





用于LiDAR点云的BEV
标题:BEVContrast: Self-Supervision in BEV Space for Automotive Lidar Point Clouds
论文链接:https://arxiv.org/pdf/2310.17281.pdf
代码链接:https://github.com/valeoai/BEVContrast
作者单位:Univ Gustave Eiffel Valeo.ai
本文提出了一种令人惊讶的简单而有效的方法,用于汽车LiDAR点云上 3D backbone 的自监督。本文设计了在同一场景中捕获的LiDAR扫描特征之间的对比损失。文献中已经提出了几种这样的方法,从 PointConstrast [40](使用 points 级别的对比)到最先进的 TARL [30](使用 segments 级别的对比),大致对应于物体。虽然前者的实现非常简单,但它被后者超越,但后者需要昂贵的预处理。在 BEVContrast 中,本文在BEV平面中的 2D cells 级别定义对比。由此产生的 cell-level 表示在 PointContrast 中利用的 point-level 表示和 TARL 中利用的 segment-level 表示之间提供了良好的权衡:本文保留了 PointContrast 的简单性(cell 表示计算成本低廉),同时在下游语义分割上超越了 TARL 的性能。
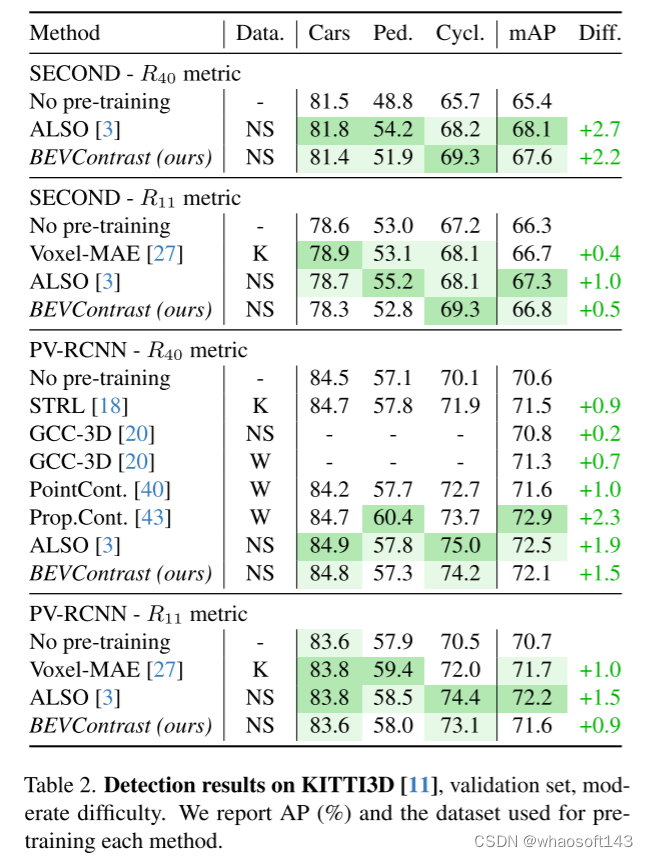
