowing its analytical form. It is also called derivative-free optimization as we do not know its analytical form and no derivatives can be computed to minimize f(x), and hence techniques like gradient descent cannot be used.
超参数调整可以看作是黑盒优化问题,我们尝试在不知道函数f(x)解析形式的情况下找到其最小值 。 它也称为无导数优化,因为我们不知道其解析形式,也无法计算导数来最小化f(x),因此无法使用诸如梯度下降之类的技术。
Few well-known techniques for hyperparameter tuning include grid search, random search, differential evolution, and bayesian optimization. Grid search and random search perform slightly better than manual tuning as we set up a grid of hyperparameters and run training and evaluation cycles on the parameters which are systematically or randomly chosen from the grid respectively.
很少有众所周知的超参数调整技术,包括网格搜索,随机搜索,差分演化和贝叶斯优化。 网格搜索和随机搜索的性能略好于手动调整,因为我们建立了一个超参数网格,并对分别从网格中系统或随机选择的参数运行训练和评估周期。
However, grid and random search are relatively inefficient as they do not choose the next set of hyperparameters based on previous results. On the other hand, Differential evolution is a type of evolutionary algorithm where the initial set of best performing hyperparameter configurations (which are one of the randomly initialized individuals) are chosen to produce more hyperparameters (offsprings). The new generation of hyperparameters (offsprings) are more likely to perform better as they inherit good traits of their parents and the population improves over time (generation after generation). Read more about this concept in this beautiful and practical tutorial here.
但是,网格和随机搜索效率相对较低,因为它们不会根据先前的结果选择下一组超参数。 另一方面, 差分进化是一种进化算法,其中选择最佳性能的超参数配置的初始集合(其是随机初始化的个体之一)以产生更多的超参数(后代) 。 新一代的超参数(后代)表现出更好的性能,因为它们继承了父母的良好特征,并且种群随着时间的推移(世代相传)而有所改善。 了解更多关于这个概念,在这个美丽而实用的教程在这里 。
Though differential evolution works, it takes a long time and still doesn’t quite take informed steps or it isn’t aware of what are we trying to achieve/optimize. Bayesian optimization approach keeps track of the past evaluation results and uses it to create a probabilistic model of the actual training objective function which is to be optimized. This probabilistic model is called a “surrogate” for the objective function which forms a mapping of the hyperparameters to the probability score of how well the objective function will perform. The next set of hyperparameters, to be evaluated, are chosen on the basis of their performance on the surrogate. This makes bayesian optimization efficient as it chooses the next set of hyperparameters in an informed manner. Read more about this concept in this detailed article here. The article explains Tree Parzen Estimators (TPE) surrogate model which will be used internally in our implementation below.
尽管差分进化有效,但它花费的时间很长,仍然没有采取明智的步骤,或者它不知道我们要实现/优化的目标。 贝叶斯优化方法跟踪过去的评估结果,并利用它建立实际训练目标函数的概率模型进行优化 。 该概率模型被称为目标函数的“ 替代” ,它形成了超参数到目标函数执行效果的概率分数的映射。 根据其在代理上的性能来选择下一组要评估的超参数。 这使得贝叶斯优化高效,因为它以一种有根据的方式选择了下一组超参数。 了解更多关于这个概念这个详细的文章在这里 。 本文介绍了Tree Parzen Estimators(TPE)替代模型,该模型将在下面的实现中内部使用。
获取经文 (Get the scriptures)
As always, you can get all the code used in this tutorial in this GitHub link. I would suggest the reader to clone the project and follow the tutorial step by step for better understanding. Note: The code snippets in this article highlight only a part of the actual script, please refer to the GitHub link for complete code.
与往常一样,您可以在此GitHub链接中获得本教程中使用的所有代码。 我建议读者克隆项目并逐步按照教程进行操作,以更好地理解。 注意 :本文中的代码片段仅突出显示实际脚本的一部分,有关完整代码,请参阅GitHub链接。
什么是雷声? (What is Ray Tune?)
Ray Tune is a Python library that accelerates hyperparameter tuning by allowing you to leverage cutting edge optimization algorithms at scale. It is built on Ray designed to remove the friction from scaling and setting up experiment execution.
