






前言
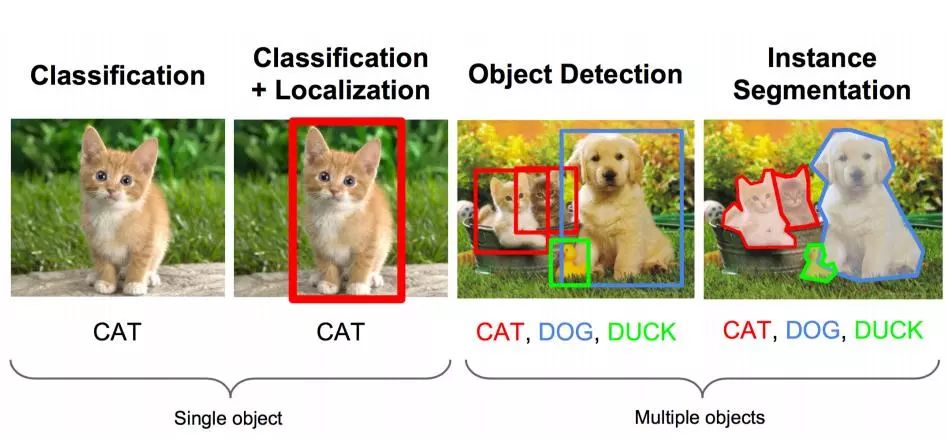
图片分类任务我们已经熟悉了,就是算法对其中的对象进行分类。而今天我们要了解构建神经网络的另一个问题,即目标检测问题。这意味着,我们不仅要用算法判断图片中是不是一辆汽车, 还要在图片中标记出它的位置, 用边框或红色方框把汽车圈起来, 这就是目标检测问题。 其中“定位”的意思是判断汽车在图片中的具体位置。
近几年来,目标检测算法取得了很大的突破。比较流行的算法可以分为两类,一类是基于Region Proposal的R-CNN系算法(R-CNN,Fast R-CNN, Faster R-CNN等),它们是two-stage的,需要先算法产生目标候选框,也就是目标位置,然后再对候选框做分类与回归。而另一类是Yolo,SSD这类one-stage算法,其仅仅使用一个卷积神经网络CNN直接预测不同目标的类别与位置。第一类方法是准确度高一些,但是速度慢,但是第二类算法是速度快,但是准确性要低一些。这可以在下图中看到。

本文对常见目标检测算法进行简要综述,并最后总结了目标检测算法方向的一些大V方便大家学习查看。
1. R-CNN
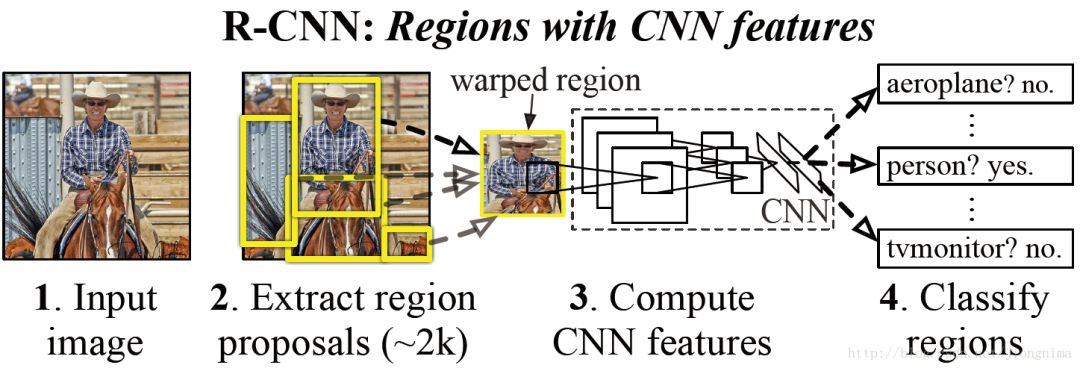
目标检测有两个主要任务:物体分类和定位,为了完成这两个任务,R-CNN借鉴了滑动窗口思想, 采用对区域进行识别的方案,具体是:
1)输入一张图片,通过指定算法从图片中提取 2000 个类别独立的候选区域(可能目标区域)
2)对于每个候选区域利用卷积神经网络来获取一个特征向量
3)对于每个区域相应的特征向量,利用支持向量机SVM 进行分类,并通过一个bounding box regression调整目标包围框的大小
1.1. 提取候选区域
R-CNN目标检测首先需要获取2000个目标候选区域,能够生成候选区域的方法很多,比如:
1)objectness
2)selective search
3)category-independen object proposals
4)constrained parametric min-cuts(CPMC)
5)multi-scale combinatorial grouping
6)Ciresan R-CNN 采用的是 Selective Search 算法。简单来说就是通过一些传统图像处理方法将图像分成很多小尺寸区域,然后根据小尺寸区域的特征合并小尺寸得到大尺寸区域,以实现候选区域的选取。
1.2. 提取特征向量
对于上述获取的候选区域,需进一步使用CNN提取对应的特征向量,作者使用模型AlexNet (2012)。(需要注意的是 Alexnet 的输入图像大小是 227x227,而通过 Selective Search 产生的候选区域大小不一,为了与 Alexnet 兼容,R-CNN 采用了非常暴力的手段,那就是无视候选区域的大小和形状,统一变换到 227x227 的尺寸)。 那么,该网络是如何训练的呢?训练过程如下:
1)有监督预训练:训练网络参数
样本:ImageNet
这里只训练和分类有关的参数,因为ImageNet数据只有分类,没有位置标注
图片尺寸调整为227x227
最后一层:4097维向量->1000向量的映射。
2)特定样本下的微调 :训练网络参数

样本:
采用训练好的AlexNet模型进行PASCAL VOC 2007样本集下的微调,学习率=0.001(PASCAL VOC 2007样本集上既有图像中物体类别标签,也有图像中物体位置标签)
mini-batch为32个正样本和96个负样本(由于正样本太少)
修改了原来的1000为类别输出,改为21维【20类+背景】输出。















 1017
1017











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