首先,本文提出了一种新颖的LiDAR点云自监督方法,它保留了 PointContrast 的简单性,同时超越了所有当前下游语义分割的自监督方法,包括非对比方法,例如 ALSO [3]。
其次,本文表明,在BEV中投影和池化特征比通过在复杂方法提取的 segments 上池化特征更有效。
最后,由于BEVContrast在BEV中工作,因此它可以开箱即用,用于预训练3D目标检测的 backbone ,例如SECOND [41]或PVRCNN [36],与最先进的技术相比,本文可以实现竞争结果。
网络设计:
在这项工作中,本文提出在BEV平面上的网格的 2D cells 级别上对比特征。cell 的特征在这里被定义为投影到该 cell 中的点的特征的平均值。本文将产生的方法称为 BEVContrast。其动机是城市场景中的物体在 BEV 平面中自然地被很好地分离。因此,对该平面中的点特征进行局部平均允许我们获得 cell-level 特征,这是 point-level 表示和 segment-level 表示之间的良好权衡。BEVContrast 的 high-level 原理如图 1 所示。它保留了 PointContrast 的简单性(BEV 中的投影和每个 BEV cell 中的局部平均池化的计算成本较低),而实验表明,尽管本文没有明确地处理动态对象,但它可以与 TARL 等最好的自监督方法竞争。
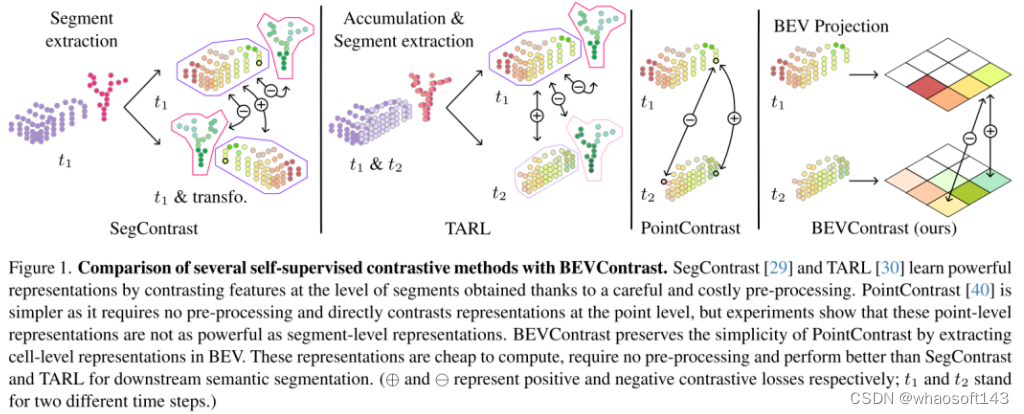