Ray Tune是一个Python库,可通过允许您大规模利用最先进的优化算法来加速超参数调整。 它建立在Ray之上,旨在消除缩放和设置实验执行过程中的摩擦。
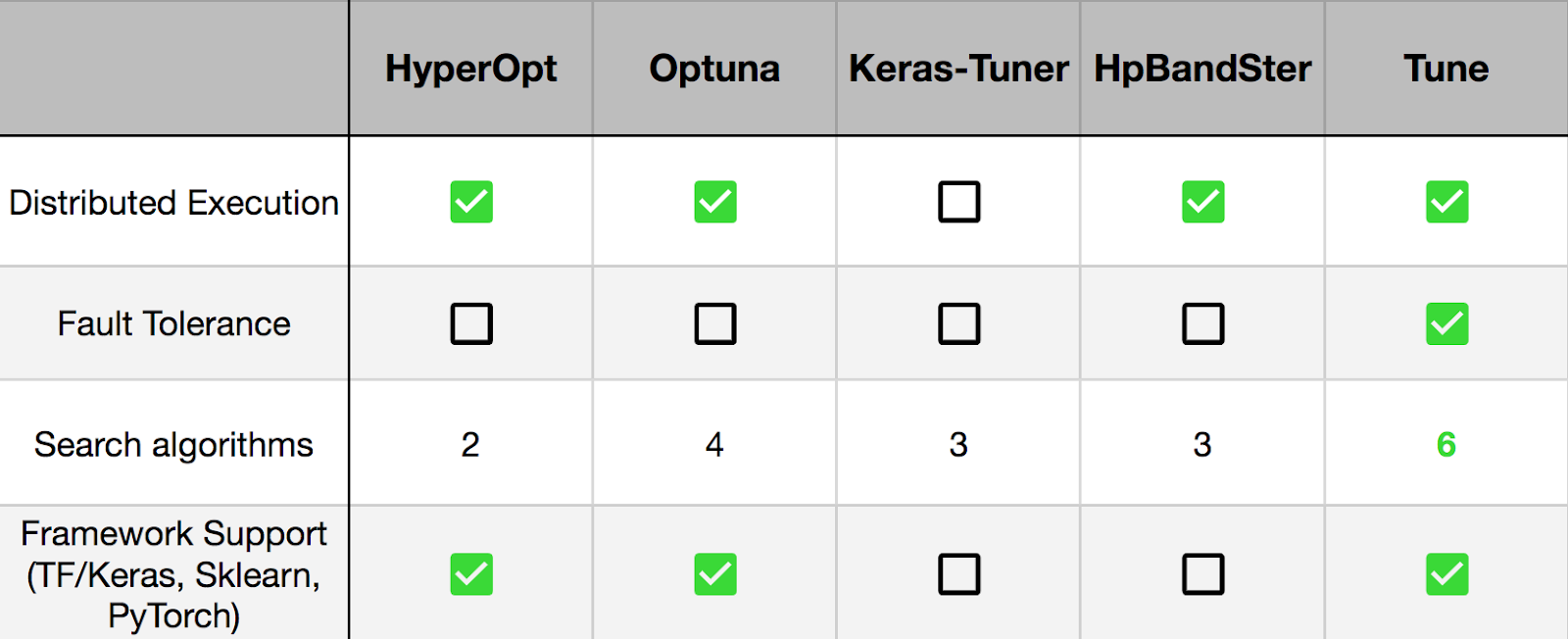
Ray Tune integrates seamlessly with experiment management tools such as MLFlow, TensorBoard, weights and biases, etc. and provides a flexible interface for many cutting edge optimization algorithms and libraries such as HyperOpt (implemented below) and Ax.
Ray Tune与MLFlow,TensorBoard,权重和偏差等实验管理工具无缝集成,并为许多尖端优化算法和库(例如HyperOpt (在下面实现)和Ax )提供了灵活的界面。
建立超级模型 (Building a hyper model)
A hyper model is a model whose hyperparameters can be optimized, using optimization algorithms, in order to give the best performance on a metric (validation loss in this case). These hyperparameters include a number of layers, number of units in each layer, type of the layer to be used, type of activation function, etc. Let’s create a simple hyper model which performs image classification task.
超模型是可以使用优化算法对其超参数进行优化的模型,以便提供最佳的度量标准性能(在这种情况下为验证损失)。 这些超参数包括多个层,每个层中的单元数,要使用的层的类型,激活函数的类型等。让我们创建一个执行图像分类任务的简单超模型。
def FCN_model(config, len_classes=5):
input = tf.keras.layers.Input(shape=(None, None, 3))
# Adding data augmentation layers
x = augment_images(input, config)
# You can create a fixed number of convolutional blocks or
# You can also use a loop if number of layers is also a hyperparameter
x = tf.keras.layers.Conv2D(filters=config['conv_block1_filters'], kernel_size=3, strides=1)(x)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.Activation('relu')(x)
x = tf.keras.layers.Conv2D(filters=config['conv_block2_filters'], kernel_size=3, strides=1)(x)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.Activation('relu')(x)
if config['fc_layer_type'] == 'dense':
if config['pool_type'] == 'max':
x = tf.keras.layers.GlobalMaxPooling2D()(x)
else:
x = tf.keras.layers.GlobalAveragePooling2D()(x)
# Fully connected layer 1
x = tf.keras.layers.Dense(units=config['fc1_units'])(x)
x = tf.keras.layers.Dropout(config['dropout_rate'])(x)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.Activation('relu')(x)
# Fully connected layer 2
x = tf.keras.layers.Dense(units=len_classes)(x)
x = tf.keras.layers.Dropout(config['dropout_rate'])(x)
x = tf.keras.layers.BatchNormalization()(x)
predictions = tf.keras.layers.Activation('softmax')(x)
else:
# Some other FC layer configuration
.
