






前言
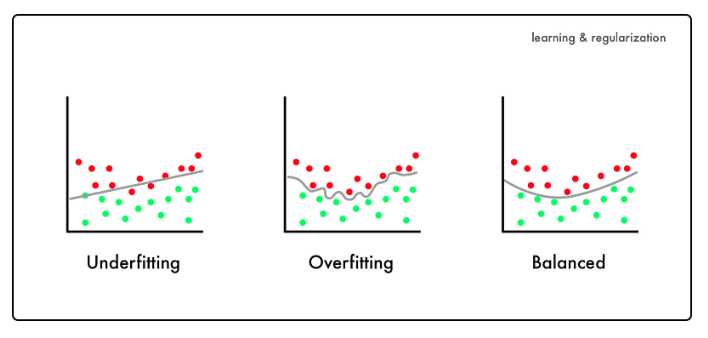
当模型在训练数据上表现良好,但对未见数据的泛化效果不佳时,就会出现过拟合的现象。过拟合是机器学习中一个非常常见的问题,已有大量文献致力于研究防止过拟合的方法。下面,我将介绍八种缓解过拟合的简单方法,每种方法只需对数据、模型或学习算法进行一次修改即可。
数据
与其将所有数据都用于训练,我们可以简单地将数据集分成两组:训练集和测试集。常见的拆分比例是 80% 用于训练,20% 用于测试。我们对模型进行训练,直到它不仅在训练集上表现良好,而且在测试集上也表现良好为止。这表明模型具有良好的泛化能力,因为测试集代表了未用于训练的未知数据。不过,这种方法需要足够大的数据集来训练,即使在拆分之后也是如此。
交叉验证
我们可以把数据集分成 k组(k-fold 交叉验证)。让其中一组作为测试集,其他组作为训练集,重复这一过程,直到每一组都被用作测试集(例如,重复 k 次)。交叉验证允许所有数据最终都用于训练。

数据增强
更大的数据集可以减少过拟合。如果我们无法收集到更多数据,只能局限于当前数据集中的数据,那么我们可以应用数据增强技术来人为增加数据集的规模。例如,如果我们正在为图像分类任务进行训练,我们可以对图像数据集进行各种图像转换(如翻转、旋转、重新缩放、平移)。

