







作者 | Cold Marie Wild译者 | 刘畅责编 | Jane出品 | AI科技大本营(公众号id:rgznai100)
【导语】根据自然梯度的支持者提出一种建议:我们不应该根据参数空间中的距离来定义值域空间,而是应该根据分布空间中的距离来定义它。这样真的有效?关于自然梯度优化,今天这篇文章值得大家一读!作者要以一个大家很少关注的角度讲一个肯定都听过的故事。
现在的深度学习模型都使用梯度下降法来进行训练。在梯度下降法的每个步骤中,参数值通常是从某个点开始,然后逐步将它们移动到模型最大损失减少的方向。我们通常可以通过从整个参数向量中计算损失的导数来实现这一点,也称为雅可比行列式。然而,这只是损失函数的一阶导数,它没有任何关于曲率的信息,换言之就是一阶导数改变的速度。由于该点可能位于一阶导数的局部近似区域中,并且它可能离极值点并不远(例如,在巨大的山峰之前的向下曲线),这时我们需要更加谨慎,并且不要以较大步长向下降低。因此,我们通常会采用下面等式中的步长 α 来控制我们的前馈速度。
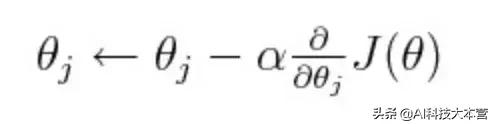
这个步长正在做这样一些事情:它以一个固定的值约束了你要在渐变方向上更新每个参数的距离。在这个算法的最简单版本中,我们采用一个标量,alpha,假设其值为 0.1,并将其乘以对损失函数求的梯度。注意,我们的梯度实际上是一个向量,也就是相对于模型中每个参数的损失梯度。因此当我们将它乘以标量时,实际上我们将沿着每个参数轴按照相同的固定量,按比例更新一个欧几里德参数距离。而且,在最基本的梯度下降版本中,我们在训练过程中使用的是相同步长。
但是......这样做真的有意义吗?使用较小学习率的前提是我们知道单个梯度的局部估计值可能仅在该估计周围的小局部区域中有效。但是,参数可以存在于不同的尺度上,并且可以对学习的条件分布产生不同程度的影响。而且,这种程度的影响可能会在训练过程中波动。从这个角度来看,在欧几里德参数空间中去固定一个全局范围看起来并不像是一件特别明智或有意义的事情
由自然梯度的支持者提出的另一种建议是,我们不应该根据参数空间中的距离来定义值域空间,而是应该根据分布空间中的距离来定义它。因此,不应该是“在符合当前梯度变化时,将参数向量保持在当前向量的 epsilon 距离内”,而应该是“在符合当前梯度变化时,要保持模型的分布是在之前预测分布的 epsilon 距离内”。这里的概念是两个分布之间的距离,而且对于任何缩放移位或一般的参数重置是具有不变性的。例如,可以使用方差参数或比例参数(1 /方差)来参数化相同的高斯分布;如果你查看参数空间,根据它们是使用方差还是比例进行参数化,两个分布将是不同的距离。但是如果你在原始概率空间中定义了一个距离,它就会是一致的。
接下来,本
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 343
343











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