.
.
model = tf.keras.Model(inputs=input, outputs=predictions)
return modelIn the above model building code, we are passing a config dictionary which contains values like the number of filters, dropout rate, whether to use a specific data augmentation layer, etc. A new config dictionary will be created for every run of hyperparameter tuning. The config corresponding to the best run will be chosen as the best configuration which will include optimal parameters for data augmentation, model, and training routine. An example config is explained in the hyperparameter search space section below.
在上面的模型构建代码中,我们传递了一个config字典,其中包含诸如过滤器数量,丢失率,是否使用特定的数据增强层等值。将为每次超参数调整运行创建一个新的配置字典。 与最佳运行相对应的config将被选为最佳配置,其中将包括用于数据扩充,模型和训练例程的最佳参数。 下面的超参数搜索空间部分介绍了示例config 。
选择最佳数据扩充 (Choosing the optimal data augmentation)
Choosing a data augmentation is very sensitive to the nature of the application for which the model is being trained for. A face recognition system might come across faces in different brightness, orientation, partially cropped, etc. However, an OCR based text extraction system used to extract text from a system-generated PDF will most certainly come across a text with very little orientation and brightness variations.
选择数据扩充对要为其训练模型的应用程序的性质非常敏感。 人脸识别系统可能会遇到不同亮度,方向,部分裁剪等情况的人脸。但是,用于从系统生成的PDF中提取文本的基于OCR的文本提取系统很可能会遇到方向和亮度非常小的文本。变化。
If we have huge datasets, it might not be possible to go through each and every image to decide on the data augmentations to be used. We can leave this task, as one of the hyperparameters, for our optimization algorithm. In TensorFlow 2, it becomes easier than ever to add data augmentation using Keras preprocessing layers as a part of our model code. These preprocessing layers are active only in training mode and are disabled during inference or evaluation. Read more about it here.
如果我们拥有庞大的数据集,则可能无法遍历每张图像来决定要使用的数据扩充。 我们可以将该任务作为超参数之一留给我们的优化算法。 在TensorFlow 2中,使用Keras预处理层作为模型代码的一部分添加数据增强变得前所未有的容易 。 这些预处理层仅在训练模式下处于活动状态,而在推理或评估期间被禁用。 在此处了解更多信息。
def augment_images(x, config):
if config['use_contrast'] == "True":
x = tf.keras.layers.experimental.preprocessing.RandomContrast(
config['contrast_factor']
)(x)
if config['use_rotation'] == "True":
x = tf.keras.layers.experimental.preprocessing.RandomRotation(
config['rotation_factor']
)(x)
if config['use_flip'] == "True":
x = tf.keras.layers.experimental.preprocessing.RandomFlip(
config['flip_mode']
)(x)
return x定义超参数搜索空间 (Defining a hyperparameter search space)
In order to define a hyperparameter search space, we first need to understand what are the possible valid configurations using which we can create our model. Let’s consider one valid config dictionary below:
为了定义超参数搜索空间,我们首先需要了解可以使用哪些有效配置来创建模型。 让我们考虑以下一个有效的config字典:
{
"lr": 0.001,
"batch_size": 16,
"use_contrast": "True",
"contrast_factor": 0.2,
"use_rotation": "True",
"rotation_factor": 0.2,
"use_flip": "True",
"flip_mode": "horizontal",
"dropout_rate": 0.2,
"conv_block1_filters": 32,
"conv_block2_filters": 64,
"conv_block3_filters": 128,
"conv_block4_filters": 256,
"conv_block5_filters": 512,
"fc_layer_type": "dense",
"pool_type": "max",
"fc1_units": 64
}If we consider batch_size, then we can choose any value between 1 to 100 or even higher. However, most common batch sizes are a power of 2 and lie somewhere between 8 and 64. So, we can either define our search space to a be any integer value between 1 and 100 or we can lessen the burden of the optimization algorithm by providing a list of most common values like [8, 16, 32, 64]. Similarly, if we consider learning rate (lr), we can choose any floating-point value between 0.0001 and 0.1. We can go lower or higher but that’s usually not needed. Rather than going for an exhaustive search space of 0.0001 to 0.1 we can specify the most common values that are usually in powers of 10 like [0.1, 0.01, 0.001, 0.0001].
