







数据预处理是数据挖掘流程的第2步,如果把数据挖掘看成做一道菜的话,数据预处理就是选择和清洗蔬菜的过程,这一步没做好会影响整个菜品的口感。数据预处理的目的就是把整个数据集调整为对于算法干扰最小的结构,以便提高最终算法的训练效果。本章主要讲述采样、去噪、归一化和数据过滤。
3.1采样
采样就是按照某种规则从数据集中挑选样本数据。通常的应用场景是数据样本过大,抽取少部分样本来训练或者验证,这样不仅会节约计算资源,在特定条件下也会提升实验效果。
3.1.1 随机采样
随机采样( Random Sampling )是所有采样中最常用的一种,也是最容易实现的采样方法。具体的实现形式是从被采样数据集中随机地抽取特定数量的数据,需要指定采样的个数。随机采样分为有放回采样和无放回采样两种,
(1)举例说明。这两种采样方法有什么区别呢?例如,在1个箱子里放了100个球,我们需要从中拿出10个,然后就闭着眼睛随便取1个出来,取出来之后记录一下取了哪个球,然后把取出来的球放回去,再重新取,如此累计10次,这就是有放回采样。而无放回采样就是直接随机取10个出来,并且不再放回。
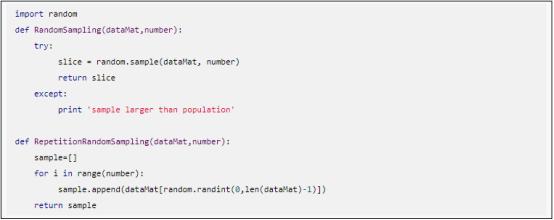
(2)示例代码。随机采样的Python2.7示例代码如下,其中:
dataMat是数据集;
number是采样数;
RandomSampling是无放回采样;
RepetitionRandomSampling是放回采样。
这里的代码只是一个示例,随机行为的实现采用了Python自带的random函数来执行。(3)效果展示。输入分为两个字段,按照从1~30排列,如图3-1所示。
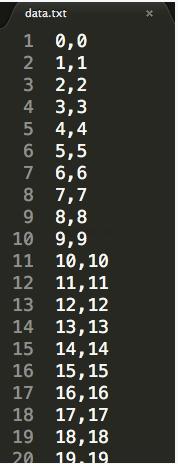
图3-1部分输入数据
无放回的采样结果RandomSampling ( dataMat, 7)。因为是无放回式采样,所以采样数据不会出现重复的样本数据,结果如图3-2所示。

图3-2无放回式采样结果
有放回的采样结果RandomSampling ( dataMat, 10 ) ,结果如图3-3所示。
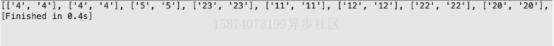
图3-3 有放回式采样结果
因为是有放回的采样,所以可能会出现重复的样本。
3.1.2 系统采样
系统采样(Systematic Sampling )在一般情况下是无放回式抽样。系统采样又称为等距采样,即先将总体的观察单位按某一顺序号分成n个部分,再从第一部分随机抽取第k
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3341
3341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









