






参考博客:
L-margin softmax loss:https://blog.csdn.net/u014380165/article/details/76864572
A-softmax loss:https://blog.csdn.net/u011808673/article/details/80491361
AM-softmax loss:https://blog.csdn.net/fire_light_/article/details/79602310
arcface:https://blog.csdn.net/Fire_Light_/article/details/79602705
softmax loss:
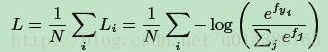
N是样本的数量,i代表第i个样本,j代表第j个类别,fyi代表着第i个样本所属的类别的分数
fyi是全连接层的输出,代表着每一个类别的分数,
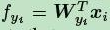 每一个分数即为权重W和特征向量X的内积
每一个分数即为权重W和特征向量X的内积
每个样本的softmax值即为:
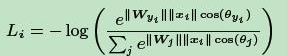
L-softmax loss:
假设一个2分类问题,x属于类别1,那么原来的softmax肯定是希望:
也就是属于类别1的概率大于类别2的概率,这个式子和下式是等效的:
large margin softmax就是将上面不等式替换为:
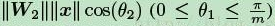
m是正整数,cos函数在0到π范围又是单调递减的,所以cos(mx)要小于cos(x)。通过这种方式定义损失会逼得模型学到类间距离更大的,类内距离更小的特征。
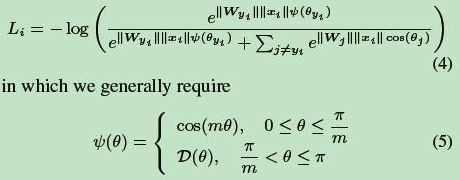
从几何的角度看两种损失的差别:
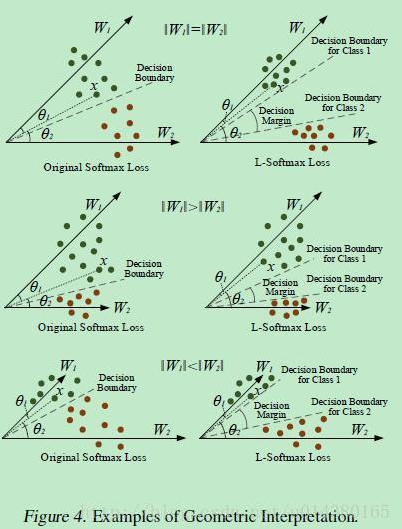
设置为cos(mx)后,使得学习到的W参数更加的扁平,可以加大样本的类间距离。
Large-Margin Softmax的实验效果:
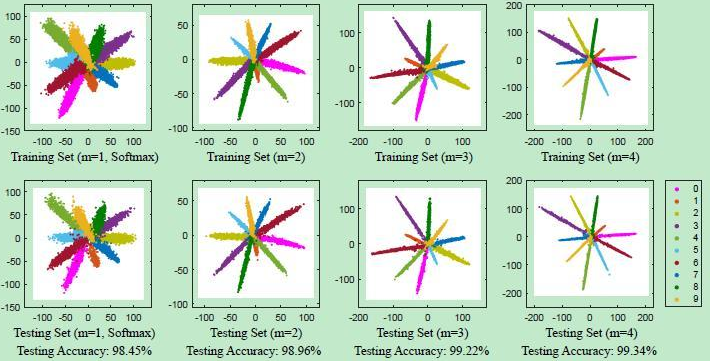
A-softmax loss
A-softmax loss简单讲就是在large margin softmax loss的基础上添加了两个限制条件||W||=1和b=0,使得预测仅取决于W和x之间的角度。
softmax的计算: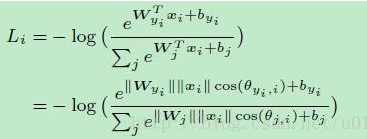
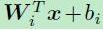 可以写成
可以写成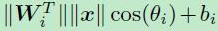
若引入两个限制条件, 和
和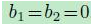
decision boundary变为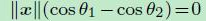 ,只取决于角度了
,只取决于角度了
则损失函数变为: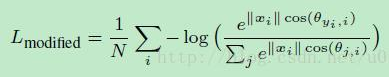
在这两个限制条件的基础上,作者又添加了和large margin softmax loss一样的角度参数,使得公式变为:
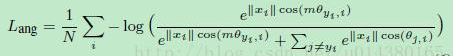
AM-softmax
在A-softmax的基础上,修改Cos(mθ)为一个新函数: 
与ASoftmax中定的的类似,可以达到减小对应标签项的概率,增大损失的效果,因此对同一类的聚合更有帮助
然后根据Normface,对f进行归一化,乘上缩放系数s,最终的损失函数变为:
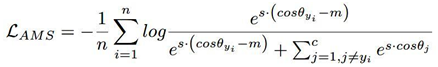
这样做的好处在于A-Softmax的倍角计算是要通过倍角公式,反向传播时不方便求导,而只减m反向传播时导数不用变化
Asoftmax是用m乘以θ,而AMSoftmax是用cosθ减去m,这是两者的最大不同之处:一个是角度距离,一个是余弦距离。
之所以选择cosθ-m而不是cos(θ-m),这是因为我们从网络中得到的是W和f的内积,如果要优化cos(θ-m)那么会涉及到arccos操作,计算量过大。
arcface
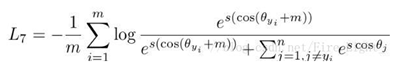
分类正确label的值为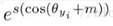 ,cos函数在(0,1)内是单调递减的,加上m,会使该值变得更小,从而loss会变得很大。
,cos函数在(0,1)内是单调递减的,加上m,会使该值变得更小,从而loss会变得很大。
这样修改的原因:角度距离比余弦距离在对角度的影响更加直接















 3214
3214











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