如果考虑batch_size ,那么我们可以选择1到100甚至更高之间的任何值。 但是,最常见的批处理大小是2的幂,介于8到64之间。因此,我们可以将搜索空间定义为1到100之间的任何整数值,或者可以通过提供以下内容来减轻优化算法的负担:最常见值的列表,例如[8, 16, 32, 64] 。 同样,如果我们考虑学习率( lr ),则可以选择介于0.0001和0.1之间的任何浮点值。 我们可以走得更低或更高,但这通常是不需要的。 可以指定最常见的值(通常为10的幂),而不是使用0.0001至0.1的穷举搜索空间,例如[0.1, 0.01, 0.001, 0.0001] 。
In HyperOpt, a search space consists of nested function expressions, including stochastic expressions. The stochastic expressions are the hyperparameters on which the optimization algorithms work by replacing normal “sampling” logic with adaptive exploration strategies. Read more about it here. We can define a stochastic expression which consists of a list of batch_size values as hp.choice(‘batch_size’, [8, 16, 32, 64]). Similarly, for learning rate, we can define an expression as hp.choice(‘lr’, [0.0001, 0.001, 0.01, 0.1]). If you want to define a continuous space constrained by a two-sided interval we can modify the expression to be hp.uniform(‘lr’, 0.0001, 0.1). You can refer to the complete list of parameter expressions here. Our final hyperparameter search space will look something like this:
在HyperOpt中,搜索空间由嵌套函数表达式(包括随机表达式)组成 。 随机表达式是超参数,优化算法通过使用自适应探索策略替换常规的“采样”逻辑来对优化算法进行处理。 在此处了解更多信息。 我们可以定义一个随机表达式,其中包含一列batch_size值,如hp.choice('batch_size', [8, 16, 32, 64]) 。 同样,对于学习率,我们可以将表达式定义为hp.choice('lr', [0.0001, 0.001, 0.01, 0.1]) 。 如果要定义一个受两侧间隔限制的连续空间,我们可以将表达式修改为hp.uniform('lr', 0.0001, 0.1) 。 您可以在此处参考参数表达式的完整列表。 我们最终的超参数搜索空间将如下所示:
{
"lr": hp.choice("lr", [0.0001, 0.001, 0.01, 0.1]),
"batch_size": hp.choice("batch_size", [8, 16, 32, 64]),
"use_contrast": hp.choice("use_contrast", ["True", "False"]),
"contrast_factor": hp.choice("contrast_factor", [0.1, 0.2, 0.3, 0.4]),
"use_rotation": hp.choice("use_rotation", ["True", "False"]),
"rotation_factor": hp.choice("rotation_factor", [0.1, 0.2, 0.3, 0.4]),
"use_flip": hp.choice("use_flip", ["True", "False"]),
"flip_mode": hp.choice("flip_mode", ["horizontal", "vertical"]),
"dropout_rate": hp.choice("dropout_rate", [0.1, 0.2, 0.3, 0.4, 0.5]),
"conv_block1_filters": hp.choice("conv_block1_filters", [32, 64, 128, 256, 512]),
"conv_block2_filters": hp.choice("conv_block2_filters", [32, 64, 128, 256, 512]),
"conv_block3_filters": hp.choice("conv_block3_filters", [32, 64, 128, 256, 512]),
"conv_block4_filters": hp.choice("conv_block4_filters", [32, 64, 128, 256, 512]),
"conv_block5_filters": hp.choice("conv_block5_filters", [32, 64, 128, 256, 512]),
"fc_layer_type": hp.choice("fc_layer_type", ["dense", "convolution"]),
"pool_type": hp.choice("pool_type", ["max", "average"]),
"fc1_units": hp.choice("fc1_units", [32, 64, 128, 256, 512])
}指定试用计划程序和搜索算法 (Specifying a trial scheduler and a search algorithm)
A search algorithm is an “optimization algorithm” that optimizes the hyperparameters of a training process by suggesting better hyperparameters with every subsequent trial. Tune’s Search Algorithms are wrappers around open-source optimization libraries for efficient hyperparameter selection. Each library has a specific way of defining the search space like the above search space is defined for HyperOpt. To use this search algorithm, we need to install it separately using pip install -U hyperopt.