图 1. 几种自监督对比方法与 BEVContrast 的比较。SegContrast [29] 和 TARL [30] 通过对比经过仔细且昂贵的预处理获得的 segments 级别的特征来学习强大的表示。PointContrast [40] 更简单,因为它不需要预处理并直接对比 point-level 表示,但实验表明这些 point-level 表示不如 segment-level 表示强大。BEVContrast 通过提取 BEV 中的 cell-level 表示来保留 PointContrast 的简单性。这些表示计算成本低廉,不需要预处理,并且在下游语义分割方面比 SegContrast 和 TARL 表现更好。(⊕和⊖分别代表正向和负向对比损失;t1和t2代表两个不同的时间步。)
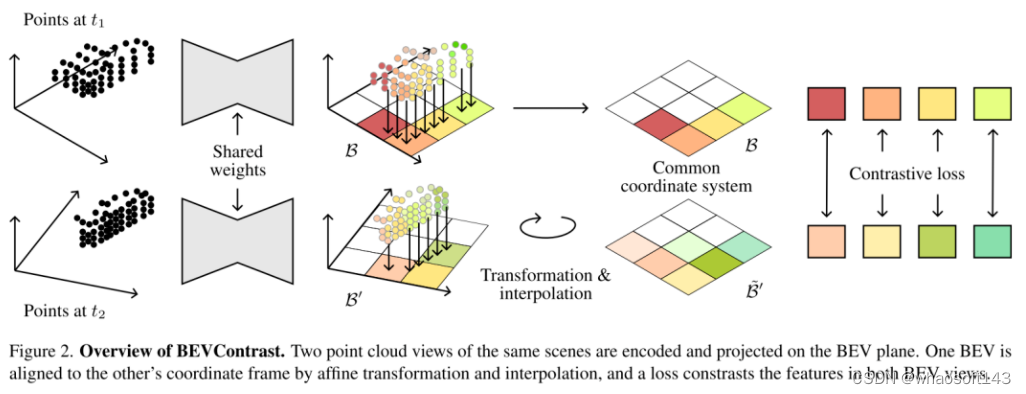
图 2. BEVContrast 概述。相同场景的两个点云视图被编码并投影在 BEV 平面上。一个 BEV 通过仿射变换和插值与另一个 BEV 的坐标系对齐,并且一个损失对比两个 BEV 视图中的特征。
实验结果:
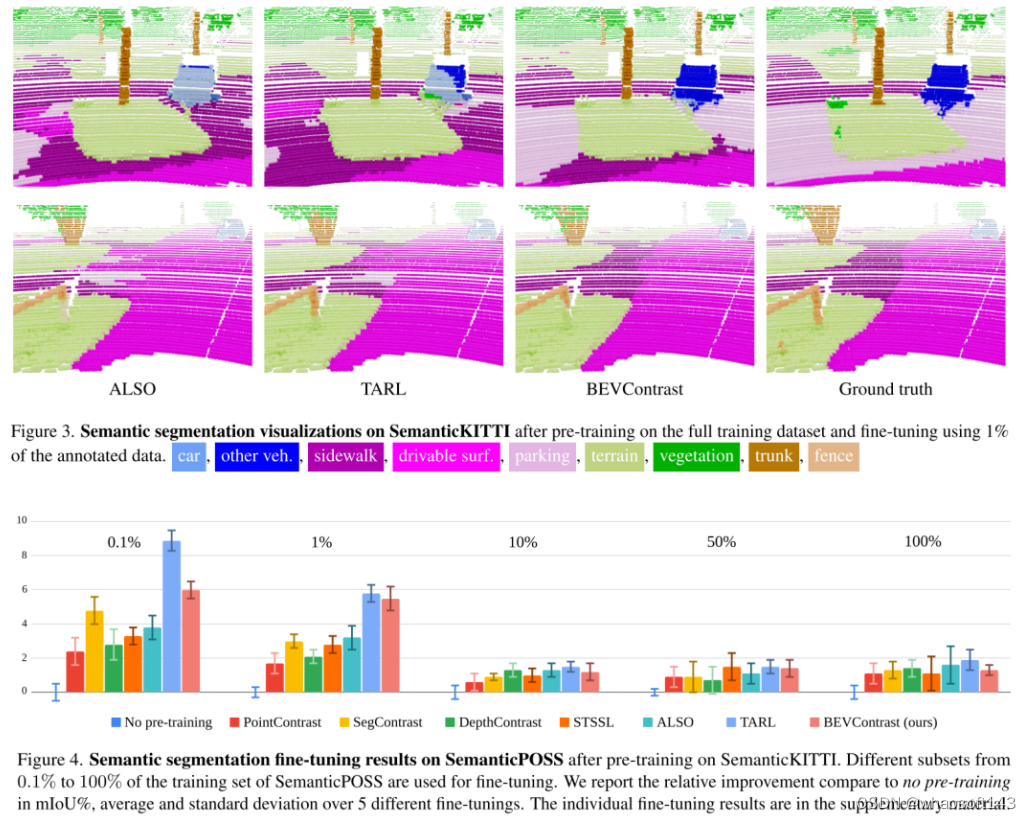
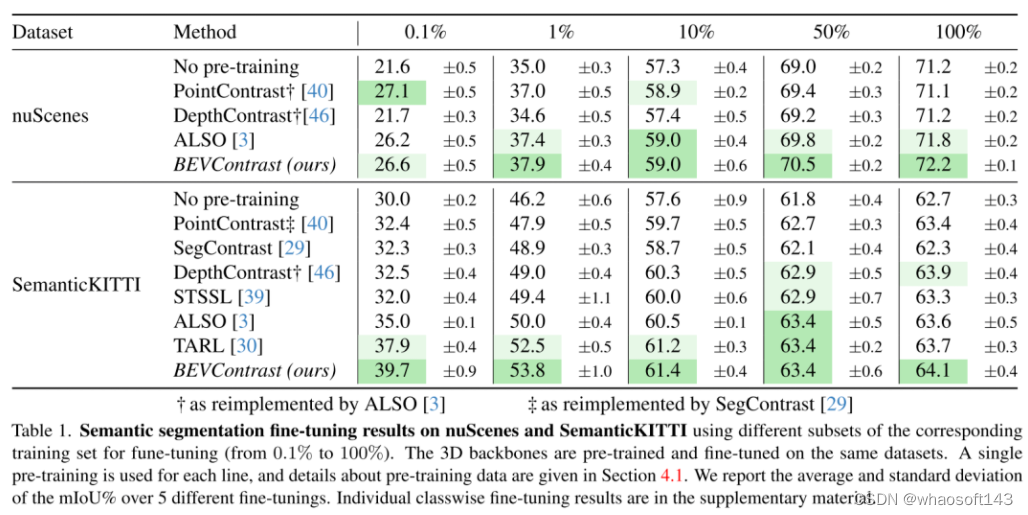
















 208
208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









