







作者 | 地平线
编辑 | 贾 伟
行人检测作为计算机视觉领域最基本的主题之一,多年来被广泛研究。尽管最先进的行人检测器已在无遮挡行人上取得了超过 90% 的准确率,但在严重遮挡行人检测上依然无法达到满意的效果。究其根源,主要存在以下两个难点:
1、严重遮挡的行人框大部分为背景,检测器难以将其与背景类别区分;
2、给定一个遮挡行人框,检测器无法得到可见区域的信息;
针对这两大难题,地平线与 Buffalo 学院提出 Tube Feature Aggregation Network(TFAN)新方法,即利用时序信息来辅助当前帧的遮挡行人检测,目前该方法已在 Caltech 和 NightOwls 两个数据集取得了业界领先的准确率。
相关论文「Temporal-Context Enhanced Detection of Heavily Occluded Pedestrians」已被收录于 CVPR 2020 。

论文链接:https://cse.buffalo.edu/~jsyuan/papers/2020/TFAN.pdf
1、核心思路
利用时序信息辅助当前帧遮挡行人检测
目前大部分行人检测工作都集中于静态图像检测,但在实际车路环境中大部分目标都处于运动状态。针对严重遮挡行人的复杂场景,单帧图像难以提供足够有效的信息。为了优化遮挡场景下行人的识别,地平线团队提出通过相邻帧寻找无遮挡或少遮挡目标,对当前图像中的遮挡行人识别进行辅助检测。
2、实验新方法Proposal tube 解决严重遮挡行人检测
如下图,给定一个视频序列,首先对每帧图像提取特征并使用 RPN(Region Proposal Network)网络生成 proposal 框。从当前帧的某个 proposal 框出发,依次在相邻帧的空间邻域内寻找最相似的proposal框并连接成 proposal tube。
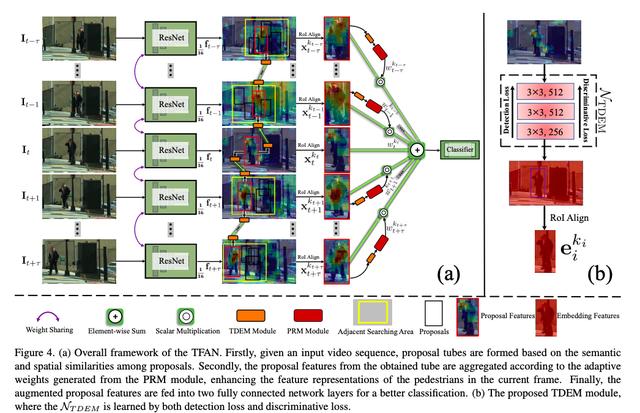
在相邻的第 i 帧和第 i-1 帧之间,具体两个 proposal 的匹配准则可根据以下公式:
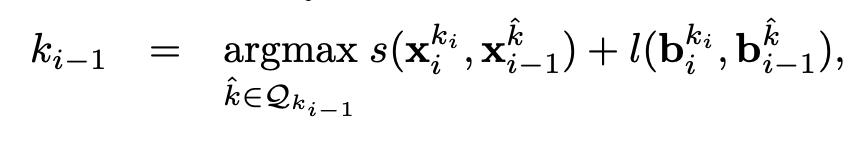
其中 s 是用于计算两个 proposal 特征的余弦相似度,而 l 是用于计算两个 proposal 在尺寸大小及空间位置上的相似程度(具体公式可见论文)。X 和 b 分别表示 proposal 特征和 proposal 边界框,字母的上标表示 proposal 编号,Qki-1 表示在第 i-1 帧搜索区域内的 proposal 框的编号集合。
假设视频序列共有 13 帧,可以得到一个具有 13 个 proposal 框的 tube 以及他们对应的 proposal 特征。这样的做法可以有效的将时序上前后存在的无遮挡行人连接到 proposal tube 当中。随后,将这些 proposal 特征以加权求和的方式融合到当前帧的 proposal 特征中来,具体的融合权重可根据以下公式求得:
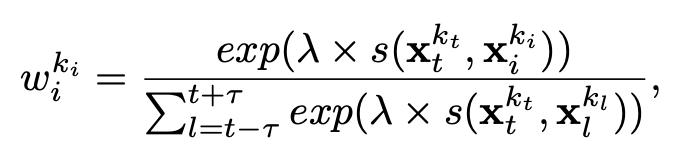
其中,τ 代表时序上前后各有 τ 帧,λ 为常数,t 表示当前帧。公式 5 的做法可以避免无关的特征被错误融合进来。当背景框被连接到了行人的 tube 当中,他们的特征相似度较低,所以最后产生的融合权重较小,从而防止了行人特征被背景特征所污染,反之亦然。最后,我们将融合后的特征送入分类器,从而更好的识别严重遮挡的行人。
TDEM模块有效避免行人框与背景框交叉
为了避免连接 tube 过程中发生错误的偏移,比如行人框连到了背景框,或背景框连到了行人框。针对这种情况,研究团队提出 TDEM(Temporally Discriminative Embedding Module)模块用于将原 proposal 特征映射到一个 embedding 空间,然后利用 embedding 特征来计算两个 proposal 之间的特征相似度。在这个 embedding 空间我们可利用损失函数来进行监督,使行人的 embedding 与前后帧背景的 embedding 相互排斥与前后帧行人的embedding相互吸引。具体的损失函数由 triplet loss 实现如下:

其中 en,ep,et^kt*分别代表前后帧背景,行人和当前帧行人的 embedding 特征。根据实验发现 TDEM 模块可以有效的避免行人框与背景框错误的相连(参见原文表 3 及图 5)。
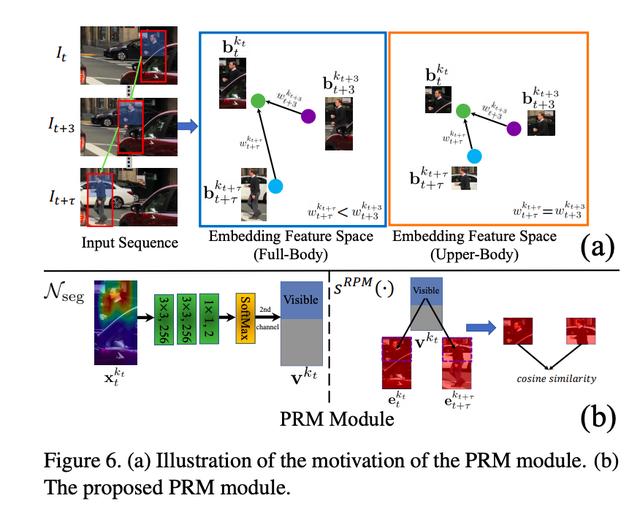
利用 PRM 模块解决融合权重较少的问题
即使通过以上的设计能够使得当前帧遮挡行人连接上前后帧未遮挡的行人,依然又一个亟待解决的难题:融合权重。由下图(a)可见,因为遮挡行人的特征充斥大量背景,所以遮挡行人的特征和无遮挡行人的特征相似度较低,产生的融合权重较小。因此即便找到了未遮挡行人,也很难有效地将其利用。
为了解决此问题,研究团队提出了 PRM(Part-based Relation Module)模块。在 PRM 模块中,首先预测当前帧行人的可见区域位置。然后,在比较两个行人框特征的相似度时,只会计算在这个可见区域内的相似度。如下图(a)右,当只比较两个行人的上半身相似度时,我们会发现他们其实是同一个人,由此产生的融合权重会较高。图 7 显示了 PRM 的可视化结果,我们发现 PRM 模块计算的相似度会比直接使用全身特征计算的相似度更高。
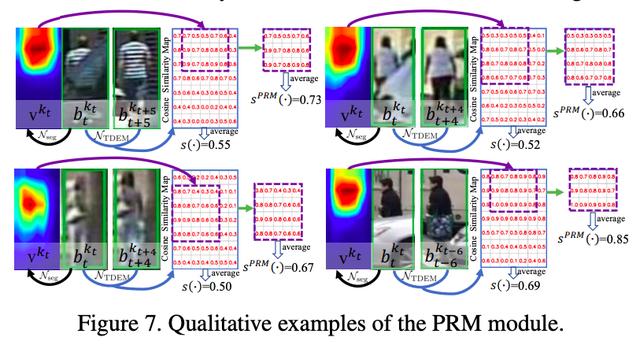
3、实验结果
TFAN 有效增强检测器的识别能力
在 Caltech 数据集上的结果如下:
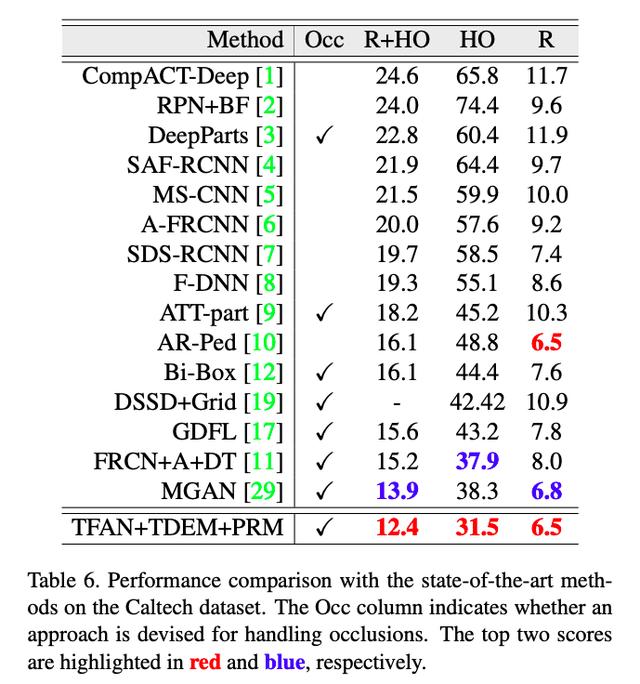
注:R 表示 Reasonable 少量遮挡及无遮挡的结果,HO 表示 Heavily Occlusion 严重遮挡的结果,R+HO 表示综合结果。
可视化结果如下:


ACL 2020原定于2020年7月5日至10日在美国华盛顿西雅图举行,因新冠肺炎疫情改为线上会议。为促进学术交流,方便国内师生提早了解自然语言处理(NLP)前沿研究,AI 科技评论将推出「ACL 实验室系列论文解读」内容,同时欢迎更多实验室参与分享,敬请期待!















 439
439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