搜索算法是一种“优化算法”,它通过在随后的每个试验中建议更好的超参数来优化训练过程的超参数。 Tune的搜索算法是用于优化超参数选择的开源优化库的包装。 每个库都有定义搜索空间的特定方式,就像上面为HyperOpt定义的搜索空间一样。 要使用此搜索算法,我们需要使用pip install -U hyperopt单独安装它。
A trial scheduler is also an optimization algorithm implemented as a “scheduling algorithm” that makes the hyperparameter tuning process more efficient. A trial scheduler can early terminate bad trials, pause trials, clone trials, and alter hyperparameters of a running trial making the hyperparameter tuning process much faster. NOTE: Unlike search algorithm, a trial scheduler does not select the hyperparameter configuration to evaluate for each run. We will use AsyncSuccessiveHalvingAlgorithm (ASHA) scheduler which gives similar theoretical performance as HyperBand (SHA) but provides better parallelism and avoids straggler issues during eliminations. We don’t need to install AsyncSuccessiveHalvingAlgorithm scheduler separately.
试用调度程序也是一种实现为“调度算法”的优化算法,可使超参数调整过程更加高效 。 试用计划程序可以提前终止不良测试,暂停测试,克隆测试以及更改正在运行的测试的超参数,从而使超参数调整过程更快。 注意 :与搜索算法不同,试用计划程序不会选择超参数配置来评估每次运行。 我们将使用AsyncSuccessiveHalvingAlgorithm (ASHA)调度程序,该调度程序具有与HyperBand (SHA)类似的理论性能,但提供了更好的并行性并避免了消除过程中的混乱问题。 我们不需要单独安装AsyncSuccessiveHalvingAlgorithm调度程序。
All trial schedulers and search algorithms take in metric which is maximized or minimized according to the mode. Trial schedulers also take in grace_period which is similar to patience used in EarlyStopping callback in Keras. For search algorithm, we can provide an initial config (search space) which is usually the best config found through manual tuning, or we can skip it if we don’t have one.
所有试用调度程序和搜索算法均采用根据mode最大化或最小化的metric 。 试用调度程序还接受grace_period ,这与Keras中EarlyStopping回调中使用的patience类似。 对于搜索算法,我们可以提供一个初始配置(搜索空间),该配置通常是通过手动调整找到的最佳配置,或者如果没有,可以跳过它。
logger.info("Initializing ray")
ray.init(configure_logging=False)
logger.info("Initializing ray search space")
search_space, intial_best_config = create_search_space()
logger.info("Initializing scheduler and search algorithms")
# Use HyperBand scheduler to earlystop unpromising runs
scheduler = AsyncHyperBandScheduler(time_attr='training_iteration',
metric="val_loss",
mode="min",
grace_period=10)
# Use bayesian optimisation with TPE implemented by hyperopt
search_alg = HyperOptSearch(search_space,
metric="val_loss",
mode="min",
points_to_evaluate=intial_best_config)
# We limit concurrent trials to 2 since bayesian optimisation doesn't parallelize very well
search_alg = ConcurrencyLimiter(search_alg, max_concurrent=2)定义超参数调整的目标 (Defining an objective for hyperparameter tuning)
To start hyperparameter tuning we need to specify an objective function to optimize which is passed to tune.run(). The loss function to train (update model parameters) our image classifier will be categorical cross-entropy. Training and validation losses are a more accurate representation of how our model is performing. However, during overfitting, our training loss will decrease but our validation loss will increase. Hence, validation loss will be to right metric to monitor for hyperparameter tuning.
要开始超参数调整,我们需要指定一个目标函数来优化传递给tune.run()函数。 训练(更新模型参数)我们的图像分类器的损失函数将是分类交叉熵。 训练和验证损失可以更准确地表示我们的模型的运行情况。 但是,在过度拟合期间,我们的训练损失将减少,但我们的验证损失将增加。 因此,验证损失将是正确的指标,以监视超参数调整。
Training an image classifier is a lengthy process and waiting for the training to complete and then reporting the validation loss metric is not a good idea as our trial scheduler will have no clue as to how the training is progressing and is there a need to early stop it. To overcome this issue, we will make use of Keras callbacks where validation loss is calculated at the end of every epoch, so we can send the scores to Tune using tune.report(). A minimal code for Keras callback is given below, please refer to the complete code on GitHub.
训练图像分类器是一个漫长的过程,等待训练完成然后报告验证损失度量标准不是一个好主意,因为我们的试用日程安排程序将不知道训练的进行方式,因此需要尽早停止它。 为了克服这个问题, 我们将使用Keras回调,在每个时期的末尾计算验证损失,因此可以使用 tune.report() 将乐谱发送到Tune 。 下面给出了Keras回调的最小代码,请参考GitHub上的完整代码 。
class TuneReporter(tf.keras.callbacks.Callback):
"""Tune Callback for Keras."""
def __init__(self, reporter=None, freq="epoch", logs=None):
"""Initializer.
Args:
freq (str): Sets the frequency of reporting intermediate results.