特征选择
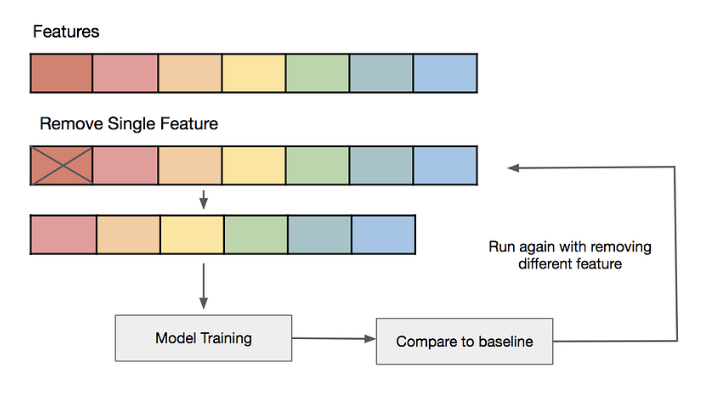
如果我们只有数量有限的训练样本,而每个样本都有大量特征,那么我们就应该只选择最重要的特征进行训练,这样我们的模型就不需要学习那么多特征,最终就不会过拟合。我们可以简单地测试不同的特征,针对这些特征训练单个模型,然后评估泛化能力,或者使用各种广泛使用的特征选择方法之一。
正则化
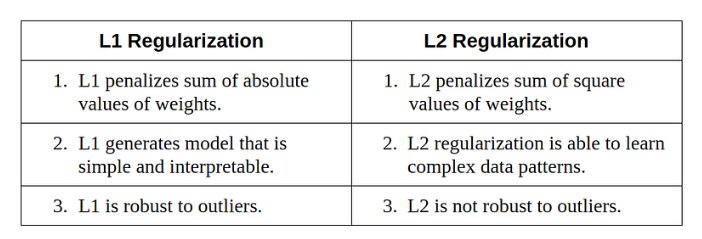
正则化是一种限制我们网络学习过于复杂模型的技术,这种模型可能会过度拟合。在 L1 或 L2 正则化中,我们可以在代价函数上添加一个惩罚项,将估计系数推向零(而不是取更极端的值)。L2 正则化允许权重向零衰减,但不会衰减到零,而 L1 正则化允许权重衰减到零。
删除层数
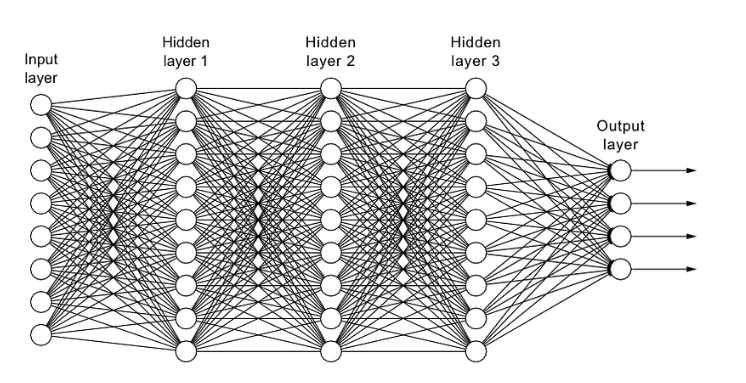
正如在 L1 或 L2 正则化中提到的,过于复杂的模型更有可能出现过拟合。因此,我们可以通过删除层来直接降低模型的复杂度,从而缩小模型的规模。我们还可以通过减少全连接层中神经元的数量来进一步降低复杂度。对于我们的任务来说,我们应该得到一个复杂度在欠拟合和过拟合之间充分平衡的模型。
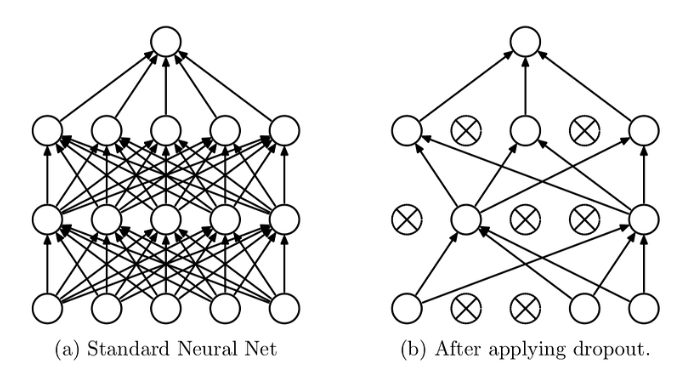
Dropout
通过在我们的网络层中应用 “Dropout”(一种正则化),我们可以以设定的概率忽略网络中的一个子单元集。使用 "Dropout"技术,我们可以减少神经单元间相互依赖的学习,因为这种学习可能会导致过度拟合。但是,如果使用 “Dropout”,我们就需要更多的epoch才能收敛模型。
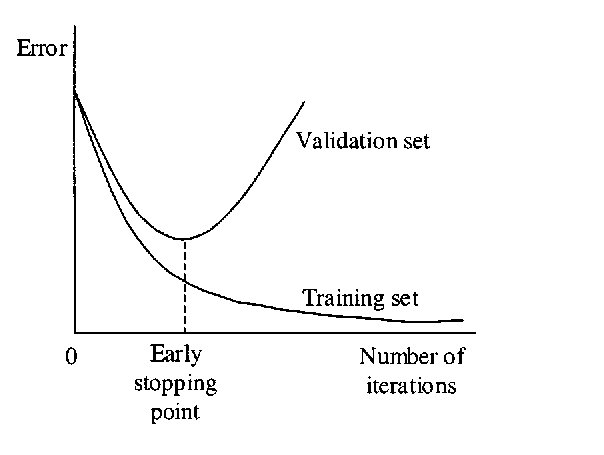
Ealy Stop
我们可以首先对模型进行任意数量epoch的训练,并绘制验证损失图。一旦验证损失开始下降(例如不再下降而是开始上升),我们就会停止训练并保存当前模型。我们可以通过监控损失函数图或设置提前停止触发器来实现这一点。保存的模型将是在不同训练epoch值之间进行泛化的最佳模型。
总结
本文重点介绍了神经网络训练过程中解决过拟合的八种常见解决方法,这些基础技术可以帮助大家理解机器学习领域中的基础知识。















 8990
8990

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