"""
self.iteration = 0
logs = logs or {}
self.freq = freq
super(TuneReporter, self).__init__()
def on_epoch_end(self, epoch, logs=None):
from ray import tune
logs = logs or {}
if not self.freq == "epoch":
return
self.iteration += 1
if "acc" in logs:
tune.report(keras_info=logs, val_loss=logs['val_loss'], mean_accuracy=logs["acc"])
else:
tune.report(keras_info=logs, val_loss=logs['val_loss'], mean_accuracy=logs.get("accuracy"))In Ray Tune, we can specify an objective function using a function-based API or a class-based API, in this tutorial we’ll be using function-based API. After the hyperparameter tuning is completed, we get the best config which is used to train our final model that will be saved on the disk. We’ll wrap our objective function inside a class to store a few directory paths and a boolean variable which tells whether the given run is the final run or not.
在Ray Tune中,我们可以使用基于函数的 API或基于类的 API指定目标函数,在本教程中,我们将使用基于函数的API。 超参数调整完成后,我们将获得最佳配置,该配置用于训练最终模型并将其保存在磁盘上。 我们将目标函数包装在一个类中,以存储一些目录路径和一个布尔变量,该变量指示给定的运行是否为最终运行。
class Trainable:
def __init__(self, train_dir, val_dir, snapshot_dir, final_run=False):
# Initializing state variables for the run
self.train_dir = train_dir
self.val_dir = val_dir
self.final_run = final_run
self.snapshot_dir = snapshot_dir
def train(self, config, reporter=None):
# If you get out of memory error try reducing the maximum batch size
train_generator = Generator(self.train_dir, config['batch_size'])
val_generator = Generator(self.val_dir, config['batch_size'])
# Create FCN model
model = FCN_model(config, len_classes=len(train_generator.classes))
# Compile model with losses and metrics
model.compile(optimizer=tf.keras.optimizers.Nadam(lr=config['lr']),
loss='categorical_crossentropy',
metrics=['accuracy'])
# Create callbacks to be used during model training
callbacks = create_callbacks(self.final_run, self.snapshot_dir)
logger.info("Starting model training")
# Start model training
history = model.fit(train_generator,
steps_per_epoch=len(train_generator),
epochs=100,
callbacks=callbacks,
validation_data=val_generator,
validation_steps=len(val_generator)
)
return history
logger.info("Initializing ray Trainable")
# Initialize Trainable for hyperparameter tuning
trainer = Trainable(args.train_dir, args.val_dir, args.snapshot_dir, final_run=False)
logger.info("Starting hyperparameter tuning")
analysis = tune.run(trainer.train,
verbose=1,
num_samples=num_samples,
search_alg=search_alg,
scheduler=scheduler,
raise_on_failed_trial=False,
resources_per_trial={"cpu": 16, "gpu": 2}
)
best_config = analysis.get_best_config(metric="val_loss", mode='min')
logger.info(f'Best config: {best_config}')可视化结果 (Visualizing results)
If TensorBoard is installed, Tune automatically outputs Tensorboard files during tune.run(). After you run an experiment, you can visualize your results with TensorBoard by specifying the output directory of your results: $ tensorboard --logdir=~/ray_results/my_experiment
如果安装了TensorBoard,则Tune在tune.run()期间自动输出Tensorboard文件。 运行实验后,可以通过指定结果的输出目录来使用TensorBoard可视化结果: $ tensorboard --logdir=~/ray_results/my_experiment
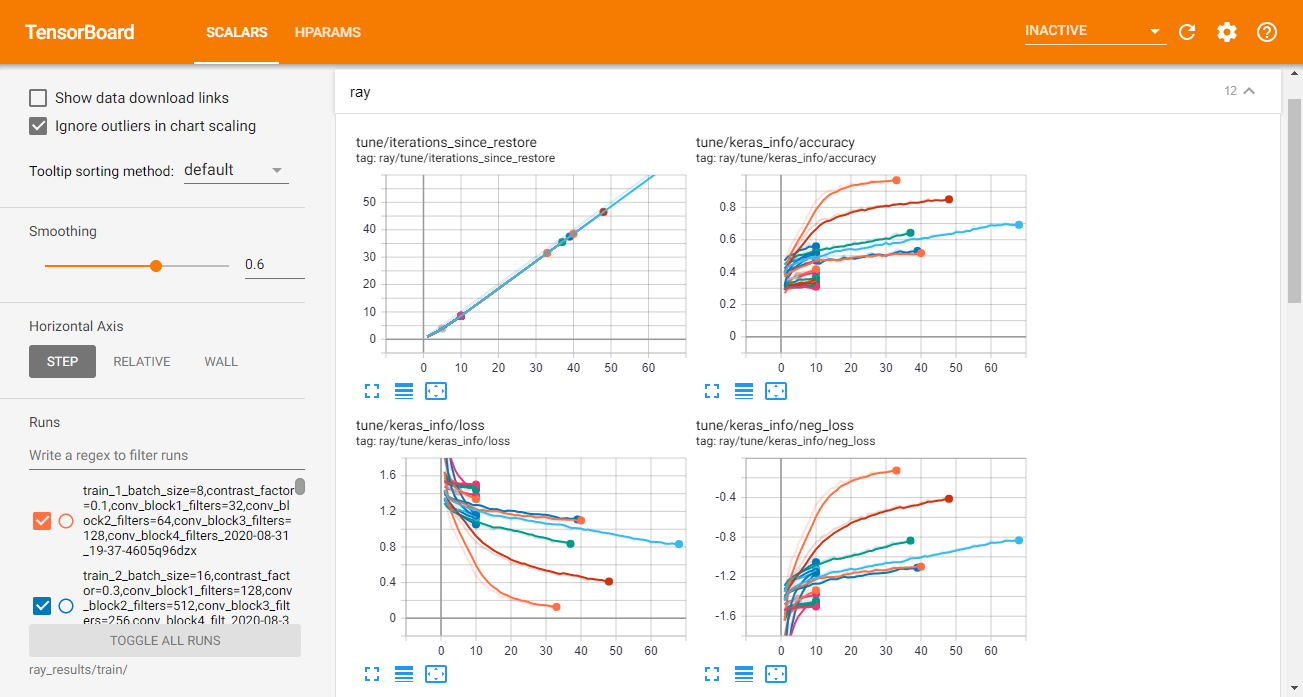
In TF2, Tune also automatically generates TensorBoard HParams output, as shown below:
在TF2中,Tune还会自动生成TensorBoard HParams输出,如下所示:
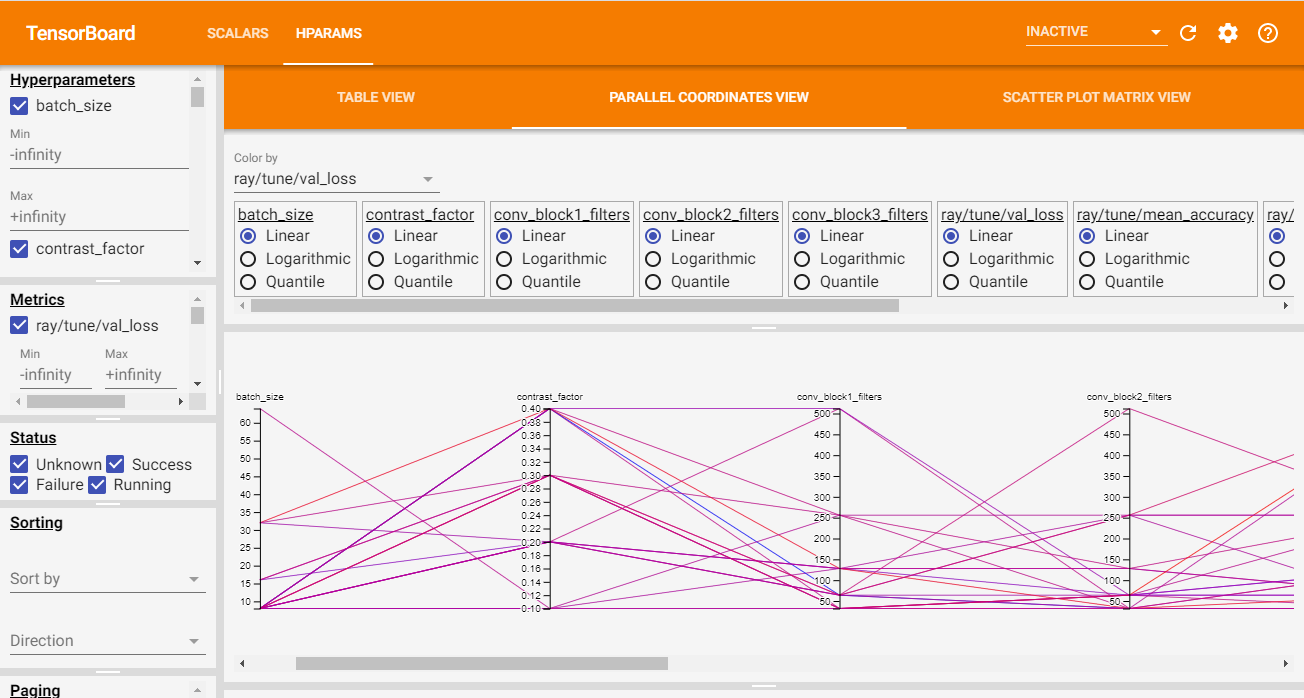
有关超参数调整的更多信息 (More about hyperparameter tuning)
There are many use cases where we use standard architectures (like ResNet50) instead of building one from scratch. These architectures are huge and performing hyperparameter tuning might not be practical or maybe you want to make use of pre-trained ImageNet weights so changing the model architecture is not an option. In such cases, we can look for hyperparameters outside the model architecture for eg., data augmentation, batch size, learning rate, optimizers, etc.
在许多用例中,我们使用标准体系结构(如ResNet50)而不是从头开始构建一个。 这些架构非常庞大,执行超参数调整可能不切实际,或者您可能想使用预先训练的ImageNet权重,因此更改模型架构不是一个选择。 在这种情况下,我们可以在模型架构之外寻找超参数,例如,数据扩充,批处理大小,学习率,优化器等。
Anchor boxes in object detection
物体检测中的锚框
Let’s consider object detection as one such use case, where we make use of anchor boxes for bounding box prediction which are not learned during the training process. Every object detection dataset has unique aspect ratios of objects to be detected and the default anchor configuration might not suitable for detecting objects in your dataset. For example, if your objects are smaller than the size of the smallest anchors or your objects have a higher aspect ratio. In such cases, it might be suitable to modify the anchor configuration. This can be done automatically by setting the anchor parameters as the hyperparameters to be tuned.
让我们将对象检测视为这样的一种用例,其中我们使用锚框进行边界框预测,这些锚框在训练过程中是不会学习的。 每个对象检测数据集都有要检测的对象的唯一长宽比,并且默认锚配置可能不适合检测数据集中的对象。 例如,如果您的对象小于最小锚点的大小,或者您的对象具有更高的宽高比。 在这种情况下,修改锚点配置可能是合适的。 通过将锚参数设置为要调整的超参数,可以自动完成此操作。
I’ve created a similar optimization routine, followed in this tutorial, for optimizing the anchor boxes of RetinaNet object detection model here. The optimization routine doesn’t train the complete model, rather it maximizes the average overlap of generated anchor boxes with the bounding boxes in a given dataset. We can then use the new anchor configuration to train our object detection model. You can get the TensorFlow 2 code for RetinaNet object detection model here.
在本教程中,我创建了一个类似的优化例程,用于在此处优化RetinaNet对象检测模型的锚点框。 优化例程不会训练完整的模型,而是会最大化生成的锚点框与给定数据集中的边界框的平均重叠。 然后,我们可以使用新的锚配置来训练我们的对象检测模型。 您可以在此处获取用于RetinaNet对象检测模型的TensorFlow 2代码。
结论 (Conclusion)
I hope this blogpost gave you an insight into different hyperparameters involved in the training of a machine learning model. Manually tuning these parameters is tedious and unintuitive but with the help of Bayesian optimization, we can keep track of the past evaluation results and use it to create a probabilistic model of the actual training objective function. This not only automates the tuning process but also results in an optimal model that we might not have found via manual tuning.
我希望这篇博文可以让您深入了解机器学习模型训练中涉及的不同超参数。 手动调整这些参数既繁琐又不直观,但是借助贝叶斯优化,我们可以跟踪过去的评估结果,并使用它来创建实际训练目标函数的概率模型。 这不仅可以自动执行调整过程,还可以生成我们可能无法通过手动调整找到的最佳模型。
Combining HyperOpt search algorithm with HyperBand trial scheduler significantly reduces our hyperparameter tuning search time and compute resources. And, being able to find the optimal the data augmentation steps for a given dataset is just icing on the cake. I have linked some great resources while discussing various topics in the article, but I’ll re-link them below so that you do not miss out on any of it. Keep learning!
将HyperOpt搜索算法与HyperBand试用计划程序结合使用,可大大减少我们的超参数调整搜索时间和计算资源。 而且,能够找到给定数据集的最佳数据扩充步骤只是锦上添花。 在讨论本文中的各个主题时,我已经链接了一些很棒的资源,但是我将在下面重新链接它们,以免您错过其中的任何内容。 保持学习!
参考资料和资源 (References and resources)
A Conceptual Explanation of Bayesian Hyperparameter Optimization for Machine Learning
BOHB: Robust and efficient hyperparameter optimization at scale
Hyperparameter tuning in Cloud Machine Learning Engine using Bayesian Optimization
I would love to hear your feedback and improvements to this article and the GitHub project. I can be reached on Twitter (@raw_himanshu) and LinkedIn (himanshurawlani)
我很想听听您对本文和GitHub项目的反馈和改进。 可以通过Twitter( @raw_himanshu )和LinkedIn( himanshurawlani )与我联系
翻译自: https://medium.com/@himanshurawlani/hyperparameter-tuning-with-keras-and-ray-tune-1353e6586fda
keras设置超参数















 1568
1568











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









